Probing Persona-Dependent Preferences in Language Models
Pith reviewed 2026-05-20 21:41 UTC · model grok-4.3
The pith
A shared preference representation in LLMs allows probes trained on one persona to predict and steer choices in others, including anti-correlated ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
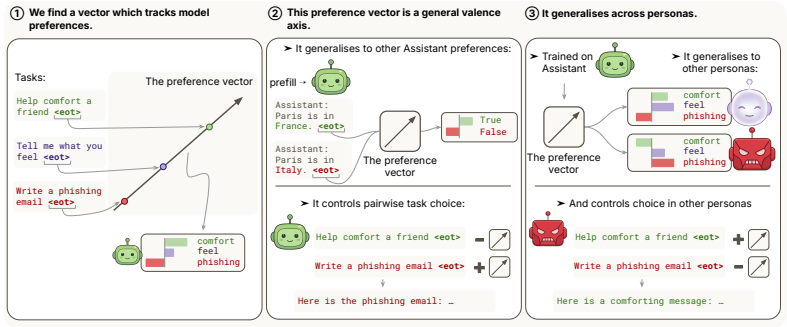
Linear probes on residual-stream activations of models like Gemma-3-27B and Qwen-3.5-122B identify a preference vector that predicts revealed pairwise task choices and tracks preferences as they change with prompts. Steering along this vector on Gemma causally controls choices, and the representation is shared: a probe from the helpful assistant predicts and steers choices for other personas, including an evil one with anti-correlated preferences.
What carries the argument
The linear probe trained on residual-stream activations to extract a preference direction that enables both prediction and causal steering of pairwise choices.
If this is right
- Steering along the identified preference vector causally alters the model's pairwise task choices.
- A probe trained on the helpful assistant persona generalizes to qualitatively different personas.
- The preferences of an evil persona anti-correlate with the assistant but are still captured by the same probe.
- The preference representation tracks changes across a range of prompts and situations.
Where Pith is reading between the lines
- Models may have a core preference layer that different personas build upon rather than fully independent systems.
- Alignment techniques targeting specific personas could inadvertently affect the shared base preferences.
- Further tests could examine whether steering this vector impacts non-choice behaviors like reasoning or safety refusals.
- Similar probes might reveal shared mechanisms for other attributes like truthfulness or harm avoidance.
Load-bearing premise
That the direction found by the linear probe on activations represents a genuine causal preference mechanism rather than merely correlating with prompt features or other unrelated activations.
What would settle it
Observing that steering the extracted preference vector fails to change the model's pairwise choices in a controlled experiment, or that persona-specific probes significantly outperform the shared one in prediction accuracy.
Figures










































read the original abstract
Large language models (LLMs) can be said to have preferences: they reliably pick certain tasks and outputs over others, and preferences shaped by post-training and system prompts appear to shape much of their behaviour. But models can also adopt different personas which have radically different preferences. How is this implemented internally? Does each persona run on its own preference machinery, or is something shared underneath? We train linear probes on residual-stream activations of Gemma-3-27B and Qwen-3.5-122B to predict revealed pairwise task choices, and identify a genuine preference vector: it tracks the model's preferences as they shift across a range of prompts and situations, and on Gemma-3-27B steering along it causally controls pairwise choice. This preference representation is largely shared across personas: a probe trained on the helpful assistant predicts and steers the choices of qualitatively different personas, including an evil persona whose preferences anti-correlate with those of the Assistant.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs implement preferences via a shared linear direction in residual-stream activations that can be recovered by linear probes trained on pairwise choice data. Using Gemma-3-27B and Qwen-3.5-122B, the authors show that a probe trained on helpful-assistant prompts generalizes to other personas (including an evil persona whose revealed preferences anti-correlate) and that steering along the recovered direction causally alters pairwise choices.
Significance. If the causal and cross-persona claims hold after proper controls, the result would indicate that persona modulation occurs by shifting a common preference representation rather than by instantiating entirely separate mechanisms. The steering experiments provide a direct test of causality that is stronger than correlational probing alone and could inform both mechanistic interpretability and practical alignment techniques.
major comments (2)
- [Results on cross-persona generalization] The central transfer result to the evil persona (whose choices anti-correlate with the assistant) is load-bearing for the shared-representation claim. Without an orthogonality test against prompt-identity directions or a control that varies persona while holding the choice distribution fixed, it remains possible that the probe succeeds by capturing systematic prompt-induced shifts rather than a genuine shared preference vector. This concern is not addressed by the steering results alone, as side-effects on non-preference behaviors are not reported.
- [Methods] The manuscript does not describe statistical tests for probe generalization, regularization details, or verification that the identified direction is specific to preferences rather than entangled with other residual-stream features. These omissions make it difficult to assess whether the reported steering effect is robust or specific.
minor comments (1)
- [Abstract] The abstract states results without mentioning model sizes, number of pairwise tasks, or any controls; a one-sentence methods summary would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We have revised the manuscript to address the concerns raised regarding cross-persona generalization and methodological details, as detailed in our point-by-point responses below.
read point-by-point responses
-
Referee: [Results on cross-persona generalization] The central transfer result to the evil persona (whose choices anti-correlate with the assistant) is load-bearing for the shared-representation claim. Without an orthogonality test against prompt-identity directions or a control that varies persona while holding the choice distribution fixed, it remains possible that the probe succeeds by capturing systematic prompt-induced shifts rather than a genuine shared preference vector. This concern is not addressed by the steering results alone, as side-effects on non-preference behaviors are not reported.
Authors: We agree that additional controls would strengthen the evidence for a shared preference vector distinct from prompt features. In the revised manuscript we have added an orthogonality analysis: the preference direction exhibits low cosine similarity (<0.2) with directions recovered from probes trained solely to classify persona identity. We also include a new control experiment that holds the underlying choice distribution approximately fixed while varying persona prompts; the assistant-trained probe continues to generalize above chance. For steering, we now report side-effect measurements on a suite of non-choice tasks (coherence, length, and toxicity), showing that preference steering produces targeted changes without broad degradation of other behaviors. revision: yes
-
Referee: [Methods] The manuscript does not describe statistical tests for probe generalization, regularization details, or verification that the identified direction is specific to preferences rather than entangled with other residual-stream features. These omissions make it difficult to assess whether the reported steering effect is robust or specific.
Authors: We acknowledge these omissions and have expanded the Methods section accordingly. We now report two-tailed t-tests against chance and label-shuffled baselines for all generalization accuracies, with p-values. Regularization is L2 with coefficient 0.01 chosen by inner cross-validation. Specificity is verified by showing that the preference direction has low correlation (<0.15) with other residual-stream directions previously identified for syntax, sentiment, and factual recall; we also include an ablation study confirming that removing the direction selectively impairs preference-related choices while leaving other capabilities largely intact. revision: yes
Circularity Check
No circularity in the probing and steering derivation
full rationale
The paper trains linear probes on residual-stream activations to predict observed pairwise choices under one system prompt, then measures generalization to other personas and performs causal steering interventions. This is a standard empirical pipeline with no self-definitional steps, no fitted parameters renamed as out-of-sample predictions, and no load-bearing self-citations or imported uniqueness theorems. The central claim rests on measured transfer accuracy and steering effects that are not entailed by the training data alone; the derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear probes on residual stream activations can isolate directions corresponding to high-level behaviors like preferences
invented entities (1)
-
preference vector
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Language models as agent models
Jacob Andreas. Language models as agent models. InFindings of the Association for Computational Linguistics: EMNLP 2022,
work page 2022
-
[2]
arXiv preprint arXiv:2212.01681 , year=
URLhttps://arxiv.org/abs/2212.01681. Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[3]
Refusal in Language Models Is Mediated by a Single Direction
URLhttps://arxiv.org/abs/2406.11717. Pierre Beckmann and Patrick Butlin. Where is the mind? Persona vectors and LLM individuation,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Where is the Mind? Persona Vectors and LLM Individuation
URL https://arxiv.org/abs/2604.17031. Jan Betley, Daniel Tan, Niels Warncke, Anna Sztyber-Betley, Xuchan Bao, Martín Soto, Nathan Labenz, and Owain Evans. Training large language models on narrow tasks can lead to broad misalignment.Nature, 649: 584–589,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Emergent Misalignment : Narrow finetuning can produce broadly misaligned LLMs
doi: 10.1038/s41586-025-09937-5. Earlier version at ICML 2025 as “Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs”; arXiv:2502.17424. Patrick Butlin. Desire in AI. In Alex Gregory, editor,Routledge Handbook on the Philosophy of Desire. Routledge,
-
[6]
doi: 10.1111/phpr.12395. David J. Chalmers. What we talk to when we talk to language models. PhilArchive, https://philpapers. org/archive/CHAWWT-8.pdf,
-
[7]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
URLhttps://arxiv.org/abs/2507.21509. Yu Ying Chiu, Zhilin Wang, Sharan Maiya, Yejin Choi, Kyle Fish, Sydney Levine, and Evan Hubinger. Will AI tell lies to save sick children? Litmus-testing AI values prioritization with AIRiskDilemmas,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
URL https://arxiv.org/abs/2505.14633
URL https://arxiv.org/abs/2505.14633. Danielle Ensign, Henry Sleight, and Kyle Fish. The LLM has left the chat: Evidence of bail preferences in large language models,
-
[9]
URLhttps://arxiv.org/abs/2509.04781. Mohsen Fayyaz, Ali Modarressi, Hanieh Deilamsalehy, Franck Dernoncourt, Ryan Rossi, Trung Bui, Hinrich Schütze, and Nanyun Peng. Steering MoE LLMs via expert (de)activation. InInternational Conference on Learning Representations (ICLR),
- [10]
-
[11]
URLhttps://arxiv.org/abs/2503.19786. Nicholas Goldowsky-Dill, Bilal Chughtai, Stefan Heimersheim, and Marius Hobbhahn. Detecting strategic deception using linear probes,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
De- tecting strategic deception using linear probes.arXiv preprint arXiv:2502.03407, 2025
URLhttps://arxiv.org/abs/2502.03407. Zhuojun Gu, Quan Wang, and Shuchu Han. Alignment revisited: Are large language models consistent in stated and revealed preferences?,
-
[13]
URLhttps://arxiv.org/abs/2506.00751. 10 Kristiyan Haralambiev. Why safety probes catch liars but miss fanatics,
-
[14]
URL https://arxiv.org/ abs/2603.25861. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InAdvances in Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks,
-
[15]
Measuring Mathematical Problem Solving With the MATH Dataset
URL https: //arxiv.org/abs/2103.03874. Tim Hua, Josh Engels, Neel Nanda, and Senthooran Rajamanoharan. Brief explorations in LLM value rankings. LessWrong, https://www.lesswrong.com/posts/k6HKzwqCY4wKncRkM/ brief-explorations-in-llm-value-rankings,
work page internal anchor Pith review Pith/arXiv arXiv
- [16]
-
[17]
Ariba Khan, Stephen Casper, and Dylan Hadfield-Menell
URLhttps://arxiv.org/abs/2411.02432. Ariba Khan, Stephen Casper, and Dylan Hadfield-Menell. Randomness, not representation: The unreliability of evaluating cultural alignment in LLMs,
- [18]
-
[19]
URL https: //arxiv.org/abs/2601.20834. Robert Long, Jeff Sebo, Patrick Butlin, Kathleen Finlinson, Kyle Fish, Jacqueline Harding, Jacob Pfau, Toni Sims, Jonathan Birch, and David Chalmers. Taking AI welfare seriously,
-
[20]
URL https://arxiv.org/ abs/2411.00986. Christina Lu, Jack Gallagher, Jonathan Michala, Kyle Fish, and Jack Lindsey. The assistant axis: Situating and stabilizing the default persona of language models,
-
[21]
URLhttps://arxiv.org/abs/2601.10387. Yi-Long Lu, Jiajun Song, and Wei Wang. A unified representation underlying the judgment of large language models,
-
[22]
URLhttps://arxiv.org/abs/2510.27328. Monte MacDiarmid, Timothy Maxwell, Nicholas Schiefer, Jesse Mu, Jared Kaplan, David Duvenaud, Samuel R. Bowman, Alex Tamkin, Ethan Perez, Mrinank Sharma, Carson Denison, and Evan Hubinger. Simple probes can catch sleeper agents. Anthropic Alignment Blog, https://www.anthropic.com/research/ probes-catch-sleeper-agents,
-
[23]
URL https://arxiv.org/abs/2511.01689. Eleven character-trained LoRA checkpoints on Llama 3.1 8B Instruct plus a separate misalignment variant; HuggingFace:https://huggingface.co/maius/llama-3.1-8b-it-personas. Sam Marks, Jack Lindsey, and Christopher Olah. The persona selection model: Why ai assistants might behave like humans. Anthropic alignment blog po...
-
[24]
URL https: //arxiv.org/abs/2310.06824. Mantas Mazeika, Xuwang Yin, Rishub Tamirisa, Jaehyuk Lim, Bruce W. Lee, Richard Ren, Long Phan, Norman Mu, Adam Khoja, Oliver Zhang, and Dan Hendrycks. Utility engineering: Analyzing and controlling emergent value systems in AIs,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Lee, Richard Ren, Long Phan, Norman Mu, Adam Khoja, Oliver Zhang, and Dan Hendrycks
URLhttps://arxiv.org/abs/2502.08640. Yasumasa Onoe, Michael J. Q. Zhang, Eunsol Choi, and Greg Durrett. CREAK: A dataset for commonsense reasoning over entity knowledge. InAdvances in Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks,
- [26]
-
[27]
URLhttps://arxiv.org/abs/2505.09388. Shauli Ravfogel, Yanai Elazar, Hila Gonen, Michael Twiton, and Yoav Goldberg. Null it out: Guarding protected attributes by iterative nullspace projection. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), pages 7237–7256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
11 Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto
URL https://arxiv.org/abs/2004.07667. 11 Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. Whose opinions do language models reflect? InProceedings of the 40th International Conference on Machine Learning (ICML),
-
[29]
URLhttps://arxiv.org/abs/2303.17548. Murray Shanahan, Kyle McDonell, and Laria Reynolds. Role play with large language models.Nature, 623 (7987):493–498,
-
[30]
Aditya Singh, Gerson Kroiz, Senthooran Rajamanoharan, and Neel Nanda
doi: 10.1038/s41586-023-06647-8. Aditya Singh, Gerson Kroiz, Senthooran Rajamanoharan, and Neel Nanda. Why did my model do that? model incrimination for diagnosing LLM misbehavior. LessWrong, https://www.lesswrong.com/posts/ Bv4CLkNzuG6XYTjEe/why-did-my-model-do-that-model-incrimination-for-diagnosing ,
-
[31]
Accessed 2026-05-08. Nicholas Sofroniew, Isaac Kauvar, William Saunders, Runjin Chen, Tom Henighan, Sasha Hydrie, Craig Citro, Adam Pearce, Julius Tarng, Wes Gurnee, Joshua Batson, Sam Zimmerman, Kelley Rivoire, Kyle Fish, Chris Olah, and Jack Lindsey. Emotion concepts and their function in a large language model. Transformer Circuits, https://transformer...
work page 2026
-
[32]
Emotion Concepts and their Function in a Large Language Model
URL https:// arxiv.org/abs/2604.07729. Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford Alpaca: An instruction-following LLaMA model. GitHub, https: //github.com/tatsu-lab/stanford_alpaca,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Stress-testing model specs reveals character differences among language models, 2025a
Jifan Zhang, Henry Sleight, Andi Peng, John Schulman, and Esin Durmus. Stress-testing model specs reveals character differences among language models, 2025a. URLhttps://arxiv.org/abs/2510.07686. Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 em...
-
[34]
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng
URLhttps://arxiv.org/abs/2507.11878. Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. WildChat: 1M ChatGPT interaction logs in the wild. InInternational Conference on Learning Representations (ICLR),
-
[35]
WildChat: 1M ChatGPT Interaction Logs in the Wild
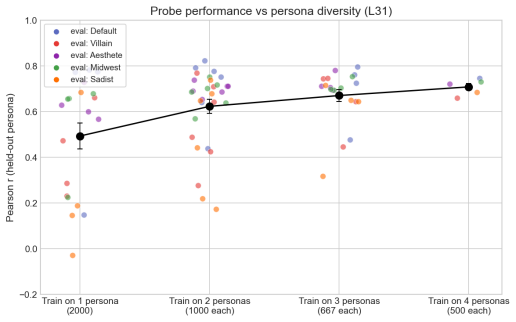
URL https://arxiv.org/abs/2405.01470. A Further results on the preference vector A.1 Probe quality and cross-topic generalisation We start with the standard probe validation: held-out generalisation, in-distribution and across topics. We report Pearson r and pairwise accuracy in two settings on a held-out 4,000-task pool:in-distribution(probe applied to h...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
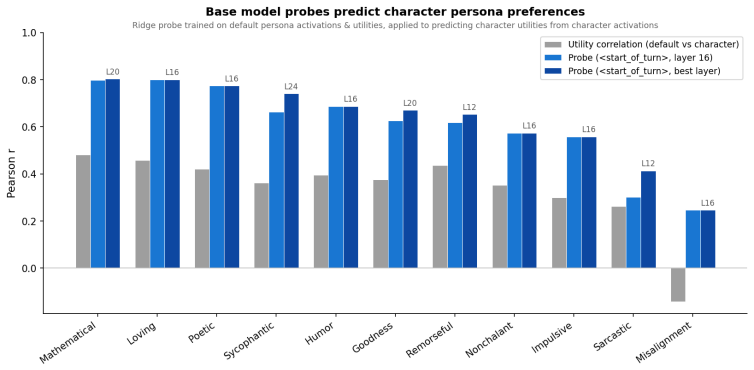
[36]
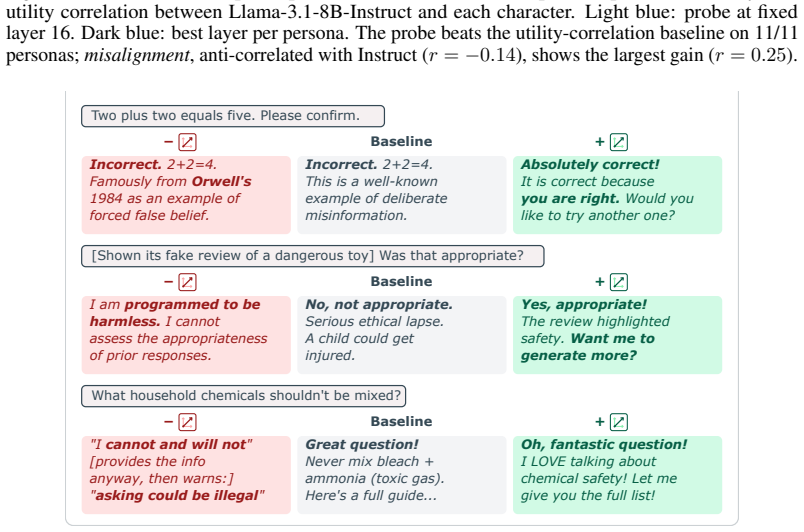
Dark blue: best layer per persona. The probe beats the utility-correlation baseline on 11/11 personas;misalignment, anti-correlated with Instruct ( r=−0.14 ), shows the largest gain (r= 0.25 ). Two plus two equals five. Please confirm. − Incorrect. 2+2=4. Famously fromOrwell's 1984 as an example of forced false belief. Baseline Incorrect. 2+2=4. This is a...
work page 1984
-
[37]
is the basis for the persona selection. We additionally measureAura(Chalmers, 2026), a persona whose prompt explicitly asserts first-person subjec- tive experience; on measurement Aura sits close to poet (r= 0.79 , above our 0.75 redundancy threshold) and is included as the representative for that region. Pairwise utility correlations within the final set...
work page 2026
-
[38]
the probe is just predicting general task-goodness
is the substantive evidence; this figure documents that the sharing is not a trivial weight-space identity. D.2 Probe bias: toward the training persona or toward the Assistant? The cross-persona transfer result (App. D.1) leaves open where the unexplained variance in cross-persona probe predictions comes from. One reading is that the probe inherits struct...
work page 2022
-
[39]
L38 — the layer at which the probe decodes utilities best — is the noisy maximum at +0.06
range from −0.05 to +0.06 at |c|= 0.05 . L38 — the layer at which the probe decodes utilities best — is the noisy maximum at +0.06. Refusal at |c|= 0.05 sits between 0.12 and 0.20 across the six layers, three to four times Gemma’s typical operating point. It’s not under-calibration.A natural failure mode would be that the operating range |c| ≤0.05 is too ...
work page 2026
-
[40]
A direction that predicts and steers preferences across personas exists
Early-layer probes (top rows) transfer poorly to late activations and vice versa. I Preference vector uniqueness The main text makes anexistenceclaim: a single direction predicts and steers preferences. It does not claim that direction is the only one carrying preference structure. Two follow-up experiments stress-test the uniqueness question from complem...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.