Recognition: unknown
X-Imitator: Spatial-Aware Imitation Learning via Bidirectional Action-Pose Interaction
Pith reviewed 2026-05-13 04:45 UTC · model grok-4.3
The pith
A bidirectional loop between pose prediction and action generation improves robotic manipulation by enabling mutual refinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose X-Imitator, a modular dual-path framework that models spatial perception and action execution as a tightly coupled bidirectional loop. By reciprocally conditioning current pose predictions on past actions and vice versa, the system enables continuous mutual refinement between spatial reasoning and action generation, exactly mimicking human internal forward models. Designed for easy integration into various visuomotor policies, the framework significantly outperforms both vanilla policies and prior methods that use explicit pose guidance across 24 simulated tasks and 3 real-world tasks.
What carries the argument
The bidirectional action-pose interaction loop that allows pose predictions and action generations to condition each other reciprocally for ongoing mutual refinement.
Load-bearing premise
Treating spatial perception and action execution as a tightly coupled bidirectional loop will produce significant performance gains over decoupled or unidirectional baselines on complex manipulation tasks.
What would settle it
Disabling the bidirectional conditioning in the same 24 simulated and 3 real-world task setups and measuring whether success rates drop below the reported levels of the full framework.
Figures



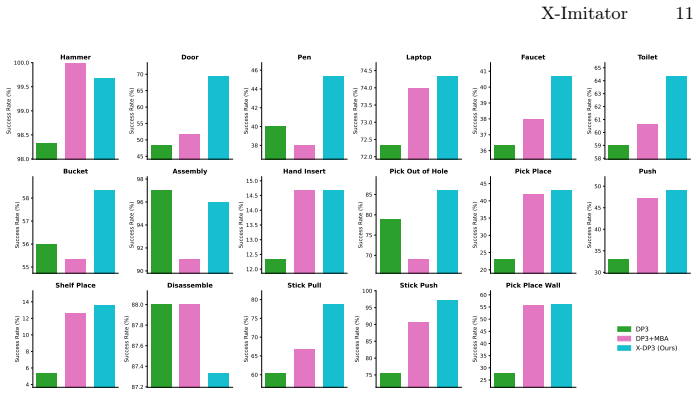




read the original abstract
Effectively handling the interplay between spatial perception and action generation remains a critical bottleneck in robotic manipulation. Existing methods typically treat spatial perception and action execution as decoupled or strictly unidirectional processes, fundamentally restricting a robot's ability to master complex manipulation tasks. To address this, we propose X-Imitator, a versatile dual-path framework that models spatial perception and action execution as a tightly coupled bidirectional loop. By reciprocally conditioning current pose predictions on past actions and vice versa, this framework enables continuous mutual refinement between spatial reasoning and action generation. This joint modeling exactly mimics human internal forward models. Designed as a modular architecture, the system can be seamlessly integrated into various visuomotor policies. Extensive experiments across 24 simulated and 3 real-world tasks demonstrate that our framework significantly outperforms both vanilla policies and prior methods utilizing explicit pose guidance. The code will be open sourced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes X-Imitator, a modular dual-path framework for imitation learning in robotic manipulation. It models spatial perception and action execution as a tightly coupled bidirectional loop in which current pose predictions are reciprocally conditioned on past actions (and vice versa), enabling continuous mutual refinement. The architecture is designed to mimic human internal forward models and can be integrated into various visuomotor policies. Experiments are reported to show significant outperformance over vanilla policies and prior methods that use explicit pose guidance, across 24 simulated and 3 real-world tasks.
Significance. If the empirical claims are supported by detailed quantitative results, ablations, and statistical validation, the work could meaningfully advance visuomotor policy design by showing that bidirectional coupling between spatial reasoning and action generation yields measurable gains on complex manipulation tasks. The modular design and commitment to open-sourcing code are strengths that would support reproducibility and follow-on research.
major comments (2)
- [§5 (Experiments)] §5 (Experiments) and associated tables: the central claim of outperformance on 24 simulated and 3 real tasks is asserted without reported means, standard deviations, statistical significance tests, or ablation studies comparing the bidirectional loop against unidirectional or decoupled baselines. This absence prevents assessment of whether the performance gains are robust or attributable to the proposed interaction mechanism.
- [§3 (Method)] §3 (Method), bidirectional conditioning description: the reciprocal conditioning between pose prediction and action generation is presented qualitatively without explicit equations, network diagrams, or loss formulations defining how past actions are encoded to condition current pose estimates (and vice versa). This makes the claim that the loop 'exactly mimics human internal forward models' difficult to verify or reproduce.
minor comments (2)
- [Abstract] Abstract: the statement that the framework 'significantly outperforms' prior methods would be strengthened by naming the specific metrics (e.g., success rate, trajectory error) and the most competitive baselines used.
- [§3 (Method)] Notation: ensure consistent use of symbols for pose and action variables across the method and experiment sections to avoid ambiguity when describing the bidirectional paths.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to strengthen the empirical reporting and methodological formalization.
read point-by-point responses
-
Referee: [§5 (Experiments)] §5 (Experiments) and associated tables: the central claim of outperformance on 24 simulated and 3 real tasks is asserted without reported means, standard deviations, statistical significance tests, or ablation studies comparing the bidirectional loop against unidirectional or decoupled baselines. This absence prevents assessment of whether the performance gains are robust or attributable to the proposed interaction mechanism.
Authors: We agree that more rigorous statistical reporting and targeted ablations are needed to substantiate the claims. In the revised manuscript, we will report means and standard deviations across multiple random seeds for all 24 simulated and 3 real-world tasks. We will add statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values) and include ablation studies that directly compare the full bidirectional loop against unidirectional conditioning and decoupled pose-action baselines. These changes will clarify the contribution of the interaction mechanism. revision: yes
-
Referee: [§3 (Method)] §3 (Method), bidirectional conditioning description: the reciprocal conditioning between pose prediction and action generation is presented qualitatively without explicit equations, network diagrams, or loss formulations defining how past actions are encoded to condition current pose estimates (and vice versa). This makes the claim that the loop 'exactly mimics human internal forward models' difficult to verify or reproduce.
Authors: We acknowledge that a more formal presentation would improve verifiability. We will update Section 3 with explicit equations describing the bidirectional conditioning (including action-to-pose and pose-to-action pathways), a detailed network diagram, and the joint loss formulation. We will also revise the phrasing from 'exactly mimics' to 'inspired by' human internal forward models and add relevant neuroscience citations to support the analogy without overstating equivalence. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents X-Imitator as a modular dual-path neural architecture for bidirectional conditioning between pose prediction and action generation in imitation learning. No equations, parameter fits, or first-principles derivations are described that could reduce to their own inputs by construction. The central contribution is an empirical claim of outperformance on 27 tasks, resting on architectural description and experimental results rather than any self-referential mathematical step. Self-citations, if present, are not load-bearing for any derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bain, M., Sammut, C.: A framework for behavioural cloning. In: Machine intelli- gence 15. pp. 103–129 (1995)
work page 1995
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bao, C., Xu, H., Qin, Y., Wang, X.: Dexart: Benchmarking generalizable dex- terous manipulation with articulated objects. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21190–21200 (2023)
work page 2023
-
[3]
In: European Conference on Computer Vision
Bharadhwaj, H., Mottaghi, R., Gupta, A., Tulsiani, S.: Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. In: European Conference on Computer Vision. pp. 306–324. Springer (2024)
work page 2024
-
[4]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y., Fox, D., Hu, F., Huang, S., et al.: Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
In: Conference on Robot Learning
Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M.R., Finn, C., Fusai, N., Galliker, M.Y., et al.:π 0.5: a vision-language-action model with open-world generalization. In: Conference on Robot Learning. vol. 305, pp. 17–40. PMLR (2025)
work page 2025
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
RT-1: Robotics Transformer for Real-World Control at Scale
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakr- ishnan, K., Hausman, K., Herzog, A., Hsu, J., et al.: Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Chen, J., Fang, H., Wang, C., Wang, S., Lu, C.: History-aware visuomotor policy learning via point tracking. In: ICRA (2026)
work page 2026
-
[9]
Chen, T., Chen, Z., Chen, B., Cai, Z., Liu, Y., Li, Z., Liang, Q., Lin, X., Ge, Y., Gu, Z., et al.: Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv:2506.18088 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, T., Mu, Y., Liang, Z., Chen, Z., Peng, S., Chen, Q., Xu, M., Hu, R., Zhang, H., Li, X., et al.: G3flow: Generative 3d semantic flow for pose-aware and general- izable object manipulation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1735–1744 (2025) 18 K. Xiong et al
work page 2025
-
[11]
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
Chen, X., Chen, Y., Fu, Y., Gao, N., Jia, J., Jin, W., Li, H., Mu, Y., Pang, J., Qiao, Y., et al.: Internvla-m1: A spatially guided vision-language-action framework for generalist robot policy. arXiv preprint arXiv:2510.13778 (2025)
work page internal anchor Pith review arXiv 2025
-
[12]
In: Robotics: Science and Systems (2023)
Chi, C., Feng, S., Du, Y., Xu, Z., Cousineau, E., Burchfiel, B., Song, S.: Diffusion policy: Visuomotor policy learning via action diffusion. In: Robotics: Science and Systems (2023)
work page 2023
-
[13]
In: Robotics: Science and Systems (2024)
Chi, C., Xu, Z., Pan, C., Cousineau, E., Burchfiel, B., Feng, S., Tedrake, R., Song, S.:Universalmanipulationinterface:In-the-wildrobotteachingwithoutin-the-wild robots. In: Robotics: Science and Systems (2024)
work page 2024
-
[14]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Choy, C., Gwak, J., Savarese, S.: 4d spatio-temporal convnets: Minkowski con- volutional neural networks. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3075–3084 (2019)
work page 2019
-
[15]
arXiv preprint arXiv:2508.08113 (2025)
Dai, Y., Lee, J., Zhang, Y., Ma, Z., Yang, J., Zadeh, A., Li, C., Fazeli, N., Chai, J.: Aimbot: A simple auxiliary visual cue to enhance spatial awareness of visuomotor policies. arXiv preprint arXiv:2508.08113 (2025)
-
[16]
In: Conference on Robot Learning
Deng, S., Yan, M., Wei, S., Ma, H., Yang, Y., Chen, J., Zhang, Z., Yang, T., Zhang, X., Cui, H., et al.: Graspvla: a grasping foundation model pre-trained on billion- scale synthetic action data. In: Conference on Robot Learning. pp. 1004–1029. PMLR (2025)
work page 2025
-
[17]
Dharmarajan, K., Huang, W., Wu, J., Fei-Fei, L., Zhang, R.: Dream2flow: Bridging video generation and open-world manipulation with 3d object flow. arXiv preprint arXiv:2512.24766 (2025)
-
[18]
In: IEEE International Conference on Robotics and Automation
Fang,H.S.,Fang,H.,Tang,Z.,Liu,J.,Wang,C.,Wang,J.,Zhu,H.,Lu,C.:RH20T: A comprehensive robotic dataset for learning diverse skills in one-shot. In: IEEE International Conference on Robotics and Automation. pp. 653–660. IEEE (2024)
work page 2024
-
[19]
In: Conference on Robot Learning
Fang, H., Wang, C., Wang, Y., Chen, J., Xia, S., Lv, J., He, Z., Yi, X., Guo, Y., Zhan, X., Yang, L., Wang, W., Lu, C., Fang, H.S.: Airexo-2: Scaling up gener- alizable robotic imitation learning with low-cost exoskeletons. In: Conference on Robot Learning. vol. 305, pp. 198–220. PMLR (2025)
work page 2025
-
[20]
arXiv preprint arXiv:2502.08449 (2025)
Fu, Y., Feng, Q., Chen, N., Zhou, Z., Liu, M., Wu, M., Chen, T., Rong, S., Liu, J., Dong, H., et al.: Cordvip: Correspondence-based visuomotor policy for dexterous manipulation in real-world. arXiv preprint arXiv:2502.08449 (2025)
-
[21]
Act3d: Infinite resolution action detection transformer for robotic manipulation
Gervet, T., Xian, Z., Gkanatsios, N., Fragkiadaki, K.: Act3d: 3d feature field transformers for multi-task robotic manipulation. arXiv preprint arXiv:2306.17817 (2023)
-
[22]
In: Conference on Robot Learning
Goyal, A., Xu, J., Guo, Y., Blukis, V., Chao, Y.W., Fox, D.: Rvt: Robotic view transformer for 3d object manipulation. In: Conference on Robot Learning. pp. 694–710. PMLR (2023)
work page 2023
-
[23]
In: First Workshop on Out-of-Distribution Generalization in Robotics at CoRL 2023 (2023)
Gu, J., Kirmani, S., Wohlhart, P., Lu, Y., Arenas, M.G., Rao, K., Yu, W., Fu, C., Gopalakrishnan, K., Xu, Z., et al.: Robotic task generalization via hindsight trajectory sketches. In: First Workshop on Out-of-Distribution Generalization in Robotics at CoRL 2023 (2023)
work page 2023
-
[24]
arXiv preprint arXiv:2512.09619 (2025)
Guo, M., Cao, M., Tao, J., Xu, R., Yan, Y., Liang, X., Laptev, I., Chang, X.: Glad: Geometric latent distillation for vision-language-action models. arXiv preprint arXiv:2512.09619 (2025)
-
[25]
In: Conference on Robot Learning
Ha, H.,Song,S.: Flingbot:The unreasonableeffectivenessof dynamicmanipulation for cloth unfolding. In: Conference on Robot Learning. pp. 24–33. PMLR (2021)
work page 2021
-
[26]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Han, M., Zhang, D.J., Wang, Y., Yan, R., Yao, L., Chang, X., Qiao, Y.: Dual-ai: Dual-path actor interaction learning for group activity recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2990–2999 (2022) X-Imitator 19
work page 2022
-
[27]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
work page 2020
-
[28]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Hsu, C.C., Wen, B., Xu, J., Narang, Y., Wang, X., Zhu, Y., Biswas, J., Birchfield, S.: Spot: Se (3) pose trajectory diffusion for object-centric manipulation. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 4853–
work page 2025
-
[29]
arXiv preprint arXiv:2508.07650 , year=
Huang, H., Cen, M., Tan, K., Quan, X., Huang, G., Zhang, H.: Graphcot-vla: A 3d spatial-aware reasoning vision-language-action model for robotic manipulation with ambiguous instructions. arXiv preprint arXiv:2508.07650 (2025)
-
[30]
In: International Conference on Learning Representations (2022)
Jaegle, A., Borgeaud, S., Alayrac, J., Doersch, C., Ionescu, C., Ding, D., Koppula, S., Zoran, D., Brock, A., Shelhamer, E., Hénaff, O.J., Botvinick, M.M., Zisserman, A., Vinyals, O., Carreira, J.: Perceiver IO: A general architecture for structured inputs & outputs. In: International Conference on Learning Representations (2022)
work page 2022
-
[31]
In: European Conference on Computer Vision
Jia, M., Tang, L., Chen, B.C., Cardie, C., Belongie, S., Hariharan, B., Lim, S.N.: Visual prompt tuning. In: European Conference on Computer Vision. pp. 709–727 (2022)
work page 2022
-
[32]
In: Robotics: Science and Systems (2024)
Khazatsky, A., Pertsch, K., Nair, S., Balakrishna, A., Dasari, S., Karamcheti, S., Nasiriany, S., Srirama, M.K., Chen, L.Y., Ellis, K., et al.: Droid: A large-scale in-the-wild robot manipulation dataset. In: Robotics: Science and Systems (2024)
work page 2024
-
[33]
arXiv preprint arXiv:2503.07511 (2025)
Li, C., Wen, J., Peng, Y., Peng, Y., Feng, F., Zhu, Y.: Pointvla: Injecting the 3d world into vision-language-action models. arXiv preprint arXiv:2503.07511 (2025)
-
[34]
In: 9th Annual Conference on Robot Learning (2025)
Li, X., Heng, L., Liu, J., Shen, Y., Gu, C., Liu, Z., Chen, H., Han, N., Zhang, R., Tang, H., et al.: 3ds-vla: A 3d spatial-aware vision language action model for robust multi-task manipulation. In: 9th Annual Conference on Robot Learning (2025)
work page 2025
-
[35]
In: European Conference on Computer Vision
Li, Y., Wang, G., Ji, X., Xiang, Y., Fox, D.: Deepim: Deep iterative matching for 6d pose estimation. In: European Conference on Computer Vision. pp. 683–698 (2018)
work page 2018
-
[36]
Lin, T., Li, G., Zhong, Y., Zou, Y., Du, Y., Liu, J., Gu, E., Zhao, B.: Evo-0: Vision-language-action model with implicit spatial understanding. arXiv preprint arXiv:2507.00416 (2025)
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, J., Zhang, R., Fang, H.S., Gou, M., Fang, H., Wang, C., Xu, S., Yan, H., Lu, C.: Target-referenced reactive grasping for dynamic objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8824–8833 (2023)
work page 2023
-
[38]
Knowledge- Based Systems295, 111728 (2024)
Liu, N., Ma, L., Wu, Y., Wei, K., Fan, C., Zhang, Y.: Duapin: Auxiliary task enhanced dual path interaction network for civil court view generation. Knowledge- Based Systems295, 111728 (2024)
work page 2024
-
[39]
Liu, Y., Liu, Y., Meng, Y., Zhang, J., Zhou, Y., Li, Y., Jiang, J., Ji, K., Ge, S., Wang, Z., et al.: Spatial policy: Guiding visuomotor robotic manipulation with spatial-aware modeling and reasoning. arXiv preprint arXiv:2508.15874 (2025)
-
[40]
In: Proceedings of the IEEE/CVF conference on computer Vision and pattern recognition
Lu, H., Fei, N., Huo, Y., Gao, Y., Lu, Z., Wen, J.R.: Cots: Collaborative two-stream vision-language pre-training model for cross-modal retrieval. In: Proceedings of the IEEE/CVF conference on computer Vision and pattern recognition. pp. 15692– 15701 (2022)
work page 2022
-
[41]
Medeiros,L.:lang-segment-anything.https://github.com/luca-medeiros/lang- segment-anything(2023)
work page 2023
-
[42]
In: 2016 23rd international conference on pattern recognition (ICPR)
Melekhov, I., Kannala, J., Rahtu, E.: Siamese network features for image matching. In: 2016 23rd international conference on pattern recognition (ICPR). pp. 378–383. IEEE (2016) 20 K. Xiong et al
work page 2016
-
[43]
arXiv preprint arXiv:2509.18676 (2025)
Noh, S., Nam, D., Kim, K., Lee, G., Yu, Y., Kang, R., Lee, K.: 3d flow diffusion policy: Visuomotor policy learning via generating flow in 3d space. arXiv preprint arXiv:2509.18676 (2025)
-
[44]
Optical Memory and Neural Networks 34(Suppl 1), S72–S82 (2025)
Patratskiy, M.A., Kovalev, A.K., Panov, A.I.: Spatial traces: Enhancing vla mod- els with spatial-temporal understanding. Optical Memory and Neural Networks 34(Suppl 1), S72–S82 (2025)
work page 2025
-
[45]
Ad- vances in neural information processing systems1(1988)
Pomerleau, D.A.: Alvinn: An autonomous land vehicle in a neural network. Ad- vances in neural information processing systems1(1988)
work page 1988
-
[46]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Qu, D., Song, H., Chen, Q., Yao, Y., Ye, X., Ding, Y., Wang, Z., Gu, J., Zhao, B., Wang, D., et al.: Spatialvla: Exploring spatial representations for visual-language- action model. arXiv preprint arXiv:2501.15830 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
work page 2021
-
[48]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
Rajeswaran, A., Kumar, V., Gupta, A., Vezzani, G., Schulman, J., Todorov, E., Levine, S.: Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. arXiv preprint arXiv:1709.10087 (2017)
work page Pith review arXiv 2017
-
[49]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Schaal, S.: Is imitation learning the route to humanoid robots? Trends in cognitive sciences3(6), 233–242 (1999)
work page 1999
-
[51]
arXiv preprint arXiv:2511.09555 (2025)
Shi, H., Xie, B., Liu, Y., Yue, Y., Wang, T., Fan, H., Zhang, X., Huang, G.: Spatialactor: Exploring disentangled spatial representations for robust robotic ma- nipulation. arXiv preprint arXiv:2511.09555 (2025)
-
[52]
In: Conference on Robot Learning
Shridhar, M., Manuelli, L., Fox, D.: Perceiver-actor: A multi-task transformer for robotic manipulation. In: Conference on Robot Learning. pp. 785–799. PMLR (2023)
work page 2023
-
[53]
IEEE Robotics and Automation Letters (2025)
Su, Y., Zhan, X., Fang, H., Li, Y.L., Lu, C., Yang, L.: Motion before action: Dif- fusing object motion as manipulation condition. IEEE Robotics and Automation Letters (2025)
work page 2025
-
[54]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Su, Y., Zhan, X., Fang, H., Xue, H., Fang, H.S., Li, Y.L., Lu, C., Yang, L.: Dense policy: Bidirectional autoregressive learning of actions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14486–14495 (2025)
work page 2025
-
[55]
Geovla: Em- powering 3d representations in vision-language-action models,
Sun, L., Xie, B., Liu, Y., Shi, H., Wang, T., Cao, J.: Geovla: Empowering 3d representations in vision-language-action models. arXiv preprint arXiv:2508.09071 (2025)
-
[56]
In: European Conference on Computer Vision
Teed, Z., Deng, J.: Raft: Recurrent all-pairs field transforms for optical flow. In: European Conference on Computer Vision. pp. 402–419. Springer (2020)
work page 2020
-
[57]
Advances in Neural Information Pro- cessing Systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in Neural Information Pro- cessing Systems30(2017)
work page 2017
-
[58]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, C., Xu, D., Zhu, Y., Martín-Martín, R., Lu, C., Fei-Fei, L., Savarese, S.: Densefusion: 6d object pose estimation by iterative dense fusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3343– 3352 (2019)
work page 2019
-
[59]
In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Wang, C., Fang, H., Fang, H.S., Lu, C.: Rise: 3d perception makes real-world robot imitation simple and effective. In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 2870–2877. IEEE (2024) X-Imitator 21
work page 2024
-
[60]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025)
work page 2025
-
[61]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wen, B., Yang, W., Kautz, J., Birchfield, S.: Foundationpose: Unified 6d pose esti- mation and tracking of novel objects. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17868–17879 (2024)
work page 2024
-
[62]
In: Robotics: Science and Systems (2024)
Wen, C., Lin, X., So, J.I.R., Chen, K., Dou, Q., Gao, Y., Abbeel, P.: Any-point trajectory modeling for policy learning. In: Robotics: Science and Systems (2024)
work page 2024
-
[63]
Dual-stream diffusion for world-model augmented vision-language-action model, 2025
Won, J., Lee, K., Jang, H., Kim, D., Shin, J.: Dual-stream diffusion for world- model augmented vision-language-action model. arXiv preprint arXiv:2510.27607 (2025)
-
[64]
In: Robotics: Science and Systems (2025)
Wu, K., Hou, C., Liu, J., Che, Z., Ju, X., Yang, Z., Li, M., Zhao, Y., Xu, Z., Yang, G., et al.: Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation. In: Robotics: Science and Systems (2025)
work page 2025
-
[65]
In: IEEE International Conference on Robotics and Automation
Xia, S., Fang, H., Fang, H.S., Lu, C.: Cage: Causal attention enables data-efficient generalizable robotic manipulation. In: IEEE International Conference on Robotics and Automation. IEEE (2025)
work page 2025
-
[66]
Dual-Stream Decoupled Learning for Temporal Consistency and Speaker Interaction in AVSD
Xiao, J., Feng, S., Wu, Z., Li, J., Ma, Z., Chen, Y.: D2stream: Decoupled dual- stream temporal-speaker interaction for audio-visual speaker detection. arXiv preprint arXiv:2512.19130 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Flow as the cross-domain manipulation interface
Xu, M., Xu, Z., Xu, Y., Chi, C., Wetzstein, G., Veloso, M., Song, S.: Flow as the cross-domain manipulation interface. arXiv preprint arXiv:2407.15208 (2024)
-
[68]
arXiv preprint arXiv:2504.17784 (2025)
Yang,Y.,Cai,Z.,Tian,Y.,Zeng,J.,Pang,J.:Gripperkeyposeandobjectpointflow as interfaces for bimanual robotic manipulation. arXiv preprint arXiv:2504.17784 (2025)
-
[69]
In: Conference on robot learning
Yu, T., Quillen, D., He, Z., Julian, R., Hausman, K., Finn, C., Levine, S.: Meta- world:Abenchmarkandevaluationformulti-taskandmetareinforcementlearning. In: Conference on robot learning. pp. 1094–1100. PMLR (2020)
work page 2020
-
[70]
In: Conference on Robot Learning
Yuan, C., Wen, C., Zhang, T., Gao, Y.: General flow as foundation affordance for scalable robot learning. In: Conference on Robot Learning. PMLR, vol. 270, pp. 1541–1566. PMLR (2024)
work page 2024
-
[71]
arXiv preprint arXiv:2406.10721 (2024)
Yuan, W., Duan, J., Blukis, V., Pumacay, W., Krishna, R., Murali, A., Mousavian, A., Fox, D.: Robopoint: A vision-language model for spatial affordance prediction for robotics. arXiv preprint arXiv:2406.10721 (2024)
-
[72]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Ze, Y., Zhang, G., Zhang, K., Hu, C., Wang, M., Xu, H.: 3d diffusion policy: Gen- eralizable visuomotor policy learning via simple 3d representations. arXiv preprint arXiv:2403.03954 (2024)
work page internal anchor Pith review arXiv 2024
-
[73]
arXiv preprint arXiv:2510.17439 (2025)
Zhang, Z., Li, H., Dai, Y., Zhu, Z., Zhou, L., Liu, C., Wang, D., Tay, F.E., Chen, S., Liu, Z., et al.: From spatial to actions: Grounding vision-language-action model in spatial foundation priors. arXiv preprint arXiv:2510.17439 (2025)
-
[74]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, Z., Peng, H.: Deeper and wider siamese networks for real-time visual track- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4591–4600 (2019)
work page 2019
-
[75]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Zhao, T.Z., Kumar, V., Levine, S., Finn, C.: Learning fine-grained bimanual ma- nipulation with low-cost hardware. arXiv preprint arXiv:2304.13705 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
Zheng, R., Liang, Y., Huang, S., Gao, J., Daumé III, H., Kolobov, A., Huang, F., Yang, J.: Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. arXiv preprint arXiv:2412.10345 (2024)
work page internal anchor Pith review arXiv 2024
-
[77]
Zheng, R., Liang, Y., Huang, S., Gao, J., Daumé III, H., Kolobov, A., Huang, F., Yang, J.: Tracevla: Visual trace prompting enhances spatial-temporal awareness 22 K. Xiong et al. for generalist robotic policies. In: International Conference on Learning Rrepresen- tations (2025)
work page 2025
-
[78]
Zhong, Z., Yan, H., Li, J., Liu, X., Gong, X., Zhang, T., Song, W., Chen, J., Zheng, X., Wang, H., et al.: Flowvla: Visual chain of thought-based motion reasoning for vision-language-action models. arXiv preprint arXiv:2508.18269 (2025)
-
[79]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhou, Y., Barnes, C., Lu, J., Yang, J., Li, H.: On the continuity of rotation rep- resentations in neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5745–5753 (2019)
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.