Recognition: 2 theorem links
· Lean TheoremPointForward: Feedforward Driving Reconstruction through Point-Aligned Representations
Pith reviewed 2026-05-13 01:17 UTC · model grok-4.3
The pith
PointForward reconstructs driving scenes by initializing sparse 3D queries in world space to enforce explicit cross-view consistency in one feedforward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By initializing sparse 3D queries in world space and performing spatial-temporal fusion onto these queries, PointForward enforces explicit cross-view consistency during feedforward reconstruction; scene graphs built on 3D bounding boxes further enable instance-level motion propagation and temporally consistent representations of dynamic instances.
What carries the argument
Sparse 3D queries initialized in world space that receive aggregated multi-view image information via spatial-temporal fusion, together with 3D bounding-box scene graphs that organize moving instances.
If this is right
- Single-pass reconstruction with explicit cross-view consistency becomes possible without post-optimization.
- Dynamic instances receive instance-level motion propagation that stays consistent across frames.
- Layering artifacts and multi-view misalignment common in per-pixel Gaussian methods are reduced.
- State-of-the-art numerical performance is achieved on large-scale driving benchmarks.
Where Pith is reading between the lines
- The explicit 3D query structure could be reused directly for downstream tasks such as tracking or planning without additional conversion steps.
- Removing reliance on dense flow prediction may lower error accumulation when correspondence across views is difficult.
- The same query-and-graph pattern might transfer to non-driving dynamic scenes where instance-level consistency matters.
- Feedforward operation at this level of consistency could support lower-latency perception pipelines in autonomous systems.
Load-bearing premise
That initializing sparse 3D queries in world space and fusing spatial-temporal information onto them will produce explicit cross-view consistency without new artifacts, and that 3D bounding-box scene graphs will maintain temporally consistent dynamic representations for every moving instance.
What would settle it
Persistent multi-view inconsistencies or temporal artifacts in dynamic objects on the same large-scale driving benchmarks would show that the consistency claims do not hold.
Figures




read the original abstract
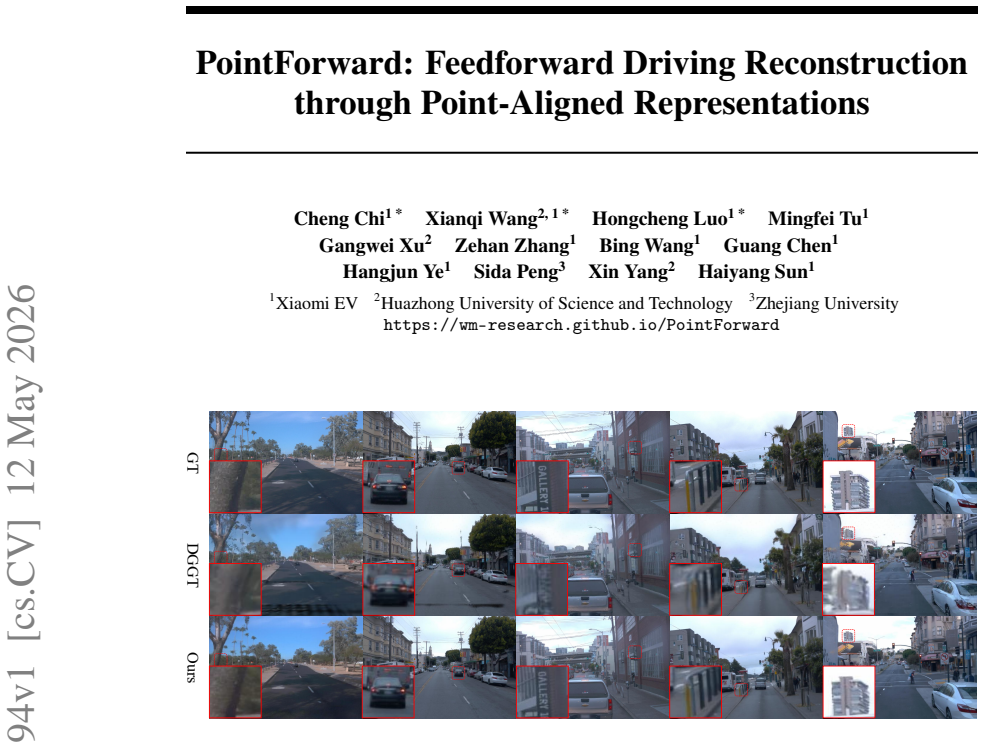
High-fidelity reconstruction of driving scenes is crucial for autonomous driving. While recent feedforward 3D Gaussian Splatting (3DGS) methods enable fast reconstruction, their per-pixel Gaussian prediction paradigm often suffers from multi-view inconsistency and layering artifacts. Moreover, existing methods often model dynamic instances via dense flow prediction, which lacks explicit cross-view correspondence and instance-level consistency. In this paper, we propose PointForward, a feedforward driving reconstruction framework through point-aligned representations. Unlike pixel-aligned methods, we initialize sparse 3D queries in world space and aggregate multi-view image information via spatial-temporal fusion onto these queries, enforcing explicit cross-view consistency in a single feedforward pass. To handle scene dynamics, we introduce scene graphs that explicitly organize moving instances during reconstruction. By leveraging 3D bounding boxes, our method enables instance-level motion propagation and temporally consistent dynamic representations. Extensive experiments demonstrate that PointForward achieves state-of-the-art performance on large-scale driving benchmarks. The code will be available upon the publication of the paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PointForward, a feedforward driving scene reconstruction framework that replaces per-pixel Gaussian prediction with point-aligned representations. Sparse 3D queries are initialized in world space and multi-view image features are aggregated onto them via spatial-temporal fusion to enforce explicit cross-view consistency in one pass. Dynamic instances are organized with scene graphs built from 3D bounding boxes to enable instance-level motion propagation and temporally consistent representations. The manuscript claims this yields state-of-the-art performance on large-scale driving benchmarks.
Significance. If the two core mechanisms deliver the promised artifact-free consistency and temporal stability for dynamics, the work would meaningfully advance feedforward 3D reconstruction for autonomous driving by mitigating the multi-view inconsistency and layering problems common in recent 3DGS methods while avoiding the need for dense flow or post-processing.
major comments (3)
- Abstract: the central claim that sparse 3D world-space queries plus spatial-temporal fusion enforce explicit cross-view consistency without new artifacts is load-bearing, yet the abstract supplies no information on query density, fusion regularization, or occlusion handling, leaving the mechanism unverified.
- Abstract: the claim that 3D bounding-box scene graphs deliver instance-level motion propagation and temporally consistent dynamic representations for all moving instances is load-bearing, yet the abstract provides no description of graph construction, update rules, or handling of partial observations and complex motion.
- Abstract: the assertion of state-of-the-art performance on large-scale driving benchmarks is unsupported by any quantitative numbers, ablation studies, error analysis, or experimental details, preventing evaluation of the soundness of the overall contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify opportunities to strengthen the abstract by incorporating more specifics on the proposed mechanisms and empirical support. We will revise the abstract in the next version to address these points while preserving its brevity. Our point-by-point responses follow.
read point-by-point responses
-
Referee: Abstract: the central claim that sparse 3D world-space queries plus spatial-temporal fusion enforce explicit cross-view consistency without new artifacts is load-bearing, yet the abstract supplies no information on query density, fusion regularization, or occlusion handling, leaving the mechanism unverified.
Authors: We agree that the abstract would be improved by including brief details on these aspects. In the revised version, we will add concise references to the query initialization density in world space, the regularization applied during spatial-temporal fusion, and the occlusion handling strategy via visibility-aware aggregation. These elements are fully specified in Sections 3.1 and 3.2 of the manuscript. revision: yes
-
Referee: Abstract: the claim that 3D bounding-box scene graphs deliver instance-level motion propagation and temporally consistent dynamic representations for all moving instances is load-bearing, yet the abstract provides no description of graph construction, update rules, or handling of partial observations and complex motion.
Authors: We acknowledge the value of additional context in the abstract. We will revise the abstract to briefly outline the construction of scene graphs from 3D bounding boxes, the update rules for propagating instance motions, and the mechanisms for managing partial observations and complex motions. Complete technical descriptions appear in Section 3.3. revision: yes
-
Referee: Abstract: the assertion of state-of-the-art performance on large-scale driving benchmarks is unsupported by any quantitative numbers, ablation studies, error analysis, or experimental details, preventing evaluation of the soundness of the overall contribution.
Authors: We agree that referencing key quantitative results would make the state-of-the-art claim more immediately verifiable from the abstract. We will update the abstract to include highlights from the quantitative evaluations, ablations, and error analyses presented in Section 4 and the associated tables, while directing readers to the full experimental details in the manuscript. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes PointForward as a feedforward framework that initializes sparse 3D queries in world space, performs spatial-temporal fusion, and uses 3D bounding-box scene graphs for dynamics. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or description. The consistency and temporal claims are presented as direct consequences of the architectural choices rather than quantities defined in terms of themselves or reduced to prior self-citations. This is a standard non-circular method proposal whose performance claims rest on empirical benchmarks rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we initialize sparse 3D queries in world space and aggregate multi-view image information via spatial-temporal fusion onto these queries, enforcing explicit cross-view consistency
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
C3G: Learning Compact 3D Representations with 2K Gaussians
Honggyu An, Jaewoo Jung, Mungyeom Kim, Sunghwan Hong, Chaehyun Kim, Kazumi Fukuda, Minkyeong Jeon, Jisang Han, Takuya Narihira, Hyuna Ko, et al. C3g: Learning compact 3d representations with 2k gaussians.arXiv preprint arXiv:2512.04021, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields
Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. InProceedings of the IEEE/CVF international conference on computer vision, pages 5855–5864, 2021
work page 2021
-
[3]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
work page 2020
-
[4]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19457–19467, 2024
work page 2024
-
[5]
Xiaoxue Chen, Ziyi Xiong, Yuantao Chen, Gen Li, Nan Wang, Hongcheng Luo, Long Chen, Haiyang Sun, Bing Wang, Guang Chen, et al. Dggt: Feedforward 4d reconstruction of dynamic driving scenes using unposed images.arXiv preprint arXiv:2512.03004, 2025
-
[6]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. InEuropean conference on computer vision, pages 370–386. Springer, 2024
work page 2024
-
[7]
Yurui Chen, Chun Gu, Junzhe Jiang, Xiatian Zhu, and Li Zhang. Periodic vibration gaussian: Dynamic urban scene reconstruction and real-time rendering.International Journal of Computer Vision, 134(3):83, 2026
work page 2026
-
[8]
Omnire: Omni urban scene reconstruction.arXiv preprint arXiv:2408.16760, 2024
Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo De Lutio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Gojcic, Sanja Fidler, Marco Pavone, et al. Omnire: Omni urban scene reconstruction.arXiv preprint arXiv:2408.16760, 2024
-
[9]
Splatad: Real-time lidar and camera rendering with 3d gaussian splatting for autonomous driving
Georg Hess, Carl Lindström, Maryam Fatemi, Christoffer Petersson, and Lennart Svensson. Splatad: Real-time lidar and camera rendering with 3d gaussian splatting for autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 11982–11992, 2025
work page 2025
-
[10]
Junjie Huang, Guan Huang, Zheng Zhu, Yun Ye, and Dalong Du. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view.arXiv preprint arXiv:2112.11790, 2021
-
[11]
Nan Huang, Xiaobao Wei, Wenzhao Zheng, Pengju An, Ming Lu, Wei Zhan, Masayoshi Tomizuka, Kurt Keutzer, and Shanghang Zhang. S3gaussian: Self-supervised street gaussians for autonomous driving.arXiv preprint arXiv:2405.20323, 2024
-
[12]
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.ACM Transactions on Graphics (TOG), 44(6):1–16, 2025
work page 2025
-
[13]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
work page 2023
-
[14]
Autosplat: Constrained gaussian splatting for autonomous driving scene reconstruction
Mustafa Khan, Hamidreza Fazlali, Dhruv Sharma, Tongtong Cao, Dongfeng Bai, Yuan Ren, and Bingbing Liu. Autosplat: Constrained gaussian splatting for autonomous driving scene reconstruction. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8315–8321. IEEE, 2025
work page 2025
-
[15]
Bevstereo: Enhanc- ing depth estimation in multi-view 3d object detection with temporal stereo
Yinhao Li, Han Bao, Zheng Ge, Jinrong Yang, Jianjian Sun, and Zeming Li. Bevstereo: Enhanc- ing depth estimation in multi-view 3d object detection with temporal stereo. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 1486–1494, 2023. 10
work page 2023
-
[16]
Bevdepth: Acquisition of reliable depth for multi-view 3d object detection
Yinhao Li, Zheng Ge, Guanyi Yu, Jinrong Yang, Zengran Wang, Yukang Shi, Jianjian Sun, and Zeming Li. Bevdepth: Acquisition of reliable depth for multi-view 3d object detection. In Proceedings of the AAAI conference on artificial intelligence, volume 37, pages 1477–1485, 2023
work page 2023
-
[17]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(3):2020– 2036, 2024
work page 2020
-
[18]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
arXiv preprint arXiv:2211.10581 (2022)
Xuewu Lin, Tianwei Lin, Zixiang Pei, Lichao Huang, and Zhizhong Su. Sparse4d: Multi-view 3d object detection with sparse spatial-temporal fusion.arXiv preprint arXiv:2211.10581, 2022
-
[20]
Petr: Position embedding transfor- mation for multi-view 3d object detection
Yingfei Liu, Tiancai Wang, Xiangyu Zhang, and Jian Sun. Petr: Position embedding transfor- mation for multi-view 3d object detection. InEuropean conference on computer vision, pages 531–548. Springer, 2022
work page 2022
-
[21]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Evolsplat: Efficient volume-based gaussian splatting for urban view synthesis
Sheng Miao, Jiaxin Huang, Dongfeng Bai, Xu Yan, Hongyu Zhou, Yue Wang, Bingbing Liu, Andreas Geiger, and Yiyi Liao. Evolsplat: Efficient volume-based gaussian splatting for urban view synthesis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 11286–11296, 2025
work page 2025
-
[23]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
work page 2021
-
[24]
Julius Plucker. Xvii. on a new geometry of space.Philosophical Transactions of the Royal Society of London, pages 725–791, 1865
-
[25]
D-nerf: Neural radiance fields for dynamic scenes
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-nerf: Neural radiance fields for dynamic scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10318–10327, 2021
work page 2021
-
[26]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020
work page 2020
-
[27]
Kaiyuan Tan, Yingying Shen, Mingfei Tu, Haohui Zhu, Bing Wang, Guang Chen, Hangjun Ye, and Haiyang Sun. Ufo: Unifying feed-forward and optimization-based methods for large driving scene modeling.arXiv preprint arXiv:2602.20943, 2026
-
[28]
Efficientnetv2: Smaller models and faster training
Mingxing Tan and Quoc Le. Efficientnetv2: Smaller models and faster training. InInternational conference on machine learning, pages 10096–10106. PMLR, 2021
work page 2021
-
[29]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view gaussian model for high-resolution 3d content creation. InEuropean Conference on Computer Vision, pages 1–18. Springer, 2024
work page 2024
-
[30]
Qijian Tian, Xin Tan, Yuan Xie, and Lizhuang Ma. Drivingforward: Feed-forward 3d gaussian splatting for driving scene reconstruction from flexible surround-view input. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7374–7382, 2025
work page 2025
-
[31]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 11
work page 2025
-
[32]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details.arXiv preprint arXiv:2507.02546, 2025
work page internal anchor Pith review arXiv 2025
-
[33]
Detr3d: 3d object detection from multi-view images via 3d-to-2d queries
Yue Wang, Vitor Campagnolo Guizilini, Tianyuan Zhang, Yilun Wang, Hang Zhao, and Justin Solomon. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In Conference on robot learning, pages 180–191. PMLR, 2022
work page 2022
-
[34]
Depthsplat: Connecting gaussian splatting and depth
Haofei Xu, Songyou Peng, Fangjinhua Wang, Hermann Blum, Daniel Barath, Andreas Geiger, and Marc Pollefeys. Depthsplat: Connecting gaussian splatting and depth. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16453–16463, 2025
work page 2025
-
[35]
Street gaussians: Modeling dynamic urban scenes with gaussian splatting
Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng. Street gaussians: Modeling dynamic urban scenes with gaussian splatting. InEuropean Conference on Computer Vision, pages 156–173. Springer, 2024
work page 2024
-
[36]
Jiawei Yang, Jiahui Huang, Yuxiao Chen, Yan Wang, Boyi Li, Yurong You, Apoorva Sharma, Maximilian Igl, Peter Karkus, Danfei Xu, et al. Storm: Spatio-temporal reconstruction model for large-scale outdoor scenes.arXiv preprint arXiv:2501.00602, 2024
-
[37]
arXiv preprint arXiv:2311.02077 , year=
Jiawei Yang, Boris Ivanovic, Or Litany, Xinshuo Weng, Seung Wook Kim, Boyi Li, Tong Che, Danfei Xu, Sanja Fidler, Marco Pavone, et al. Emernerf: Emergent spatial-temporal scene decomposition via self-supervision.arXiv preprint arXiv:2311.02077, 2023
-
[38]
Unisim: A neural closed-loop sensor simulator
Ze Yang, Yun Chen, Jingkang Wang, Sivabalan Manivasagam, Wei-Chiu Ma, Anqi Joyce Yang, and Raquel Urtasun. Unisim: A neural closed-loop sensor simulator. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1389–1399, 2023
work page 2023
-
[39]
Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20331–20341, 2024
work page 2024
-
[40]
Hao Yu, Haotong Lin, Jiawei Wang, Jiaxin Li, Yida Wang, Xueyang Zhang, Yue Wang, Xiaowei Zhou, Ruizhen Hu, and Sida Peng. Infinidepth: Arbitrary-resolution and fine-grained depth estimation with neural implicit fields.arXiv preprint arXiv:2601.03252, 2026
-
[41]
Gs-lrm: Large reconstruction model for 3d gaussian splatting
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, and Zexiang Xu. Gs-lrm: Large reconstruction model for 3d gaussian splatting. InEuropean Conference on Computer Vision, pages 1–19. Springer, 2024
work page 2024
-
[42]
SparseSplat: Towards Applicable Feed-Forward 3D Gaussian Splatting with Pixel-Unaligned Prediction
Zicheng Zhang, Xiangting Meng, Ke Wu, and Wenchao Ding. Sparsesplat: Towards ap- plicable feed-forward 3d gaussian splatting with pixel-unaligned prediction.arXiv preprint arXiv:2604.03069, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Hugs: Holistic urban 3d scene understanding via gaussian splatting
Hongyu Zhou, Jiahao Shao, Lu Xu, Dongfeng Bai, Weichao Qiu, Bingbing Liu, Yue Wang, Andreas Geiger, and Yiyi Liao. Hugs: Holistic urban 3d scene understanding via gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21336–21345, 2024
work page 2024
-
[44]
Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes
Xiaoyu Zhou, Zhiwei Lin, Xiaojun Shan, Yongtao Wang, Deqing Sun, and Ming-Hsuan Yang. Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21634–21643, 2024. 12
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.