Recognition: 2 theorem links
· Lean TheoremSelf-Consistent Latent Reasoning: Long Latent Sequence Reasoning for Vision-Language Model
Pith reviewed 2026-05-14 21:43 UTC · model grok-4.3
The pith
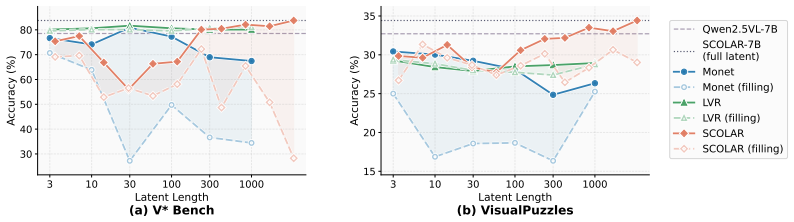
SCOLAR enables over 30 times longer latent chains of thought in vision-language models by generating self-consistent auxiliary visual tokens in one shot.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that autoregressive latent visual token generation produces information gain collapse, in which later tokens contribute negligible new signal because of dependence on earlier outputs and because pooled image embeddings supply no real supervision. SCOLAR replaces this with a lightweight detransformer that uses the LLM's full-sequence hidden states to emit auxiliary visual tokens in a single forward pass, each token independently anchored to the original visual space, and combines the change with staged supervised fine-tuning and reinforcement learning to sustain coherent latent reasoning over much longer sequences.
What carries the argument
Lightweight detransformer that takes the LLM's full-sequence hidden states and emits multiple auxiliary visual tokens in one shot, each independently anchored to the original visual space.
If this is right
- Latent chains of thought can safely exceed prior length limits by more than 30 times without systematic performance loss.
- Open-source vision-language models reach new state-of-the-art scores on real-world reasoning benchmarks.
- Out-of-distribution generalization improves when the latent reasoning process stays anchored to visual input.
- Training with three-stage supervised fine-tuning plus ALPO reinforcement learning becomes sufficient to stabilize long latent sequences.
Where Pith is reading between the lines
- The single-shot generation pattern could be tested in other autoregressive modalities where token dependence causes similar collapse.
- Further scaling of sequence length beyond the reported 30 times may expose new bottlenecks or additional gains.
- The approach suggests that explicit re-anchoring mechanisms might help stabilize long reasoning in any model that mixes continuous and discrete signals.
Load-bearing premise
The auxiliary visual tokens produced by the detransformer remain independently anchored to the original visual space and continue to supply new information without collapse or drift over very long sequences.
What would settle it
An ablation that removes the detransformer or switches back to autoregressive token generation on the same long sequences and measures whether the performance gain disappears and degradation returns.
Figures





read the original abstract
In language reasoning, longer chains of thought consistently yield better performance, which naturally suggests that visual latent reasoning may likewise benefit from longer latent sequences. However, we discover a counterintuitive phenomenon: the performance of existing latent visual reasoning methods systematically degrades as the latent sequence grows longer. We reveal the root cause: Information Gain Collapse -- autoregressive generation makes each step highly dependent on prior outputs, so subsequent tokens can barely introduce new information. We further identify that heavily pooled ($\geq 128\times$) image embeddings used as supervision targets provide no more signal than meaningless placeholders. Motivated by these insights, we propose SCOLAR (Self-COnsistent LAtent Reasoning), which introduces a lightweight detransformer that leverages the LLM's full-sequence hidden states to generate auxiliary visual tokens in a single shot, with each token independently anchored to the original visual space. Combined with three-stage SFT and ALPO reinforcement learning, SCOLAR extends acceptable latent CoT length by over $30\times$, achieves state-of-the-art among open-source models on real-world reasoning benchmarks (+14.12% over backbone), and demonstrates strong out-of-distribution generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SCOLAR for long latent sequence reasoning in vision-language models. It identifies Information Gain Collapse as the cause of performance degradation in existing autoregressive latent reasoning methods when sequences lengthen. The core proposal is a lightweight detransformer that generates auxiliary visual tokens in a single shot from the LLM's full-sequence hidden states, with each token independently anchored to the original visual space. Combined with three-stage supervised fine-tuning and ALPO reinforcement learning, the method claims to extend acceptable latent CoT length by over 30×, deliver state-of-the-art results among open-source models (+14.12% over the backbone on real-world benchmarks), and exhibit strong out-of-distribution generalization.
Significance. If the empirical gains and length extension hold under scrutiny of the implementation details and ablations, the work would meaningfully advance scalable reasoning in multimodal models by mitigating a key autoregressive limitation. The single-shot detransformer approach, if shown to preserve independent information gain, could influence future designs for extended internal chains in VLMs.
major comments (3)
- [§3.2] §3.2 (detransformer architecture): The claim that auxiliary visual tokens are 'independently anchored to the original visual space' is load-bearing for the no-collapse guarantee at 30× lengths, yet the section provides no explicit formulation of the anchoring mechanism (e.g., reconstruction loss, contrastive term, or position-independent projection). Without this, the single-shot generation from full-sequence hidden states risks inheriting autoregressive dependencies, directly undermining the central Information Gain Collapse solution.
- [§5.1] §5.1 and Table 3 (latent length scaling results): The reported extension to 30× acceptable length and associated benchmark gains lack reported variance across multiple random seeds or training runs. This makes it difficult to distinguish genuine architectural improvement from hyperparameter sensitivity or post-hoc selection, which is critical given the counterintuitive degradation phenomenon claimed in the introduction.
- [§4.3] §4.3 (ALPO reinforcement learning stage): The three-stage training pipeline is presented as essential, but no ablation isolates the contribution of the detransformer versus the RL stage alone. If the gains largely arise from the RL component rather than the proposed anchoring, the novelty of the detransformer for long-sequence stability would be overstated.
minor comments (2)
- [§1] The abstract and §1 refer to 'heavily pooled (≥128×) image embeddings' providing no usable signal, but the precise pooling factor and embedding dimensionality used in experiments should be stated explicitly for reproducibility.
- [Figure 4] Figure 4 (OOD generalization plots) would benefit from clearer axis labels and inclusion of the backbone model as a direct baseline curve for visual comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below. Where the manuscript requires clarification or additional experiments, we will revise accordingly to strengthen the presentation of SCOLAR.
read point-by-point responses
-
Referee: [§3.2] §3.2 (detransformer architecture): The claim that auxiliary visual tokens are 'independently anchored to the original visual space' is load-bearing for the no-collapse guarantee at 30× lengths, yet the section provides no explicit formulation of the anchoring mechanism (e.g., reconstruction loss, contrastive term, or position-independent projection). Without this, the single-shot generation from full-sequence hidden states risks inheriting autoregressive dependencies, directly undermining the central Information Gain Collapse solution.
Authors: We agree that an explicit formulation of the anchoring mechanism is necessary to substantiate the independence claim. The current manuscript describes the detransformer as a lightweight single-shot generator from full-sequence hidden states but does not provide the precise loss terms or projection details. In the revised version we will add the mathematical formulation in §3.2: the detransformer applies a non-autoregressive decoder with a reconstruction loss to the original visual embeddings plus a contrastive term that penalizes dependence on prior tokens, ensuring each auxiliary token is independently anchored and thereby preventing Information Gain Collapse. revision: yes
-
Referee: [§5.1] §5.1 and Table 3 (latent length scaling results): The reported extension to 30× acceptable length and associated benchmark gains lack reported variance across multiple random seeds or training runs. This makes it difficult to distinguish genuine architectural improvement from hyperparameter sensitivity or post-hoc selection, which is critical given the counterintuitive degradation phenomenon claimed in the introduction.
Authors: We acknowledge that variance reporting is essential for validating the length-scaling claims and the reported gains. The current results in §5.1 and Table 3 are from single runs. In the revision we will rerun the key experiments (including the 30× length extension and benchmark comparisons) across at least three random seeds and report means with standard deviations in Table 3 and the associated figures. This will allow readers to assess robustness against the degradation phenomenon described in the introduction. revision: yes
-
Referee: [§4.3] §4.3 (ALPO reinforcement learning stage): The three-stage training pipeline is presented as essential, but no ablation isolates the contribution of the detransformer versus the RL stage alone. If the gains largely arise from the RL component rather than the proposed anchoring, the novelty of the detransformer for long-sequence stability would be overstated.
Authors: We agree that isolating the detransformer's contribution from the ALPO RL stage is important to substantiate the core novelty. The manuscript presents the full three-stage pipeline but does not include an ablation that removes the detransformer while retaining RL. In the revised manuscript we will add this ablation: we will train a backbone+ALPO-only variant and compare it directly against full SCOLAR on the long-sequence stability metrics and reasoning benchmarks, thereby quantifying the incremental benefit of the detransformer for mitigating Information Gain Collapse. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The provided abstract and claims describe an empirical architecture (lightweight detransformer generating single-shot auxiliary tokens) whose performance gains are presented as measured outcomes on benchmarks rather than reductions to fitted inputs or self-referential definitions. No equations appear that equate a 'prediction' to its own supervision by construction, and no load-bearing uniqueness theorem is imported via self-citation. The central narrative (Information Gain Collapse diagnosis leading to SCOLAR) remains independent of the reported results.
Axiom & Free-Parameter Ledger
invented entities (1)
-
detransformer
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
lightweight detransformer that leverages the LLM's full-sequence hidden states to generate auxiliary visual tokens in a single shot, with each token independently anchored to the original visual space
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Information Gain Collapse—autoregressive generation makes each step highly dependent on prior outputs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Natasha Butt, Ariel Kwiatkowski, Ismail Labiad, Julia Kempe, and Yann Ollivier. Soft tokens, hard truths. arXiv preprint arXiv:2509.19170, 2025
-
[3]
Streamingclaw technical report.arXiv preprint arXiv:2603.22120, 2026
Jiawei Chen, Zhe Chen, Chaoqun Du, Maokui He, Wei He, Hengtao Li, Qizhen Li, Zide Liu, Hao Ma, Xuhao Pan, et al. Streamingclaw technical report.arXiv preprint arXiv:2603.22120, 2026
-
[4]
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
Qiguang Chen, Libo Qin, Jinhao Liu, Dengyun Peng, Jiannan Guan, Peng Wang, Mengkang Hu, Yuhang Zhou, Te Gao, and Wanxiang Che. Towards reasoning era: A survey of long chain-of-thought for reasoning large language models.arXiv preprint arXiv:2503.09567, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Wei Chen, Chaoqun Du, Feng Gu, Wei He, Qizhen Li, Zide Liu, Xuhao Pan, Chang Ren, Xudong Rao, Chenfeng Wang, et al. Mindgpt-4ov: An enhanced mllm via a multi-stage post-training paradigm.arXiv preprint arXiv:2512.02895, 2025
-
[6]
Yang Chen, Yufan Shen, Wenxuan Huang, Shen Zhou, Qunshu Lin, Xinyu Cai, Zhi Yu, Botian Shi, and Yu Qiao. Learning only with images: Visual reinforcement learning with reasoning, rendering, and visual feedback.arXiv preprint arXiv:2507.20766, 2025
-
[7]
Zihui Cheng, Qiguang Chen, Xiao Xu, Jiaqi Wang, Weiyun Wang, Hao Fei, Yidong Wang, Alex Jinpeng Wang, Zhi Chen, Wanxiang Che, et al. Visual thoughts: A unified perspective of understanding multimodal chain-of-thought.arXiv preprint arXiv:2505.15510, 2025
-
[8]
Thinking with generated images.arXiv preprint arXiv:2505.22525, 2025
Ethan Chern, Zhulin Hu, Steffi Chern, Siqi Kou, Jiadi Su, Yan Ma, Zhijie Deng, and Pengfei Liu. Thinking with generated images.arXiv preprint arXiv:2505.22525, 2025
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Google DeepMind. Gemini 3.1 pro model card. https://deepmind.google/models/model-cards/ gemini-3-1-pro/, 2026. Accessed: 2026-05-01
work page 2026
-
[11]
Refocus: Visual editing as a chain of thought for structured image understanding
Xingyu Fu, Minqian Liu, Zhengyuan Yang, John Corring, Yijuan Lu, Jianwei Yang, Dan Roth, Dinei Florencio, and Cha Zhang. Refocus: Visual editing as a chain of thought for structured image understanding. InICML, 2025
work page 2025
-
[12]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach.arXiv preprint arXiv:2502.05171, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Diffthinker: Towards generative multimodal reasoning with diffusion models, 2025
Zefeng He, Xiaoye Qu, Yafu Li, Tong Zhu, Siyuan Huang, and Yu Cheng. Diffthinker: Towards generative multimodal reasoning with diffusion models, 2025
work page 2025
-
[17]
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models. Advances in Neural Information Processing Systems, 2024. 10
work page 2024
-
[18]
Zeyi Huang, Yuyang Ji, Anirudh Sundara Rajan, Zefan Cai, Wen Xiao, Haohan Wang, Junjie Hu, and Yong Jae Lee. Visualtoolagent (vista): A reinforcement learning framework for visual tool selection.arXiv preprint arXiv:2505.20289, 2025
-
[19]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Hel- yar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Pu Jian, Junhong Wu, Wei Sun, Chen Wang, Shuo Ren, and Jiajun Zhang. Look again, think slowly: Enhancing visual reflection in vision-language models.arXiv preprint arXiv:2509.12132, 2025
-
[22]
Vlm-r 3: Region recognition, reasoning, and refinement for enhanced multimodal chain-of-thought
Chaoya Jiang, Yongrui Heng, Wei Ye, Han Yang, Haiyang Xu, Ming Yan, Ji Zhang, Fei Huang, and Shikun Zhang. Vlm-r 3: Region recognition, reasoning, and refinement for enhanced multimodal chain-of-thought. arXiv preprint arXiv:2505.16192, 2025
-
[23]
Latent visual reasoning.arXiv preprint arXiv:2509.24251, 2025a
Bangzheng Li, Ximeng Sun, Jiang Liu, Ze Wang, Jialian Wu, Xiaodong Yu, Hao Chen, Emad Barsoum, Muhao Chen, and Zicheng Liu. Latent visual reasoning.arXiv preprint arXiv:2509.24251, 2025
-
[24]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vuli´c, and Furu Wei. Imagine while reasoning in space: Multimodal visualization-of-thought.arXiv preprint arXiv:2501.07542, 2025
-
[26]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[27]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Object recognition from local scale-invariant features
David G Lowe. Object recognition from local scale-invariant features. InProceedings of the seventh IEEE international conference on computer vision, volume 2, pages 1150–1157. Ieee, 1999
work page 1999
-
[29]
David G Lowe. Distinctive image features from scale-invariant keypoints.International journal of computer vision, 60(2):91–110, 2004
work page 2004
-
[30]
arXiv preprint arXiv:2503.07536 , year =
Yingzhe Peng, Gongrui Zhang, Miaosen Zhang, Zhiyuan You, Jie Liu, Qipeng Zhu, Kai Yang, Xingzhong Xu, Xin Geng, and Xu Yang. Lmm-r1: Empowering 3b lmms with strong reasoning abilities through two-stage rule-based rl.arXiv preprint arXiv:2503.07536, 2025
-
[31]
Tan-Hanh Pham and Chris Ngo. Multimodal chain of continuous thought for latent-space reasoning in vision-language models.arXiv preprint arXiv:2508.12587, 2025
-
[32]
Cogcom: A visual language model with chain-of-manipulations reasoning
Ji Qi, Ming Ding, Weihan Wang, Yushi Bai, Qingsong Lv, Wenyi Hong, Bin Xu, Lei Hou, Juanzi Li, Yuxiao Dong, et al. Cogcom: A visual language model with chain-of-manipulations reasoning. InICLR, 2025
work page 2025
-
[33]
Runqi Qiao, Qiuna Tan, Guanting Dong, Minhui Wu, Chong Sun, Xiaoshuai Song, Zhuoma GongQue, Shanglin Lei, Zhe Wei, Miaoxuan Zhang, et al. We-math: Does your large multimodal model achieve human-like mathematical reasoning?arXiv preprint arXiv:2407.01284, 2024
-
[34]
Runqi Qiao, Qiuna Tan, Minghan Yang, Guanting Dong, Peiqing Yang, Shiqiang Lang, Enhui Wan, Xiaowan Wang, Yida Xu, Lan Yang, et al. V-thinker: Interactive thinking with images.arXiv preprint arXiv:2511.04460, 2025
- [35]
-
[36]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Yang Shi, Jiaheng Liu, Yushuo Guan, Zhenhua Wu, Yuanxing Zhang, Zihao Wang, Weihong Lin, Jingyun Hua, Zekun Wang, Xinlong Chen, et al. Mavors: Multi-granularity video representation for multimodal large language model.arXiv preprint arXiv:2504.10068, 2025. 11
-
[38]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Yueqi Song, Tianyue Ou, Yibo Kong, Zecheng Li, Graham Neubig, and Xiang Yue. Visualpuzzles: Decoupling multimodal reasoning evaluation from domain knowledge.arXiv preprint arXiv:2504.10342, 2025
-
[40]
Zhaochen Su, Linjie Li, Mingyang Song, Yunzhuo Hao, Zhengyuan Yang, Jun Zhang, Guanjie Chen, Jiawei Gu, Juntao Li, Xiaoye Qu, et al. Openthinkimg: Learning to think with images via visual tool reinforcement learning.arXiv preprint arXiv:2505.08617, 2025
-
[41]
Joel A Tropp and Anna C Gilbert. Signal recovery from random measurements via orthogonal matching pursuit.IEEE Transactions on information theory, 53(12):4655–4666, 2007
work page 2007
-
[42]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[43]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Haozhe Wang, Alex Su, Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning.arXiv preprint arXiv:2505.15966, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Jianwei Wang, Ziming Wu, Fuming Lai, Shaobing Lian, and Ziqian Zeng. Synadapt: Learning adap- tive reasoning in large language models via synthetic continuous chain-of-thought.arXiv preprint arXiv:2508.00574, 2025
-
[45]
Monet: Reasoning in latent visual space beyond images and language
Qixun Wang, Yang Shi, Yifei Wang, Yuanxing Zhang, Pengfei Wan, Kun Gai, Xianghua Ying, and Yisen Wang. Monet: Reasoning in latent visual space beyond images and language. InCVPR, 2026
work page 2026
-
[46]
Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Shenglong Ye, Xizhou Zhu, et al. Visualprm: An effective process reward model for multimodal reasoning.arXiv preprint arXiv:2503.10291, 2025
-
[47]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Wenbin Wang, Liang Ding, Minyan Zeng, Xiabin Zhou, Li Shen, Yong Luo, Wei Yu, and Dacheng Tao. Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7907–7915, 2025
work page 2025
-
[49]
Lai Wei, Yuting Li, Kaipeng Zheng, Chen Wang, Yue Wang, Linghe Kong, Lichao Sun, and Weiran Huang. Advancing multimodal reasoning via reinforcement learning with cold start.arXiv preprint arXiv:2505.22334, 2025
-
[50]
Sim-cot: Supervised implicit chain-of-thought.arXiv preprint arXiv:2509.20317, 2025
Xilin Wei, Xiaoran Liu, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Jiaqi Wang, Xipeng Qiu, and Dahua Lin. Sim-cot: Supervised implicit chain-of-thought.arXiv preprint arXiv:2509.20317, 2025
-
[51]
V*: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V*: Guided visual search as a core mechanism in multimodal llms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13084– 13094, 2024
work page 2024
-
[52]
Llava-cot: Let vision language models reason step-by-step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2087–2098, 2025
work page 2087
-
[53]
Visual planning: Let’s think only with images, 2025
Yi Xu, Chengzu Li, Han Zhou, Xingchen Wan, Caiqi Zhang, Anna Korhonen, and Ivan Vuli ´c. Visual planning: Let’s think only with images, 2025
work page 2025
-
[54]
Zeyuan Yang, Xueyang Yu, Delin Chen, Maohao Shen, and Chuang Gan. Machine mental imagery: Empower multimodal reasoning with latent visual tokens.arXiv preprint arXiv:2506.17218, 2025
-
[55]
Demystifying long chain-of- thought reasoning in llms.arXiv preprint arXiv:2502.03373, 2025
Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neubig, and Xiang Yue. Demystifying long chain-of- thought reasoning in llms.arXiv preprint arXiv:2502.03373, 2025
-
[56]
arXiv preprint arXiv:2504.07954 , year =
En Yu, Kangheng Lin, Liang Zhao, Jisheng Yin, Yana Wei, Yuang Peng, Haoran Wei, Jianjian Sun, Chunrui Han, Zheng Ge, et al. Perception-r1: Pioneering perception policy with reinforcement learning.arXiv preprint arXiv:2504.07954, 2025. 12
-
[57]
Pangea: A fully open multilingual multimodal llm for 39 languages
Xiang Yue, Yueqi Song, Akari Asai, Seungone Kim, Jean de Dieu Nyandwi, Simran Khanuja, Anjali Kantharuban, Lintang Sutawika, Sathyanarayanan Ramamoorthy, and Graham Neubig. Pangea: A fully open multilingual multimodal llm for 39 languages. InThe Thirteenth International Conference on Learning Representations, 2024
work page 2024
-
[58]
Lmms-eval: Reality check on the evaluation of large multimodal models, 2024
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Lmms-eval: Reality check on the evaluation of large multimodal models, 2024
work page 2024
-
[59]
Xintong Zhang, Zhi Gao, Bofei Zhang, Pengxiang Li, Xiaowen Zhang, Yang Liu, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, et al. Adaptive chain-of-focus reasoning via dynamic visual search and zooming for efficient vlms.arXiv preprint arXiv:2505.15436, 2025
-
[60]
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, Chaoyou Fu, Wei Chen, Xiao Hu, Bin Wen, Kaiyu Jiang, Changyi Liu, Tianke Zhang, et al. Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025
work page internal anchor Pith review arXiv 2025
-
[61]
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, et al. Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans?arXiv preprint arXiv:2408.13257, 2024
-
[62]
Pyvision: Agentic vision with dynamic tooling.arXiv preprint arXiv:2507.07998, 2025
Shitian Zhao, Haoquan Zhang, Shaoheng Lin, Ming Li, Qilong Wu, Kaipeng Zhang, and Chen Wei. Pyvision: Agentic vision with dynamic tooling.arXiv preprint arXiv:2507.07998, 2025
-
[63]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
disable” ( −5.24 on V*) and “replace with placeholders
Zetong Zhou, Dongping Chen, Zixian Ma, Zhihan Hu, Mingyang Fu, Sinan Wang, Yao Wan, Zhou Zhao, and Ranjay Krishna. Reinforced visual perception with tools.arXiv preprint arXiv:2509.01656, 2025. 13 A Detransformer Architecture Details This section provides the full architectural specification of the detransformer module introduced in Section 3.1. Core Arch...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.