CM-EVS: Sparse Panoramic RGB-D-Pose Data for Complete Scene Coverage
Pith reviewed 2026-05-20 19:21 UTC · model grok-4.3
The pith
COVER selects sparse panoramic RGB-D-pose frames from 3D assets that achieve complete scene coverage with low redundancy under bounded approximation error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
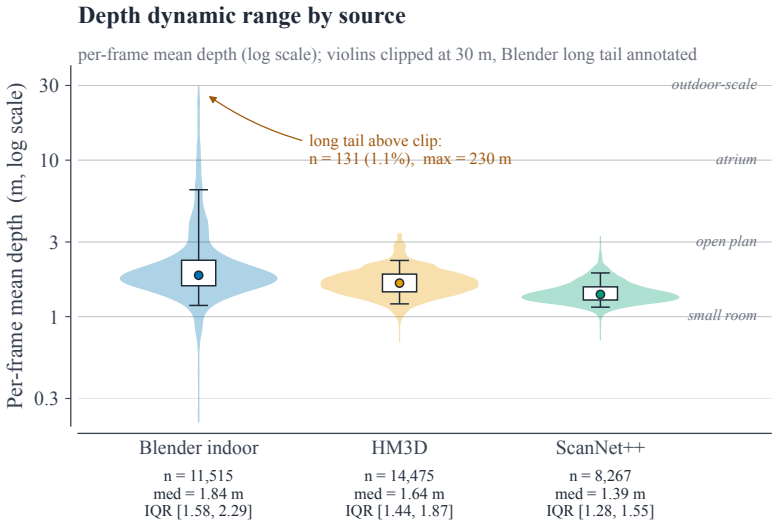
COVER (Coverage-Oriented Viewpoint curation with ERP Range-depth warping) projects observed geometry from selected views into candidate ERP probes, computes incremental coverage scores, and penalizes depth conflicts. Under the assumption of bounded proxy error, its greedy coverage proxy preserves the standard coverage-style approximation behavior up to an additive error term. Using this curator on Blender indoor, HM3D, ScanNet++, TartanGround, and OB3D sources produces the CM-EVS dataset of 36,373 frames from 1,275 scenes, each supplying calibrated panoramic RGB, range depth, and pose with provenance logs.
What carries the argument
COVER, the Coverage-Oriented Viewpoint curation with ERP Range-depth warping procedure, which works by projecting geometry observed from already selected views into candidate equirectangular probes to score incremental coverage while penalizing depth inconsistencies.
If this is right
- CM-EVS supplies 36,373 panoramic frames across 1,275 scenes with a median of 25 frames per indoor scene.
- The collection covers all 13 unified room types while keeping low redundancy.
- Indoor frames include per-step provenance logs that record how each view was chosen.
- Experiments demonstrate a better coverage-conflict trade-off than prior heuristics.
- The same schema works for re-encoded outdoor panoramas from TartanGround and OB3D.
Where Pith is reading between the lines
- The curation approach could be tested on larger or dynamic scenes to check whether the bounded-error condition continues to hold.
- If the proxy remains reliable, similar greedy selection might be applied to other spherical or multi-view representations beyond ERP.
- The resulting compact sets could support ablation studies that isolate the effect of view density on downstream panoramic 3D tasks.
Load-bearing premise
The error introduced by projecting geometry from selected views into candidate ERP probes remains bounded.
What would settle it
A direct measurement on a held-out scene where the greedy coverage ratio deviates from the standard approximation guarantee by more than the stated additive error term after the proxy projections are applied.
Figures














read the original abstract
Modern 3D visual learning relies on observations sampled from metric 3D assets, yet existing scans, meshes, point clouds, simulations, and reconstructions do not directly provide a sparse, comparable, and geometry-consistent panoramic training interface. Dense trajectories duplicate nearby views, source-specific rendering policies yield heterogeneous annotations, and sparse heuristics may miss important regions or introduce depth-inconsistent observations. We study how to convert 3D assets into sparse panoramic RGB-D-pose data that preserves complete scene coverage with low redundancy and auditable provenance. We propose COVER (Coverage-Oriented Viewpoint curation with ERP Range-depth warping), a training-free ERP viewpoint curator that projects geometry observed from selected views into candidate ERP probes, scores incremental coverage, and penalizes depth conflicts. Under bounded proxy error, its greedy coverage proxy preserves the standard coverage-style approximation behavior up to an additive error term. Using COVER, we build CM-EVS (Coverage-curated Metric ERP View Set), a panoramic RGB-D-pose dataset with 36,373 curated ERP frames from 1,275 indoor scenes across Blender indoor, HM3D, and ScanNet++, complemented by outdoor panoramas from TartanGround and OB3D re-encoded into the same schema. Each frame provides full-sphere RGB, metric range depth, calibrated pose; COVER-produced indoor frames include per-step provenance logs. With a median of only 25 frames per indoor scene, CM-EVS covers all 13 unified room types while maintaining compact scene-level coverage. Experiments show that COVER improves the coverage-conflict trade-off, making CM-EVS a sparse, compact, and auditable RGB-D-pose resource for geometry-consistent panoramic 3D learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces COVER, a training-free ERP viewpoint curator that projects geometry from selected views into candidate ERP probes, scores incremental coverage, and penalizes depth conflicts. Under a bounded proxy error assumption, its greedy coverage proxy is claimed to preserve standard coverage-style approximation behavior up to an additive error term. Using COVER, the authors construct the CM-EVS dataset comprising 36,373 curated panoramic RGB-D-pose frames from 1,275 indoor scenes (Blender indoor, HM3D, ScanNet++) plus outdoor panoramas, achieving complete coverage of 13 room types with a median of 25 frames per scene while maintaining low redundancy and auditable provenance.
Significance. If the bounded proxy error holds and the approximation guarantee can be verified, the work supplies a sparse, compact, geometry-consistent, and provenance-auditable panoramic RGB-D-pose resource that directly addresses redundancy, heterogeneity, and coverage gaps in existing 3D assets. The training-free construction from public sources and explicit coverage-conflict trade-off experiments constitute clear strengths for downstream 3D visual learning tasks.
major comments (2)
- [Abstract] Abstract: the central claim that 'under bounded proxy error, its greedy coverage proxy preserves the standard coverage-style approximation behavior up to an additive error term' is load-bearing for the method's theoretical contribution, yet the manuscript provides no derivation of an explicit bound on the proxy error incurred when projecting geometry from selected views into candidate ERP probes, no error-bar analysis, and no ablation isolating the depth-conflict penalty term.
- [Abstract] The assumption that proxy error remains bounded independently of scene scale, depth discontinuities, and ERP distortion is required for the approximation guarantee to hold, but the text does not supply a concrete test or worst-case analysis showing the additive term stays controlled rather than accumulating with the number of selected views.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We appreciate the recognition of the dataset's value for 3D visual learning and the identification of areas where the theoretical claims require stronger support. We address each major comment below and outline specific revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'under bounded proxy error, its greedy coverage proxy preserves the standard coverage-style approximation behavior up to an additive error term' is load-bearing for the method's theoretical contribution, yet the manuscript provides no derivation of an explicit bound on the proxy error incurred when projecting geometry from selected views into candidate ERP probes, no error-bar analysis, and no ablation isolating the depth-conflict penalty term.
Authors: We agree that the central claim requires explicit support and that the abstract alone does not supply the requested derivation, error-bar analysis, or ablation. The full manuscript discusses the proxy error arising from ERP range-depth warping but does not isolate the bound or perform the suggested analyses. In the revised version we will add a new subsection deriving an explicit bound on the proxy error under the stated assumptions, include error-bar plots quantifying the additive term, and report an ablation that isolates the depth-conflict penalty's contribution to coverage scoring. revision: yes
-
Referee: [Abstract] The assumption that proxy error remains bounded independently of scene scale, depth discontinuities, and ERP distortion is required for the approximation guarantee to hold, but the text does not supply a concrete test or worst-case analysis showing the additive term stays controlled rather than accumulating with the number of selected views.
Authors: We acknowledge that the boundedness assumption must be substantiated with concrete tests rather than left implicit. The current text states the assumption without worst-case analysis or scaling experiments. We will revise the manuscript to include a worst-case analysis of the additive error term under varying scene scales, depth discontinuities, and ERP distortion, together with empirical plots showing that the term remains controlled and does not accumulate unboundedly as the number of selected views increases. revision: yes
Circularity Check
Coverage guarantee stated conditionally on unverified assumption; no reduction to inputs by construction
full rationale
The paper presents COVER as a training-free method that projects geometry from selected views into ERP probes and uses a greedy coverage proxy. The key claim is that under bounded proxy error this proxy preserves standard coverage-style approximation up to an additive term. No equations in the provided text reduce this guarantee to a fitted parameter, self-citation chain, or definitional equivalence. The bounded-error assumption is explicitly stated as a precondition rather than derived from the method itself, and the dataset construction draws from public sources without introducing fitted predictions renamed as results. This keeps the derivation self-contained against external benchmarks, warranting only a minor score for the unproven bound rather than circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing 3D assets provide accurate metric geometry that can be projected into ERP without significant distortion for coverage purposes.
Reference graph
Works this paper leans on
-
[1]
Xu Zheng, Chenfei Liao, Ziqiao Weng, Kaiyu Lei, Zihao Dongfang, Haocong He, Yuanhuiyi Lyu, Lutao Jiang, Lu Qi, Li Chen, et al. Panorama: The rise of omnidirectional vision in the 9 1.0 0.5 0.0 0.5 1.0 (a) =0 (coverage-only greedy) 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.0 0.5 0.0 0.5 1.0 (b) =0.2 (coverage peak) 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.0 0.5 0.0...
-
[2]
PanoFormer: Panorama transformer for indoor 360 ◦ depth estimation
Zhijie Shen, Chunyu Lin, Kang Liao, Lang Nie, Zishuo Zheng, and Yao Zhao. PanoFormer: Panorama transformer for indoor 360 ◦ depth estimation. InProceedings of the European Conference on Computer Vision (ECCV), 2022
work page 2022
-
[3]
Guangcong Wang, Peng Wang, Zhaoxi Chen, Wenping Wang, Chen Change Loy, and Ziwei Liu. PERF: Panoramic neural radiance field from a single panorama.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024
work page 2024
-
[4]
360DVD: Controllable panorama video generation with 360-degree video diffusion model
Qian Wang, Weiqi Li, Chong Mou, Xinhua Cheng, and Jian Zhang. 360DVD: Controllable panorama video generation with 360-degree video diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[5]
Pano3D: A holis- tic benchmark and a solid baseline for 360◦ depth estimation
Georgios Albanis, Nikolaos Zioulis, Petros Drakoulis, Vasileios Gkitsas, Vladimiros Sterzentsenko, Federico Alvarez, Dimitrios Zarpalas, and Petros Daras. Pano3D: A holis- tic benchmark and a solid baseline for 360◦ depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2021
work page 2021
-
[6]
OmniPhotos: Casual 360◦ VR photography
Tobias Bertel, Mingze Yuan, Reuben Lindroos, and Christian Richardt. OmniPhotos: Casual 360◦ VR photography. InACM Transactions on Graphics (Proc. SIGGRAPH Asia), volume 39. ACM, 2020
work page 2020
-
[7]
Matrix-3D: Omnidirectional explorable 3D world generation
Zhongqi Yang, Wenhang Ge, Yuqi Li, Jiaqi Chen, Haoyuan Li, Mengyin An, Fei Kang, Hua Xue, Baixin Xu, Yuyang Yin, et al. Matrix-3D: Omnidirectional explorable 3D world generation. arXiv preprint, 2025. Skywork Matrix-3D
work page 2025
-
[8]
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
work page 2021
-
[9]
Structured3D: A large photo-realistic dataset for structured 3D modeling
Jia Zheng, Junfei Zhang, Jing Li, Rui Tang, Shenghua Gao, and Zihan Zhou. Structured3D: A large photo-realistic dataset for structured 3D modeling. InProceedings of the European Conference on Computer Vision (ECCV), 2020
work page 2020
-
[10]
ScanNet++: A high-fidelity dataset of 3D indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. ScanNet++: A high-fidelity dataset of 3D indoor scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[11]
Matterport3D: Learning from RGB-D data in indoor environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Nießner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3D: Learning from RGB-D data in indoor environments. InInternational Conference on 3D Vision (3DV), 2017
work page 2017
-
[12]
Santhosh K. Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X. Chang, Manolis Savva, Yili Zhao, and Dhruv Batra. Habitat-matterport 3D dataset (HM3D): 1000 large-scale 3D environments for embodied AI. InProceedings of the NeurIPS Track on Datasets and Bench...
work page 2021
-
[13]
TartanGround: A large-scale dataset for ground robot perception and navigation
Manthan Patel, Fan Yang, Yuheng Qiu, Cesar Cadena, Sebastian Scherer, Marco Hutter, and Wenshan Wang. TartanGround: A large-scale dataset for ground robot perception and navigation. arXiv:2505.10696, 2025
-
[14]
OB3D: A new dataset for benchmarking omnidirectional 3D reconstruction using Blender
Shintaro Ito, Natsuki Takama, Toshiki Watanabe, Koichi Ito, Hwann-Tzong Chen, and Takafumi Aoki. OB3D: A new dataset for benchmarking omnidirectional 3D reconstruction using Blender. arXiv:2505.20126, 2025
-
[15]
Jing Ou, Zidong Cao, Yinrui Ren, Zhuoxiao Li, Jinjing Zhu, Tongyan Hua, Shuai Zhang, Hui Xiong, and Wufan Zhao. Holo360d: A large-scale real-world dataset with continuous trajectories for advancing panoramic 3d reconstruction and beyond.arXiv preprint arXiv:2604.22482, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
PanoGRF: Generalizable spherical radiance fields for wide-baseline panoramas
Zheng Chen, Yan-Pei Cao, Yuan-Chen Guo, Chen Wang, Ying Shan, and Song-Hai Zhang. PanoGRF: Generalizable spherical radiance fields for wide-baseline panoramas. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[17]
DreamScene360: Unconstrained text-to-3D scene generation with panoramic Gaussian splatting
Shijie Zhou, Zhiwen Fan, Dejia Xu, Haoran Chang, Pradyumna Chari, Tejas Bharadwaj, Suya You, Zhangyang Wang, and Achuta Kadambi. DreamScene360: Unconstrained text-to-3D scene generation with panoramic Gaussian splatting. InProceedings of the European Conference on Computer Vision (ECCV), 2024
work page 2024
-
[18]
MVDiffu- sion: Enabling holistic multi-view image generation with correspondence-aware diffusion
Shitao Tang, Fuyang Zhang, Jiacheng Chen, Peng Wang, and Yasutaka Furukawa. MVDiffu- sion: Enabling holistic multi-view image generation with correspondence-aware diffusion. In Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[19]
J. Irving Vasquez-Gomez, L. Enrique Sucar, Rafael Murrieta-Cid, and Efrain Lopez-Damian. V olumetric next-best-view planning for 3D object reconstruction with positioning error.Inter- national Journal of Advanced Robotic Systems, 11(10), 2014
work page 2014
-
[20]
SCVP: Learning one-shot view planning via set covering for unknown object reconstruction
Sicong Pan, Hao Hu, and Hui Wei. SCVP: Learning one-shot view planning via set covering for unknown object reconstruction. InIEEE Robotics and Automation Letters / Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022
work page 2022
-
[21]
ActiveNeRF: Learning where to see with uncertainty estimation
Xuran Pan, Zihang Lai, Shiji Song, and Gao Huang. ActiveNeRF: Learning where to see with uncertainty estimation. InProceedings of the European Conference on Computer Vision (ECCV), 2022
work page 2022
-
[22]
Yunlong Ran, Jing Zeng, Shibo He, Jiming Chen, Lincheng Li, Yingfeng Chen, Gimhee Lee, and Qi Ye. NeurAR: Neural uncertainty for autonomous 3D reconstruction with implicit neural representations.IEEE Robotics and Automation Letters, 8(2):1125–1132, 2023
work page 2023
-
[23]
GenNBV: Generalizable next-best-view policy for active 3D reconstruction
Xiao Chen, Quanyi Li, Tai Wang, Tianfan Xue, and Jiangmiao Pang. GenNBV: Generalizable next-best-view policy for active 3D reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[24]
Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
work page 2021
-
[25]
Mubashara Akhtar, Omar Benjelloun, Costanza Conforti, Luca Foschini, Pieter Gijsbers, Joan Giner-Miguelez, Sujata Goswami, Nitisha Jain, Michalis Karamousadakis, Satyapriya Krishna, et al. Croissant: A metadata format for ML-ready datasets.Advances in Neural Information Processing Systems, 37:82133–82148, 2024
work page 2024
-
[26]
Richard M. Karp. Reducibility among combinatorial problems. InComplexity of Computer Computations, pages 85–103. Plenum Press, 1972
work page 1972
-
[27]
A threshold oflnn for approximating set cover.Journal of the ACM, 45(4):634–652, 1998
Uriel Feige. A threshold oflnn for approximating set cover.Journal of the ACM, 45(4):634–652, 1998
work page 1998
-
[28]
George L. Nemhauser, Laurence A. Wolsey, and Marshall L. Fisher. An analysis of approxima- tions for maximizing submodular set functions—I.Mathematical Programming, 14(1):265–294, 1978. 11
work page 1978
-
[29]
Submodular function maximization
Andreas Krause and Daniel Golovin. Submodular function maximization. In Lucas Bordeaux, Youssef Hamadi, and Pushmeet Kohli, editors,Tractability: Practical Approaches to Hard Problems, pages 71–104. Cambridge University Press, 2014
work page 2014
-
[30]
Submodular optimization under noise
Avinatan Hassidim and Yaron Singer. Submodular optimization under noise. InProceedings of the 2017 Conference on Learning Theory (COLT), volume 65 ofProceedings of Machine Learning Research, pages 1069–1122. PMLR, 2017
work page 2017
-
[31]
Streaming submodular maximization: Massive data summarization on the fly
Ashwinkumar Badanidiyuru, Baharan Mirzasoleiman, Amin Karbasi, and Andreas Krause. Streaming submodular maximization: Massive data summarization on the fly. InProceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2014
work page 2014
-
[32]
Streaming non-monotone submodular maximization: Personalized video summarization on the fly
Baharan Mirzasoleiman, Stefanie Jegelka, and Andreas Krause. Streaming non-monotone submodular maximization: Personalized video summarization on the fly. InProceedings of the AAAI Conference on Artificial Intelligence, 2018
work page 2018
-
[33]
Maximilian Denninger, Dominik Winkelbauer, Martin Sundermeyer, Wout Boerdijk, Markus Wendelin Knauer, Klaus H Strobl, Matthias Humt, and Rudolph Triebel. BlenderProc2: A procedural pipeline for photorealistic rendering.Journal of Open Source Software, 8(82):4901, 2023
work page 2023
-
[34]
Habitat: A platform for embodied AI research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A platform for embodied AI research. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
work page 2019
-
[35]
Marc Levoy and Pat Hanrahan. Light field rendering. InProceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), pages 31–42, 1996
work page 1996
-
[36]
Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. ScanNet: Richly-annotated 3D reconstructions of indoor scenes. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
work page 2017
-
[37]
ARKitScenes: A diverse real-world dataset for 3D indoor scene understanding using mobile RGB-D data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, and Elad Shulman. ARKitScenes: A diverse real-world dataset for 3D indoor scene understanding using mobile RGB-D data. In Proceedings of the NeurIPS Track on Datasets and Benchmarks, 2021
work page 2021
-
[38]
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J. Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, Anton Clarkson, Mingfei Yan, Brian Budge, Yajie Yan, Xiaqing Pan, June Yon, Yuyang Zou, Kimberly Leon, Nigel Carter, Jesus Briales, Tyler Gillingham, Elias Mueggler, Luis Pesqueira, Manolis Savva, Dhruv Batra, Hauke M. S...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[39]
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J. Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, Thomas Kipf, Abhijit Kundu, Dmitry Lagun, Issam Laradji, Hsueh-Ti Derek Liu, Henning Meyer, Yishu Miao, Derek Nowrouzezahrai, Cengiz Oztireli, Etienne Pot, Noha Radwan, Daniel Rebain, Sara Sabour, Mehd...
work page 2022
-
[40]
Infinite photorealistic worlds using procedural generation
Alexander Raistrick, Lahav Lipson, Zeyu Ma, Lingjie Mei, Mingzhe Wang, Yiming Zuo, Karhan Kayan, Hongyu Wen, Beining Han, Yihan Wang, Alejandro Newell, Hei Law, Ankit Goyal, Kaiyu Yang, and Jia Deng. Infinite photorealistic worlds using procedural generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 12
work page 2023
-
[41]
3D-FRONT: 3D furnished rooms with layouts and semantics
Huan Fu, Bowen Cai, Lin Gao, Ling-Xiao Zhang, Jiaming Wang, Cao Li, Qixun Zeng, Chengyue Sun, Rongfei Jia, Binqiang Zhao, and Hao Zhang. 3D-FRONT: 3D furnished rooms with layouts and semantics. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
work page 2021
-
[42]
Zamir, Zhi-Yang He, Alexander Sax, Jitendra Malik, and Silvio Savarese
Fei Xia, Amir R. Zamir, Zhi-Yang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. Gibson Env: Real-world perception for embodied agents. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
work page 2018
-
[43]
Bokui Shen, Fei Xia, Chengshu Li, Roberto Martín-Martín, Linxi Fan, Guanzhi Wang, Claudia Pérez-D’Arpino, Shyamal Buch, Sanjana Srivastava, Lyne P. Tchapmi, Micael E. Tchapmi, Kent Vainio, Josiah Wong, Li Fei-Fei, and Silvio Savarese. iGibson 1.0: A simulation environment for interactive tasks in large realistic scenes. InProceedings of the IEEE/RSJ Inter...
work page 2021
-
[44]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. In Proceedings of the European Conference on Computer Vision (ECCV), 2020
work page 2020
-
[45]
3D Gaus- sian splatting for real-time radiance field rendering.ACM Transactions on Graphics (Proc
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3D Gaus- sian splatting for real-time radiance field rendering.ACM Transactions on Graphics (Proc. SIGGRAPH), 42(4), 2023
work page 2023
-
[46]
360-GS: Layout-guided panoramic gaussian splatting for indoor roaming
Jiayang Bai, Letian Huang, Jie Guo, Wen Gong, Yuanqi Li, and Yanwen Guo. 360-GS: Layout-guided panoramic gaussian splatting for indoor roaming. arXiv:2402.00763, 2024
-
[47]
Balanced spherical grid for egocentric view synthesis
Changwoon Choi, Sang Min Kim, and Young Min Kim. Balanced spherical grid for egocentric view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[48]
Omni-nerf: neural radiance field from 360 image captures
Kai Gu, Thomas Maugey, Sebastian Knorr, and Christine Guillemot. Omni-nerf: neural radiance field from 360 image captures. InProceedings of the IEEE International Conference on Image Processing (ICIP), 2022
work page 2022
-
[49]
360Roam: Real-time indoor roaming using geometry-aware 360◦ radiance fields
Huajian Huang, Yingshu Chen, Tianjia Zhang, and Sai-Kit Yeung. 360Roam: Real-time indoor roaming using geometry-aware 360◦ radiance fields. arXiv:2208.02705, 2022
-
[50]
Weicai Ye, Chenhao Ji, Zheng Chen, Junyao Gao, Xiaoshui Huang, Song-Hai Zhang, Wanli Ouyang, Tong He, Cairong Zhao, and Guofeng Zhang. DiffPano: Scalable and consistent text to panorama generation with spherical epipolar-aware diffusion. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[51]
Text2Light: Zero-shot text-driven HDR panorama generation
Zhaoxi Chen, Guangcong Wang, and Ziwei Liu. Text2Light: Zero-shot text-driven HDR panorama generation. InACM Transactions on Graphics (Proc. SIGGRAPH Asia), 2022
work page 2022
-
[52]
Taming stable diffusion for text to 360◦ panorama image generation
Cheng Zhang, Qianyi Wu, Camilo Cruz Gambardella, Xiaoshui Huang, Dinh Phung, Wanli Ouyang, and Jianfei Cai. Taming stable diffusion for text to 360◦ panorama image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[53]
PanoDiffusion: 360-degree panorama outpainting via diffusion
Tianhao Wu, Chuanxia Zheng, and Tat-Jen Cham. PanoDiffusion: 360-degree panorama outpainting via diffusion. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
- [54]
-
[55]
where does the pipeline break?
Nikolaos A. Massios and Robert B. Fisher. A best next view selection algorithm incorporating a quality criterion. InProceedings of the British Machine Vision Conference (BMVC), 1998. 13 Appendix Contents The page limit forces the main body to point to supporting evidence rather than reproduce it. The full Datasheet, the production hyperparameters and geom...
work page 1998
-
[56]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.