Recognition: 2 theorem links
· Lean TheoremClinicalBench: Stress-Testing Assertion-Aware Retrieval for Cross-Admission Clinical QA on MIMIC-IV
Pith reviewed 2026-05-13 03:47 UTC · model grok-4.3
The pith
Assertion-aware retrieval from knowledge graphs improves clinical QA accuracy by 22 percentage points over dense retrieval on MIMIC-IV notes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
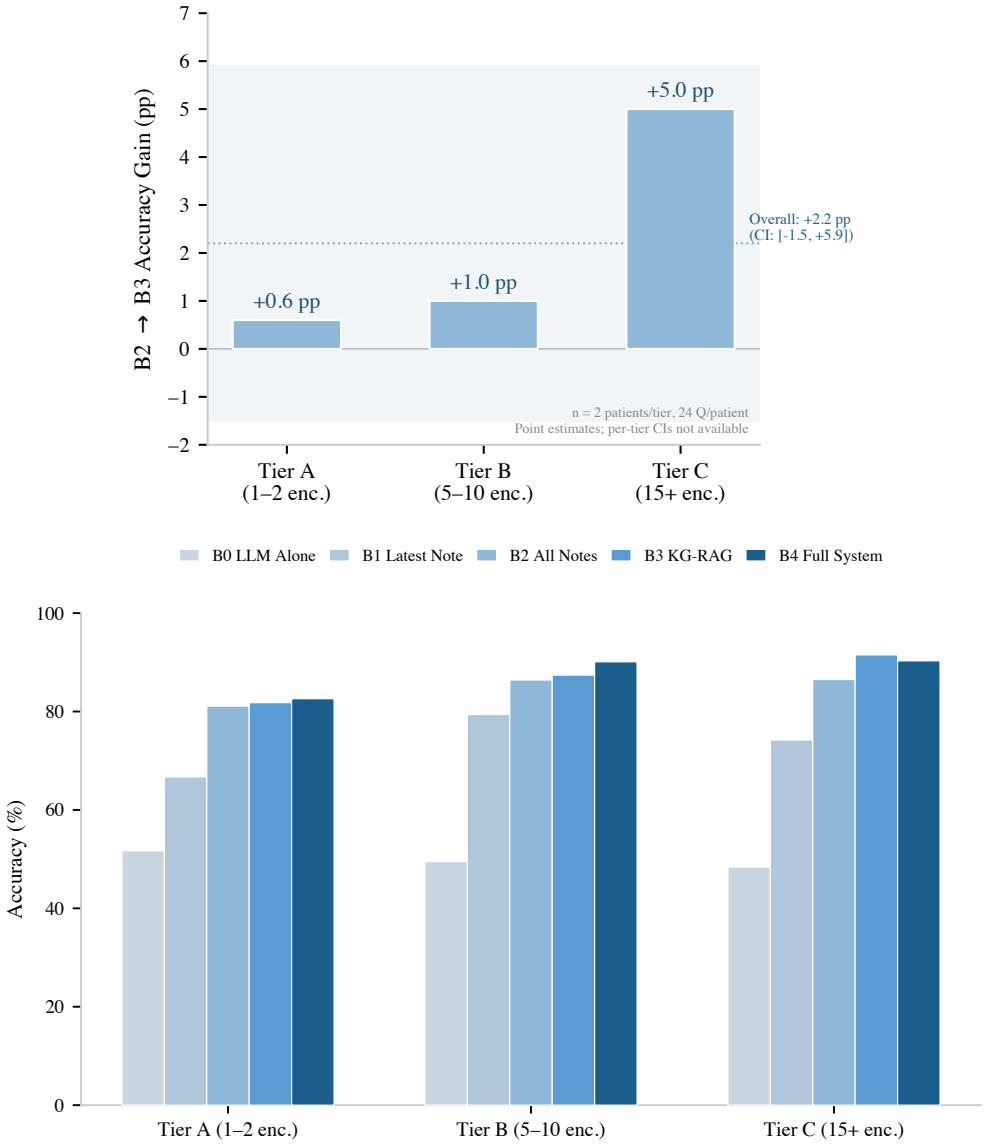
EpiKG attaches an assertion label and temporality tag to every fact in a patient knowledge graph and routes retrieval according to question intent. Intent-aware KG-RAG improves over a Contriever dense-RAG baseline by 8.84 percentage points on the main endpoint and by 12.43 points under oracle intent. The author-blind primary endpoint on 50 unanimous-strict items rated by two external physicians shows a +22.0 percentage point lift (95 percent Newcombe CI [+5.1, +31.5], p=0.0192). Physician review found 56 percent of auto-generated reference answers defective.
What carries the argument
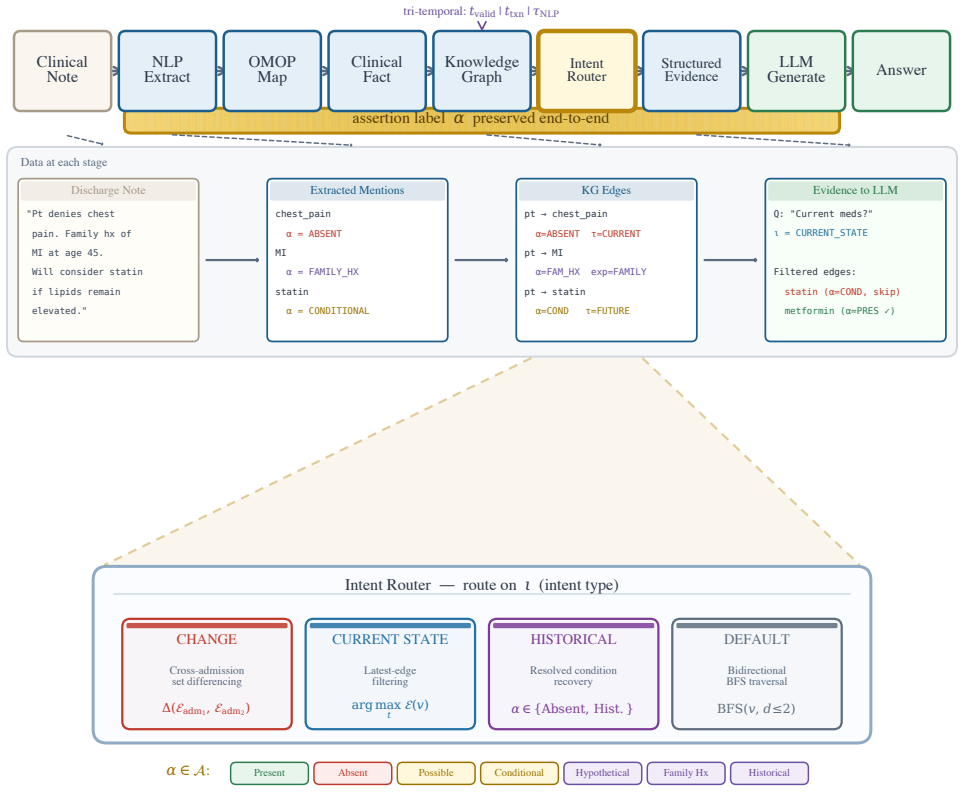
EpiKG, the patient knowledge graph that labels each fact with an assertion and temporality tag and routes retrieval by question intent.
If this is right
- Retrieval that ignores assertion and temporality produces answers contradicted by negation or wrong time in EHR notes.
- The accuracy gain is reproducible with a deterministic keyword proxy and holds directionally under three-rater majority.
- Performance improvement shrinks as the standalone LLM baseline rises, with a strong negative correlation across models.
- Over half of pipeline-generated reference answers contain defects that require physician adjudication for usable benchmarks.
Where Pith is reading between the lines
- Assertion-aware routing could help question answering in other domains that routinely handle negated or time-bound facts.
- The public release of ClinicalBench and the EpiKG outputs lets other groups test new retrieval methods on the same clinical questions.
- As language models continue to improve, specialized retrieval may become less decisive unless the benchmark expands to harder cases.
Load-bearing premise
The nine assertion-sensitive categories and the 43 selected MIMIC-IV patients capture the main real-world failure modes of clinical QA, and the external physician ratings on the 50-item subset are sufficiently consistent and representative.
What would settle it
A replication study on a new set of patients or a different hospital system that finds no significant accuracy difference between assertion-aware KG-RAG and dense retrieval would falsify the central result.
Figures





read the original abstract
Reasoning benchmarks measure clinical performance on clean inputs. We evaluate the step before reasoning: retrieval over real EHR notes, where negation, temporality, and family-versus-patient attribution can flip a correct answer to a wrong one. EpiKG carries an assertion label and a temporality tag with every fact in a patient knowledge graph, then routes retrieval by question intent. ClinicalBench is a 400-question test over 43 MIMIC-IV patients across 9 assertion-sensitive categories. A 7-condition ablation tests each piece of EpiKG across six LLMs (Claude Opus 4.6, GPT-OSS 20B, MedGemma 27B, Gemma 4 31B, MedGemma 1.5 4B, Qwen 3.5 35B). Three physicians blindly adjudicated 100 paired items. The author-blind primary endpoint, leave-author-out paired exact McNemar on 50 unanimous-strict items rated by two external physicians, yields +22.0 percentage points (95 percent Newcombe CI [+5.1, +31.5], p=0.0192). The architectural novelty, intent-aware KG-RAG over a Contriever dense-RAG baseline (C2b to C4g_kw on the change-excluded n=362 endpoint), is +8.84 percentage points (paired McNemar p=1.79e-3); +12.43 percentage points under oracle intent. Sensitivities agree directionally: three-rater physician majority +24.0 percentage points (subject to single-author circularity); deterministic keyword reproducibility proxy +39.5 percentage points. Across the six models, the gain shrinks as the LLM-alone baseline rises (beta=-1.123, r=-0.921, p=0.009). With n=6 this looks more like regression to the mean than encoding substituting for model size. Physician adjudication identified 56 percent of auto-generated reference answers as defective, a methodological finding indicating that NLP-pipeline clinical-QA benchmarks require physician adjudication to be usable. ClinicalBench, the frozen evaluator, three-rater adjudication data, and the EpiKG output stack are publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EpiKG, a patient knowledge graph that augments facts with assertion labels and temporality tags, and ClinicalBench, a 400-question cross-admission QA benchmark over 43 MIMIC-IV patients spanning 9 hand-selected assertion-sensitive categories. It evaluates an intent-aware KG-RAG retrieval method against a Contriever dense-RAG baseline across six LLMs, with the primary author-blind endpoint being a leave-author-out paired exact McNemar test on 50 unanimous-strict items (from 100 physician-adjudicated pairs) showing +22.0 percentage points improvement (95% Newcombe CI [+5.1, +31.5], p=0.0192). Additional results include +8.84 pp over baseline (p=1.79e-3) on the n=362 change-excluded set, +12.43 pp under oracle intent, directional agreement in sensitivities, a regression of gains versus baseline performance across models, and the finding that 56% of auto-generated references are defective per physician review. The benchmark, adjudication data, and EpiKG outputs are released publicly.
Significance. If the primary statistical result holds after addressing subset-selection concerns, the work demonstrates that assertion and temporality handling in retrieval can meaningfully improve clinical QA performance on real EHR notes, where standard dense retrieval often fails on negation, family history, and temporal distinctions. The multi-LLM ablation, leave-author-out design, external rater blinding, and public release of the frozen evaluator plus adjudication data are strengths that support reproducibility and extension. The 56% defective-reference rate is a useful methodological observation for the field. However, the narrow patient and category scope plus the small n=6 for the regression analysis limit broader claims about capturing main real-world failure modes.
major comments (2)
- [Primary endpoint description] Primary endpoint (abstract and Results): The +22.0 pp headline result with p=0.0192 is computed exclusively on the 50 unanimous-strict items from the 100 adjudicated pairs. The manuscript must explicitly document whether this unanimous-strict filter was pre-specified in the analysis plan or applied after inspecting rater disagreements and model outputs; if post-hoc, a sensitivity analysis on the full 100 items (or the entire 400-question set) is required to rule out selection bias that could inflate effect size and significance.
- [Regression-to-the-mean analysis] Regression analysis (Results): The claim that gains shrink with rising LLM-alone baseline (beta=-1.123, r=-0.921, p=0.009) rests on only six models. With n=6 this correlation is underpowered and sensitive to model selection; the interpretation as 'regression to the mean' should be presented with stronger caveats and perhaps supplemented by additional models or a different analysis.
minor comments (1)
- [Abstract and Methods] The abstract and text use abbreviations such as 'C2b to C4g_kw' and 'EpiKG' without immediate definition on first use; ensure all acronyms and condition labels are expanded at first mention for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing statistical transparency and appropriate interpretation of exploratory analyses. We address each major comment below with specific revisions to the manuscript.
read point-by-point responses
-
Referee: [Primary endpoint description] Primary endpoint (abstract and Results): The +22.0 pp headline result with p=0.0192 is computed exclusively on the 50 unanimous-strict items from the 100 adjudicated pairs. The manuscript must explicitly document whether this unanimous-strict filter was pre-specified in the analysis plan or applied after inspecting rater disagreements and model outputs; if post-hoc, a sensitivity analysis on the full 100 items (or the entire 400-question set) is required to rule out selection bias that could inflate effect size and significance.
Authors: We acknowledge that the current manuscript does not explicitly state the pre-specification status of the unanimous-strict filter. The filter was applied to restrict the primary endpoint to items with full rater agreement in order to reduce adjudication noise, but to fully address the concern we will revise the Methods section to document the adjudication protocol and analysis plan. We will also add a sensitivity analysis reporting the paired McNemar results on the full 100 adjudicated pairs and on the entire 400-question set. These changes will be incorporated in the revised version. revision: yes
-
Referee: [Regression-to-the-mean analysis] Regression analysis (Results): The claim that gains shrink with rising LLM-alone baseline (beta=-1.123, r=-0.921, p=0.009) rests on only six models. With n=6 this correlation is underpowered and sensitive to model selection; the interpretation as 'regression to the mean' should be presented with stronger caveats and perhaps supplemented by additional models or a different analysis.
Authors: We agree that n=6 renders the regression underpowered and sensitive to model choice. In the revision we will strengthen the caveats in the Results and Discussion sections, explicitly noting the small sample size, the exploratory nature of the analysis, and that the observed negative correlation should be viewed as suggestive rather than conclusive evidence of regression to the mean. We will also add a leave-one-out robustness check on the correlation coefficient. While expanding the model set would be desirable, the current six models already span a wide range of sizes and families; we therefore treat this as a partial revision focused on clearer qualification of the finding. revision: partial
Circularity Check
Minor circularity flagged by paper in one sensitivity analysis; primary endpoint uses external raters and is independent.
specific steps
-
other
[Abstract]
"three-rater physician majority +24.0 percentage points (subject to single-author circularity)"
The paper explicitly flags this sensitivity result as subject to single-author circularity, indicating the three-rater adjudication process incorporates the author's own judgments and thereby reduces the independence of that particular evaluation.
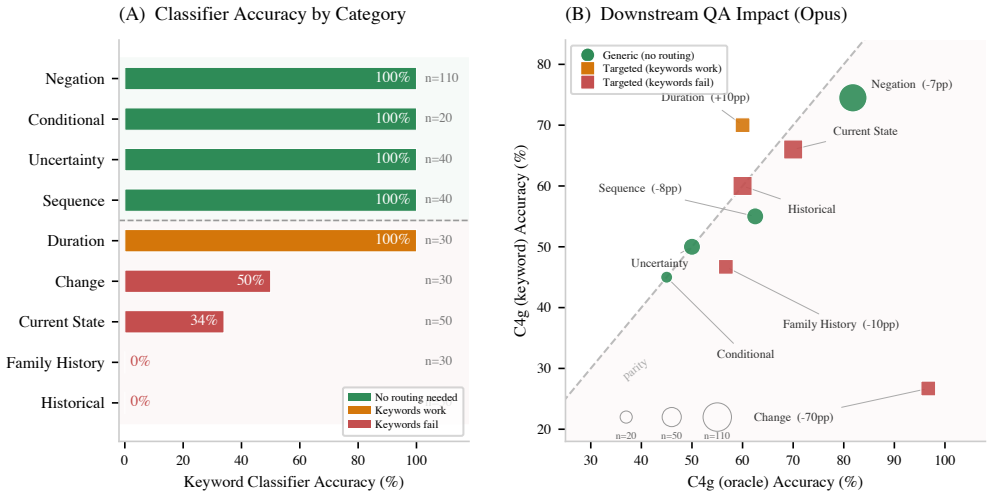
full rationale
The paper's central claim (leave-author-out McNemar on 50 unanimous-strict items by two external physicians) relies on independent external adjudication and is not reduced to the author's inputs by construction. The 56% defective-reference observation is presented as a methodological finding rather than a derived prediction. No self-citations, fitted inputs renamed as predictions, ansatzes, or uniqueness theorems appear. The paper itself explicitly notes the three-rater majority sensitivity as subject to single-author circularity, which is minor and non-load-bearing for the headline result. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MIMIC-IV patient notes contain the full range of negation, temporality, and attribution phenomena that cause clinical QA errors in practice
invented entities (1)
-
EpiKG
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EpiKG carries an assertion label and a temporality tag with every fact... routes retrieval by question intent... 7-value assertion taxonomy α ∈ {Pres., Abs., Poss., Cond., Hypo., Fam.Hx., Hist.}
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
leave-author-out paired exact McNemar on 50 unanimous-strict items... +22.0 percentage points
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Towards expert-level medical question answering with large language models.Nature, 620: 399–404, 2023. doi: 10.1038/s41586-023-06291-2
-
[2]
Capabilities of gemini models in medicine.arXiv preprint arXiv:2404.18416.2024
Khaled Saab, Tao Tu, Xavier Amatriain, et al. Capa- bilitiesofGeminimodelsinmedicine.arXivpreprint arXiv:2404.18416, 2024
-
[3]
Towards conversational diagnostic AI.Nature, 2024
Tao Tu, Anil Palepu, Mike Schaekermann, Khaled Saab, Jan Freyberg, Ryutaro Tanno, Amy Wang, Brenna Li, Mohamed Amin, Nenad Tober, et al. Towards conversational diagnostic AI.Nature, 2024
work page 2024
-
[4]
South, Shuying Shen, and Scott L
Özlem Uzuner, Brett R. South, Shuying Shen, and Scott L. DuVall. 2010 i2b2/VA challenge on con- cepts, assertions, and relations in clinical text.Jour- naloftheAmericanMedicalInformaticsAssociation, 18(5):552–556, 2011
work page 2010
-
[5]
Beyond negation detection: Comprehensive assertion detection models for clinical NLP
VeyselKocaman,YigitGul,M.AytugKaya,Hasham Ul Haq, Mehmet Butgul, Cabir Celik, and David Talby. Beyond negation detection: Comprehensive assertion detection models for clinical NLP. In Text2Story Workshop at European Conference on Information Retrieval (ECIR), 2025
work page 2025
-
[6]
OMOP common data model v5.4.Observational Health Data Sciences and In- formatics, 2024
OHDSI Collaborative. OMOP common data model v5.4.Observational Health Data Sciences and In- formatics, 2024
work page 2024
-
[7]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge et al. From local to global: A graph RAG approach to query-focused summarization. arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
GFM-RAG: Graph foundation model for retrieval augmented generation
Tianjun Luo et al. GFM-RAG: Graph foundation model for retrieval augmented generation. InAd- vances in Neural Information Processing Systems, 2025
work page 2025
-
[9]
KARE: Knowledge graph aug- mented reasoning via llms for clinical decision sup- port
Peng Jiang et al. KARE: Knowledge graph aug- mented reasoning via llms for clinical decision sup- port. InInternational Conference on Learning Rep- resentations, 2025
work page 2025
-
[10]
Junde Wu et al. Medical-Graph-RAG: Towards safe medical large language model via graph retrieval- augmented generation. InProceedings of the 63rd AnnualMeetingoftheAssociationforComputational Linguistics, 2025
work page 2025
-
[11]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beau- vais,JackRyan,andDanielChalef. Zep: Atemporal knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Marco Postiglione, Daniel Bean, Zeljko Kraljevic, Richard Dobson, and Vincenzo Moscato. Predicting future disorders via temporal knowledge graphs and medicalontologies.IEEEJournalofBiomedicaland Health Informatics, 28(7):4238–4248, 2024. doi: 10.1109/JBHI.2024.3390419
-
[13]
OpenAI. HealthBenchProfessional: Evaluatingclin- ical reasoning in large language models.https:// openai.com/research/healthbench,2026. Ac- cessed 26 April 2026
work page 2026
-
[14]
Applied Sciences, 11(14):6421, 2021
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng,HanyiFang,andPeterSzolovits.Whatdisease 15 does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14):6421, 2021. doi: 10.3390/ app11146421
work page 2021
-
[15]
MIRAGE: Medical infor- mation retrieval-augmented generation evaluation
Guangzhi Xiong et al. MIRAGE: Medical infor- mation retrieval-augmented generation evaluation. InFindings of the Association for Computational Linguistics: ACL, 2024
work page 2024
-
[16]
emrQA: A large corpus for question answering on electronic medical records
Anusri Pampari, Preethi Raghavan, Jennifer Liang, and Jian Peng. emrQA: A large corpus for question answering on electronic medical records. InPro- ceedings of the Conference on Empirical Methods in Natural Language Processing, pages 2357–2368, 2018
work page 2018
-
[17]
Wei Chen et al. Multi-LLM KG-RAG: End-to- end clinical knowledge graph construction.arXiv preprint arXiv:2601.01844, 2026
-
[18]
AutoRD:Anautomaticandend-to-end systemforrarediseaseknowledgegraphconstruction
LangLietal. AutoRD:Anautomaticandend-to-end systemforrarediseaseknowledgegraphconstruction. JMIR Medical Informatics, 12, 2024
work page 2024
-
[19]
Rakhilya Lee Mekhtieva, Brandon Forbes, Dalal Alrajeh, Brendan Delaney, and Alessandra Russo. RECAP-KG:MiningknowledgegraphsfromrawGP notes for remote COVID-19 assessment in primary care.arXiv preprint arXiv:2306.17175, 2023
-
[20]
Chapman, Will Bridewell, Paul Hanbury, Gregory F
Wendy W. Chapman, Will Bridewell, Paul Hanbury, Gregory F. Cooper, and Bruce G. Buchanan. A simple algorithm for identifying negated findings and diseases in discharge summaries.Journal of Biomedical Informatics, 34(5):301–310, 2001
work page 2001
-
[21]
Dowling, Tyler Thornblade, and Wendy W
Henk Harkema, John N. Dowling, Tyler Thornblade, and Wendy W. Chapman. ConText: An algorithm for determining negation, experiencer, and temporal status from clinical reports.Journal of Biomedical Informatics, 42(5):839–851, 2009
work page 2009
-
[22]
Claude E. Shannon. A mathematical theory of com- munication.Bell System Technical Journal, 27(3): 379–423, 1948
work page 1948
-
[23]
Yixing Jiang, Kameron C. Black, Gloria Geng, Danny Park, James Zou, Andrew Y. Ng, and JonathanH.Chen. MedAgentBench: AvirtualEHR environment to benchmark medical LLM agents. NEJM AI, 2(9), 2025. doi: 10.1056/AIdbp2500144
-
[24]
Alistair E.W. Johnson, Lucas Bulgarelli, Lu Shen, etal.MIMIC-IV,afreelyaccessibleelectronichealth record dataset.Scientific Data, 10:1, 2023
work page 2023
-
[25]
Tibshirani.An Intro- duction to the Bootstrap
Bradley Efron and Robert J. Tibshirani.An Intro- duction to the Bootstrap. Chapman and Hall/CRC, 1993
work page 1993
-
[26]
A. Colin Cameron and Douglas L. Miller. A practi- tioner’s guide to cluster-robust inference.Journal of Human Resources, 50(2):317–372, 2015
work page 2015
-
[27]
Quinn McNemar. Note on the sampling error of the difference between correlated proportions or percentages.Psychometrika, 12(2):153–157, 1947
work page 1947
-
[28]
J. Richard Landis and Gary G. Koch. The mea- surement of observer agreement for categorical data. Biometrics, 33(1):159–174, 1977
work page 1977
-
[29]
Valid post-selection infer- ence.Annals of Statistics, 41(2):802–837, 2013
Richard Berk, Lawrence Brown, Andreas Buja, Kai Zhang, and Linda Zhao. Valid post-selection infer- ence.Annals of Statistics, 41(2):802–837, 2013
work page 2013
-
[30]
Andre Bittar, Sumithra Velupillai, Johnny Downs, Rosemary Sedgwick, and Rina Dutta. Portability of natural language processing methods to detect suicidality from unstructured clinical text in us and uk electronic health records.Journal of the Amer- ican Medical Informatics Association Open, 6(3): ooad078, 2023. doi: 10.1093/jamiaopen/ooad078
-
[31]
Nigam H. Shah, John D. Halamka, Suchi Saria, Michael Pencina, Troy Tazbaz, Micky Tripathi, Al- ison Callahan, Hailey Hildahl, and Brian Ander- son. A nationwide network of health ai assurance laboratories.JAMA, 331(3):245–249, 2024. doi: 10.1001/jama.2023.26930
-
[32]
Peter J. Embi. Algorithmovigilance—advancing methods to analyze and monitor artificial intelligence–driven health care for effectiveness and equity.JAMA Network Open, 4(4):e214622, 2021. doi: 10.1001/jamanetworkopen.2021.4622
-
[33]
[dataset] ClinicalBench: Assertion- sensitive clinical question answering bench- mark
Alex Stinard. [dataset] ClinicalBench: Assertion- sensitive clinical question answering bench- mark. https://huggingface.co/datasets/ alexstinard/epikg-clinicalbench,2026. Ac- cessed 25 April 2026
work page 2026
-
[34]
Werner Ceusters and Barry Smith. Aboutness: To- wards foundations for the information artifact on- tology.International Conference on Biomedical Ontology, 2015. 16
work page 2015
-
[35]
Snodgrass.Developing Time-Oriented Database Applications in SQL
Richard T. Snodgrass.Developing Time-Oriented Database Applications in SQL. Morgan Kaufmann, 2000
work page 2000
-
[36]
James F. Allen. Maintaining knowledge about tem- poral intervals.Communications of the ACM, 26 (11):832–843, 1983
work page 1983
-
[37]
Fei Li, Jianfu Hong, Cui Tao, et al. TEO: A time event ontology for clinical narratives.Journal of the American Medical Informatics Association, 27(10): 1560–1568, 2020
work page 2020
-
[38]
Tem- poral cohort logic.AMIA Annual Symposium Pro- ceedings, 2022:1237–1246, 2023
YanHuang,XiaojinLi,andGuo-QiangZhang. Tem- poral cohort logic.AMIA Annual Symposium Pro- ceedings, 2022:1237–1246, 2023
work page 2022
-
[39]
Doctorrag: Medical rag emulating doctor-like reasoning
Yifan Lu, Tianyu Fu, et al. Doctorrag: Medical rag emulating doctor-like reasoning. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[40]
Yusheng Wang et al. MedRAG: Enhancing medical diagnosis through retrieval-augmented generation with knowledge graph-elicited reasoning.Proceed- ings of The Web Conference, 2025
work page 2025
- [41]
-
[42]
Graph retrieval-augmented generation: A survey.ACM Transactions on Information Systems,
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, HaizhouShi,ChuntaoHong,YanZhang,andSiliang Tang. Graph retrieval-augmented generation: A survey.ACM Transactions on Information Systems,
-
[43]
doi: 10.1145/3777378
-
[44]
Lang Cao, Qingyu Chen, and Yue Guo. EHR-RAG: Bridging long-horizon structured electronic health records and large language models via enhanced retrieval-augmented generation.arXiv preprint arXiv:2601.21340, 2026
-
[45]
Patterson, Matthew Churpek, Tim- othy Miller, Dmitriy Dligach, and Majid Afshar
Yanjun Gao, Ruizhe Li, Emma Croxford, John Caskey, Brian W. Patterson, Matthew Churpek, Tim- othy Miller, Dmitriy Dligach, and Majid Afshar. Leveraging medical knowledge graphs into large language models for diagnosis prediction: Design and application study.JMIR AI, 4(1):e58670, 2025. doi: 10.2196/58670
-
[46]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, andEdouardGrave. Unsuperviseddenseinformation retrieval with contrastive learning.Transactions on Machine Learning Research, 2022
work page 2022
-
[47]
YifanPeng,XiaosongWang,LeLu,Mohammadhadi Bagheri,RonaldSummers,andZhiyongLu. NegBio: Ahigh-performancetoolfornegationanduncertainty detection in radiology reports.AMIA Summits on Translational Science Proceedings, 2018. 17 A Notation Summary Symbol Meaning 𝛼∈ AAssertion label (7 values, Eq. 1) 𝝉𝑣 Valid time (event date, valid from/to) 𝝉𝑡 Transaction time ...
-
[48]
Reference answers systematically wrong for medication change questions(103 notes mentioning reference- answer issues): Every reference answer in the change category conflates inpatient medication orders (heparin, IV antibiotics, CIWA protocol) with discharge medications
-
[49]
Zero C4g items received this complaint
C1 hallucinates from limited context(15 notes, exclusively C1): Without retrieval, C1 fabricates admission IDs, medication names, and clinical scenarios. Zero C4g items received this complaint
-
[50]
NLP assertion classifier propagates errors(8 notes): Boilerplate discharge instructions (“call if fever>101.5”) tagged as clinical findings; “h/o recently diagnosed metastatic cancer” tagged as historical
-
[51]
Safety-critical errors(10 items flagged as potentially harmful): Code status errors (model “hallucinates DNR confirmation” when chart says full code), active cancer missed from medication list, anticoagulation misclassified
-
[52]
Modelpraisedwhenreferenceanswerswerewrong(63notes): Reviewernotedthemodelgaveclinicallycorrect answers that the automated benchmark reference penalized. X.5 Reference Answer Version History The ClinicalBench reference answers have undergone iterative refinement: • v1 (auto-generated reference set): Reference answers created by LLM from MIMIC-IV notes via ...
-
[53]
NLP assertion classifier error(28 questions, 36%): The dominant failure. Manifests as: “history of heart failure” →“heartfailureisresolved”(clinicalidiommeansactivechroniccondition);“edema,likelyduetononcompliance” → “edema is uncertain” (causal vs. existential uncertainty conflation); experiencer tag reversal (patient’s atrial fibrillation labeled as fam...
-
[54]
Wrong answer / inverted truth(16 questions, 21%): The reference answer states the opposite of the chart. Example: the reference says pitting edema is absent when PE documents “2+ pitting edema bilaterally.”
-
[55]
Non-clinical entity extraction(11 questions, 14%): NLP extracted boilerplate (“call if fever>101”), devices (Foley catheter as diagnosis), lab values (blood sugar as diagnosis), or section headers (“Allergies” as medical condition)
-
[56]
discharge medications, or admission med-rec vs
Medication list conflation(10 questions, 13%): Change questions compared wrong lists—inpatient orders (heparin, IV antibiotics) vs. discharge medications, or admission med-rec vs. discharge list. PRN-only medications (CIWA Valium) counted as prescribed
-
[57]
Fabricated temporal relationship(8 questions, 10%): Sequence questions claimed ordering not supported by the chart—both conditions in the same admission with no temporal anchoring, or based on NLP-extracted entities from negated text. X.7 Impact on Reported Numbers Because the detected defects are question-level rather than condition-specific, they are le...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.