Recognition: no theorem link
G-Zero: Self-Play for Open-Ended Generation from Zero Data
Pith reviewed 2026-05-12 03:36 UTC · model grok-4.3
The pith
G-Zero lets LLMs self-improve on open-ended tasks by generating their own training signals from internal distributional shifts rather than external judges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
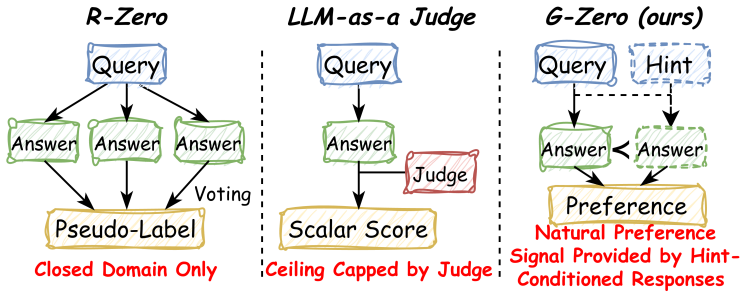
G-Zero is a verifier-free framework that trains a Proposer via GRPO to target a Generator's blind spots with synthetic queries and hints, while the Generator is updated via DPO to absorb the hint-conditioned improvements; the only training signal is Hint-δ, defined as the predictive shift between the Generator's unassisted response and its hint-conditioned response, yielding a best-iterate suboptimality guarantee for idealized standard-DPO training whenever the Proposer supplies sufficient exploration coverage and data filtration maintains low pseudo-label noise.
What carries the argument
Hint-δ, the scalar that quantifies the distributional difference between a Generator model's response without a hint and its response when conditioned on a self-generated hint, serving as the sole reward for both Proposer and Generator optimization.
Load-bearing premise
The Proposer must keep generating queries that expose the Generator's current weaknesses while the filtering step must preserve accurate pseudo-label scores.
What would settle it
Run repeated rounds of G-Zero on an open-ended benchmark and observe whether Generator performance on held-out tasks plateaus or declines even as the Proposer continues to propose new hints.
Figures




read the original abstract
Self-evolving LLMs excel in verifiable domains but struggle in open-ended tasks, where reliance on proxy LLM judges introduces capability bottlenecks and reward hacking. To overcome this, we introduce G-Zero, a verifier-free, co-evolutionary framework for autonomous self-improvement. Our core innovation is Hint-$\delta$, an intrinsic reward that quantifies the predictive shift between a Generator model's unassisted response and its response conditioned on a self-generated hint. Using this signal, a Proposer model is trained via GRPO to continuously target the Generator's blind spots by synthesizing challenging queries and informative hints. The Generator is concurrently optimized via DPO to internalize these hint-guided improvements. Theoretically, we prove a best-iterate suboptimality guarantee for an idealized standard-DPO version of G-Zero, provided that the Proposer induces sufficient exploration coverage and the data filteration keeps pseudo-label score noise low. By deriving supervision entirely from internal distributional dynamics, G-Zero bypasses the capability ceilings of external judges, providing a scalable, robust pathway for continuous LLM self-evolution across unverifiable domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces G-Zero, a verifier-free co-evolutionary self-play framework for open-ended LLM generation. It defines an intrinsic Hint-δ reward based on the predictive distributional shift between a Generator's unassisted response and its response conditioned on a self-generated hint. A Proposer is trained via GRPO to synthesize challenging queries and hints targeting the Generator's blind spots, while the Generator is optimized concurrently via DPO to internalize the improvements. The central theoretical contribution is a best-iterate suboptimality guarantee for an idealized standard-DPO instantiation, conditioned on the Proposer providing sufficient exploration coverage and the data filtration maintaining low pseudo-label score noise.
Significance. If the result holds, G-Zero would offer a scalable route to continuous LLM self-evolution in unverifiable domains by deriving supervision solely from internal distributional dynamics, thereby sidestepping the capability ceilings and reward-hacking risks of external LLM judges. The attempt to supply a formal best-iterate suboptimality guarantee, even if conditional, is a constructive step toward rigorous analysis of self-play methods and should be credited as such.
major comments (2)
- [Abstract and theoretical analysis] Abstract and theoretical analysis: The best-iterate suboptimality guarantee is explicitly conditional on two assumptions—the Proposer induces sufficient exploration coverage and the data filtration keeps pseudo-label score noise low. The manuscript provides no argument, additional derivation, or empirical measurement showing that GRPO training on Hint-δ signals automatically satisfies these conditions rather than leading to coverage collapse or excessive noise; because the guarantee is load-bearing for the claim that G-Zero supplies a robust internal self-evolution pathway, this gap must be addressed.
- [Method section describing the practical algorithm] Method section describing the practical algorithm: The Proposer is trained with GRPO on Hint-δ while the Generator uses DPO on filtered data, yet no analysis is given of how the co-evolutionary loop prevents the Proposer from collapsing to low-coverage modes or of the noise level introduced by the self-generated pseudo-labels; without such verification the practical method cannot inherit the idealized guarantee.
minor comments (3)
- [Abstract] Abstract: 'filteration' is a typographical error and should be corrected to 'filtration'.
- [Definition of Hint-δ] Definition of Hint-δ: The predictive-shift quantity should be stated with an explicit mathematical expression (e.g., a KL divergence or log-probability difference) rather than left at the level of informal description.
- [Notation] Notation: Ensure that the symbols for the Generator and Proposer models, as well as for the hint-conditioned versus unconditioned distributions, are introduced once and used consistently in all subsequent sections and equations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the link between the conditional theoretical guarantee and the practical GRPO/DPO co-evolution requires explicit discussion and supporting evidence. We outline targeted revisions below to address both major comments.
read point-by-point responses
-
Referee: [Abstract and theoretical analysis] Abstract and theoretical analysis: The best-iterate suboptimality guarantee is explicitly conditional on two assumptions—the Proposer induces sufficient exploration coverage and the data filtration keeps pseudo-label score noise low. The manuscript provides no argument, additional derivation, or empirical measurement showing that GRPO training on Hint-δ signals automatically satisfies these conditions rather than leading to coverage collapse or excessive noise; because the guarantee is load-bearing for the claim that G-Zero supplies a robust internal self-evolution pathway, this gap must be addressed.
Authors: We acknowledge that the current manuscript presents the best-iterate guarantee only for the idealized standard-DPO case under the stated assumptions and does not include a formal derivation or empirical verification that GRPO on Hint-δ automatically enforces sufficient coverage or bounded noise. The theoretical result is intended to identify the precise conditions required for guaranteed self-improvement rather than to claim that the practical algorithm always meets them. In the revision we will add a dedicated paragraph in the theoretical analysis section discussing how the Hint-δ reward, by construction, incentivizes the Proposer to target regions of high distributional shift (i.e., the Generator’s current blind spots), which provides an inductive bias against trivial low-coverage modes. We will also include new empirical measurements—coverage entropy of the Proposer’s query distribution and estimated pseudo-label noise over training iterations—drawn from the existing experimental setups to illustrate that the assumptions are satisfied in the regimes we study. revision: yes
-
Referee: [Method section describing the practical algorithm] Method section describing the practical algorithm: The Proposer is trained with GRPO on Hint-δ while the Generator uses DPO on filtered data, yet no analysis is given of how the co-evolutionary loop prevents the Proposer from collapsing to low-coverage modes or of the noise level introduced by the self-generated pseudo-labels; without such verification the practical method cannot inherit the idealized guarantee.
Authors: We agree that the manuscript currently lacks an explicit analysis of coverage preservation and noise accumulation within the alternating GRPO–DPO loop. To close this gap we will expand the method section with a new subsection that (i) describes the data-filtration heuristic and its effect on pseudo-label score variance, (ii) provides a qualitative argument that the Proposer’s objective of maximizing Hint-δ continually rewards diversity because low-coverage modes yield diminishing returns on the shift signal, and (iii) reports quantitative diagnostics (Proposer output entropy and hint-quality variance) tracked across co-evolution steps. These additions will clarify why the practical procedure is expected to remain compatible with the idealized assumptions. revision: yes
Circularity Check
No significant circularity; derivation self-contained with explicit conditions
full rationale
The paper's core claim introduces Hint-δ as an intrinsic signal based on predictive shift between unassisted and hint-conditioned responses, then uses it to co-train Proposer (via GRPO) and Generator (via DPO). The only formal result is a best-iterate suboptimality guarantee for an idealized standard-DPO version, explicitly conditioned on two external requirements: sufficient exploration coverage by the Proposer and low pseudo-label noise after filtration. These conditions are stated as prerequisites for the bound to hold rather than derived from the method itself or assumed to be automatically satisfied. No equations, self-citations, uniqueness theorems, or ansatzes are shown reducing the output to the input by construction. The framework therefore remains non-circular: it proposes a new internal supervision mechanism whose theoretical support is conditional and does not tautologically equate to its own fitted dynamics.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Hint-δ
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models, 2024. URL https://arxiv.org/ abs/2401.01335
work page internal anchor Pith review arXiv 2024
-
[3]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
Serl: Self-play reinforcement learning for large language models with limited data, 2025
Wenkai Fang, Shunyu Liu, Yang Zhou, Kongcheng Zhang, Tongya Zheng, Kaixuan Chen, Mingli Song, and Dacheng Tao. Serl: Self-play reinforcement learning for large language models with limited data, 2025. URLhttps://arxiv.org/abs/2505.20347
-
[5]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
A survey on LLM-as-a-judge.The Innovation, 2024
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on LLM-as-a-judge.The Innovation, 2024
work page 2024
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Visplay: Self-evolving vision-language models from images,
Yicheng He, Chengsong Huang, Zongxia Li, Jiaxin Huang, and Yonghui Yang. Visplay: Self-evolving vision-language models from images.arXiv preprint arXiv:2511.15661, 2025
-
[9]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[10]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-Zero: Self-evolving reasoning LLM from zero data. arXiv preprint arXiv:2508.05004, 2025
work page internal anchor Pith review arXiv 2025
-
[11]
Large language models can self-improve, 2022
Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. Large language models can self-improve, 2022. URL https://arxiv.org/abs/2210. 11610
work page 2022
-
[12]
Likelihood- based reward designs for general llm reasoning.arXiv preprint arXiv:2602.03979, 2026
Ariel Kwiatkowski, Natasha Butt, Ismail Labiad, Julia Kempe, and Yann Ollivier. Likelihood- based reward designs for general llm reasoning.arXiv preprint arXiv:2602.03979, 2026
-
[13]
Mm-zero: Self-evolving multi-model vision language models from zero data,
Zongxia Li, Hongyang Du, Chengsong Huang, Xiyang Wu, Lantao Yu, Yicheng He, Jing Xie, Xiaomin Wu, Zhichao Liu, Jiarui Zhang, and Fuxiao Liu. Mm-zero: Self-evolving multi-model vision language models from zero data, 2026. URL https://arxiv.org/abs/2603.09206
-
[14]
Xiao Liang, Zhong-Zhi Li, Yeyun Gong, Yang Wang, Hengyuan Zhang, Yelong Shen, Ying Nian Wu, and Weizhu Chen. Sws: Self-aware weakness-driven problem synthesis in reinforcement learning for llm reasoning, 2025. URLhttps://arxiv.org/abs/2506.08989
-
[15]
Zi Lin, Sheng Shen, Ilia Kulikov, Jingbo Shang, Jason Weston, and Yixin Nie. Learning to solve and verify: A self-play framework for code and test generation.arXiv preprint arXiv:2502.14948, 2025. 10
-
[16]
Spice: Self-play in corpus environments improves reasoning.arXiv, 2025
Bo Liu, Chuanyang Jin, Seungone Kim, Weizhe Yuan, Wenting Zhao, Ilia Kulikov, Xian Li, Sainbayar Sukhbaatar, Jack Lanchantin, and Jason Weston. Spice: Self-play in corpus environments improves reasoning.arXiv preprint arXiv:2510.24684, 2025
-
[17]
Mmc: Advancing multimodal chart understanding with large-scale instruction tuning
Fuxiao Liu, Xiaoyang Wang, Wenlin Yao, Jianshu Chen, Kaiqiang Song, Sangwoo Cho, Yaser Yacoob, and Dong Yu. Mmc: Advancing multimodal chart understanding with large-scale instruction tuning. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Paper...
work page 2024
-
[18]
Nover: Incentive training for language models via verifier-free reinforcement learning
Wei Liu, Siya Qi, Xinyu Wang, Chen Qian, Yali Du, and Yulan He. Nover: Incentive training for language models via verifier-free reinforcement learning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 7450–7469, 2025
work page 2025
-
[19]
Yan Liu, Feng Zhang, Zhanyu Ma, Jun Xu, Jiuchong Gao, Jinghua Hao, Renqing He, Han Liu, and Yangdong Deng. Efficient paths and dense rewards: Probabilistic flow reasoning for large language models.arXiv preprint arXiv:2601.09260, 2026
-
[20]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
work page 2023
-
[22]
Sheikh Shafayat, Fahim Tajwar, Ruslan Salakhutdinov, Jeff Schneider, and Andrea Zanette. Can large reasoning models self-train?, 2025. URL https://arxiv.org/abs/2505.21444
-
[23]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Hi robot: Open-ended instruction following with hierarchical vision-language-action models,
Lucy Xiaoyang Shi, Brian Ichter, Michael Equi, Liyiming Ke, Karl Pertsch, Quan Vuong, James Tanner, Anna Walling, Haohuan Wang, Niccolo Fusai, et al. Hi robot: Open-ended instruction following with hierarchical vision-language-action models.arXiv preprint arXiv:2502.19417, 2025
-
[25]
Ai models collapse when trained on recursively generated data.Nature, 631(8022): 755–759, 2024
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. Ai models collapse when trained on recursively generated data.Nature, 631(8022): 755–759, 2024
work page 2024
-
[26]
Large language models for data annotation and synthesis: A survey
Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Mansooreh Karami, Jundong Li, Lu Cheng, and Huan Liu. Large language models for data annotation and synthesis: A survey. InConference on Empirical Methods in Natural Language Processing, 2024
work page 2024
-
[27]
A survey on self-evolution of large language models
Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, et al. A survey on self-evolution of large language models.ArXiv preprint, abs/2404.14387, 2024
-
[28]
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
Xiaohua Wang, Muzhao Tian, Yuqi Zeng, Zisu Huang, Jiakang Yuan, Bowen Chen, Jingwen Xu, Mingbo Zhou, Wenhao Liu, Muling Wu, et al. Reward hacking in the era of large models: Mechanisms, emergent misalignment, challenges.arXiv preprint arXiv:2604.13602, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language model with self generated instruc- tions, 2022
work page 2022
-
[30]
Associated with the WaltonFuture GeoQA-8K-direct-synthesizing dataset release
Lai Wei, Yuting Li, Chen Wang, Yue Wang, Linghe Kong, Weiran Huang, and Lichao Sun. First sft, second rl, third upt: Continual improving multi-modal llm reasoning via unsupervised post-training, 2025. URLhttps://arxiv.org/abs/2505.22453. 11
-
[31]
Zhishang Xiang, Chengyi Yang, Zerui Chen, Zhimin Wei, Yunbo Tang, Zongpei Teng, Zexi Peng, Zongxia Li, Chengsong Huang, Yicheng He, et al. A systematic survey of self-evolving agents: From model-centric to environment-driven co-evolution, 2025
work page 2025
-
[32]
Reinforcement learning with conditional expectation reward.arXiv preprint arXiv:2603.10624, 2026
Changyi Xiao, Caijun Xu, and Yixin Cao. Reinforcement learning with conditional expectation reward.arXiv preprint arXiv:2603.10624, 2026
-
[33]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Zihao Yi, Jiarui Ouyang, Zhe Xu, Yuwen Liu, Tianhao Liao, Haohao Luo, and Ying Shen. A survey on recent advances in LLM-based multi-turn dialogue systems.ACM Computing Surveys, 58(6):1–38, 2025
work page 2025
-
[35]
Rlpr: Extrapolating rlvr to general domains without verifiers, 2025
Tianyu Yu, Bo Ji, Shouli Wang, Shu Yao, Zefan Wang, Ganqu Cui, Lifan Yuan, Ning Ding, Yuan Yao, Zhiyuan Liu, et al. Rlpr: Extrapolating rlvr to general domains without verifiers. arXiv preprint arXiv:2506.18254, 2025
-
[36]
Guided self-evolving llms with minimal human supervision.arXiv preprint arXiv:2512.02472,
Wenhao Yu, Zhenwen Liang, Chengsong Huang, Kishan Panaganti, Tianqing Fang, Haitao Mi, and Dong Yu. Guided self-evolving LLMs with minimal human supervision.arXiv preprint arXiv:2512.02472, 2025
-
[37]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data, 2025. URLhttps://arxiv.org/abs/2505.03335
work page internal anchor Pith review arXiv 2025
-
[38]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Reinforcing general reasoning without verifiers.arXiv preprint arXiv:2505.21493, 2025
Xiangxin Zhou, Zichen Liu, Anya Sims, Haonan Wang, Tianyu Pang, Chongxuan Li, Liang Wang, Min Lin, and Chao Du. Reinforcing general reasoning without verifiers.arXiv preprint arXiv:2505.21493, 2025
-
[40]
Yifei Zhou, Sergey Levine, Jason Weston, Xian Li, and Sainbayar Sukhbaatar. Self-challenging language model agents, 2025. URLhttps://arxiv.org/abs/2506.01716. 12 A Prompts and Templates Configuration: Proposer (Phase 1 GRPO and Phase 2 generation) •Model: base policy (Qwen/Qwen3-8B-Base by default) •Temperature: 1.0 •Max tokens: 8 192 •System message:(non...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.