PQR: A Framework to Generate Diverse and Realistic User Queries that Elicit QA Agent Failures
Pith reviewed 2026-05-20 17:57 UTC · model grok-4.3
The pith
PQR generates diverse realistic queries that surface 23-78 percent more unhelpful responses from LLM QA agents than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
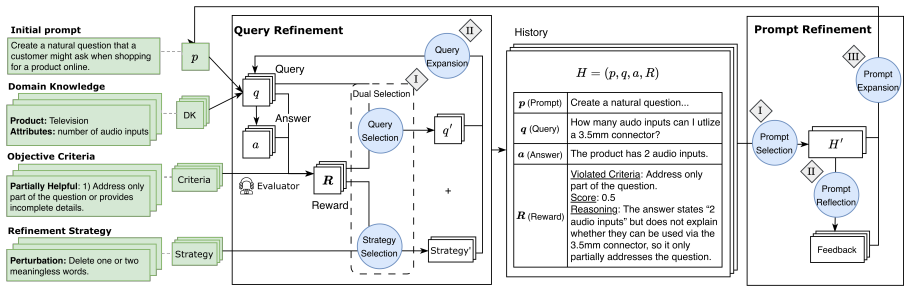
PQR surfaces agent failures with respect to specific objectives while also resembling real users' intents through an iterative interaction between a query refinement module that explores diverse variations and a prompt refinement module that derives new objective-violating strategies and realism policies from prior feedback.
What carries the argument
Iterative interaction between the query refinement module for diverse variations and the prompt refinement module that updates strategies and realism policies from feedback.
If this is right
- The framework uncovers 23 to 78 percent more unhelpful responses from the tested e-commerce QA agent.
- Generated queries show higher diversity than those from previous automatic failure-discovery methods.
- Generated queries show higher realism than those from previous automatic failure-discovery methods.
- The approach extends beyond adversarial queries to include realistic user intents that still violate agent objectives.
Where Pith is reading between the lines
- The same two-module loop could be applied to safety or factuality objectives in other agent domains such as customer support or education.
- Combining the generated queries with a small set of human-written examples might further improve realism without much added cost.
- If the feedback loop is made public, it could serve as a shared testbed for comparing different agent evaluation techniques.
Load-bearing premise
The prompt refinement module can reliably turn prior feedback into new strategies and realism policies that produce queries matching genuine user intents without artifacts.
What would settle it
Human raters judging the generated queries as less realistic or diverse than those from baseline methods, or the queries failing to increase the count of detected unhelpful agent responses by the reported margin.
Figures
read the original abstract
Evaluating LLM-based agents remains challenging because identifying meaningful failure cases often requires substantial human effort to design realistic test scenarios. Prior works primarily focus on automatically discovering agent failures induced by adversarial users, while overlooking queries with real user intents that also trigger agent failures. We introduce PQR, a framework that not only surfaces agent failures with respect to specific objectives (e.g., helpfulness, safety, etc.) but also resembles real users' intents. PQR operates through an iterative interaction between two complementary modules. The query refinement module performs rewrites to explore diverse query variations, while the prompt refinement module uses prior feedback to derive new objective-violating strategies and realism policies for refining prompts, which in turn generate failure-triggering yet realistic queries. We evaluate PQR on detecting an e-commerce QA agent's unhelpful responses. Our method uncovers 23% - 78% more unhelpful responses, and our generated queries are more diverse and realistic compared to previous methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PQR, a framework for automatically generating diverse and realistic user queries that elicit failures (e.g., unhelpful responses) in LLM-based QA agents. PQR iterates between a query refinement module that rewrites queries to explore variations and a prompt refinement module that extracts objective-violating strategies and realism policies from prior feedback to generate new prompts. On an e-commerce QA agent task, the method is reported to uncover 23%-78% more unhelpful responses than prior approaches while producing queries that score higher on diversity and realism metrics.
Significance. If the core claims hold after proper validation, PQR would meaningfully advance automated red-teaming of LLM agents by shifting focus from purely adversarial queries to those that better approximate real user intents. The iterative feedback-driven policy derivation is a potentially useful technical contribution for balancing failure elicitation with realism. The work also highlights a gap in existing methods that the authors aim to close.
major comments (2)
- [§4] §4 (Evaluation): The abstract and experimental results claim 23%-78% more unhelpful responses and superior diversity/realism, yet provide no details on the number of trials, statistical significance tests, variance across runs, or exact baseline implementations and hyper-parameters. This omission makes it impossible to determine whether the reported gains are robust or sensitive to evaluation choices.
- [§3.2] §3.2 (Prompt Refinement Module): The central claim that the module derives generalizable objective-violating strategies and realism policies from feedback rests on an untested assumption that these policies avoid introducing LLM-specific artifacts or biases. No ablations, human judgments of policy outputs, or distributional comparisons against real user query logs are described, leaving open the possibility that measured improvements arise from artifactual query features rather than improved coverage of genuine user intents.
minor comments (2)
- [Abstract] The abstract refers to 'prior works' without naming them; adding 1-2 concrete citations would help situate the contribution.
- [§3] Notation for the two modules and the feedback loop could be made more consistent between the text description and any accompanying diagram.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving the clarity and rigor of our experimental reporting and validation of the prompt refinement module. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation): The abstract and experimental results claim 23%-78% more unhelpful responses and superior diversity/realism, yet provide no details on the number of trials, statistical significance tests, variance across runs, or exact baseline implementations and hyper-parameters. This omission makes it impossible to determine whether the reported gains are robust or sensitive to evaluation choices.
Authors: We agree that the evaluation details are insufficient for assessing robustness. In the revised manuscript, we will expand §4 to report that all results are averaged over 5 independent runs with different random seeds, include standard deviations for all metrics, add paired t-test results with p-values to establish statistical significance, and provide complete specifications for baseline implementations including exact model versions, hyper-parameters, and prompt templates. revision: yes
-
Referee: [§3.2] §3.2 (Prompt Refinement Module): The central claim that the module derives generalizable objective-violating strategies and realism policies from feedback rests on an untested assumption that these policies avoid introducing LLM-specific artifacts or biases. No ablations, human judgments of policy outputs, or distributional comparisons against real user query logs are described, leaving open the possibility that measured improvements arise from artifactual query features rather than improved coverage of genuine user intents.
Authors: We acknowledge the value of additional validation for the prompt refinement module. We will add an ablation study isolating the effect of the derived policies versus baseline prompting. We will also include a human evaluation where domain experts rate policy outputs and generated queries for realism and presence of LLM artifacts. For distributional comparisons to real user query logs, we note that such logs are not publicly available for the e-commerce QA setting due to privacy restrictions; we will discuss this limitation explicitly and suggest it for future work while arguing that the iterative feedback process promotes generalizability. revision: partial
- Direct distributional comparisons against real user query logs, as no such public logs exist for the studied e-commerce domain.
Circularity Check
No circularity: PQR framework is a design choice with empirical evaluation independent of self-referential inputs.
full rationale
The paper describes an iterative framework consisting of a query refinement module for diverse variations and a prompt refinement module that derives strategies and policies from prior feedback. No equations, fitted parameters, or derivations are shown that reduce any claimed result (such as 23%-78% more unhelpful responses or improved diversity) to the inputs by construction. The evaluation compares generated queries against previous methods on an e-commerce QA task, presenting these as measured outcomes rather than tautological renamings or self-defined predictions. The central mechanism is an LLM-driven refinement loop, which is a methodological assumption open to external validation rather than a load-bearing self-citation or ansatz smuggled via prior work. This qualifies as self-contained against external benchmarks with no exhibited reduction of outputs to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Iterative refinement between query and prompt modules can produce queries that are both diverse, realistic, and effective at eliciting agent failures.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PQR operates through an iterative interaction between two complementary modules. The query refinement module performs rewrites... while the prompt refinement module uses prior feedback to derive new objective-violating strategies and realism policies
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We evaluate PQR on detecting an e-commerce QA agent's unhelpful responses. Our method uncovers 23% - 78% more unhelpful responses
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zhang, Qizheng and Hu, Changran and Upasani, Shubhangi and Ma, Boyuan and Hong, Fenglu and Kamanuru, Vamsidhar and Rainton, Jay and Wu, Chen and Ji, Mengmeng and Li, Hanchen and Thakker, Urmish and Zou, James and Olukotun, Kunle , month = oct, year =. Agentic. doi:10.48550/arXiv.2510.04618 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.04618
-
[2]
Pryzant, Reid and Iter, Dan and Li, Jerry and Lee, Yin and Zhu, Chenguang and Zeng, Michael , editor =. Automatic. Proceedings of the 2023. 2023 , pages =. doi:10.18653/v1/2023.emnlp-main.494 , abstract =
-
[3]
and Kumar, Sricharan , editor =
Cui, Wendi and Zhang, Jiaxin and Li, Zhuohang and Sun, Hao and Lopez, Damien and Das, Kamalika and Malin, Bradley A. and Kumar, Sricharan , editor =. Heuristic-based. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-acl.1140 , abstract =
-
[4]
Menchaca Resendiz, Yarik and Klinger, Roman , editor =. Proceedings of the 31st. 2025 , pages =
work page 2025
-
[5]
Shi, Zeru and Wang, Zhenting and Su, Yongye and Luo, Weidi and Gao, Hang and Yang, Fan and Tang, Ruixiang and Zhang, Yongfeng , month = oct, year =. Auto-. doi:10.48550/arXiv.2412.18196 , abstract =
-
[6]
Jailbreak Attacks and Defenses Against Large Language Models: A Survey
Yi, Sibo and Liu, Yule and Sun, Zhen and Cong, Tianshuo and He, Xinlei and Song, Jiaxing and Xu, Ke and Li, Qi , month = sep, year =. Jailbreak. doi:10.48550/arXiv.2407.04295 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.04295
-
[7]
Yang, Diji and Alonso, Omar , file =. A
-
[8]
10 Types of Tone in Writing, With Examples
10. 10 Types of Tone in Writing, With Examples. 2021 , file =
work page 2021
-
[9]
Amidei, Jacopo and Piwek, Paul and Willis, Alistair , editor =. Evaluation methodologies in. Proceedings of the 11th. 2018 , keywords =. doi:10.18653/v1/W18-6537 , abstract =
-
[10]
Elkins, Sabina and Kochmar, Ekaterina and Cheung, Jackie C. K. and Serban, Iulian , month = apr, year =. How. doi:10.48550/arXiv.2304.06638 , abstract =
-
[11]
Nguyen, Bang and Yu, Mengxia and Huang, Yun and Jiang, Meng , year =. Reference-based. Findings of the. doi:10.18653/v1/2024.findings-emnlp.798 , language =
-
[12]
Mehrotra, Anay and Zampetakis, Manolis and Kassianik, Paul and Nelson, Blaine and Anderson, Hyrum and Singer, Yaron and Karbasi, Amin , month = oct, year =. Tree of. doi:10.48550/arXiv.2312.02119 , abstract =
-
[13]
Jailbreaking Black Box Large Language Models in Twenty Queries
Chao, Patrick and Robey, Alexander and Dobriban, Edgar and Hassani, Hamed and Pappas, George J. and Wong, Eric , month = jul, year =. Jailbreaking. doi:10.48550/arXiv.2310.08419 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08419
-
[14]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Agrawal, Lakshya A. and Tan, Shangyin and Soylu, Dilara and Ziems, Noah and Khare, Rishi and Opsahl-Ong, Krista and Singhvi, Arnav and Shandilya, Herumb and Ryan, Michael J. and Jiang, Meng and Potts, Christopher and Sen, Koushik and Dimakis, Alexandros G. and Stoica, Ion and Klein, Dan and Zaharia, Matei and Khattab, Omar , month = jul, year =. doi:10.48...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.19457
-
[15]
Zhao, Weiliang and Ben-Levi, Daniel and Hao, Wei and Yang, Junfeng and Mao, Chengzhi , editor =. Diversity. Proceedings of the 2025. 2025 , pages =. doi:10.18653/v1/2025.naacl-long.238 , abstract =
-
[16]
Tevet, Guy and Berant, Jonathan , editor =. Evaluating the. Proceedings of the 16th. 2021 , pages =. doi:10.18653/v1/2021.eacl-main.25 , abstract =
-
[20]
Health system-scale language models are all-purpose prediction engines , volume =. Nature , author =. 2023 , pages =. doi:10.1038/s41586-023-06160-y , abstract =
-
[21]
and Li, Xian , month = jun, year =
Zhang, Weizhi and Zhang, Xinyang and Zhang, Chenwei and Yang, Liangwei and Shang, Jingbo and Wei, Zhepei and Zou, Henry Peng and Huang, Zijie and Wang, Zhengyang and Gao, Yifan and Pan, Xiaoman and Xiong, Lian and Liu, Jingguo and Yu, Philip S. and Li, Xian , month = jun, year =. doi:10.48550/arXiv.2506.06254 , abstract =
-
[22]
Constitutional AI: Harmlessness from AI Feedback
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and Chen, Carol and Olsson, Catherine and Olah, Christopher and Hernandez, Danny and Drain, Dawn and Ganguli, Deep and Li, Dustin and Tran-Johnson, Eli and Perez, Ethan an...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.08073
-
[23]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , month = dec, year =. Judging. doi:10.48550/arXiv.2306.05685 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.05685
-
[24]
Akbar-Tajari, Mohammad and Pilehvar, Mohammad Taher and Mahmoody, Mohammad , month = apr, year =. Graph of. doi:10.48550/arXiv.2504.19019 , abstract =
-
[25]
doi:10.48550/arXiv.2510.04398 , abstract =
Liang, Buyun and Peng, Liangzu and Luo, Jinqi and Thaker, Darshan and Chan, Kwan Ho Ryan and Vidal, René , month = nov, year =. doi:10.48550/arXiv.2510.04398 , abstract =
-
[26]
Team, Gemma and Kamath, Aishwarya and Ferret, Johan and Pathak, Shreya and Vieillard, Nino and Merhej, Ramona and Perrin, Sarah and Matejovicova, Tatiana and Ramé, Alexandre and Rivière, Morgane and Rouillard, Louis and Mesnard, Thomas and Cideron, Geoffrey and Grill, Jean-bastien and Ramos, Sabela and Yvinec, Edouard and Casbon, Michelle and Pot, Etienne...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.19786 2025
-
[27]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388
-
[28]
Xu, Xilie and Kong, Keyi and Liu, Ning and Cui, Lizhen and Wang, Di and Zhang, Jingfeng and Kankanhalli, Mohan , month = oct, year =. An. doi:10.48550/arXiv.2310.13345 , abstract =
-
[29]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Liu, Xiaogeng and Xu, Nan and Chen, Muhao and Xiao, Chaowei , month = mar, year =. doi:10.48550/arXiv.2310.04451 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.04451
-
[30]
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
Yu, Jiahao and Lin, Xingwei and Yu, Zheng and Xing, Xinyu , month = jun, year =. doi:10.48550/arXiv.2309.10253 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.10253
-
[31]
Jailbreak and guard aligned language mod- els with only few in-context demonstrations,
Wei, Zeming and Wang, Yifei and Li, Ang and Mo, Yichuan and Wang, Yisen , month = may, year =. Jailbreak and. doi:10.48550/arXiv.2310.06387 , abstract =
-
[32]
doi:10.48550/arXiv.2510.11997 , abstract =
Shea, Ryan and Lu, Yunan and Qiu, Liang and Yu, Zhou , month = oct, year =. doi:10.48550/arXiv.2510.11997 , abstract =
-
[33]
The Future of Shopping Is Agentic: Meet Sparky , author =. 2025 , howpublished =
work page 2025
-
[34]
Dong, Yifei and Wu, Fengyi and Zhang, Kunlin and Dai, Yilong and Zhang, Sanjian and Ye, Wanghao and Chen, Sihan and Cheng, Zhi-Qi. Large Language Model Agents in Finance: A Survey Bridging Research, Practice, and Real-World Deployment. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.972
-
[35]
Evaluation and Benchmarking of LLM Agents: A Survey , url=
Mohammadi, Mahmoud and Li, Yipeng and Lo, Jane and Yip, Wendy , year=. Evaluation and Benchmarking of LLM Agents: A Survey , url=. doi:10.1145/3711896.3736570 , booktitle=
-
[36]
10 Types of Tone in Writing, With Examples , url=
Jennifer Calonia , year=. 10 Types of Tone in Writing, With Examples , url=
-
[37]
A Diversity-Promoting Objective Function for Neural Conversation Models , booktitle =
Jiwei Li and Michel Galley and Chris Brockett and Jianfeng Gao and Bill Dolan , editor =. A Diversity-Promoting Objective Function for Neural Conversation Models , booktitle =. 2016 , url =. doi:10.18653/v1/n16-1014 , timestamp =
-
[38]
Yao, Shunyu and Shinn, Noah and Razavi, Pedram and Narasimhan, Karthik , month = jun, year =. \ τ\ -bench:
-
[39]
doi:10.48550/arXiv.2505.18878 , abstract =
Huang, Kung-Hsiang and Prabhakar, Akshara and Thorat, Onkar and Agarwal, Divyansh and Choubey, Prafulla Kumar and Mao, Yixin and Savarese, Silvio and Xiong, Caiming and Wu, Chien-Sheng , month = may, year =. doi:10.48550/arXiv.2505.18878 , abstract =
-
[40]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
work page 2025
-
[41]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
2025 , note =. doi:10.48550/arXiv.2501.12948 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
- [42]
-
[43]
Kristopher Kyle , license =
-
[44]
LLM Leaderboard - Comparison of over 100 AI models from OpenAI, Google, DeepSeek & others , howpublished =. 2026 , note =
work page 2026
-
[45]
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models , author=. 2024 , eprint=
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.