Attention Hijacking: Response Manipulation Across Queries in Vision-Language Models
Pith reviewed 2026-05-20 14:21 UTC · model grok-4.3
The pith
Steering attention toward visual tokens lets one adversarial image force target responses across many different queries in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that preserving an image-dominant attention pattern during response generation enables substantially better cross-query transferability for adversarial examples in vision-language models. Attention Hijacking achieves this by explicitly amplifying the influence of visual tokens on target response tokens while suppressing the competing influence of textual tokens, thereby reducing how much the manipulated output depends on the specific wording of any given query.
What carries the argument
Attention Hijacking, the method that steers internal attention distributions toward a persistent image-dominant pattern by amplifying visual token influence on target response tokens and suppressing textual token influence.
If this is right
- The attack improves transfer success across diverse target responses and previously unseen queries on standard vision-language models.
- The same steering approach extends to several different attack scenarios beyond the initial setting.
- Attention stability emerges as a controllable factor that directly affects how well response manipulation survives changes in query text.
- The findings highlight that internal attention patterns can be a lever for making adversarial examples more query-independent.
Where Pith is reading between the lines
- Defenses could focus on detecting or regularizing image-dominant attention shifts rather than only looking at final output tokens.
- The same attention-steering idea might transfer to other multimodal systems where one modality needs to dominate over another for attack transfer.
- If attention hijacking proves reliable, training routines that encourage balanced attention across modalities could reduce vulnerability to this class of attack.
- Future work might test whether the method still works when the model is fine-tuned on data that explicitly discourages over-reliance on visual tokens.
Load-bearing premise
That preserving an image-dominant attention pattern during response generation is what drives successful cross-query transfer and that explicitly steering attention toward this pattern will produce the claimed transfer gains.
What would settle it
An experiment that steers attention to an image-dominant pattern yet finds no improvement in success rate when the same perturbed image is paired with new queries compared to existing attacks.
Figures
















read the original abstract
Existing adversarial attacks on vision-language models (VLMs) can steer model outputs toward attacker-specified target responses, but their effectiveness often degrades when the same perturbed input is paired with different textual queries. This paper studies cross-query response manipulation, where a single adversarial example is expected to remain effective across diverse user queries. We first analyze the limitations of existing attacks and find that successful transfer is closely associated with preserving an image-dominant attention pattern during response generation. Motivated by the observation, we propose \textbf{Attention Hijacking}, a novel adversarial attack that explicitly steers internal attention distributions toward a persistent image-dominant pattern. By amplifying the influence of visual tokens on target response tokens while suppressing the competing influence of textual tokens, our method reduces the dependence of the manipulated output on the specific wording of the query. Extensive experiments on widely used VLMs show that Attention Hijacking substantially improves cross-query transferability across diverse target responses and unseen queries. The method also extends effectively to multiple attack scenarios, offering new insights into the role of attention stability in transferable response manipulation for VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Attention Hijacking, a novel adversarial attack on vision-language models aimed at cross-query response manipulation. It first analyzes existing attacks and observes that successful transfer across queries correlates with preserving an image-dominant attention pattern during response generation. Motivated by this, the method explicitly steers attention distributions by amplifying the influence of visual tokens on target response tokens while suppressing textual token influence. Extensive experiments on standard VLMs demonstrate substantially improved cross-query transferability for diverse target responses and unseen queries, with extensions to multiple attack scenarios.
Significance. If the central claims hold after addressing the noted gaps, this work would be significant for adversarial robustness research in multimodal models. It provides mechanistic insights linking attention stability to query-independent transferability and offers a practical method that outperforms prior approaches in cross-query settings. The emphasis on internal attention patterns could guide both stronger attacks and potential defenses, advancing understanding of how VLMs process visual versus textual inputs under perturbation.
major comments (2)
- [§3 (Analysis and Motivation)] §3 (Analysis and Motivation): The manuscript reports an association between image-dominant attention patterns and successful cross-query transfers but does not establish that explicitly steering attention to this pattern is the causal mechanism driving the gains. No controlled ablation is presented that holds perturbation magnitude or other optimization terms fixed while removing the attention-hijacking objective to isolate its contribution. This is load-bearing for the central claim that the method 'reduces the dependence of the manipulated output on the specific wording of the query' via attention steering.
- [§5 (Experiments)] §5 (Experiments): The reported improvements in cross-query transferability lack supporting details on query selection criteria, statistical significance (e.g., error bars or p-values across runs), and full ablation tables comparing variants. Without these, it is difficult to verify that the gains are robust and not due to post-hoc choices or unaccounted factors, undermining the claim of 'substantially improves cross-query transferability'.
minor comments (2)
- [Abstract] Abstract: The phrase 'substantially improves' should be accompanied by concrete metrics (e.g., average success rate increase) or a reference to the relevant table/figure for precision.
- [Method] Notation in the method description: Clarify how the amplification and suppression terms are combined into the final loss function, including any weighting hyperparameters, to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which help clarify the presentation of our contributions. We address each major comment below and will revise the manuscript accordingly to strengthen the evidence for our claims.
read point-by-point responses
-
Referee: [§3 (Analysis and Motivation)] §3 (Analysis and Motivation): The manuscript reports an association between image-dominant attention patterns and successful cross-query transfers but does not establish that explicitly steering attention to this pattern is the causal mechanism driving the gains. No controlled ablation is presented that holds perturbation magnitude or other optimization terms fixed while removing the attention-hijacking objective to isolate its contribution. This is load-bearing for the central claim that the method 'reduces the dependence of the manipulated output on the specific wording of the query' via attention steering.
Authors: We acknowledge that Section 3 primarily demonstrates a correlation between image-dominant attention patterns and improved cross-query transferability, without a controlled ablation that isolates the attention-hijacking term while holding perturbation magnitude and other loss components fixed. To directly address this, we will add such an ablation in the revised manuscript. We will compare the full Attention Hijacking objective against a variant that removes the attention-steering component (while matching perturbation budgets via the same L_p constraint), reporting the resulting differences in cross-query success rates. This will provide clearer evidence for the causal role of attention steering in reducing query dependence. revision: yes
-
Referee: [§5 (Experiments)] §5 (Experiments): The reported improvements in cross-query transferability lack supporting details on query selection criteria, statistical significance (e.g., error bars or p-values across runs), and full ablation tables comparing variants. Without these, it is difficult to verify that the gains are robust and not due to post-hoc choices or unaccounted factors, undermining the claim of 'substantially improves cross-query transferability'.
Authors: We agree that the experimental section would benefit from greater transparency and rigor. In the revision, we will expand Section 5 (and the appendix) to specify the query selection criteria in detail, including how queries were chosen for diversity in length, topic, and phrasing. We will also report results with error bars from multiple independent optimization runs, include p-values for key comparisons, and provide complete ablation tables for all method variants. These additions will allow readers to better assess the robustness of the transferability improvements. revision: yes
Circularity Check
No significant circularity; derivation is observation-driven and self-contained
full rationale
The paper first analyzes existing attacks to observe an association between successful cross-query transfer and image-dominant attention patterns during response generation. This empirical finding directly motivates the Attention Hijacking method, which introduces an explicit steering objective to amplify visual-token influence and suppress textual-token influence. No load-bearing step reduces to a self-citation chain, a fitted parameter renamed as a prediction, a self-definitional construct, or an ansatz imported from prior author work. The central claim rests on the proposed intervention and its experimental validation rather than on any internal redefinition or circular reduction of the target quantity. The derivation therefore remains independent of its own inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
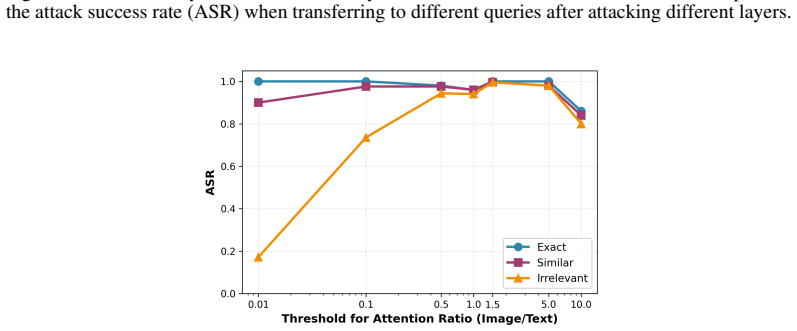
we encourage the average visual-to-textual attention ratio to exceed a threshold r, i.e., ¯A(l,h)img→y/( ¯A(l,h)txt→y +τ)≥r … LAR = Σ max(0, r − … )²
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
successful transfer is closely associated with preserving an image-dominant attention pattern during response generation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Lawrence Zitnick, Devi Parikh, and Dhruv Batra
Aishwarya Agrawal, Jiasen Lu, Stanislaw Antol, Margaret Mitchell, C. Lawrence Zitnick, Devi Parikh, and Dhruv Batra. Vqa: Visual question answering.International Journal of Computer Vision, 123:4 – 31, 2015
work page 2015
- [3]
-
[4]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenhang Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, K. Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Adversarial examples are not easily detected: Bypassing ten detection methods
Nicholas Carlini, Milad Nasr, Christopher A. Choquette-Choo, Matthew Jagielski, Irena Gao, Anas Awadalla, Pang Wei Koh, Daphne Ippolito, Katherine Lee, Florian Tramèr, and Ludwig Schmidt. Are aligned neural networks adversarially aligned?ArXiv, abs/2306.15447, 2023
-
[8]
Nicholas Carlini and David A. Wagner. Towards evaluating the robustness of neural networks. 2017 IEEE Symposium on Security and Privacy (SP), pages 39–57, 2016
work page 2017
-
[9]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Zhong Muyan, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. Intern vl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24185– 24198, 2023
work page 2024
- [10]
-
[11]
How robust is Google’s Bard to adversarial image attacks? arXiv:2309.11751, 2023
Yinpeng Dong, Huanran Chen, Jiawei Chen, Zhengwei Fang, X. Yang, Yichi Zhang, Yu Tian, Hang Su, and Jun Zhu. How robust is google’s bard to adversarial image attacks?ArXiv, abs/2309.11751, 2023
-
[12]
Yinpeng Dong, Fangzhou Liao, Tianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. Boosting adversarial attacks with momentum.2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9185–9193, 2017
work page 2018
-
[13]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 10
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[14]
Zhangwei Gao, Zhe Chen, Erfei Cui, Yiming Ren, Weiyun Wang, Jinguo Zhu, Hao Tian, Shenglong Ye, Junjun He, Xizhou Zhu, et al. Mini-internvl: a flexible-transfer pocket multi- modal model with 5% parameters and 90% performance.Visual Intelligence, 2(1):1–17, 2024
work page 2024
-
[15]
Explaining and Harnessing Adversarial Examples
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adver- sarial examples.CoRR, abs/1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[16]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[17]
Adversarial examples in the physical world
Alexey Kurakin, Ian J. Goodfellow, and Samy Bengio. Adversarial examples in the physical world.ArXiv, abs/1607.02533, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[19]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space, 2025
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context image ...
work page 2025
-
[20]
Evaluating Object Hallucination in Large Vision-Language Models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models.arXiv preprint arXiv:2305.10355, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Improved baselines with visual instruction tuning, 2023
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2023
work page 2023
-
[22]
Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
work page 2024
-
[23]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.ArXiv, abs/2304.08485, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Zhao Liu and Huan Zhang. Stealthy backdoor attack in self-supervised learning vision encoders for large vision language models.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 25060–25070, 2025
work page 2025
-
[25]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bing-Li Wang, Kai Dong, Bo Liu (Benjamin Liu), Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, Yaofeng Sun, Chengqi Deng, Hanwei Xu, Zhenda Xie, and Chong Ruan. Deepseek-vl: Towards real-world vision-language understanding.ArXiv, abs/2403.05525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks.ArXiv, abs/1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Jailbreaking attack against multimodal large language model.arXiv preprint arXiv:2402.02309, 2024
Zhenxing Niu, Haodong Ren, Xinbo Gao, Gang Hua, and Rong Jin. Jailbreaking attack against multimodal large language model.ArXiv, abs/2402.02309, 2024
- [28]
-
[29]
Visual adversarial examples jailbreak aligned large language models
Xiangyu Qi, Kaixuan Huang, Ashwinee Panda, Mengdi Wang, and Prateek Mittal. Visual adversarial examples jailbreak aligned large language models. InAAAI Conference on Artificial Intelligence, 2023
work page 2023
-
[30]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[31]
Intriguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, D. Erhan, Ian J. Goodfellow, and Rob Fergus. Intriguing properties of neural networks.CoRR, abs/1312.6199, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[32]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alab- dulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Attention! your vision language model could be maliciously manipulated
Xiaosen Wang, Shaokang Wang, Zhijin Ge, Yuyang Luo, and Shudong Zhang. Attention! your vision language model could be maliciously manipulated. 2025
work page 2025
-
[40]
Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding, 2024
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, Zhenda Xie, Yu Wu, Kai Hu, Jiawei Wang, Yaofeng Sun, Yukun Li, Yishi Piao, Kang Guan, Aixin Liu, Xin Xie, Yuxiang You, Kai Dong, Xingkai Yu, Haowei Zhang, Liang Zhao, Yisong Wang, and Chong Ruan. Deepseek-vl2: Mixture-of-experts visio...
work page 2024
-
[41]
Cihang Xie, Zhishuai Zhang, Jianyu Wang, Yuyin Zhou, Zhou Ren, and Alan Loddon Yuille. Im- proving transferability of adversarial examples with input diversity.2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2725–2734, 2018
work page 2019
-
[42]
Shadowcast: Stealthy data poisoning attacks against vision-language models
Yuancheng Xu, Jiarui Yao, Manli Shu, Yanchao Sun, Zichu Wu, Ning Yu, Tom Goldstein, and Furong Huang. Shadowcast: Stealthy data poisoning attacks against vision-language models. ArXiv, abs/2402.06659, 2024
-
[43]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
work page 2023
-
[44]
Theoretically principled trade-off between robustness and accuracy
Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric Xing, Laurent El Ghaoui, and Michael Jordan. Theoretically principled trade-off between robustness and accuracy. InInternational conference on machine learning, pages 7472–7482. PMLR, 2019
work page 2019
-
[45]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
work page 2023
-
[46]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Safety fine-tuning at (almost) no cost: A baseline for vision large language models
Yongshuo Zong, Ondrej Bohdal, Tingyang Yu, Yongxin Yang, and Timothy Hospedales. Safety fine-tuning at (almost) no cost: A baseline for vision large language models.arXiv preprint arXiv:2402.02207, 2024. 12
-
[48]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. A Related Works. A.1 Visual Language Models Visual Language Models (VLMs) represent a category of multimodal artificial intelligence systems designed to pro...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Gradient Update:Compute the gradient of the loss with respect to the current adversarial image: g(k) =∇ x(k) adv L(f, x(k) adv, q, Y),(10) then take a step in the negative gradient direction with step sizeα: ˜x(k+1) adv =x (k) adv −α·sign(g (k)).(11) The sign function is used for ℓ∞ norm constraints; for other norms, the raw gradient g(k) may be used inst...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.