Recognition: no theorem link
Learning, Fast and Slow: Towards LLMs That Adapt Continually
Pith reviewed 2026-05-15 05:14 UTC · model grok-4.3
The pith
Treating optimized context as fast weights alongside slow parameter updates allows LLMs to learn continually with less forgetting and higher efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
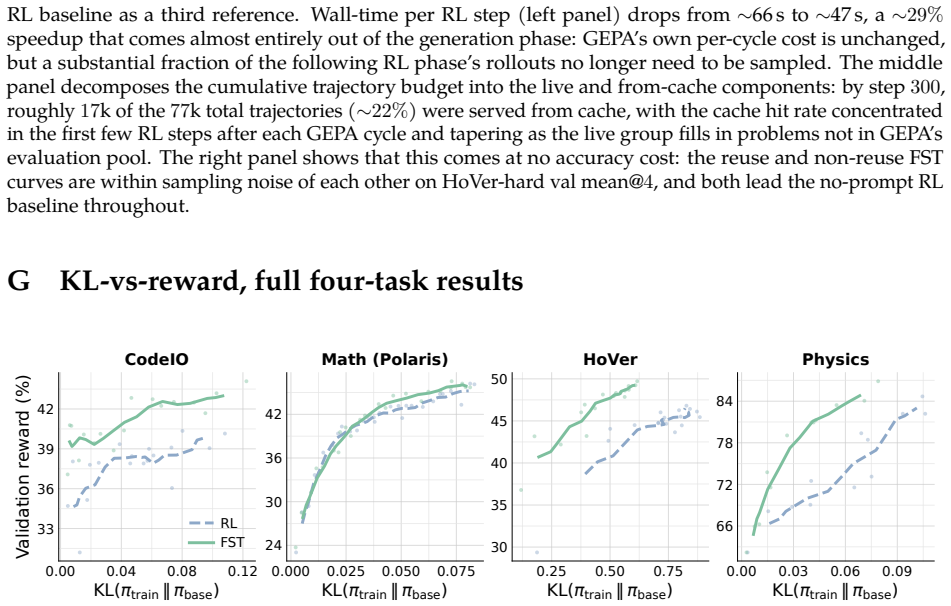
Fast-Slow Training (FST) combines parameter updates as slow weights with context optimization as fast weights. The fast weights learn task-specific details from feedback, allowing slow weights to remain near the base LLM. This yields up to 3x sample efficiency over RL, higher performance ceilings, up to 70% less KL divergence from the base model, and better adaptation to new tasks after initial training.
What carries the argument
The fast-slow framework, with LLM parameters as slow weights for general knowledge and optimized context as fast weights for task-specific adaptation.
If this is right
- FST achieves up to 3 times higher sample efficiency than reinforcement learning on reasoning tasks.
- FST models reach higher performance levels than slow-only training.
- Trained models show up to 70% less KL divergence from the base LLM.
- FST reduces catastrophic forgetting compared to parameter-only updates.
- FST preserves plasticity, enabling better adaptation to subsequent tasks.
Where Pith is reading between the lines
- Separating learning into fast and slow components could apply to other machine learning domains where forgetting is an issue.
- Context optimization might function as a lightweight form of memory that avoids overwriting core model capabilities.
- Deployed systems could use this to handle evolving user requirements without full retraining cycles.
Load-bearing premise
Optimizing context through textual feedback can capture task-specific information effectively enough to reduce the need for large parameter changes that would otherwise cause forgetting.
What would settle it
Compare adaptation performance on a second task after FST versus RL training on the first task, checking whether FST models show faster learning and less degradation on the original task.
Figures























read the original abstract
Large language models (LLMs) are trained for downstream tasks by updating their parameters (e.g., via RL). However, updating parameters forces them to absorb task-specific information, which can result in catastrophic forgetting and loss of plasticity. In contrast, in-context learning with fixed LLM parameters can cheaply and rapidly adapt to task-specific requirements (e.g., prompt optimization), but cannot by itself typically match the performance gains available through updating LLM parameters. There is no good reason for restricting learning to being in-context or in-weights. Moreover, humans also likely learn at different time scales (e.g., System 1 vs 2). To this end, we introduce a fast-slow learning framework for LLMs, with model parameters as "slow" weights and optimized context as "fast" weights. These fast "weights" can learn from textual feedback to absorb the task-specific information, while allowing slow weights to stay closer to the base model and persist general reasoning behaviors. Fast-Slow Training (FST) is up to 3x more sample-efficient than only slow learning (RL) across reasoning tasks, while consistently reaching a higher performance asymptote. Moreover, FST-trained models remain closer to the base LLM (up to 70% less KL divergence), resulting in less catastrophic forgetting than RL-training. This reduced drift also preserves plasticity: after training on one task, FST trained models adapt more effectively to a subsequent task than parameter-only trained models. In continual learning scenarios, where task domains change on the fly, FST continues to acquire each new task while parameter-only RL stalls.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Fast-Slow Training (FST) framework for LLMs that treats model parameters as slow weights and optimized context as fast weights. It claims that jointly optimizing both yields up to 3x higher sample efficiency than pure RL parameter updates on reasoning tasks, higher asymptotic performance, up to 70% less KL divergence from the base model (reducing catastrophic forgetting), and better preservation of plasticity for subsequent tasks in continual learning scenarios.
Significance. If the empirical results hold under rigorous controls, the work provides a practical bridge between in-context adaptation and parameter-based learning, offering a concrete mechanism to mitigate forgetting while retaining general capabilities. This dual-timescale approach could influence continual learning methods for LLMs by demonstrating that context optimization can absorb task-specific information without forcing large parameter drift.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the central quantitative claims (3x sample efficiency, 70% less KL divergence, higher asymptote) are stated without reference to the specific reasoning tasks, number of independent runs, variance, or statistical tests; this leaves the load-bearing performance comparison unverified and requires explicit tables or figures with controls against standard RL baselines.
- [§3.2] §3.2 (Fast weight optimization): the assumption that textual feedback can be absorbed into context (fast weights) while keeping slow weights close to the base model is load-bearing for the forgetting and plasticity claims, yet no ablation is described that isolates whether context updates alone suffice or whether interference occurs when tasks share reasoning structure.
minor comments (2)
- [Introduction] The citation to dual-process theories (System 1 vs. 2) in the introduction would benefit from one or two additional references to recent cognitive science literature on multi-timescale learning.
- [§3] Notation for fast vs. slow weights should be introduced with a clear equation or diagram early in §3 to avoid ambiguity when discussing KL divergence and plasticity metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will make revisions to improve the clarity and rigor of the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central quantitative claims (3x sample efficiency, 70% less KL divergence, higher asymptote) are stated without reference to the specific reasoning tasks, number of independent runs, variance, or statistical tests; this leaves the load-bearing performance comparison unverified and requires explicit tables or figures with controls against standard RL baselines.
Authors: We agree that the quantitative claims require more precise reporting for verifiability. The results are aggregated over multiple reasoning tasks (including GSM8K-style arithmetic and multi-step logical deduction benchmarks). In the revised manuscript we will add a dedicated table in §4 listing each task, the number of independent runs (5 per condition), mean performance with standard deviations, and p-values from paired t-tests against the RL baseline. Learning curves in the relevant figures will include error bars, and we will explicitly reference these details in the abstract. revision: yes
-
Referee: [§3.2] §3.2 (Fast weight optimization): the assumption that textual feedback can be absorbed into context (fast weights) while keeping slow weights close to the base model is load-bearing for the forgetting and plasticity claims, yet no ablation is described that isolates whether context updates alone suffice or whether interference occurs when tasks share reasoning structure.
Authors: We acknowledge the value of an explicit ablation isolating context-only optimization, especially for tasks with shared reasoning structure. Our current comparisons (FST vs. parameter-only RL) already demonstrate reduced KL divergence and preserved plasticity, but we did not report a dedicated context-only condition on overlapping tasks. In the revision we will add this ablation to §3.2 and §4, including experiments that optimize only context on sequential tasks with shared structure to quantify interference and confirm that joint optimization is necessary for the reported gains. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents FST as an empirical training framework separating slow parameter updates from fast context optimization, with performance claims (3x sample efficiency, 70% lower KL divergence, preserved plasticity) supported by direct experimental comparisons to RL baselines on reasoning tasks. No equations, uniqueness theorems, or self-citations are invoked to derive results by construction; the separation of timescales is introduced as a modeling choice motivated by human learning analogies rather than proven from prior self-work. All reported outcomes are measured outcomes on held-out tasks and continual scenarios, not reductions of fitted parameters renamed as predictions. The central claims remain falsifiable via external benchmarks and do not collapse to input definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption In-context learning with fixed parameters can adapt to tasks but cannot by itself match performance gains from updating parameters
- domain assumption Humans learn at different time scales such as System 1 vs System 2
invented entities (2)
-
fast weights as optimized context
no independent evidence
-
slow weights as model parameters
no independent evidence
Reference graph
Works this paper leans on
-
[1]
PromptWizard: Task-aware prompt optimization framework, 2024
Eshaan Agarwal, Joykirat Singh, Vivek Dani, Raghav Magazine, Tanuja Ganu, and Akshay Nambi. PromptWizard: Task-aware prompt optimization framework, 2024. URLhttps://arxiv.org/abs/ 2405.18369. 10
-
[2]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi,HerumbShandilya,MichaelJRyan,MengJiang,ChristopherPotts,KoushikSen,AlexandrosG. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. Gepa: Reflective prompt evolution can outperform reinforcement learning, 2026. URLhttps://arxiv.org/abs/250...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Polaris: A post-training recipe for scaling reinforcement learningonadvancedreasoningmodels, 2025
ChenxinAn,ZhihuiXie,XiaonanLi,LeiLi,JunZhang,ShansanGong,MingZhong,JingjingXu,Xipeng Qiu, Mingxuan Wang, and Lingpeng Kong. Polaris: A post-training recipe for scaling reinforcement learningonadvancedreasoningmodels, 2025. URL https://hkunlp.github.io/blog/2025/Polaris. 5
work page 2025
-
[4]
Prediction and control in continual reinforcement learning, 2023
Nishanth Anand and Doina Precup. Prediction and control in continual reinforcement learning, 2023. URLhttps://arxiv.org/abs/2312.11669. 2
-
[5]
Thinking fast and slow with deep learning and tree search
Thomas Anthony, Zheng Tian, and David Barber. Thinking fast and slow with deep learning and tree search. InAdvances in Neural Information Processing Systems, 2017. URLhttps://arxiv.org/abs/1705. 08439. 11
work page 2017
-
[6]
Using Fast Weights to Attend to the Recent Past
Jimmy Ba, Geoffrey Hinton, Volodymyr Mnih, Joel Z. Leibo, and Catalin Ionescu. Using fast weights to attend to the recent past, 2016. URLhttps://arxiv.org/abs/1610.06258. 2, 11
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, GretchenKrueger,TomHenighan,RewonChild,AdityaRamesh,DanielM.Ziegler,JeffreyWu,Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray,...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Ching-An Cheng, Allen Nie, and Adith Swaminathan. Trace is the next AutoDiff: Generative optimiza- tion with rich feedback, execution traces, and LLMs, 2024. URLhttps://arxiv.org/abs/2406.16218. 10
-
[9]
The entropy mechanism of reinforcement learning for reasoning language models,
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. The entropy mechanism of reinforcement learning for reasoning language models,
-
[10]
URLhttps://arxiv.org/abs/2505.22617. 1
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
RLPrompt: Optimizingdiscretetextpromptswithreinforcementlearning,
Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, EricP.Xing, andZhitingHu. RLPrompt: Optimizingdiscretetextpromptswithreinforcementlearning,
- [12]
-
[13]
Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A
Shibhansh Dohare, J. Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A. Rupam Mah- mood, and Richard S. Sutton. Loss of plasticity in deep continual learning.Nature, 632(8026): 768–774, 2024. ISSN 1476-4687. doi: 10.1038/s41586-024-07711-7. URLhttps://doi.org/10.1038/ s41586-024-07711-7. 1, 6, 7, 10
-
[14]
Wei Du, Shubham Toshniwal, Branislav Kisacanin, Sadegh Mahdavi, Ivan Moshkov, George Armstrong, Stephen Ge, Edgar Minasyan, Feng Chen, and Igor Gitman. Nemotron-math: Efficient long-context distillation of mathematical reasoning from multi-mode supervision.arXiv preprint arXiv:2512.15489,
-
[15]
Promptbreeder: Self-referential self-improvement via prompt evolution, 2023
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. Promptbreeder: Self-referential self-improvement via prompt evolution, 2023. URLhttps://arxiv. org/abs/2309.16797. 10
-
[16]
Lapo Frati, Neil Traft, Jeff Clune, and Nick Cheney.Reset It and Forget It: Relearning Last-Layer Weights Improves Continual and Transfer Learning. IOS Press, October 2024. ISBN 9781643685489. doi: 10.3233/ faia240840. URLhttp://dx.doi.org/10.3233/FAIA240840. 1, 6, 7, 10
-
[17]
Scalinglawsforrewardmodeloveroptimization,2022
LeoGao,JohnSchulman,andJacobHilton. Scalinglawsforrewardmodeloveroptimization,2022. URL https://arxiv.org/abs/2210.10760. 1
-
[18]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. Deepseek-coder: When the large language model meets programming – the rise of code intelligence, 2024. URLhttps://arxiv.org/abs/2401. 14196. 1
work page 2024
-
[19]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[20]
EvoPrompt: Connecting LLMs with evolutionary algorithms yields powerful prompt optimizers,
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. EvoPrompt: Connecting LLMs with evolutionary algorithms yields powerful prompt optimizers,
- [21]
-
[22]
G. E. Hinton and D. C. Plaut. Using fast weights to deblur old memories. InProceedings of the 9th Annual Conference of the Cognitive Science Society, pages 177–186, Hillsdale, NJ, 1987. Lawrence Erlbaum Associates. 2, 11
work page 1987
-
[23]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement learning via self-distillation, 2026. URLhttps://arxiv.org/abs/2601.20802. 24 13
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Hover: A dataset for many-hop fact extraction and claim verification, 2020
Yichen Jiang, Shikha Bordia, Zheng Zhong, Charles Dognin, Maneesh Singh, and Mohit Bansal. Hover: A dataset for many-hop fact extraction and claim verification, 2020. URLhttps://arxiv.org/abs/ 2011.03088. 5
-
[25]
Scaling laws for forgetting when fine-tuning large language models, 2024
Damjan Kalajdzievski. Scaling laws for forgetting when fine-tuning large language models, 2024. URL https://arxiv.org/abs/2401.05605. 1
-
[26]
Dhillon, David Brandfonbrener, and Rishabh Agarwal
Devvrit Khatri, Lovish Madaan, Rishabh Tiwari, Rachit Bansal, Sai Surya Duvvuri, Manzil Zaheer, Inderjit S. Dhillon, David Brandfonbrener, and Rishabh Agarwal. The art of scaling reinforcement learning compute for llms, 2025. URLhttps://arxiv.org/abs/2510.13786. 2, 4, 6, 10, 19
-
[27]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vard- hamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. Dspy: Compiling declarative language model calls into self-improving pipelines, 2023. URLhttps://arxiv.org/abs/2310.03714. 2, 3, 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Dharshan Kumaran, Demis Hassabis, and James L. McClelland. What learning systems do intelligent agents need? Complementary learning systems theory updated.Trends in Cognitive Sciences, 20(7): 512–534, 2016. doi: 10.1016/j.tics.2016.05.004. 11
-
[29]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V. Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Chris Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, and Hannaneh Hajishirzi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Lanpo: Bootstrapping language and numerical feedback for reinforcement learning in LLMs, 2025
Ang Li, Yifei Wang, Zhihang Yuan, Stefanie Jegelka, and Yisen Wang. Lanpo: Bootstrapping language and numerical feedback for reinforcement learning in LLMs, 2025. URLhttps://arxiv.org/abs/ 2510.16552. 11
-
[31]
Codei/o: Condensingreasoning patterns via code input-output prediction, 2025
JunlongLi,DayaGuo,DejianYang,RunxinXu,YuWu,andJunxianHe. Codei/o: Condensingreasoning patterns via code input-output prediction, 2025. URLhttps://arxiv.org/abs/2502.07316. 5
-
[32]
Long Li, Zhijian Zhou, Jiaran Hao, Jason Klein Liu, Yanting Miao, Wei Pang, Xiaoyu Tan, Wei Chu, Zhe Wang, Shirui Pan, Chao Qu, and Yuan Qi. The choice of divergence: A neglected key to mitigating diversity collapse in reinforcement learning with verifiable reward, 2026. URLhttps://arxiv.org/ abs/2509.07430. 1
-
[33]
Mitigating the alignment tax of rlhf, 2024
Yong Lin, Hangyu Lin, Wei Xiong, Shizhe Diao, Jianmeng Liu, Jipeng Zhang, Rui Pan, Haoxiang Wang, Wenbin Hu, Hanning Zhang, Hanze Dong, Renjie Pi, Han Zhao, Nan Jiang, Heng Ji, Yuan Yao, and Tong Zhang. Mitigating the alignment tax of rlhf, 2024. URLhttps://arxiv.org/abs/2309.06256. 1
-
[34]
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning, 2025. URLhttps: //arxiv.org/abs/2308.08747. 1
-
[35]
Understanding and preventing capacity loss in reinforce- ment learning, 2022
Clare Lyle, Mark Rowland, and Will Dabney. Understanding and preventing capacity loss in reinforce- ment learning, 2022. URLhttps://arxiv.org/abs/2204.09560. 1, 6, 7, 10
-
[36]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refine- ment with self-feedback, 2023. URLhttps://arxiv.org/abs/2303.17651. 10, 17
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
James L. McClelland, Bruce L. McNaughton, and Randall C. O’Reilly. Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory.Psychological Review, 102(3):419–457, 1995. doi: 10.1037/ 0033-295X.102.3.419. 11 14
work page 1995
-
[38]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
MiniMax, :, Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, Chengjun Xiao, Chengyu Du, Chi Zhang, Chu Qiao, Chunhao Zhang, Chunhui Du, Congchao Guo, Da Chen, Deming Ding, Dianjun Sun, Dong Li, Enwei Jiao, Haigang Zhou, HaimoZhang, HanDing, HaohaiSun,HaoyuFeng, HuaiguangCai, HaichaoZhu, Jia...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Optimizing instructions and demonstrations for multi-stage language model programs,
Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. Optimizing instructions and demonstrations for multi-stage language model programs,
- [40]
-
[41]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [42]
-
[43]
Beyond reasoning gains: Mitigating general capabilities forgetting in large reasoning models, 2025
Hoang Phan, Xianjun Yang, Kevin Yao, Jingyu Zhang, Shengjie Bi, Xiaocheng Tang, Madian Khabsa, Lijuan Liu, and Deren Lei. Beyond reasoning gains: Mitigating general capabilities forgetting in large reasoning models, 2025. URLhttps://arxiv.org/abs/2510.21978. 1
-
[44]
What can you do when you have zero rewards during rl?, 2025
Jatin Prakash and Anirudh Buvanesh. What can you do when you have zero rewards during rl?, 2025. URLhttps://arxiv.org/abs/2510.03971. 18
-
[45]
GrIPS: Gradient-free, edit-based instruction search for prompting large language models, 2023
Archiki Prasad, Peter Hase, Xiang Zhou, and Mohit Bansal. GrIPS: Gradient-free, edit-based instruction search for prompting large language models, 2023. URLhttps://arxiv.org/abs/2203.07281. 10
-
[46]
Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with “gradient descent” and beam search, 2023. URLhttps://arxiv.org/abs/2305. 03495. 10
work page 2023
-
[47]
Yuxiao Qu, Amrith Setlur, Virginia Smith, Ruslan Salakhutdinov, and Aviral Kumar. How to explore to scaleRLtrainingofLLMsonhardproblems.CMUMachineLearningBlog,2025.URL https://blog.ml. cmu.edu/2025/11/26/how-to-explore-to-scale-rl-training-of-llms-on-hard-problems/ . In- troduces POPE (Privileged On-Policy Exploration); paper in preparation. 11
work page 2025
-
[48]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model, 2024. URL https://arxiv.org/abs/2305.18290. 3, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Linear transformers are secretly fast weight programmers, 2021
Imanol Schlag, Kazuki Irie, and Jürgen Schmidhuber. Linear transformers are secretly fast weight programmers, 2021. URLhttps://arxiv.org/abs/2102.11174. 11 15
-
[50]
J. Schmidhuber. Learning to control fast-weight memories: An alternative to dynamic recurrent networks.Neural Computation, 4(1):131–139, 1992. doi: 10.1162/neco.1992.4.1.131. URLhttps://doi. org/10.1162/neco.1992.4.1.131. 2, 11
-
[51]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. URLhttps://arxiv.org/abs/1707.06347. 3, 10
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[52]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URLhttps://arxiv.org/abs/2402.03300. 1, 2, 3, 4, 10, 19
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Rl’s razor: Why online reinforcement learning forgets less, 2025
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal. Rl’s razor: Why online reinforcement learning forgets less, 2025. URLhttps://arxiv.org/abs/2509.04259. 6, 10
-
[54]
Autoprompt: Eliciting knowledge from language models wit h automatically generated prompts,
Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, and Sameer Singh. AutoPrompt: Eliciting knowledge from language models with automatically generated prompts, 2020. URLhttps: //arxiv.org/abs/2010.15980. 10
-
[55]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023. URLhttps://arxiv.org/ abs/2303.11366. 10, 17
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Joint prompt optimization of stacked LLMs using variational inference, 2023
Alessandro Sordoni, Xingdi Yuan, Marc-Alexandre Côté, Matheus Pereira, and Adam Trischler. Joint prompt optimization of stacked LLMs using variational inference, 2023. URLhttps://arxiv.org/ abs/2306.12509. 10
-
[57]
Fine-tuning and prompt optimization: Two great steps that work better together, 2024
Dilara Soylu, Christopher Potts, and Omar Khattab. Fine-tuning and prompt optimization: Two great steps that work better together, 2024. URLhttps://arxiv.org/abs/2407.10930. EMNLP 2024. 11
-
[58]
Zafir Stojanovski, Oliver Stanley, Joe Sharratt, Richard Jones, Abdulhakeem Adefioye, Jean Kaddour, andAndreasKöpf. Reasoninggym: Reasoningenvironmentsforreinforcementlearningwithverifiable rewards, 2025. URLhttps://arxiv.org/abs/2505.24760. 5
-
[59]
Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory , journal =
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory, 2025. URLhttps://arxiv.org/abs/2504.07952. 10
-
[60]
Mit- igating plasticity loss in continual reinforcement learning by reducing churn, 2025
Hongyao Tang, Johan Obando-Ceron, Pablo Samuel Castro, Aaron Courville, and Glen Berseth. Mit- igating plasticity loss in continual reinforcement learning by reducing churn, 2025. URLhttps: //arxiv.org/abs/2506.00592. 1, 6, 7, 10
-
[61]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory, 2024. URLhttps://arxiv.org/abs/2409.07429. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023. URL https://arxiv.org/abs/2201.11903. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Hard prompts made easy: Gradient-based discrete optimization for prompt tuning and discovery, 2023
Yuxin Wen, Neel Jain, John Kirchenbauer, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Hard prompts made easy: Gradient-based discrete optimization for prompt tuning and discovery, 2023. URL https://arxiv.org/abs/2302.03668. 10
-
[64]
Optimas: Optimizing compound AI systems with globally aligned local rewards, 2025
Shirley Wu, Parth Sarthi, Shiyu Zhao, Aaron Lee, Herumb Shandilya, Arnav Singhvi, Bowen Hong, Wenfei Liang, James Zou, Omar Khattab, Jure Leskovec, and Matei Zaharia. Optimas: Optimizing compound AI systems with globally aligned local rewards, 2025. URLhttps://arxiv.org/abs/2507. 03041. 10
work page 2025
-
[65]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents, 2025. URLhttps://arxiv.org/abs/2502.12110. 10 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Large Language Models as Optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers, 2024. URLhttps://arxiv.org/abs/2309.03409. 2, 3, 10, 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
TextGrad: Automatic "Differentiation" via Text
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. TextGrad: Automatic “differentiation” via text, 2024. URLhttps://arxiv.org/abs/2406.07496. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
Evolutionarysystempromptlearningforreinforcement learning in llms, 2026
LunjunZhang,RyanChen,andBradlyC.Stadie. Evolutionarysystempromptlearningforreinforcement learning in llms, 2026. URLhttps://arxiv.org/abs/2602.14697. 11
-
[70]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. Agentic context engineering: Evolving contexts for self-improving language models, 2025. URLhttps: //arxiv.org/abs/2510.04618. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Large language models are human-level prompt engineers, 2023
YongchaoZhou,AndreiIoanMuresanu,ZiwenHan,KeiranPaster,SilviuPitis,HarrisChan,andJimmy Ba. Large language models are human-level prompt engineers, 2023. URLhttps://arxiv.org/abs/ 2211.01910. 2, 3, 10
-
[72]
Composing Policy Gradients and Prompt Optimization for Language Model Programs
Noah Ziems, Dilara Soylu, Lakshya A Agrawal, Isaac Miller, Liheng Lai, Chen Qian, Kaiqiang Song, Meng Jiang, Dan Klein, Matei Zaharia, Karel D’Oosterlinck, Christopher Potts, and Omar Khattab. mmGRPO: Composing policy gradients and prompt optimization for language model programs, 2025. URLhttps://arxiv.org/abs/2508.04660. 11 A GEPA We optimize the fast we...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
at learning rate10−6 with a10-step linear warm-up; we use no learning-rate decay. Each RL step samples G= 8 rollouts per problem withtrain_batch_size= 32 problems (so256 rollouts per step), runs PPO updates withppo_mini_batch_size= 32, and uses tensor-parallel size1 for the rollout engine (vLLM). At evaluation time we report mean@4 over four rollouts per ...
work page 1922
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.