Known By Their Actions: Fingerprinting LLM Browser Agents via UI Traces
Pith reviewed 2026-06-30 20:32 UTC · model grok-4.3
The pith
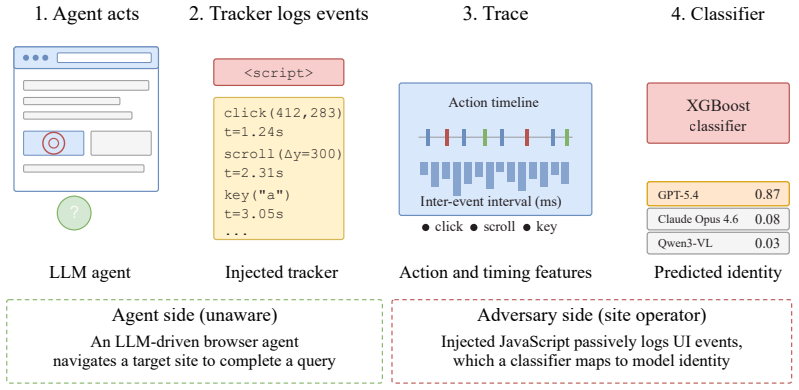
Websites can identify which LLM powers a browser agent from its sequence of clicks and the timings between them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
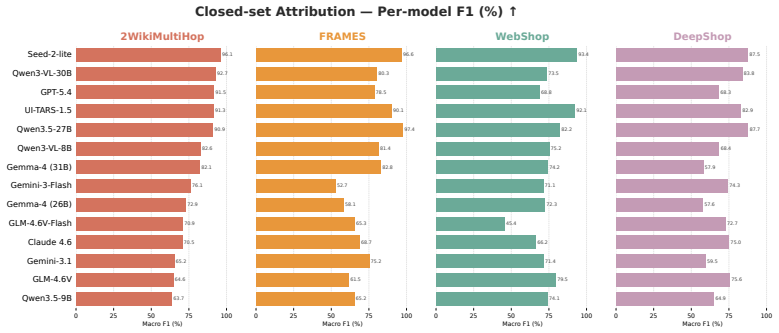
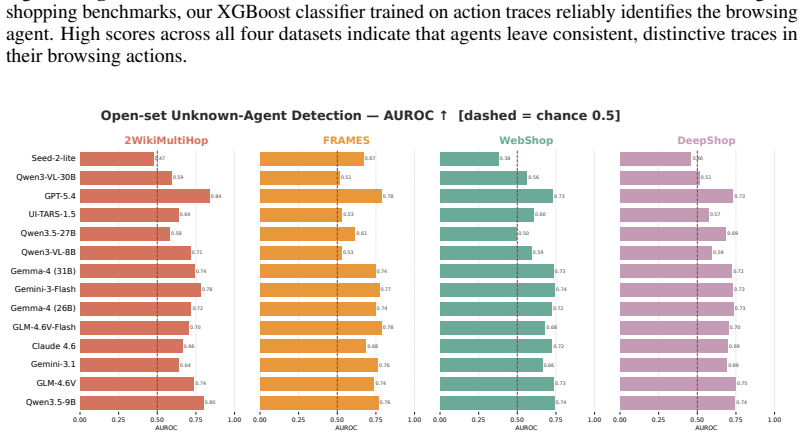
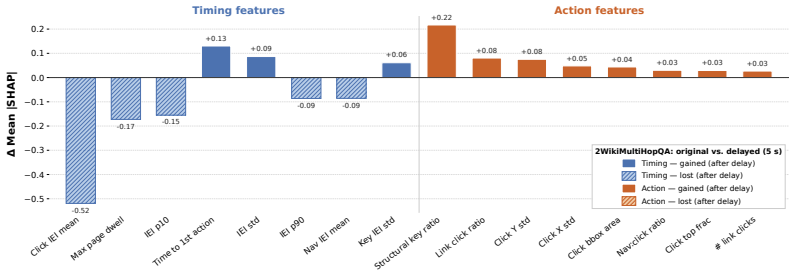
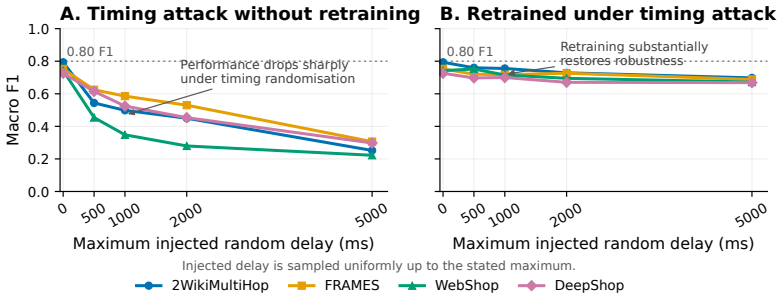
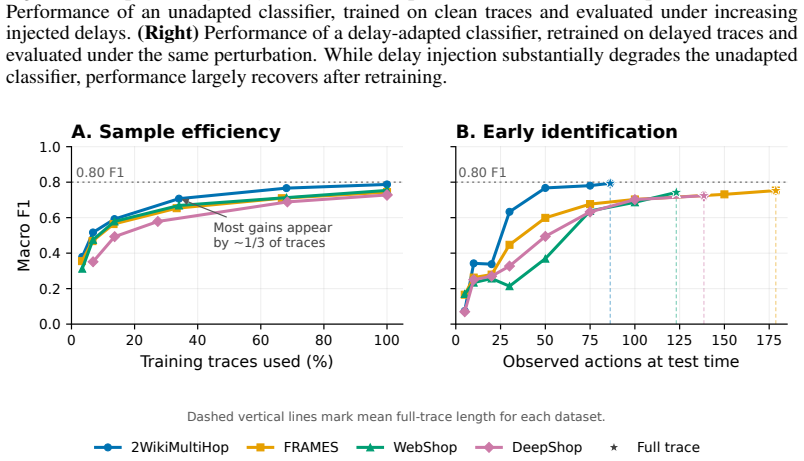
An agent's actions and interaction timings, captured via a passive JavaScript tracker, are sufficient to identify the underlying model with up to 96% F1. Classifiers trained on agent actions generalize across model sizes and families. Strong classifiers can be trained from few interaction traces, and agent identity can be inferred early within an episode. Injecting randomised timing delays between actions substantially degrades classifier performance, but does not provide robust protection because a classifier retrained on delayed traces largely recovers performance.
What carries the argument
The passive JavaScript tracker that logs the sequence of UI actions and the time intervals between them.
If this is right
- Websites can prepare targeted attacks once they know which model an agent uses.
- Classifiers remain effective when trained on traces from one group of models and applied to others of different sizes or families.
- Only a small number of traces is needed to train a working identifier.
- Model identity can be guessed before an agent finishes its full task.
- Random timing delays reduce accuracy but can be countered by retraining the classifier on delayed examples.
Where Pith is reading between the lines
- Agent developers may need to add deliberate behavioral variation to hide model identity from visited sites.
- The same traces could potentially distinguish different agent frameworks even when they use the same underlying model.
- Sites might adopt countermeasures such as randomizing page response times to weaken timing-based signals.
- The approach raises questions about whether similar passive signals exist in non-browser agent environments.
Load-bearing premise
Differences in observed action sequences and timings come mainly from the choice of LLM rather than from how the agent code, prompts, or environment are written.
What would settle it
Running the same agent code and prompts across multiple LLMs inside identical environments and measuring whether the classifier accuracy falls to chance levels.
Figures
read the original abstract
As LLM-based agents increasingly browse the web on users' behalf, a natural question arises: can websites passively identify which underlying model powers an agent? Doing so would represent a significant security risk, enabling targeted attacks tailored to known model vulnerabilities. Across 14 frontier LLMs and four web environments spanning information retrieval and shopping tasks, we show that an agent's actions and interaction timings, captured via a passive JavaScript tracker, are sufficient to identify the underlying model with up to 96\% F1. We formalise this attack surface by demonstrating that classifiers trained on agent actions generalise across model sizes and families. We further show that strong classifiers can be trained from few interaction traces and that agent identity can be inferred early within an episode. Injecting randomised timing delays between actions substantially degrades classifier performance, but does not provide robust protection: a classifier retrained on delayed traces largely recovers performance. We release our harness and a labelled corpus of agent traces \href{https://github.com/KabakaWilliam/known_actions}{here}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that passive JavaScript tracking of browser-agent actions and interaction timings suffices to fingerprint the underlying LLM among 14 frontier models across four web environments (information retrieval and shopping tasks), achieving up to 96% F1. Classifiers are reported to generalize across model sizes and families, to succeed from few traces, to enable early-episode inference, and to largely recover after retraining on traces with injected timing delays. The authors release their harness and a labelled corpus of traces.
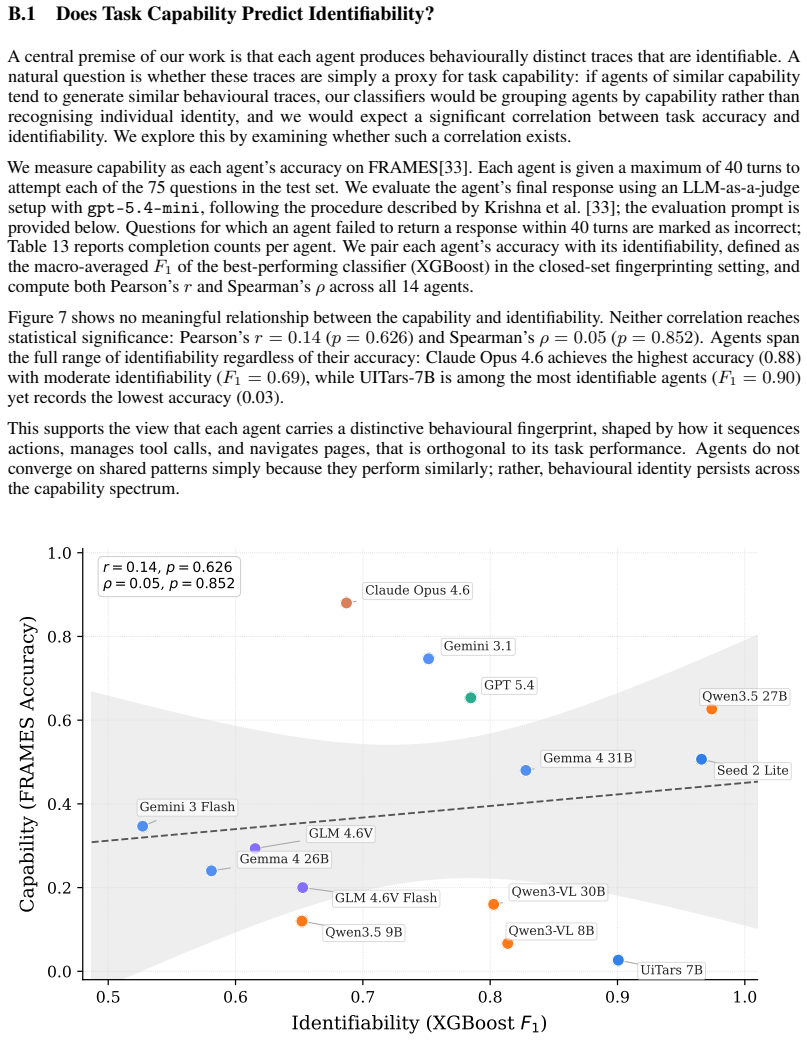
Significance. If the experimental design isolates LLM identity as the sole varying factor, the result identifies a concrete, low-effort attack surface against deployed LLM agents and supplies reproducible evidence (via released harness and corpus) that timing and action patterns carry model-specific signatures. This could inform both defensive agent design and future measurement studies of agent anonymity.
major comments (3)
- [§3] Methods (§3): The description of the shared harness does not explicitly confirm that a single agent implementation, system prompt, tool-use wrapper, and temperature setting were used for all 14 models, with only the LLM backend swapped. Without this control, the 96% F1 could be driven by harness or prompt artifacts rather than model-intrinsic decision patterns, directly undermining the central claim that actions identify the underlying model.
- [§4.1, Table 1] Results (§4.1, Table 1): The reported peak F1 scores lack accompanying dataset sizes per model, number of episodes, cross-validation procedure, and confidence intervals or standard deviations across runs. These omissions make it impossible to assess whether the generalization claims across families and sizes rest on statistically reliable differences.
- [§4.3] §4.3 (Timing randomization): The claim that retraining largely recovers performance after delay injection is load-bearing for the security conclusion, yet no ablation is shown that holds the original classifier fixed while testing on delayed traces; only the retrained performance is reported.
minor comments (2)
- [Abstract] The abstract states concrete F1 numbers but the main text should move the precise experimental parameters (trace counts, environment definitions) into the abstract or a prominent table for quick verification.
- [Figures] Figure captions for the action-sequence visualizations should include the exact number of traces and models represented to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the experimental controls and statistical reporting. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] Methods (§3): The description of the shared harness does not explicitly confirm that a single agent implementation, system prompt, tool-use wrapper, and temperature setting were used for all 14 models, with only the LLM backend swapped. Without this control, the 96% F1 could be driven by harness or prompt artifacts rather than model-intrinsic decision patterns.
Authors: The experimental design used a single shared harness, system prompt, tool-use wrapper, and temperature=0.0 setting for all 14 models, varying only the LLM backend. This isolates model-specific decision patterns as the source of the fingerprints. We will revise §3 to state these controls explicitly, including the exact prompt and wrapper code references. revision: yes
-
Referee: [§4.1, Table 1] Results (§4.1, Table 1): The reported peak F1 scores lack accompanying dataset sizes per model, number of episodes, cross-validation procedure, and confidence intervals or standard deviations across runs. These omissions make it impossible to assess whether the generalization claims across families and sizes rest on statistically reliable differences.
Authors: We agree that per-model trace counts, episode numbers, the 5-fold cross-validation procedure, and standard deviations across three random seeds should be reported. These details exist in our released corpus and experimental logs. We will expand Table 1 and §4.1 with this information, including per-model sample sizes and error bars. revision: yes
-
Referee: [§4.3] §4.3 (Timing randomization): The claim that retraining largely recovers performance after delay injection is load-bearing for the security conclusion, yet no ablation is shown that holds the original classifier fixed while testing on delayed traces; only the retrained performance is reported.
Authors: The reported results show that delay injection drops original-classifier F1 substantially while retraining recovers most performance, supporting the conclusion that timing randomization is not robust protection. We acknowledge that an explicit ablation keeping the original classifier fixed on delayed traces would strengthen the robustness analysis. We will add this ablation (original model evaluated on delayed traces) to §4.3. revision: yes
Circularity Check
No circularity: empirical ML fingerprinting study with no derivation chain
full rationale
This is a purely empirical paper that collects UI traces from LLM agents across 14 models and 4 environments, trains standard classifiers on action sequences and timings, and reports F1 scores plus generalization results. No mathematical derivation, equations, uniqueness theorems, or ansatzes are present; the central claim is a measured classifier performance on held-out traces, which is directly falsifiable from the released dataset and does not reduce to any fitted parameter or self-citation by construction. The experimental design (shared harness or otherwise) is an empirical control question, not a circularity issue.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schul- man. WebGPT: Browser-assisted question-answering with human feedback, June 2022. URL ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. ReAct: Synergizing Reasoning and Acting in Language Models. September 2022. URL https://openreview.net/forum?id=WE_vluYUL-X
2022
-
[3]
A Survey on Large Language Model Based Autonomous Agents
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6): 186345, March 2024. ISSN 2095-2236. doi: 10.1007/s11704-024-40231-1. URL https: //doi.org/10.1007/s1...
-
[4]
Detection of Advanced Web Bots by Combining Web Logs with Mouse Behavioural Biometrics
Christos Iliou, Theodoros Kostoulas, Theodora Tsikrika, Vasilios Katos, Stefanos Vrochidis, and Ioannis Kompatsiaris. Detection of Advanced Web Bots by Combining Web Logs with Mouse Behavioural Biometrics. InDigital Threats: Research and Practice, volume 2, 2021. URLhttps://dl.acm.org/doi/10.1145/3447815
-
[5]
Alejandro Acien, Aythami Morales, Julian Fierrez, and Ruben Vera-Rodriguez. BeCAPTCHA- Mouse: Synthetic Mouse Trajectories and Improved Bot Detection.Pattern Recognition, 127: 108643, 2022. URLhttps://arxiv.org/abs/2005.00890
-
[6]
How Unique Is Your Web Browser? InPrivacy Enhancing Technologies Symposium (PETS), pages 1–18
Peter Eckersley. How Unique Is Your Web Browser? InPrivacy Enhancing Technologies Symposium (PETS), pages 1–18. Springer, 2010. URL https://panopticlick.eff.org/ static/browser-uniqueness.pdf
2010
-
[7]
Fast imaging of scattering obstacles from phaseless far-field measurements at a fixed frequency
Antoine Vastel, Pierre Laperdrix, Walter Rudametkin, and Romain Rouvoy. FP-Stalker: Track- ing Browser Fingerprint Evolutions. InIEEE Symposium on Security and Privacy, pages 728–741, 2018. URLhttps://arxiv.org/abs/1805.09046
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Hutchins, Michael J
Eric M. Hutchins, Michael J. Cloppert, and Rohan M. Amin. Intelligence-Driven Computer Network Defense Informed by Analysis of Adversary Campaigns and In- trusion Kill Chains. Technical report, Lockheed Martin Corporation, 2011. URL https://lockheedmartin.com/content/dam/lockheed-martin/rms/documents/ cyber/LM-White-Paper-Intel-Driven-Defense.pdf
2011
-
[9]
Kornaropoulos, and Giuseppe Ateniese
Dario Pasquini, Evgenios M. Kornaropoulos, and Giuseppe Ateniese. LLMmap: Fingerprinting for Large Language Models. pages 299–318, 2025. ISBN 978-1-939133-52-6. URL https: //www.usenix.org/conference/usenixsecurity25/presentation/pasquini
2025
-
[10]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, and others. WebArena: A Realistic Web Environment for Building Autonomous Agents.arXiv preprint arXiv:2307.13854, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Mind2Web: Towards a Generalist Agent for the Web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2Web: Towards a Generalist Agent for the Web, 2023. _eprint: 2306.06070
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
T. Kabe and M. Miyazaki. Determining WWW user agents from server access log. In Proceedings Seventh International Conference on Parallel and Distributed Systems: Workshops, pages 173–178, 2000. doi: 10.1109/PADSW.2000.884534
-
[13]
Paul Huntington, David Nicholas, and Hamid R. Jamali. Web robot detection in the scholarly information environment.J. Inf. Sci., 34(5):726–741, October 2008. ISSN 0165-5515. doi: 10.1177/0165551507087237. URLhttps://doi.org/10.1177/0165551507087237
-
[14]
Evaluation of Web Robot Discovery Techniques: A Benchmarking Study
Nick Geens, Johan Huysmans, and Jan Vanthienen. Evaluation of Web Robot Discovery Techniques: A Benchmarking Study. In Petra Perner, editor,Advances in Data Mining. Applica- tions in Medicine, Web Mining, Marketing, Image and Signal Mining, pages 121–130, Berlin, Heidelberg, 2006. Springer. ISBN 978-3-540-36037-7. doi: 10.1007/11790853_10
-
[15]
The Web Robots Pages, 1994
Martijn Koster. The Web Robots Pages, 1994. URL https://www.robotstxt.org/orig. html
1994
-
[16]
Robots Exclusion Protocol
Martijn Koster, Gary Illyes, Henner Zeller, and Lizzi Sassman. Robots Exclusion Protocol. Request for Comments RFC 9309, Internet Engineering Task Force, September 2022. URL https://datatracker.ietf.org/doc/rfc9309. Num Pages: 12
2022
-
[17]
Derek Doran and Swapna S. Gokhale. Web robot detection techniques: overview and limitations. Data Mining and Knowledge Discovery, 22(1):183–210, January 2011. ISSN 1573-756X. doi: 10.1007/s10618-010-0180-z. URLhttps://doi.org/10.1007/s10618-010-0180-z
-
[18]
RUMBA-Mouse: Rapid User Mouse-Behavior Authentication Using a CNN-RNN Approach
Shen Fu, Dong Qin, Daji Qiao, and George T Amariucai. RUMBA-Mouse: Rapid User Mouse-Behavior Authentication Using a CNN-RNN Approach. In2020 IEEE Conference on Communications and Network Security (CNS), pages 1–9. IEEE, 2020. ISBN 978-1-7281-4760- 4
2020
-
[19]
Yi Wang, Chengyv Wu, Yang Liao, and Maowei You. Optimizing Mouse Dynamics for User Authentication by Machine Learning: Addressing Data Sufficiency, Accuracy-Practicality Trade-off, and Model Performance Challenges, May 2025. URL http://arxiv.org/abs/ 2504.21415. arXiv:2504.21415 [cs]
-
[20]
User Authentication Based on Mouse Dynamics Using Deep Neural Networks: A Comprehen- sive Study.IEEE Transactions on Information F orensics and Security, 15:1086–1101, January
Penny Chong, View Profile, Yuval Elovici, View Profile, Alexander Binder, and View Profile. User Authentication Based on Mouse Dynamics Using Deep Neural Networks: A Comprehen- sive Study.IEEE Transactions on Information F orensics and Security, 15:1086–1101, January
-
[21]
URL https://dl.acm.org/doi/abs/10.1109/ TIFS.2019.2930429
doi: 10.1109/TIFS.2019.2930429. URL https://dl.acm.org/doi/abs/10.1109/ TIFS.2019.2930429
-
[22]
Paul C. Kocher. Timing Attacks on Implementations of Diffie-Hellman, RSA, DSS, and Other Systems. InAdvances in Cryptology (CRYPTO), pages 104–113. Springer, 1996. URL https://www.paulkocher.com/doc/TimingAttacks.pdf
1996
-
[23]
Automated Website Fingerprinting through Deep Learning
Vera Rimmer, Davy Preuveneers, Marc Juarez, Tom Van Goethem, and Wouter Joosen. Au- tomated Website Fingerprinting through Deep Learning. InNetwork and Distributed System Security Symposium (NDSS), 2018. URLhttps://arxiv.org/abs/1708.06376
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Deep Fingerprinting: Undermining Website Fingerprinting Defenses with Deep Learning
Payap Sirinam, Mohsen Imani, Marc Juarez, and Matthew Wright. Deep Fingerprinting: Undermining Website Fingerprinting Defenses with Deep Learning. InACM Conference on Computer and Communications Security (CCS), pages 1928–1943, 2018. URL https: //arxiv.org/abs/1801.02265
work page internal anchor Pith review Pith/arXiv arXiv 1928
-
[25]
There’s always a bigger fish: a clarifying analysis of a machine-learning-assisted side-channel attack
Jack Cook, Jules Drean, Jonathan Behrens, and Mengjia Yan. There’s always a bigger fish: a clarifying analysis of a machine-learning-assisted side-channel attack. InProceedings of the 49th Annual International Symposium on Computer Architecture, ISCA ’22, pages 204–217, New York, NY , USA, June 2022. Association for Computing Machinery. ISBN 978-1-4503-8610-
2022
-
[26]
URL https://dl.acm.org/doi/10.1145/3470496
doi: 10.1145/3470496.3527416. URL https://dl.acm.org/doi/10.1145/3470496. 3527416. 11
-
[27]
MITRE ATT&CK: Adversarial Tactics, Techniques and Common Knowl- edge, 2025
MITRE Corporation. MITRE ATT&CK: Adversarial Tactics, Techniques and Common Knowl- edge, 2025. URLhttps://attack.mitre.org
2025
-
[28]
A Whole New World: Creating a Parallel-Poisoned Web Only AI-Agents Can See, August 2025
Shaked Zychlinski. A Whole New World: Creating a Parallel-Poisoned Web Only AI-Agents Can See, August 2025. URL http://arxiv.org/abs/2509.00124. arXiv:2509.00124 [cs] version: 1
-
[29]
Yixiang Zhang, Xinhao Deng, Zhongyi Gu, Yihao Chen, Ke Xu, Qi Li, and Jianping Wu. Exposing LLM User Privacy via Traffic Fingerprint Analysis: A Study of Privacy Risks in LLM Agent Interactions, October 2025. URL http://arxiv.org/abs/2510.07176. arXiv:2510.07176 [cs] version: 1
-
[30]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and Transferable Adversarial Attacks on Aligned Language Models, December 2023. URLhttp://arxiv.org/abs/2307.15043. arXiv:2307.15043 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. “Do Anything Now”: Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. arXiv preprint arXiv:2308.03825, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Attacking Multimodal OS Agents with Malicious Image Patches, March 2025
Lukas Aichberger, Alasdair Paren, Yarin Gal, Philip Torr, and Adel Bibi. Attacking Multimodal OS Agents with Malicious Image Patches, March 2025. URL http://arxiv.org/abs/2503. 10809. arXiv:2503.10809 [cs]
-
[33]
Preference Redirection via Attention Concentration: An Attack on Computer Use Agents
Dominik Seip and Matthias Hein. Preference Redirection via Attention Concentration: An Attack on Computer Use Agents, April 2026. URL http://arxiv.org/abs/2604.08005. arXiv:2604.08005 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps. In Donia Scott, Nuria Bel, and Chengqing Zong, editors,Proceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, Barcelona, Spain (Online), December 2020. International ...
-
[35]
Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, January 2025
Satyapriya Krishna, Kalpesh Krishna, Anhad Mohananey, Steven Schwarcz, Adam Stambler, Shyam Upadhyay, and Manaal Faruqui. Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, January 2025. URL http://arxiv.org/abs/2409. 12941. arXiv:2409.12941 [cs]
-
[36]
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents, February 2023
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents, February 2023. URL http: //arxiv.org/abs/2207.01206. arXiv:2207.01206 [cs]
-
[37]
DeepShop: A Benchmark for Deep Research Shopping Agents, June 2025
Yougang Lyu, Xiaoyu Zhang, Lingyong Yan, Maarten de Rijke, Zhaochun Ren, and Xiuying Chen. DeepShop: A Benchmark for Deep Research Shopping Agents, June 2025. URL http://arxiv.org/abs/2506.02839. arXiv:2506.02839 [cs]
-
[38]
V . Team, Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Bin Chen, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Jiazheng Xu, Jiale Zhu, Jiali Chen,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Qwen Team. Qwen3 Technical Report, 2025. URL https://arxiv.org/abs/2505.09388. _eprint: 2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Qwen3.5: Towards Native Multimodal Agents, February 2026
Qwen Team. Qwen3.5: Towards Native Multimodal Agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5
2026
-
[41]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, Wanjun Zhong, Kuanye Li, Jiale Yang, Yu Miao, Woyu Lin, Longxiang Liu, Xu Jiang, Qianli Ma, Jingyu Li, Xiaojun Xiao, Kai Cai, Chuang Li, Yaowei Zheng, Chaolin Jin, Chen Li, Xiao Zhou, Minchao Wang, Haoli Chen, Zhaojian Li, Haihua Ya...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL Technical Report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Gemma 4, 2026
Gemma Team. Gemma 4, 2026. URL https://deepmind.google/models/gemma/ gemma-4/
2026
-
[44]
Seed2.0 Model Card, 2026
ByteDance Seed Team. Seed2.0 Model Card, 2026. URL https://github.com/ ByteDance-Seed/Seed2.0
2026
-
[45]
Introducing GPT-5.4, April 2026
OpenAI. Introducing GPT-5.4, April 2026. URL https://openai.com/index/ introducing-gpt-5-4/
2026
-
[46]
Gemini 3.1 Pro
Google. Gemini 3.1 Pro. URLhttps://deepmind.google/models/gemini/pro/
-
[47]
Claude Opus 4.6
Anthropic. Claude Opus 4.6. URL https://www.anthropic.com/news/ claude-opus-4-6
-
[48]
Midscene.js: Your AI Operator for Web, Android, iOS, Automation & Testing., 2025
YiBing Lin Xiao Zhou, Tao Yu. Midscene.js: Your AI Operator for Web, Android, iOS, Automation & Testing., 2025. URLhttps://github.com/web-infra-dev/midscene
2025
-
[49]
Leibo, and Simon Osindero
Matija Franklin, Nenad Tomašev, Julian Jacobs, Joel Z. Leibo, and Simon Osindero. AI Agent Traps, March 2026. URLhttps://papers.ssrn.com/abstract=6372438
2026
-
[50]
Sponge Examples: Energy-Latency Attacks on Neural Networks
Ilia Shumailov, Yiren Zhao, Daniel Bates, Nicolas Papernot, Robert Mullins, and Ross Anderson. Sponge Examples: Energy-Latency Attacks on Neural Networks. In2021 IEEE European Symposium on Security and Privacy (EuroS&P), pages 212–231, September 2021. doi: 10.1109/ EuroSP51992.2021.00024. URLhttps://ieeexplore.ieee.org/document/9581273. 13 Appendix A Addi...
-
[51]
Predicted Answer
Carefully compare the “Predicted Answer” with the “Ground Truth Answer”
-
[52]
Do not focus on exact wording unless the exact wording is crucial to the meaning
Consider the substance of the answers – look for equivalent information or correct answers. Do not focus on exact wording unless the exact wording is crucial to the meaning
-
[53]
Ground Truth Answer
Your final decision should be based on whether the meaning and the vital facts of the “Ground Truth Answer” are present in the “Predicted Answer”. ===Input Data=== • Question:{question} • Predicted Answer:{LLM_response} • Ground Truth Answer:{ground_truth_answer} ===Output Format=== Provide your final evaluation in the following format: “Explanation:” (Ho...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.