Formal Methods Meet LLMs: Auditing, Monitoring, and Intervention for Compliance of Advanced AI Systems
Pith reviewed 2026-05-20 17:20 UTC · model grok-4.3
The pith
Formal methods using Linear Temporal Logic outperform LLM-based methods for auditing and monitoring compliance in advanced AI systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By exploiting the formal syntax and semantics of Linear Temporal Logic (LTL), the proposed auditing and monitoring techniques are superior to LLM baseline methods in detecting violations of temporally extended behavioral constraints. Even small-model labelers match or exceed frontier LLM judges. Predictive and intervening monitors significantly reduce the violation rates of LLM-based agents while largely preserving task performance. LLMs show degraded temporal reasoning accuracy with increasing event distance, number of constraints, and number of propositions.
What carries the argument
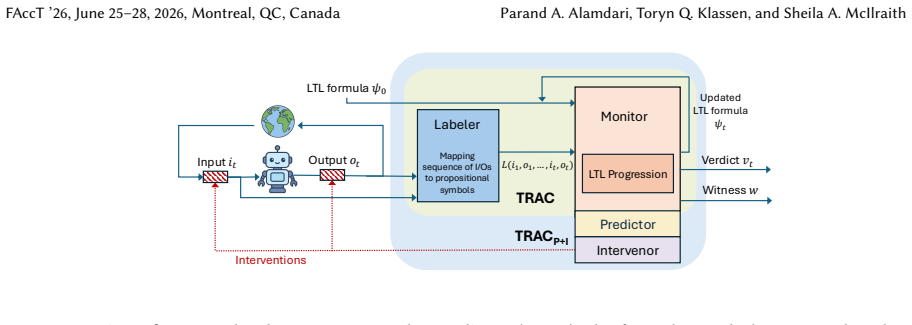
Linear Temporal Logic (LTL) for formal specification of behavioral constraints, enabling sampling-based auditing and runtime predictive and intervening monitoring against black-box AI systems.
Load-bearing premise
That formal LTL specifications of behavioral constraints can be reliably checked against black-box LLMs via sampling or external observation without requiring internal model access or complete state information.
What would settle it
Observing a case where an LLM-based agent violates a specified temporal constraint but the LTL monitor does not flag it, or where intervening reduces task performance substantially.
Figures






read the original abstract
We examine one particular dimension of AI governance: how to monitor and audit AI-enabled products and services throughout the AI development lifecycle, from pre-deployment testing to post-deployment auditing. Combining principles from formal methods with SoTA machine learning, we propose techniques that enable AI-enabled product and service developers, as well as third party AI developers and evaluators, to perform offline auditing and online (runtime) monitoring of product-specific (temporally extended) behavioral constraints such as safety constraints, norms, rules and regulations with respect to black-box advanced AI systems, notably LLMs. We further provide practical techniques for predictive monitoring, such as sampling-based methods, and we introduce intervening monitors that act at runtime to preempt and potentially mitigate predicted violations. Experimental results show that by exploiting the formal syntax and semantics of Linear Temporal Logic (LTL), our proposed auditing and monitoring techniques are superior to LLM baseline methods in detecting violations of temporally extended behavioral constraints; with our approach, even small-model labelers match or exceed frontier LLM judges. Our predictive and intervening monitors significantly reduce the violation rates of LLM-based agents while largely preserving task performance. We further show through controlled experiments that LLMs' temporal reasoning shows a pronounced degradation in accuracy with increasing event distance, number of constraints, and number of propositions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a hybrid approach combining Linear Temporal Logic (LTL) formal methods with machine learning for auditing and monitoring compliance of black-box LLMs with temporally extended behavioral constraints. It proposes offline auditing techniques and online runtime monitoring, including sampling-based predictive monitoring and intervening monitors that preempt violations. The paper reports experimental results demonstrating that LTL-exploiting methods outperform LLM-only baselines in violation detection, that small-model labelers can match or exceed frontier LLMs, and that the monitors reduce violation rates while preserving task performance. It also shows degradation in LLMs' temporal reasoning with increased event distance, constraints, and propositions.
Significance. Should the results be confirmed with detailed experimental protocols, this work has potential significance for AI safety and governance by enabling formal verification techniques to be applied to opaque advanced AI systems. The practical techniques for predictive and intervening monitoring could inform regulatory compliance tools. The empirical findings on LLM limitations in handling complex temporal logic add to the literature on LLM capabilities and failure modes.
major comments (3)
- [Experimental Evaluation] The central claims of superiority in detecting violations and effectiveness of monitors rest on experimental comparisons, but the abstract provides no details on experimental design, baselines used, statistical tests, number of trials, or potential confounds. The full paper must include these to substantiate that the data supports the reported superiority and violation reductions.
- [Runtime Monitoring and Intervention] The LTL-based monitoring assumes reliable labeling of atomic propositions from sampled external observations of black-box LLM behavior. For formulas involving nested temporal operators or implications like G(P → F Q), any inconsistency or error in proposition evaluation due to partial observability or natural language ambiguity could invalidate the formal guarantees and the claimed performance advantages over LLM baselines.
- [LLM Temporal Reasoning Experiments] The controlled experiments on degradation with event distance, number of constraints, and propositions are presented as supporting evidence, but it is unclear whether these directly validate the auditing pipeline or if they account for variations in LTL formula complexity and observation completeness.
minor comments (2)
- [Abstract] The term 'SoTA machine learning' is used without specifying the particular ML components integrated with LTL; a brief clarification would improve readability.
- [Introduction] Ensure that all acronyms such as LTL are defined at first use, and consider adding a reference to prior work on runtime verification for AI systems.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for improving the clarity and robustness of our presentation. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Experimental Evaluation] The central claims of superiority in detecting violations and effectiveness of monitors rest on experimental comparisons, but the abstract provides no details on experimental design, baselines used, statistical tests, number of trials, or potential confounds. The full paper must include these to substantiate that the data supports the reported superiority and violation reductions.
Authors: We agree that the abstract is high-level and would benefit from additional experimental context to better support the claims. The full manuscript already details the experimental design in Section 4, including baselines (LLM-only judges and random sampling), number of trials (100 per condition across 5 LTL formulas), statistical tests (paired t-tests with reported p-values), and controls for confounds such as prompt phrasing and event ordering. In the revision, we will expand the abstract with a concise summary of these elements (e.g., 'evaluated over 500 trials with statistical significance testing') while preserving the word limit. revision: yes
-
Referee: [Runtime Monitoring and Intervention] The LTL-based monitoring assumes reliable labeling of atomic propositions from sampled external observations of black-box LLM behavior. For formulas involving nested temporal operators or implications like G(P → F Q), any inconsistency or error in proposition evaluation due to partial observability or natural language ambiguity could invalidate the formal guarantees and the claimed performance advantages over LLM baselines.
Authors: We acknowledge this as a substantive limitation of the formal guarantees, which depend on accurate proposition evaluation. Our empirical results rely on LLM labelers whose accuracy we measure (small models reaching 92% human agreement), and the performance gains are shown experimentally rather than purely formally. We will add a dedicated limitations paragraph in Section 3.2 discussing error propagation for nested operators, including a sensitivity analysis with simulated label noise, and note that conservative intervention thresholds can mitigate risks in practice. revision: partial
-
Referee: [LLM Temporal Reasoning Experiments] The controlled experiments on degradation with event distance, number of constraints, and propositions are presented as supporting evidence, but it is unclear whether these directly validate the auditing pipeline or if they account for variations in LTL formula complexity and observation completeness.
Authors: These experiments characterize inherent LLM limitations in temporal reasoning to motivate the hybrid approach, rather than serving as direct validation of the auditing pipeline. To strengthen the connection, we will revise the text in the introduction and Section 5 to explicitly link them to the auditing results. We will also incorporate additional controls for LTL formula complexity (varying nesting depth) and observation completeness (partial vs. full traces) in the revised experimental protocol. revision: yes
Circularity Check
No circularity: empirical validation of LTL monitoring against LLM baselines
full rationale
The paper's central claims rest on experimental comparisons of LTL-based auditing/monitoring (using sampling for proposition evaluation on black-box traces) to LLM baseline judges, plus controlled tests of temporal reasoning degradation with distance and constraints. These are direct empirical results rather than derivations that reduce by construction to fitted parameters, self-definitions, or self-citation chains. No load-bearing step equates a prediction to its input or imports uniqueness via author overlap. The formal semantics of LTL are applied as a standard tool to external observations, with performance measured against independent baselines, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Linear Temporal Logic has well-defined syntax and semantics suitable for specifying temporally extended properties such as safety constraints.
invented entities (1)
-
intervening monitors
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a family of Temporal Rule Assessment and Compliance (TRAC) algorithms... leveraging LTL progression... TRAC significantly outperforms LLM-as-a-Judge auditing on temporally extended patterns
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LTL progression... prg(φ, σ_i) ... soundness follows directly from that of LTL3 progression
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Parand A. Alamdari, Toryn Q. Klassen, Elliot Creager, and Sheila A. McIlraith. 2024. Remembering to Be Fair: Non-Markovian Fairness in Sequential Decision Making. InProceedings of the 41st International Conference on Machine Learning. PMLR, 906–920. https://proceedings.mlr.press/v235/alamdari24a.html
work page 2024
-
[3]
Parand A. Alamdari, Toryn Q. Klassen, Rodrigo Toro Icarte, and Sheila A. McIlraith. 2024. Being considerate as a pathway towards pluralistic alignment for agentic AI.arXiv preprint arXiv:2411.10613(2024)
-
[4]
Parand A. Alamdari, Toryn Q. Klassen, Rodrigo Toro Icarte, and Sheila A. McIlraith. 2022. Be Considerate: Avoiding Negative Side Effects in Reinforcement Learning. InProceedings of the International Conference on Autonomous Agents and Multiagent Systems (AAMAS). 18–26
work page 2022
-
[5]
Maryam Amirizaniani, Elias Martin, Tanya Roosta, Aman Chadha, and Chirag Shah. 2024. AuditLLM: A Tool for Auditing Large Language Models Using Multiprobe Approach. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM ’24). Association for Computing Machinery, 5174–5179. doi:10.1145/3627673.3679222
- [6]
-
[7]
Anthropic. 2024. Introducing Claude 3. https://www.anthropic.com/news/claude-3-family
work page 2024
-
[8]
Marco Autili, Lars Grunske, Markus Lumpe, Patrizio Pelliccione, and Antony Tang. 2015. Aligning qualitative, real-time, and probabilistic property specification patterns using a structured English grammar.IEEE Transactions on Software Engineering41, 7 (2015), 620–638
work page 2015
-
[9]
Fahiem Bacchus and Froduald Kabanza. 2000. Using temporal logics to express search control knowledge for planning.Artificial Intelligence116, 1-2 (2000), 123–191
work page 2000
-
[10]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
2014.Principles of Model Checking
Christel Baier, Joost-Pieter Katoen, and Kim Guldstrand Larsen. 2014.Principles of Model Checking. MIT Press. Auditing, Monitoring, and Intervention for Compliance of Advanced AI Systems FAccT ’26, June 25–28, 2026, Montreal, QC, Canada
work page 2014
-
[13]
Bowen Baker, Joost Huizinga, Leo Gao, Zehao Dou, Melody Y Guan, Aleksander Madry, Wojciech Zaremba, Jakub Pachocki, and David Farhi. 2025. Monitoring reasoning models for misbehavior and the risks of promoting obfuscation.arXiv preprint arXiv:2503.11926 (2025)
work page internal anchor Pith review arXiv 2025
-
[14]
Howard Barringer, Allen Goldberg, Klaus Havelund, and Koushik Sen. 2004. Rule-based runtime verification. InInternational Workshop on Verification, Model Checking, and Abstract Interpretation. Springer, 44–57
work page 2004
-
[15]
Andreas Bauer and Yliès Falcone. 2016. Decentralised LTL monitoring.Formal Methods in System Design48, 1-2 (2016), 46–93. doi:10.1007/S10703-016-0253-8
-
[16]
Andreas Bauer, Martin Leucker, and Christian Schallhart. 2006. Monitoring of real-time properties. InInternational Conference on Foundations of Software Technology and Theoretical Computer Science. Springer, 260–272
work page 2006
-
[17]
Andreas Bauer, Martin Leucker, and Christian Schallhart. 2010. Comparing LTL semantics for runtime verification.Journal of Logic and Computation20, 3 (2010), 651–674
work page 2010
-
[18]
Andreas Bauer, Martin Leucker, and Christian Schallhart. 2011. Runtime verification for LTL and TLTL.ACM Transactions on Software Engineering and Methodology (TOSEM)20, 4 (2011), 1–64
work page 2011
-
[19]
Yoshua Bengio, Stephen Clare, Carina Prunkl, Malcolm Murray, Maksym Andriushchenko, Ben Bucknall, Rishi Bommasani, Stephen Casper, Tom Davidson, Raymond Douglas, David Duvenaud, Philip Fox, Usman Gohar, Rose Hadshar, Anson Ho, Tiancheng Hu, Cameron Jones, Sayash Kapoor, Atoosa Kasirzadeh, Sam Manning, Nestor Maslej, Vasilios Mavroudis, Conor McGlynn, Rich...
work page 2026
-
[20]
Yoshua Bengio, Sören Mindermann, Daniel Privitera, Tamay Besiroglu, Rishi Bommasani, Stephen Casper, Yejin Choi, Philip Fox, Ben Garfinkel, Danielle Goldfarb, Hoda Heidari, Anson Ho, Sayash Kapoor, Leila Khalatbari, Shayne Longpre, Sam Manning, Vasilios Mavroudis, Mantas Mazeika, Julian Michael, Jessica Newman, Kwan Yee Ng, Chinasa T. Okolo, Deborah Raji,...
work page 2025
-
[21]
Meghyn Bienvenu, Christian Fritz, and Sheila A McIlraith. 2011. Specifying and computing preferred plans.Artificial Intelligence175, 7-8 (2011), 1308–1345
work page 2011
-
[22]
Abeba Birhane, Ryan Steed, Victor Ojewale, Briana Vecchione, and Inioluwa Deborah Raji. 2024. AI auditing: The broken bus on the road to AI accountability. In2024 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 612–643
work page 2024
-
[23]
Andrea Brunello, Angelo Montanari, and Mark Reynolds. 2019. Synthesis of LTL Formulas from Natural Language Texts: State of the Art and Research Directions. In26th International Symposium on Temporal Representation and Reasoning (TIME 2019) (Leibniz International Proceedings in Informatics (LIPIcs), Vol. 147). Schloss Dagstuhl – Leibniz-Zentrum für Inform...
-
[24]
Klassen, Richard Valenzano, and Sheila A
Alberto Camacho, Rodrigo Toro Icarte, Toryn Q. Klassen, Richard Valenzano, and Sheila A. McIlraith. 2019. LTL and Beyond: Formal Languages for Reward Function Specification in Reinforcement Learning. InProceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019. 6065–6073. doi:10.24963/ijcai.2019/840
-
[25]
Zouying Cao, Yifei Yang, and Hai Zhao. 2025. SCANS: Mitigating the Exaggerated Safety for LLMs via Safety-Conscious Activation Steering.Proceedings of the AAAI Conference on Artificial Intelligence39 (2025), 23523–23531. doi:10.1609/aaai.v39i22.34521 FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Parand A. Alamdari, Toryn Q. Klassen, and Sheila A. McIlraith
-
[26]
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, Tony Tong Wang, Samuel Marks, Charbel-Raphaël Segerie, Micah Carroll, Andi Peng, Phillip J. K. Christoffersen, Mehul Damani, Stewart Slocum, Usman Anwar, Anand Siththaranjan, Max Nadeau, Eric J. Mic...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Stephen Casper, Carson Ezell, Charlotte Siegmann, Noam Kolt, Taylor Lynn Curtis, Benjamin Bucknall, Andreas Haupt, Kevin Wei, Jérémy Scheurer, Marius Hobbhahn, Lee Sharkey, Satyapriya Krishna, Marvin Von Hagen, Silas Alberti, Alan Chan, Qinyi Sun, Michael Gerovitch, David Bau, Max Tegmark, David Krueger, and Dylan Hadfield-Menell. 2024. Black-box access i...
work page 2024
- [28]
-
[29]
Alan Chan, Carson Ezell, Max Kaufmann, Kevin Wei, Lewis Hammond, Herbie Bradley, Emma Bluemke, Nitarshan Rajkumar, David Krueger, Noam Kolt, Lennart Heim, and Markus Anderljung. 2024. Visibility into AI Agents. InThe 2024 ACM Conference on Fairness, Accountability, and Transparency, FAccT 2024. ACM, 958–973. https://doi.org/10.1145/3630106.3658948
-
[30]
Yongchao Chen, Rujul Gandhi, Yang Zhang, and Chuchu Fan. 2023. NL2TL: Transforming Natural Languages to Temporal Logics using Large Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 15880–15903. doi:10.18653/v1/2023.emnlp-main.985
-
[31]
Noam Chomsky. 1956. Three models for the description of language.IRE Transactions on Information Theory2, 3 (1956), 113–124. https://doi.org/10.1109/TIT.1956.1056813
-
[32]
2024 BCCRT 149 (canLII) Civil Resolution Tribunal of British Columbia. 2024. Moffatt v. Air Canada. https://canlii.ca/t/k2spq File Number SC-2023-005609
work page 2024
-
[33]
Matthias Cosler, Christopher Hahn, Daniel Mendoza, Frederik Schmitt, and Caroline Trippel. 2023. nl2spec: Interactively translating unstructured natural language to temporal logics with large language models. InInternational Conference on Computer Aided Verification. Springer, 383–396
work page 2023
-
[34]
Sasha Costanza-Chock, Inioluwa Deborah Raji, and Joy Buolamwini. 2022. Who Audits the Auditors? Recommendations from a field scan of the algorithmic auditing ecosystem. InProceedings of the 2022 ACM conference on Fairness, Accountability, and Transparency. 1571–1583
work page 2022
-
[35]
Marc-Alexandre Côté, Ákos Kádár, Xingdi Yuan, Ben Kybartas, Tavian Barnes, Emery Fine, James Moore, Matthew Hausknecht, Layla El Asri, Mahmoud Adada, Wendy Tay, and Adam Trischler. 2019. Textworld: A learning environment for text-based games. InComputer Games: 7th Workshop, CGW 2018, Held in Conjunction with the 27th International Conference on Artificial...
work page 2019
-
[36]
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. 2024. Safe RLHF: Safe Reinforcement Learning from Human Feedback. InThe Twelfth International Conference on Learning Representations
work page 2024
-
[37]
Ben d’Angelo, Sriram Sankaranarayanan, César Sánchez, Will Robinson, Bernd Finkbeiner, Henny B Sipma, Sandeep Mehrotra, and Zohar Manna. 2005. LOLA: runtime monitoring of synchronous systems. In12th International Symposium on Temporal Representation and Reasoning (TIME’05). IEEE, 166–174
work page 2005
-
[38]
Google DeepMind. 2023. Gemini: A Family of Highly Capable Multimodal Models.arXiv preprint arXiv:2312.11805(2023). https: //arxiv.org/abs/2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Matthew B Dwyer, George S Avrunin, and James C Corbett. 1999. Patterns in property specifications for finite-state verification. In Proceedings of the 21st International Conference on Software Engineering. 411–420
work page 1999
-
[40]
Thomas Ferrère, Thomas A. Henzinger, and Bernhard Kragl. 2020. Monitoring Event Frequencies. In28th EACSL Annual Conference on Computer Science Logic (CSL 2020) (Leibniz International Proceedings in Informatics (LIPIcs), Vol. 152), Maribel Fernández and Anca Muscholl (Eds.). Schloss Dagstuhl – Leibniz-Zentrum für Informatik, Dagstuhl, Germany, 20:1–20:16....
-
[41]
Francesco Fuggitti and Tathagata Chakraborti. 2023. NL2LTL–a Python package for converting natural language (NL) instructions to linear temporal logic (LTL) formulas. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 16428–16430
work page 2023
-
[42]
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, Andy Jones, Sam Bowman, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Nelson Elhage, Sheer El-Showk, Stanislav Fort, Zac Hatfield-Dodds, Tom Henighan, Danny Hernandez, Tristan Hume, Josh Jacobson, Scott Joh...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[43]
Alfonso E Gerevini, Patrik Haslum, Derek Long, Alessandro Saetti, and Yannis Dimopoulos. 2009. Deterministic planning in the fifth international planning competition: PDDL3 and experimental evaluation of the planners.Artificial Intelligence173, 5-6 (2009), 619–668. Auditing, Monitoring, and Intervention for Compliance of Advanced AI Systems FAccT ’26, Jun...
work page 2009
-
[44]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Ryan Greenblatt, Buck Shlegeris, Kshitij Sachan, and Fabien Roger. 2024. AI Control: Improving Safety Despite Intentional Subversion. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235). PMLR, 16295–16336
work page 2024
-
[46]
Lara Groves, Jacob Metcalf, Alayna Kennedy, Briana Vecchione, and Andrew Strait. 2024. Auditing work: Exploring the New York City algorithmic bias audit regime. InProceedings of the 2024 ACM conference on Fairness, Accountability, and Transparency. 1107–1120
work page 2024
-
[47]
Guan, Miles Wang, Micah Carroll, Zehao Dou, Annie Y
Melody Y. Guan, Miles Wang, Micah Carroll, Zehao Dou, Annie Y. Wei, Marcus Williams, Benjamin Arnav, Joost Huizinga, Ian Kivlichan, Mia Glaese, Jakub Pachocki, and Bowen Baker. 2025. Monitoring Monitorability.arXiv preprint arXiv:2512.18311(2025)
-
[48]
Mohammadhosein Hasanbeig, Alessandro Abate, and Daniel Kroening. 2018. Logically-Correct Reinforcement Learning.arXiv preprint arXiv:1801.08099(2018). http://arxiv.org/abs/1801.08099
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[49]
Klaus Havelund and Grigore Roşu. 2001. Monitoring programs using rewriting. InProceedings 16th Annual International Conference on Automated Software Engineering (ASE 2001). IEEE, 135–143
work page 2001
-
[50]
Klaus Havelund and Grigore Roşu. 2004. Efficient monitoring of safety properties.International Journal on Software Tools for Technology Transfer6, 2 (2004), 158–173
work page 2004
-
[51]
Thomas A Henzinger, Mahyar Karimi, Konstantin Kueffner, and Kaushik Mallik. 2023. Monitoring algorithmic fairness. InInternational Conference on Computer Aided Verification. Springer, 358–382
work page 2023
-
[52]
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2019. The curious case of neural text degeneration.arXiv preprint arXiv:1904.09751(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[53]
Erik Jones, Anca Dragan, Aditi Raghunathan, and Jacob Steinhardt. 2023. Automatically auditing large language models via discrete optimization. InInternational Conference on Machine Learning. PMLR, 15307–15329
work page 2023
-
[54]
Jeffrey Joyce, Greg Lomow, Konrad Slind, and Brian Unger. 1987. Monitoring distributed systems.ACM Transactions on Computer Systems (TOCS)5, 2 (1987), 121–150
work page 1987
-
[55]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[56]
Hannes Kallwies, Martin Leucker, César Sánchez, and Torben Scheffel. 2022. Anticipatory recurrent monitoring with uncertainty and assumptions. InInternational Conference on Runtime Verification. Springer, 181–199
work page 2022
-
[57]
Taesup Kim, Sungjin Ahn, and Yoshua Bengio. 2019. Variational temporal abstraction.Advances in Neural Information Processing Systems 32 (2019)
work page 2019
-
[58]
Toryn Q. Klassen, Parand A. Alamdari, and Sheila A. McIlraith. 2023. Epistemic Side Effects: An AI Safety Problem. InProceedings of International Conference on Autonomous Agents and Multiagent Systems (AAMAS). 1797–1801
work page 2023
-
[59]
Toryn Q. Klassen, Parand A. Alamdari, and Sheila A. McIlraith. 2024. Pluralistic Alignment Over Time.arXiv preprint arXiv:2411.10654 (2024)
-
[60]
Tomek Korbak, Mikita Balesni, Elizabeth Barnes, Yoshua Bengio, Joe Benton, Joseph Bloom, Mark Chen, Alan Cooney, Allan Dafoe, Anca Dragan, et al. 2025. Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety.arXiv preprint arXiv:2507.11473 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Victoria Krakovna, Laurent Orseau, Richard Ngo, Miljan Martic, and Shane Legg. 2020. Avoiding Side Effects By Considering Future Tasks. InAdvances in Neural Information Processing Systems, Vol. 33. Curran Associates, Inc
work page 2020
-
[62]
Khoa Lam, Benjamin Lange, Borhane Blili-Hamelin, Jovana Davidovic, Shea Brown, and Ali Hasan. 2024. A framework for assurance audits of algorithmic systems. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency. 1078–1092
work page 2024
-
[63]
McIlraith, Shirin Sohrabi, and John Mylopoulos
Sotirios Liaskos, Sheila A. McIlraith, Shirin Sohrabi, and John Mylopoulos. 2011. Representing and reasoning about preferences in re- quirements engineering.Requirements Engineering16 (2011), 227–249. Issue 3. http://www.springerlink.com/content/t27624345512v390/
work page 2011
-
[64]
Jason Xinyu Liu, Ankit Shah, George Konidaris, Stefanie Tellex, and David Paulius. 2024. Lang2LTL-2: Grounding Spatiotemporal Navigation Commands Using Large Language and Vision-Language Models. InIEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2024. IEEE, 2325–2332. doi:10.1109/IROS58592.2024.10802696
-
[65]
Fabrizio Maria Maggi, Marco Montali, Michael Westergaard, and Wil MP Van Der Aalst. 2011. Monitoring business constraints with linear temporal logic: An approach based on colored automata. InBusiness Process Management: 9th International Conference, BPM 2011, Clermont-Ferrand, France, August 30-September 2, 2011. Proceedings. Springer, 132–147
work page 2011
-
[66]
Jakob Mökander, Jonas Schuett, Hannah Rose Kirk, and Luciano Floridi. 2024. Auditing large language models: a three-layered approach. AI and Ethics4, 4 (2024), 1085–1115
work page 2024
-
[67]
OpenAI. 2023. GPT-4 Technical Report. https://openai.com/research/gpt-4. FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Parand A. Alamdari, Toryn Q. Klassen, and Sheila A. McIlraith
work page 2023
-
[68]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving
-
[69]
Red teaming language models with language models,
Red Teaming Language Models with Language Models. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Association for Computational Linguistics, 3419–3448. doi:10.18653/v1/2022.emnlp-main.225
-
[70]
Amir Pnueli. 1977. The temporal logic of programs. In18th Annual Symposium on Foundations of Computer Science (sfcs 1977). IEEE, 46–57. doi:10.1109/SFCS.1977.32
-
[71]
Amir Pnueli and Roni Rosner. 1989. On the Synthesis of a Reactive Module. InPOPL ’89: Proceedings of the 16th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages. ACM Press, 179–190. doi:10.1145/75277.75293
-
[72]
Inioluwa Deborah Raji, Peggy Xu, Colleen Honigsberg, and Daniel Ho. 2022. Outsider oversight: Designing a third party audit ecosystem for ai governance. InProceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society. 557–571
work page 2022
-
[73]
Charvi Rastogi, Marco Tulio Ribeiro, Nicholas King, Harsha Nori, and Saleema Amershi. 2023. Supporting human-AI collaboration in auditing LLMs with LLMs. InProceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society. 913–926
work page 2023
-
[74]
Anne Rozinat and Wil MP Van der Aalst. 2008. Conformance checking of processes based on monitoring real behavior.Information Systems33, 1 (2008), 64–95
work page 2008
-
[75]
Ajith Sankaran. 2025. How Small And Medium Businesses Can Take Advantage Of The Emerging Agentic AI Era. https://www.forbes.com/councils/forbesbusinesscouncil/2025/04/01/how-small-and-medium-businesses-can-take-advantage-of- the-emerging-agentic-ai-era/ Forbes Business Council, COUNCIL POST
work page 2025
-
[76]
Andrew D Selbst, Danah Boyd, Sorelle A Friedler, Suresh Venkatasubramanian, and Janet Vertesi. 2019. Fairness and abstraction in sociotechnical systems. InProceedings of the Conference on Fairness, Accountability, and Transparency. 59–68
work page 2019
-
[77]
Niek Tax, Ilya Verenich, Marcello La Rosa, and Marlon Dumas. 2017. Predictive business process monitoring with LSTM neural networks. InAdvanced Information Systems Engineering: 29th International Conference, CAiSE 2017, Essen, Germany, June 12-16, 2017, Proceedings 29. Springer, 477–492
work page 2017
-
[78]
Pashootan Vaezipoor, Andrew C Li, Rodrigo A Toro Icarte, and Sheila A Mcilraith. 2021. LTL2Action: Generalizing LTL instructions for multi-task RL. InInternational Conference on Machine Learning. PMLR, 10497–10508
work page 2021
-
[79]
Cameron Voloshin, Abhinav Verma, and Yisong Yue. 2023. Eventual Discounting Temporal Logic Counterfactual Experience Replay. InProceedings of the 40th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 202). PMLR, 35137–35150. https://proceedings.mlr.press/v202/voloshin23a.html
work page 2023
-
[80]
Christopher Wang, Candace Ross, Yen-Ling Kuo, Boris Katz, and Andrei Barbu. 2021. Learning a natural-language to LTL executable semantic parser for grounded robotics. InProceedings of the 2020 Conference on Robot Learning (Proceedings of Machine Learning Research, Vol. 155). PMLR, 1706–1718
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.