Recognition: 2 theorem links
· Lean TheoremPredicting 3D structure by latent posterior sampling
Pith reviewed 2026-05-12 05:08 UTC · model grok-4.3
The pith
Representing 3D scenes as stochastic latent variables decoded by a NeRF allows sampling from the posterior to perform reconstruction from diverse observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that by training a reconstruction model to auto-decode latent representations of 3D scenes and then fitting a diffusion model as the prior over those latents, posterior sampling can be used to generate 3D structure predictions. The sampling uses score-based diffusion inference combined with a likelihood term derived from the volumetric rendering of the decoded NeRF. This produces accurate reconstructions for inputs ranging from single-view images to sparse depth data, while capturing the uncertainty inherent to each observation type.
What carries the argument
The stochastic latent variable that encodes the 3D scene, decoded into a neural radiance field for rendering, with the diffusion model providing the mechanism for prior and posterior sampling.
If this is right
- Various 3D reconstruction tasks become unified under one posterior sampling procedure.
- The uncertainty associated with different observation types is explicitly modeled through the spread of posterior samples.
- Reconstructions from less informative inputs exhibit greater variability in the generated 3D scenes.
- The two-stage training separates learning the scene representation from learning the scene prior.
Where Pith is reading between the lines
- The approach might generalize to other scene representations beyond NeRF if the decoder can be swapped.
- Posterior sampling could be used for tasks like novel view synthesis with uncertainty estimates.
- This probabilistic view of 3D reconstruction may connect to active sensing or data acquisition strategies that minimize uncertainty.
Load-bearing premise
A single low-dimensional stochastic latent variable, once decoded by a NeRF, faithfully represents the posterior distribution over 3D scenes for the range of observation types considered.
What would settle it
If generating multiple samples from the posterior for a fixed set of observations yields 3D structures that are inconsistent with the ground truth or do not reflect the expected uncertainty levels in quantitative evaluations on test scenes.
Figures







read the original abstract
The remarkable achievements of both generative models of 2D images and neural field representations for 3D scenes present a compelling opportunity to integrate the strengths of both approaches. In this work, we propose a methodology that combines a NeRF-based representation of 3D scenes with probabilistic modeling and reasoning using diffusion models. We view 3D reconstruction as a perception problem with inherent uncertainty that can thereby benefit from probabilistic inference methods. The core idea is to represent the 3D scene as a stochastic latent variable for which we can learn a prior and use it to perform posterior inference given a set of observations. We formulate posterior sampling using the score-based inference method of diffusion models in conjunction with a likelihood term computed from a reconstruction model that includes volumetric rendering. We train the model using a two-stage process: first we train the reconstruction model while auto-decoding the latent representations for a dataset of 3D scenes, and then we train the prior over the latents using a diffusion model. By using the model to generate samples from the posterior we demonstrate that various 3D reconstruction tasks can be performed, differing by the type of observation used as inputs. We showcase reconstruction from single-view, multi-view, noisy images, sparse pixels, and sparse depth data. These observations vary in the amount of information they provide for the scene and we show that our method can model the varying levels of inherent uncertainty associated with each task. Our experiments illustrate that this approach yields a comprehensive method capable of accurately predicting 3D structure from diverse types of observations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a two-stage framework for probabilistic 3D scene reconstruction: (1) auto-decoding a low-dimensional stochastic latent z with a NeRF-based reconstruction model that includes volumetric rendering, and (2) training a diffusion model as a prior over the learned latents. Posterior sampling is performed via score-based diffusion inference conditioned on a reconstruction likelihood, enabling 3D prediction from diverse observations (single-view images, multi-view, noisy images, sparse pixels, sparse depth) while claiming to capture task-dependent uncertainty.
Significance. If the central claims hold, the work offers a unified probabilistic treatment of 3D reconstruction that integrates the representational power of NeRFs with the generative capabilities of diffusion models. The two-stage separation of reconstruction learning from prior modeling is a clear design strength, and the demonstration across observation types with varying information content addresses a genuine need in uncertainty-aware 3D perception.
major comments (2)
- [§3] §3 (Method), posterior sampling formulation: the claim that sampling from the diffusion prior conditioned on the reconstruction likelihood recovers the true posterior over scenes is load-bearing for the uncertainty-modeling results, yet the text provides no derivation or empirical check that the low-dimensional z can represent multimodal posteriors (e.g., for sparse-pixel or single-view inputs).
- [Experiments] Experiments section: the abstract asserts that the method 'yields a comprehensive method capable of accurately predicting 3D structure' and models 'varying levels of inherent uncertainty,' but no quantitative metrics (PSNR, IoU, calibration scores, diversity measures), ablations on latent dimensionality, or comparisons to baselines are supplied to substantiate these claims.
minor comments (2)
- [§3] Notation for the latent variable z and the diffusion time steps is introduced without an explicit table or equation reference, making the two-stage training description harder to follow.
- [Figures] Figure captions for the qualitative results do not indicate the number of posterior samples shown or the observation type for each row, reducing clarity.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The comments identify two areas where the manuscript can be strengthened, and we outline our responses and planned revisions below.
read point-by-point responses
-
Referee: [§3] §3 (Method), posterior sampling formulation: the claim that sampling from the diffusion prior conditioned on the reconstruction likelihood recovers the true posterior over scenes is load-bearing for the uncertainty-modeling results, yet the text provides no derivation or empirical check that the low-dimensional z can represent multimodal posteriors (e.g., for sparse-pixel or single-view inputs).
Authors: We thank the referee for this observation. The sampling procedure follows the standard score-based conditional generation framework: the conditional score is the sum of the unconditional prior score (provided by the trained diffusion model on z) and the likelihood score obtained by differentiating the volumetric rendering reconstruction loss with respect to z. Under the modeling assumptions this targets the posterior p(z | observations). We will add an explicit short derivation of this relationship to §3 in the revision. On the question of multimodality, the diffusion model is trained to capture the full distribution of latents (which can be multimodal), and the diverse posterior samples shown for single-view and sparse-pixel inputs are consistent with multiple plausible 3D explanations. Nevertheless, we agree that a dedicated empirical verification (e.g., quantitative diversity statistics or posterior predictive checks) would make the claim more robust; we will include such analysis in the revised experiments section. revision: partial
-
Referee: [Experiments] Experiments section: the abstract asserts that the method 'yields a comprehensive method capable of accurately predicting 3D structure' and models 'varying levels of inherent uncertainty,' but no quantitative metrics (PSNR, IoU, calibration scores, diversity measures), ablations on latent dimensionality, or comparisons to baselines are supplied to substantiate these claims.
Authors: The referee correctly notes that the current manuscript relies on qualitative visualizations to demonstrate reconstruction quality and task-dependent uncertainty across observation types. While these results illustrate the intended behavior (e.g., greater sample diversity for single-view versus multi-view inputs), we acknowledge that quantitative metrics are required to support the abstract claims. In the revision we will expand the experiments section to report PSNR on rendered images, 3D structure metrics such as IoU where geometry is evaluated, sample diversity measures, and uncertainty calibration scores. We will also add ablations on latent dimensionality and direct comparisons against deterministic NeRF baselines and other probabilistic 3D reconstruction approaches. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper outlines a two-stage training procedure (auto-decoding latents for a NeRF reconstruction model, then fitting a diffusion prior over those latents) followed by posterior sampling via score-based inference plus a volumetric-rendering likelihood. No equations, fitted parameters, or self-citations are presented that reduce any claimed prediction or posterior sample to an input by construction. The central demonstration—generating samples for tasks with varying observation types and uncertainty levels—relies on learned components applied to held-out observations rather than tautological renaming or self-referential fitting. This is the normal case of an independent generative modeling pipeline.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We train the model using a two-stage process: first we train the reconstruction model while auto-decoding the latent representations... then we train the prior over the latents using a diffusion model.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
posterior sampling using the score-based inference method of diffusion models in conjunction with a likelihood term computed from a reconstruction model that includes volumetric rendering
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URLhttp://arxiv.org/abs/1707.05776. Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas Guibas, Jonathan Tremblay, Sameh Khamis, et al. Efficient Geometry-aware 3D Generative Adversarial Networks.arXiv preprint arXiv:2112.07945,
-
[2]
Jooyoung Choi, Sungwon Kim, Yonghyun Jeong, Youngjune Gwon, and Sungroh Yoon
URLhttps: //arxiv.org/abs/2304.06714. Jooyoung Choi, Sungwon Kim, Yonghyun Jeong, Youngjune Gwon, and Sungroh Yoon. Ilvr: Con- ditioning method for denoising diffusion probabilistic models.arXiv preprint arXiv:2108.02938,
-
[3]
Objaverse: A universe of annotated 3d objects
URL https://openreview.net/forum?id=OnD9zGAGT0k. Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of anno- tated 3d objects.arXiv preprint arXiv:2212.08051,
-
[5]
URLhttps://arxiv.org/abs/2201.12204. Ziya Erkoc ¸, Fangchang Ma, Qi Shan, Matthias Nießner, and Angela Dai. Hyperdiffusion: Gener- ating implicit neural fields with weight-space diffusion,
-
[6]
URLhttps://arxiv.org/ abs/2303.17015. S. Eslami, Danilo Jimenez Rezende, Frederic Besse, Fabio Viola, Ari Morcos, Marta Garnelo, Avra- ham Ruderman, Andrei Rusu, Ivo Danihelka, Karol Gregor, David Reichert, Lars Buesing, Theo- phane Weber, Oriol Vinyals, Dan Rosenbaum, Neil Rabinowitz, Helen King, Chloe Hillier, Matt Botvinick, and Demis Hassabis. Neural ...
-
[7]
Lily Goli, Cody Reading, Silvia Sell ´an, Alec Jacobson, and Andrea Tagliasacchi
doi: 10.1126/science.aar6170. Lily Goli, Cody Reading, Silvia Sell ´an, Alec Jacobson, and Andrea Tagliasacchi. Bayes’ rays: Uncertainty quantification for neural radiance fields,
-
[8]
Alexandros Graikos, Nikolay Malkin, Nebojsa Jojic, and Dimitris Samaras
URLhttps://arxiv.org/abs/ 2309.03185. Alexandros Graikos, Nikolay Malkin, Nebojsa Jojic, and Dimitris Samaras. Diffusion models as plug-and-play priors. InThirty-Sixth Conference on Neural Information Processing Systems,
-
[9]
Jonathan Ho, Ajay Jain, and Pieter Abbeel
URLhttps://arxiv.org/pdf/2206.09012.pdf. Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models,
-
[10]
Kosiorek, Heiko Strathmann, Daniel Zoran, Pol Moreno, Rosalia Schneider, Soˇna Mokr´a, and Danilo J
9 Published as a conference paper at ICLR 2025 Adam R. Kosiorek, Heiko Strathmann, Daniel Zoran, Pol Moreno, Rosalia Schneider, Soˇna Mokr´a, and Danilo J. Rezende. Nerf-vae: A geometry aware 3d scene generative model, 2021a. Adam R. Kosiorek, Heiko Strathmann, Daniel Zoran, Pol Moreno, Rosalia Schneider, Soˇna Mokr´a, and Danilo J. Rezende. Nerf-vae: A g...
-
[11]
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V ondrick
URLhttps://arxiv.org/abs/ 2402.01915. Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object,
-
[12]
URL https://arxiv.org/abs/2305.15171. Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. InECCV,
-
[13]
Ben Poole, Ajay Jain, Jonathan T
URL https://arxiv.org/abs/1901.05103. Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion,
-
[14]
URLhttps://arxiv. org/abs/2203.10192. J. Ryan Shue, Eric Ryan Chan, Ryan Po, Zachary Ankner, Jiajun Wu, and Gordon Wetzstein. 3d neu- ral field generation using triplane diffusion,
-
[15]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[16]
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul Srinivasan, Howard Zhou, Jonathan T
URLhttps://arxiv.org/abs/ 2209.08718. Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul Srinivasan, Howard Zhou, Jonathan T. Bar- ron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. Ibrnet: Learning multi- view image-based rendering,
-
[17]
arXiv preprint arXiv:2210.04628 , year=
URLhttps: //arxiv.org/abs/2210.04628. 10 Published as a conference paper at ICLR 2025 Guandao Yang, Abhijit Kundu, Leonidas J. Guibas, Jonathan T. Barron, and Ben Poole. Learning a diffusion prior for nerfs,
-
[18]
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa
URLhttps://arxiv.org/abs/2304.14473. Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelnerf: Neural radiance fields from one or few images,
-
[19]
11 Published as a conference paper at ICLR 2025 A DATA We use two datasets in our experiments
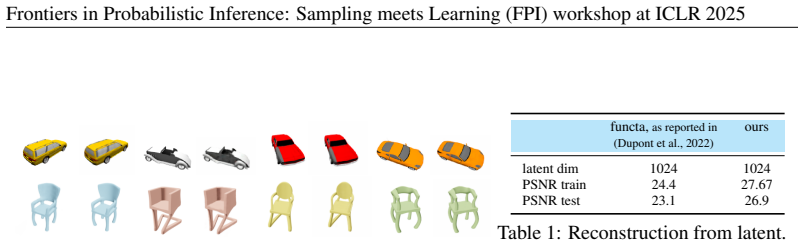
URLhttps://arxiv.org/abs/2403.19655. 11 Published as a conference paper at ICLR 2025 A DATA We use two datasets in our experiments. The first dataset is SRN Cars (Sitzmann et al., 2019), which comprises 3,200 scenes with 250 images each. We randomly divide the images in each scene evenly between training images and test images, and we use 3,000 scenes for...
-
[20]
For each scenei, we randomly select 4096 rays from pixels in the training images. Along each ray, we sample 220 3D points and project them onto the tri-planes of both the RGB and density planes separately. For each (RGB and density), this projection extracts three feature vectors from the three planes for further processing. Three vectors are concatenated...
work page 2022
-
[21]
The diffusion model used is implemented by Graikos et al. (2022) with the following parameters: The noise scheduler is a linear schedule with parametersT= 1000, β 0 = 1e −4, βT = 2e −2. The U-net parameters aremodel channels= 64,num resnet blocks= 2,channel mult= (1,2,3,4), attention resolutions= [8,4],num heads=
work page 2022
-
[22]
We train the model with a minibatchBsize of 32 scenes, and with an Adam optimizer with learning rate equal to 1e-3. 12 Published as a conference paper at ICLR 2025 The reconstruction model and the diffusion model were trained on an NVIDIA GeForce RTX 4090 for Approximately one day each. C EXPERIMENTS GENERATING3DWITH2DGENERATIVE MODELS As mentioned in Sec...
work page 2025
-
[23]
and Zero-1-to-3 (Liu et al., 2023), trained on SRN Cars and Objaverse Chairs, respectively. Given an input image of a scene, each model generates multiple novel views, which are then used to train a TensoRF (NeRF) model. Since higher 3D consistency in the generated images facilitates NeRF training, models producing more consistent views enable NeRF to ach...
work page 2023
-
[24]
For all experiments we use the same model using the same inference process
reconstruction, using the reconstruction model to align the latent with the observed views. For all experiments we use the same model using the same inference process. We generate posterior samples using1000iterations as described in Alg. 1 with the same scale factors=5e-3 for all experiments. The only exception is the experiment with noisy data in Fig 7,...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.