Recognition: 2 theorem links
· Lean TheoremUnlocking LLM Creativity in Science through Analogical Reasoning
Pith reviewed 2026-05-13 01:49 UTC · model grok-4.3
The pith
Analogical reasoning enables LLMs to generate more diverse and novel solutions for open-ended scientific problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
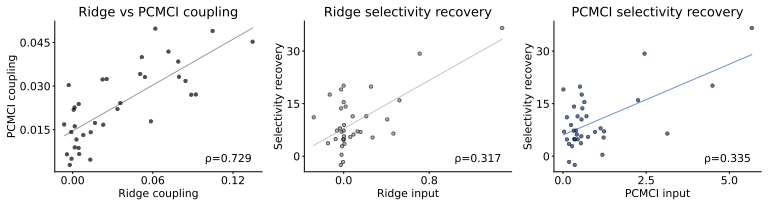
Analogical reasoning (AR) generates analogies to cross-domain problems based on shared relational structure, then uses those analogies to search for novel solutions. Compared to baselines, AR improves solution diversity metrics by 90-173 percent, produces novel solutions over 50 percent of the time versus as little as 1.6 percent for baselines, and yields high-quality analogies. When the resulting approaches are implemented on four biomedical problems, they deliver consistent quantitative gains including a nearly 13-fold improvement on distributional metrics for perturbation effect prediction, better AUPRC for cell-cell communication, high correlation with published brain region interaction,
What carries the argument
Analogical reasoning (AR), which creates cross-domain analogies based on shared relational structure and then applies them to search for novel solutions in the target scientific problem.
Load-bearing premise
Analogies produced by the LLM reliably reflect true shared relational structures across domains and translate into genuinely novel, high-quality scientific solutions rather than superficial or invalid ones.
What would settle it
A controlled experiment in which domain experts rate the generated analogies as lacking valid relational similarity or in which AR-generated solutions show no performance advantage over baselines when evaluated on independent, held-out biomedical datasets.
Figures








read the original abstract
Autonomous science promises to augment scientific discovery, particularly in complex fields like biomedicine. However, this requires AI systems that can consistently generate novel and diverse solutions to open-ended problems. We evaluate LLMs on the task of open-ended solution generation and quantify their tendency to mode collapse into low-diversity generations. To mitigate this mode collapse, we introduce analogical reasoning (AR) as a new approach to solution generation. AR generates analogies to cross-domain problems based on shared relational structure, then uses those analogies to search for novel solutions. Compared to baselines, AR discovers significantly more diverse generations (improving solution diversity metrics by 90-173%), generates novel solutions over 50% of the time (compared to as little as 1.6% for baselines), and produces high-quality analogies. To validate the real-world feasibility of AR, we implement AR-generated solutions across four biomedical problems, yielding consistent quantitative gains. AR-generated approaches achieve a nearly 13-fold improvement on distributional metrics for perturbation effect prediction, outperform all baselines on AUPRC when predicting cell-cell communication, infer brain region interactions with a high Spearman correlation ($\rho$=0.729) to published methods, and establish state-of-the-art performance on 2 datasets for oligonucleotide property prediction. The novel and diverse solutions produced by AR can be used to augment the search space of existing solution generation methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs exhibit mode collapse in open-ended scientific solution generation, producing low-diversity outputs. It introduces Analogical Reasoning (AR), which generates cross-domain analogies based on shared relational structure and transfers them to the target problem to yield novel solutions. Evaluations on four tasks report 90-173% gains in diversity metrics, >50% novelty rate (vs. 1.6% baselines), high-quality analogies, and real-world biomedical validation with a 13-fold improvement on perturbation effect prediction metrics, superior AUPRC on cell-cell communication, Spearman ρ=0.729 on brain interactions, and SOTA on two oligonucleotide datasets.
Significance. If the central attribution to relational structure mapping holds, the work offers a promising direction for mitigating creativity limitations in LLMs for autonomous science, with concrete empirical support from multiple quantitative metrics and direct implementation on biomedical problems. Strengths include the reproducible performance claims across tasks and the attempt to link LLM outputs to downstream scientific utility.
major comments (3)
- [§4] §4 (Evaluation setup): Baseline implementations lack sufficient detail on prompt length, number of reasoning steps, temperature, and few-shot examples. Without these controls or an ablation comparing AR to other multi-step open-ended prompts of matched complexity, the diversity (90-173%) and novelty (>50%) gains cannot be confidently attributed to the analogical mechanism rather than prompting format differences.
- [§3.1] §3.1 (Analogy generation): The description states that analogies are generated 'based on shared relational structure,' but no independent verification is provided (e.g., human-rated mapping quality, predicate alignment score, or contrast against surface-similarity baselines). This leaves open the possibility that gains arise from increased textual variation rather than structure-mapping as claimed.
- [§5.1] §5.1 (Biomedical results): No statistical significance tests, confidence intervals, or multiple-run variance are reported for the 13-fold distributional metric improvement or other gains. This is load-bearing for the claim of consistent outperformance, as single-run results on LLM outputs are known to be sensitive to sampling.
minor comments (2)
- [Abstract] Abstract: The four biomedical problems are listed via their metrics but not named explicitly; adding the problem names (e.g., perturbation prediction, cell-cell communication) would improve clarity.
- [§4.2] Notation: The diversity and novelty metrics are introduced without a dedicated equation or table defining their exact formulas (e.g., how 'novel' is operationalized against a reference set), which could be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will incorporate revisions to improve clarity, reproducibility, and evidential support for our claims.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation setup): Baseline implementations lack sufficient detail on prompt length, number of reasoning steps, temperature, and few-shot examples. Without these controls or an ablation comparing AR to other multi-step open-ended prompts of matched complexity, the diversity (90-173%) and novelty (>50%) gains cannot be confidently attributed to the analogical mechanism rather than prompting format differences.
Authors: We agree that the current description of baselines is insufficient for full reproducibility and attribution. In the revised manuscript, we will expand §4 to include complete prompt templates, exact token lengths, number of reasoning steps, temperature settings (0.7 across methods), and few-shot counts (3 examples for all conditions). We will also add a new ablation subsection comparing AR against other multi-step open-ended prompting strategies (e.g., extended chain-of-thought and iterative self-refinement) that are matched in total prompt length and number of generation steps. This will allow readers to isolate the contribution of relational structure mapping from general prompting effects. revision: yes
-
Referee: [§3.1] §3.1 (Analogy generation): The description states that analogies are generated 'based on shared relational structure,' but no independent verification is provided (e.g., human-rated mapping quality, predicate alignment score, or contrast against surface-similarity baselines). This leaves open the possibility that gains arise from increased textual variation rather than structure-mapping as claimed.
Authors: We acknowledge that the manuscript currently supports the relational-structure claim primarily through downstream performance metrics rather than direct verification of the analogies themselves. To strengthen this, we will add a human evaluation protocol in the revised §3.1 in which independent annotators rate a sample of generated analogies on relational mapping fidelity and relevance (using a standardized rubric). We will also introduce a surface-similarity baseline that constructs analogies via lexical overlap instead of structure mapping, allowing direct comparison of diversity and novelty outcomes. These additions will provide independent evidence that the observed gains derive from the intended mechanism. revision: yes
-
Referee: [§5.1] §5.1 (Biomedical results): No statistical significance tests, confidence intervals, or multiple-run variance are reported for the 13-fold distributional metric improvement or other gains. This is load-bearing for the claim of consistent outperformance, as single-run results on LLM outputs are known to be sensitive to sampling.
Authors: We agree that the absence of statistical reporting and variance estimates limits confidence in the biomedical results. In the revised manuscript, we will re-execute all four biomedical experiments across at least five independent runs with different random seeds. We will report means and standard deviations for all metrics, 95% confidence intervals, and results of appropriate statistical tests (paired t-tests or Wilcoxon signed-rank tests with Bonferroni correction) comparing AR against baselines. These changes will be added to §5.1 and the corresponding figures/tables. revision: yes
Circularity Check
No circularity: empirical method validated against external baselines
full rationale
The paper introduces analogical reasoning (AR) as a prompting-based approach to increase diversity and novelty in LLM solution generation, then reports direct empirical gains (diversity +90-173%, novelty >50%, biomedical task improvements) measured against independent baselines and external published methods. No derivations, equations, fitted parameters, or self-citations are invoked to establish the central claims; results rest on falsifiable comparisons outside the paper's own definitions or inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can generate meaningful cross-domain analogies based on shared relational structure when prompted appropriately
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AR generates analogies to cross-domain problems based on shared relational structure, then uses those analogies to search for novel solutions.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We utilize the definition of analogy established by the structure-mapping framework... Object Mappings and Shared Relations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Dhruv Agarwal, Bodhisattwa Prasad Majumder, Reece Adamson, Megha Chakravorty, Satvika Reddy Gavireddy, Aditya Parashar, Harshit Surana, Bhavana Dalvi Mishra, Andrew McCallum, Ashish Sabharwal, and Peter Clark. Autodiscovery: Open-ended scientific discovery via bayesian surprise, 2026. URLhttps://arxiv.org/abs/2507.00310
-
[2]
Constantin Ahlmann-Eltze, Wolfgang Huber, and Simon Anders. Deep learning-based predic- tions of gene perturbation effects do not yet outperform simple linear baselines.bioRxiv,
-
[3]
URL https://www.biorxiv.org/content/ early/2025/02/07/2024.09.16.613342
doi: 10.1101/2024.09.16.613342. URL https://www.biorxiv.org/content/ early/2025/02/07/2024.09.16.613342
-
[4]
Samuel Alber, Bowen Chen, Eric Sun, Alina Isakova, Aaron J. Wilk, and James Zou. Cel- lvoyager: Ai compbio agent generates new insights by autonomously analyzing biological data.bioRxiv, 2025. doi: 10.1101/2025.06.03.657517. URL https://www.biorxiv.org/ content/early/2025/06/04/2025.06.03.657517
-
[5]
Homogenization effects of large language models on human creative ideation
Barrett R Anderson, Jash Hemant Shah, and Max Kreminski. Homogenization effects of large language models on human creative ideation. InCreativity and Cognition, C&C ’24, pp. 413–425. ACM, June 2024. doi: 10.1145/3635636.3656204. URL http://dx.doi.org/10. 1145/3635636.3656204
-
[6]
Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. Researchagent: Iterative research idea generation over scientific literature with large language models, 2025. URLhttps://arxiv.org/abs/2404.07738
-
[7]
Quality-diversity through ai feedback, 2023
Herbie Bradley, Andrew Dai, Hannah Teufel, Jenny Zhang, Koen Oostermeijer, Marco Bella- gente, Jeff Clune, Kenneth Stanley, Grégory Schott, and Joel Lehman. Quality-diversity through ai feedback, 2023. URLhttps://arxiv.org/abs/2310.13032
-
[8]
Modularity and robustness of frontal cortical networks.Cell, 184(14):3717–3730.e24, 2021
Guang Chen, Byungwoo Kang, Jack Lindsey, Shaul Druckmann, and Nuo Li. Modularity and robustness of frontal cortical networks.Cell, 184(14):3717–3730.e24, 2021. ISSN 0092-8674. doi: https://doi.org/10.1016/j.cell.2021.05.026. URL https://www.sciencedirect.com/ science/article/pii/S0092867421006565
-
[9]
Tingting Chen, Beibei Lin, Zifeng Yuan, Qiran Zou, Hongyu He, Anirudh Goyal, Yew-Soon Ong, and Dianbo Liu. Hypospace: Evaluating llm creativity as set-valued hypothesis generators under underdetermination, 2026. URLhttps://arxiv.org/abs/2510.15614
-
[10]
Automatic icd- 10 coding: Deep semantic matching based on analogical reasoning.Heliyon, 9(4):e15570,
Yani Chen, Han Chen, Xudong Lu, Huilong Duan, Shilin He, and Jiye An. Automatic icd- 10 coding: Deep semantic matching based on analogical reasoning.Heliyon, 9(4):e15570,
-
[11]
doi: https://doi.org/10.1016/j.heliyon.2023.e15570
ISSN 2405-8440. doi: https://doi.org/10.1016/j.heliyon.2023.e15570. URL https: //www.sciencedirect.com/science/article/pii/S2405844023027779
- [12]
-
[13]
Elvis Dohmatob, Yunzhen Feng, Arjun Subramonian, and Julia Kempe. Strong model collapse,
- [14]
-
[15]
Is our solar system just a giant atom? Facebook post, 2025
Ethical Explorations. Is our solar system just a giant atom? Facebook post, 2025. https://www.facebook.com/ethicalexploration/posts/122196896288285338 [Ac- cessed: 2026-03-23]
-
[16]
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning, 2023. URLhttps://arxiv.org/abs/2210.02410
-
[17]
Structure-mapping: A theoretical framework for analogy.Cognitive science, 7 (2):155–170, 1983
Dedre Gentner. Structure-mapping: A theoretical framework for analogy.Cognitive science, 7 (2):155–170, 1983
work page 1983
-
[18]
Dedre Gentner and Francisco Maravilla. Analogical reasoning. InInternational handbook of thinking and reasoning, pp. 186–203. Routledge, 2017. 11
work page 2017
-
[19]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, Khaled Saab, Dan Popovici, Jacob Blum, Fan Zhang, Katherine Chou, Avinatan Hassidim, Burak Gokturk, Amin Vahdat, Pushmeet Kohli, Yossi Matias, Andrew Carroll, Kavita Kulkarni, Nenad Tomasev, Yuan Guan, Vi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Arlen Harbaugh. Documentation of the MT3DMS: A modular three-dimensional multispecies transport model for simulation of advection, dispersion, and chemical reactions of contaminants in groundwater systems, 2005. URLhttps://pubs.usgs.gov/tm/2005/tm6A16/
work page 2005
-
[21]
Artificial hivemind: The open-ended homogeneity of language models (and beyond), 2025
Liwei Jiang, Yuanjun Chai, Margaret Li, Mickel Liu, Raymond Fok, Nouha Dziri, Yulia Tsvetkov, Maarten Sap, Alon Albalak, and Yejin Choi. Artificial hivemind: The open-ended homogeneity of language models (and beyond), 2025. URL https://arxiv.org/abs/2510. 22954
work page 2025
-
[22]
Tech overview - stanford agentic reviewer
Yixing Jiang and Andrew Ng. Tech overview - stanford agentic reviewer. https:// paperreview.ai/tech-overview, 2025. Accessed: 2026-03-24
work page 2025
-
[23]
Rodney Michael Kinney, Chloe Anastasiades, Russell Authur, Iz Beltagy, Jonathan Bragg, Alexandra Buraczynski, Isabel Cachola, Stefan Candra, Yoganand Chandrasekhar, Arman Cohan, Miles Crawford, Doug Downey, Jason Dunkelberger, Oren Etzioni, Rob Evans, Sergey Feldman, Joseph Gorney, David W. Graham, F.Q. Hu, Regan Huff, Daniel King, Sebastian Kohlmeier, Ba...
-
[24]
Foster, Cyril Zhang, and Aleksandrs Slivkins
Akshay Krishnamurthy, Keegan Harris, Dylan J. Foster, Cyril Zhang, and Aleksandrs Slivkins. Can large language models explore in-context?, 2024. URL https://arxiv.org/abs/2403. 15371
work page 2024
-
[25]
Digital red queen: Adversarial program evolution in core war with llms, 2026
Akarsh Kumar, Ryan Bahlous-Boldi, Prafull Sharma, Phillip Isola, Sebastian Risi, Yujin Tang, and David Ha. Digital red queen: Adversarial program evolution in core war with llms, 2026. URLhttps://arxiv.org/abs/2601.03335
-
[26]
Diverse preference optimization, 2025
Jack Lanchantin, Angelica Chen, Shehzaad Dhuliawala, Ping Yu, Jason Weston, Sainbayar Sukhbaatar, and Ilia Kulikov. Diverse preference optimization, 2025. URL https://arxiv. org/abs/2501.18101
-
[27]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery, 2024. URL https: //arxiv.org/abs/2408.06292
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Malte D Luecken, Scott Gigante, Daniel B Burkhardt, Robrecht Cannoodt, Daniel C Strobl, Nikolay S Markov, Luke Zappia, Giovanni Palla, Wesley Lewis, Daniel Dimitrov, et al. Defining and benchmarking open problems in single-cell analysis.Nature Biotechnology, 43(7):1035– 1040, 2025
work page 2025
-
[29]
Ludovico Mitchener, Angela Yiu, Benjamin Chang, Mathieu Bourdenx, Tyler Nadolski, Arvis Sulovari, Eric C. Landsness, Daniel L. Barabasi, Siddharth Narayanan, Nicky Evans, Shriya Reddy, Martha Foiani, Aizad Kamal, Leah P. Shriver, Fang Cao, Asmamaw T. Wassie, Jon M. Laurent, Edwin Melville-Green, Mayk Caldas, Albert Bou, Kaleigh F. Roberts, Sladjana Zagora...
-
[30]
Llms as models for analogical reasoning.Journal of Memory and Language, 145:104676, December 2025
Sam Musker, Alex Duchnowski, Raphaël Millière, and Ellie Pavlick. Llms as models for analogical reasoning.Journal of Memory and Language, 145:104676, December 2025. ISSN 0749-596X. doi: 10.1016/j.jml.2025.104676. URL http://dx.doi.org/10.1016/j.jml. 2025.104676
-
[31]
Minh Nhat Nguyen, Andrew Baker, Clement Neo, Allen Roush, Andreas Kirsch, and Ravid Shwartz-Ziv. Turning up the heat: Min-p sampling for creative and coherent llm outputs, 2025. URLhttps://arxiv.org/abs/2407.01082
-
[32]
Phanish Puranam, Prothit Sen, and Maciej Workiewicz. Can llms help improve analogical reasoning for strategic decisions? experimental evidence from humans and gpt-4, 2025. URL https://arxiv.org/abs/2505.00603
-
[33]
Relevant or random: Can llms truly perform analogical reasoning?, 2025
Chengwei Qin, Wenhan Xia, Tan Wang, Fangkai Jiao, Yuchen Hu, Bosheng Ding, Ruirui Chen, and Shafiq Joty. Relevant or random: Can llms truly perform analogical reasoning?, 2025. URL https://arxiv.org/abs/2404.12728
-
[34]
Dive: Diversified iterative self-improvement, 2025
Yiwei Qin, Yixiu Liu, and Pengfei Liu. Dive: Diversified iterative self-improvement, 2025. URLhttps://arxiv.org/abs/2501.00747
-
[35]
Oligogym: Curated datasets and bench- marks for oligonucleotide drug discovery
Rachapun Rotrattanadumrong and Carlo De Donno. Oligogym: Curated datasets and bench- marks for oligonucleotide drug discovery. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
work page 2025
-
[36]
Simra Shahid, Marissa Radensky, Raymond Fok, Pao Siangliulue, Daniel S. Weld, and Tom Hope. Literature-grounded novelty assessment of scientific ideas, 2025. URL https://arxiv. org/abs/2506.22026
-
[37]
Si, C., Hashimoto, T., and Yang, D
Chenglei Si, Diyi Yang, and Tatsunori Hashimoto. Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers, 2024. URL https://arxiv.org/abs/ 2409.04109
-
[38]
Towards execution-grounded automated ai research, 2026
Chenglei Si, Zitong Yang, Yejin Choi, Emmanuel Candès, Diyi Yang, and Tatsunori Hashimoto. Towards execution-grounded automated ai research, 2026. URL https://arxiv.org/abs/ 2601.14525
-
[39]
Haoyang Su, Renqi Chen, Shixiang Tang, Zhenfei Yin, Xinzhe Zheng, Jinzhe Li, Biqing Qi, Qi Wu, Hui Li, Wanli Ouyang, Philip Torr, Bowen Zhou, and Nanqing Dong. Many heads are better than one: Improved scientific idea generation by a llm-based multi-agent system, 2025. URLhttps://arxiv.org/abs/2410.09403
-
[40]
Oren Sultan, Eitan Stern, and Dafna Shahaf. A neuro-symbolic approach for reliable proof generation with llms: A case study in euclidean geometry, 2026. URL https://arxiv.org/ abs/2505.14479
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Kyle Swanson, Wesley Wu, Nash L. Bulaong, John E. Pak, and James Zou. The virtual lab: Ai agents design new sars-cov-2 nanobodies with experimental validation.bioRxiv, 2024. doi: 10. 1101/2024.11.11.623004. URL https://www.biorxiv.org/content/early/2024/11/ 12/2024.11.11.623004
work page 2024
-
[42]
Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models
Ashwin K Vijayakumar, Michael Cogswell, Ramprasath R. Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. Diverse beam search: Decoding diverse solutions from neural sequence models, 2018. URLhttps://arxiv.org/abs/1610.02424
work page Pith review arXiv 2018
-
[43]
Francisco Villaescusa-Navarro, Boris Bolliet, Pablo Villanueva-Domingo, Adrian E. Bayer, Aidan Acquah, Chetana Amancharla, Almog Barzilay-Siegal, Pablo Bermejo, Camille Bilodeau, Pablo Cárdenas Ramírez, Miles Cranmer, Urbano L. França, ChangHoon Hahn, Yan-Fei Jiang, Raul Jimenez, Jun-Young Lee, Antonio Lerario, Osman Mamun, Thomas Meier, Anupam A. Ojha, P...
-
[44]
hypodd: A program to compute double-difference hypocenter locations,
Felix Waldhauser. hypodd: A program to compute double-difference hypocenter locations,
-
[45]
URLhttps://www.ldeo.columbia.edu/~felixw/hypoDD.html
-
[46]
Felix Waldhauser and William L. Ellsworth. A double-difference earthquake location algorithm: Method and application to the northern Hayward fault, California.Bulletin of the Seismological Society of America, 90(6):1353–1368, 2000. doi: 10.1785/0120000006. URL https://doi. org/10.1785/0120000006
-
[47]
Taylor Webb, Keith J. Holyoak, and Hongjing Lu. Emergent analogical reasoning in large language models, 2023. URLhttps://arxiv.org/abs/2212.09196
-
[48]
Base models beat aligned models at randomness and creativity,
Peter West and Christopher Potts. Base models beat aligned models at randomness and creativity,
- [49]
-
[50]
Yan Wu, Esther Wershof, Sebastian M Schmon, Marcel Nassar, Bła˙zej Osi´nski, Ridvan Eksi, Zichao Yan, Rory Stark, Kun Zhang, and Thore Graepel. Perturbench: Benchmarking machine learning models for cellular perturbation analysis, 2025. URL https://arxiv.org/abs/ 2408.10609
-
[51]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search, 2025. URLhttps://arxiv.org/abs/2504.08066
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Large language models for automated open-domain scientific hypotheses discovery, 2024
Zonglin Yang, Xinya Du, Junxian Li, Jie Zheng, Soujanya Poria, and Erik Cambria. Large language models for automated open-domain scientific hypotheses discovery, 2024. URL https://arxiv.org/abs/2309.02726
-
[53]
doi: 10.48550/arXiv.2310.01714
Michihiro Yasunaga, Xinyun Chen, Yujia Li, Panupong Pasupat, Jure Leskovec, Percy Liang, Ed H. Chi, and Denny Zhou. Large language models as analogical reasoners, 2024. URL https://arxiv.org/abs/2310.01714
-
[54]
U2f: Encouraging swe-agent to seize novelty without losing feasibility, 2025
Wencheng Ye and Yan Liu. U2f: Encouraging swe-agent to seize novelty without losing feasibility, 2025. URLhttps://arxiv.org/abs/2511.03517
-
[55]
The price of format: Diversity collapse in llms, 2025
Longfei Yun, Chenyang An, Zilong Wang, Letian Peng, and Jingbo Shang. The price of format: Diversity collapse in llms, 2025. URLhttps://arxiv.org/abs/2505.18949
-
[56]
Zhang, Peter Eckmann, Jiacheng Miao, Andrew B
Harrison G. Zhang, Peter Eckmann, Jiacheng Miao, Andrew B. Mahon, and James Zou. The virtual biotech: A multi-agent ai framework for therapeutic discovery and development.bioRxiv,
-
[57]
URL https://www.biorxiv.org/content/ early/2026/02/23/2026.02.23.707551
doi: 10.64898/2026.02.23.707551. URL https://www.biorxiv.org/content/ early/2026/02/23/2026.02.23.707551
-
[58]
Jiayi Zhang, Simon Yu, Derek Chong, Anthony Sicilia, Michael R Tomz, Christopher D Manning, and Weiyan Shi. Verbalized sampling: How to mitigate mode collapse and unlock llm diversity.arXiv preprint arXiv:2510.01171, 2025
-
[59]
Forcing diffuse distributions out of language models, 2024
Yiming Zhang, Avi Schwarzschild, Nicholas Carlini, Zico Kolter, and Daphne Ippolito. Forcing diffuse distributions out of language models, 2024. URL https://arxiv.org/abs/2404. 10859
work page 2024
-
[60]
Yilun Zhou, Caiming Xiong, Silvio Savarese, and Chien-Sheng Wu. Shared imagination: Llms hallucinate alike, 2024. URLhttps://arxiv.org/abs/2407.16604. 14 A Reproducibility Statement We describe the evaluation setup for our analyses and methods in the main text and Appendix. All LLM prompts used are provided in Section G. In addition, we include the codeba...
- [61]
-
[62]
"problem_objects": Array of key objects/entities with their functional roles
-
[63]
"problem_relations": Array of core relational structures between objects
-
[64]
"analogies": Array of {num_domains} analogies, each with: - "target_domain": The domain name (e.g., "computer_science", "logistics") - "analogy_title": A descriptive title for this analogy - "object_mappings": Array of source-to-target mappings with rationale - "shared_relations": The relational structure preserved across domains
- [65]
-
[66]
"target_domains": Array of the {num_domains} domain names (from analogies) **Map objects by FUNCTION, not surface similarity.** "Delivers payload" is a good mapping basis; " is liquid" is not. **Example format:** ‘‘‘json {{ "problem_summary": "Brief description of the biomedical problem", "problem_objects": [ {{"name": "object_A", "role": "functional role...
- [71]
-
[74]
"github_repos": Array of GitHub repositories found (can be empty if none found) **CRITICAL:** After completing your research, return ONLY the JSON array with NO additional text, explanation, or commentary. Do not write "Based on my research" or any other introduction. Start your response directly with the JSON array. Format: ‘‘‘json [ {{ "title": "Solutio...
- [76]
-
[82]
"github_repos": Array of GitHub repositories found (can be empty if none found) **CRITICAL:** After completing your research, return ONLY the JSON array with NO additional text, explanation, or commentary. Do not write "Based on my research" or any other introduction. Start your response directly with the JSON array. Format: ‘‘‘json [ {{ "title": "Solutio...
-
[83]
"title": Descriptive title of the solution/algorithm
-
[84]
"source_domain": A single domain name where this solution comes from (e.g., "computer_science", "logistics"). Do not combine multiple domains with slashes
- [85]
- [86]
- [87]
-
[88]
"sources": URLs or citations you found
-
[89]
"source_titles": EXACT titles of papers/articles at each source URL (must match order of sources array)
-
[90]
"github_repos": Array of GitHub repositories found (can be empty if none found) **Example format:** ‘‘‘json [ {{ "title": "Solution name", "source_domain": "Domain name", "description": "Detailed explanation...", "key_concepts": ["concept1", "concept2", "concept3"], "relevance": "How this addresses the biomedical problem...", "sources": ["url1", "url2"], ...
-
[91]
Rewrite the TITLE to combine the methodology with the application (under 15 words) - Use the ACTUAL TECHNICAL METHODOLOGY from the key concepts, NOT any brand/algorithm names - Focus on the underlying technical approach (e.g., "graph neural networks", "matrix factorization") rather than named methods - MUST show how it’s applied to the target domain - Exa...
-
[92]
Rewrite the ABSTRACT to highlight practical application (~150-200 words) - Start with what problem in the target domain this method solves - Describe the technical methodology using the key concepts (avoid brand/algorithm names) - Explain how this technical approach addresses that specific problem - Focus on domain-specific application, not general theory...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.