CRAFT: Critic-Refined Adaptive Key-Frame Targeting for Multimodal Video Question Answering
Pith reviewed 2026-05-20 10:41 UTC · model grok-4.3
The pith
CRAFT refines claims from video keyframes with a critic loop to improve accuracy in multi-video news question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
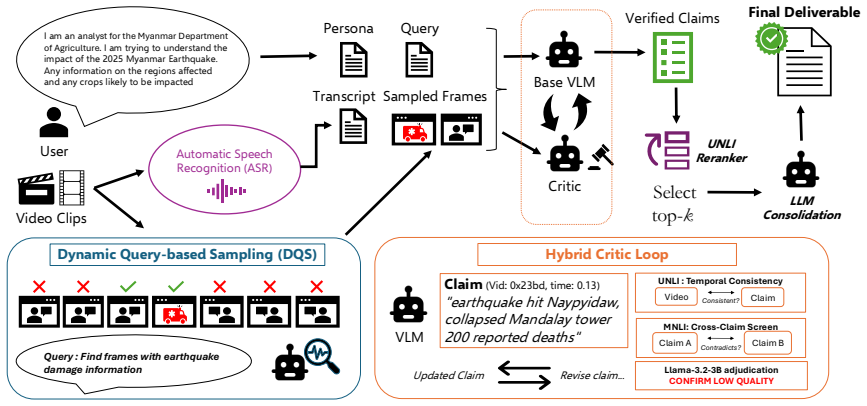
CRAFT is a query-conditioned pipeline combining dynamic key-frame selection, per-video ASR with multilingual fallback, and a hybrid critic loop that uses UNLI temporal entailment, DeBERTa-v3 cross-claim screening, and a Llama-3.2-3B adjudicator to iteratively verify and repair claims before emitting each fact once with all supporting source identifiers; on MAGMaR 2026 it records the highest overall average of 0.739, reference recall of 0.810, and citation F1 of 0.635, while also scoring 0.823 average on a MAGMaR-style WikiVideo conversion.
What carries the argument
The hybrid critic loop that iteratively verifies and repairs claims using temporal entailment checks, cross-claim screening, and an adjudicator model before citation merging.
If this is right
- Atomic claims, automatic speech recognition, and the critic loop each contribute measurable gains over a vanilla query-conditioned baseline.
- The same claim-centric aggregation approach generalizes to non-overlapping event queries on a converted WikiVideo dataset.
- Final citation merging ensures each fact appears once with all supporting source identifiers attached.
- The pipeline supports multilingual audio handling through fallback transcription.
Where Pith is reading between the lines
- Iterative claim repair may reduce unsupported statements in other multimodal evidence tasks such as timeline reconstruction from mixed video sources.
- The emphasis on source attribution could extend to live news monitoring systems that need traceable facts across incoming video streams.
- If the critic components scale with larger models, the method might support higher-volume archives without proportional increase in manual review.
Load-bearing premise
The hybrid critic loop can verify and repair claims without introducing new errors or biases.
What would settle it
Running the full pipeline on a fresh collection of news video queries and finding that the critic loop fails to raise reference recall or citation F1 above a simple query-conditioned baseline would disprove the central claim.
Figures
read the original abstract
Grounded multi-video question answering over real-world news events requires systems to surface query-relevant evidence across heterogeneous video archives while attributing every claim to its supporting source. We introduce CRAFT (Critic-Refined Adaptive Key-Frame Targeting), a query-conditioned pipeline that combines dynamic keyframe selection, per-video ASR with multilingual fallback, and a hybrid critic loop to iteratively verify and repair claims before consolidation. The pipeline integrates UNLI temporal entailment, DeBERTa-v3 cross-claim screening, and a Llama-3.2-3B adjudicator, with a final citation-merging stage that emits each fact once with all supporting source identifiers. On MAGMaR 2026, CRAFT achieves the best overall average (0.739), reference recall (0.810), and citation F1 (0.635). We further evaluate on a MAGMaR-style conversion of WikiVideo with 52 non-overlapping event queries, where CRAFT also performs strongly (0.823 Avg), showing that its claim-centric evidence aggregation generalizes beyond MAGMaR. Ablations show that atomic claims, ASR, and the critic loop drive the main gains over the vanilla query-conditioned baseline. Code and implementation details are publicly available at https://github.com/bhosalems/CRAFT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CRAFT, a query-conditioned pipeline for grounded multi-video question answering over news events. It integrates dynamic key-frame selection, per-video ASR with multilingual fallback, and a hybrid critic loop (UNLI temporal entailment + DeBERTa-v3 cross-claim screening + Llama-3.2-3B adjudicator) to iteratively verify and repair claims before final citation merging. On the MAGMaR 2026 benchmark the system reports the highest overall average (0.739), reference recall (0.810), and citation F1 (0.635); a MAGMaR-style conversion of WikiVideo with 52 event queries yields 0.823 average. Ablations attribute the main gains to atomic claims, ASR, and the critic loop.
Significance. If the critic loop can be shown to improve claim quality without injecting new errors or biases, the pipeline would offer a practical advance in evidence-grounded multimodal QA with explicit source attribution. Public code release supports reproducibility. The current evaluation, however, leaves the reliability of the critic component itself unmeasured, weakening attribution of the headline metrics.
major comments (2)
- [Ablation studies] Ablation studies: gains are attributed to the critic loop, yet no separate precision/recall figures, error analysis on repaired versus original claims, or bias checks (e.g., Llama-3.2-3B source-type preference) are reported. End-to-end metrics alone cannot confirm that the observed 0.810 reference recall and 0.635 citation F1 arise from accurate repairs rather than other stages or silent failures.
- [Experiments on MAGMaR 2026] MAGMaR 2026 results: the central performance claims (0.739 avg, 0.810 recall, 0.635 F1) rest on the unverified assumption that the iterative critic loop (UNLI + DeBERTa-v3 + Llama adjudicator) never drops valid evidence or fabricates citations. Without direct measurement of the loop's own accuracy, the headline numbers remain difficult to interpret.
minor comments (1)
- [Abstract] The abstract and evaluation sections should state the exact number of videos and queries in the primary MAGMaR 2026 test set to allow readers to assess scale and statistical power.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify the need for more granular evaluation of the critic loop, and we address each point below while committing to revisions that strengthen the attribution of our results.
read point-by-point responses
-
Referee: [Ablation studies] Ablation studies: gains are attributed to the critic loop, yet no separate precision/recall figures, error analysis on repaired versus original claims, or bias checks (e.g., Llama-3.2-3B source-type preference) are reported. End-to-end metrics alone cannot confirm that the observed 0.810 reference recall and 0.635 citation F1 arise from accurate repairs rather than other stages or silent failures.
Authors: We thank the referee for this observation. Our ablations demonstrate that ablating the critic loop reduces performance on reference recall and citation F1, supporting its contribution alongside atomic claims and ASR. However, we agree that end-to-end metrics alone leave room for ambiguity about whether gains stem from accurate repairs. We will add dedicated precision/recall figures for the critic loop, an error analysis contrasting repaired versus original claims, and bias checks on the Llama-3.2-3B adjudicator (including source-type preferences) in the revised manuscript. revision: yes
-
Referee: [Experiments on MAGMaR 2026] MAGMaR 2026 results: the central performance claims (0.739 avg, 0.810 recall, 0.635 F1) rest on the unverified assumption that the iterative critic loop (UNLI + DeBERTa-v3 + Llama adjudicator) never drops valid evidence or fabricates citations. Without direct measurement of the loop's own accuracy, the headline numbers remain difficult to interpret.
Authors: We acknowledge the referee's concern that direct accuracy measurement of the critic loop would make the headline metrics easier to interpret. The hybrid design (UNLI temporal entailment, DeBERTa-v3 screening, and Llama-3.2-3B adjudication) is intended to minimize both dropped evidence and fabricated citations, and the consistent gains across MAGMaR 2026 and the WikiVideo conversion support its net positive effect. To strengthen this, we will include a direct accuracy evaluation of the critic loop on a held-out sample of claims in the revision. revision: yes
Circularity Check
No circularity in CRAFT's empirical pipeline and benchmark results
full rationale
The paper describes a query-conditioned pipeline for multimodal video QA evaluated on external datasets (MAGMaR 2026 and a MAGMaR-style WikiVideo conversion). Performance numbers (0.739 avg, 0.810 recall, 0.635 F1) are reported as direct experimental outcomes rather than predictions derived from fitted parameters or equations within the paper. Ablations attribute gains to components like the critic loop, but these are empirical comparisons on held-out data, not self-definitional reductions or renamings of inputs. No mathematical derivation chain, uniqueness theorems, or ansatzes are invoked that collapse back to the paper's own fitted values or self-citations. The system is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Publications Manual , year = "1983", publisher =
work page 1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
- [4]
-
[5]
Dan Gusfield , title =. 1997
work page 1997
-
[6]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[7]
Proceedings of the 2024 ACM conference on fairness, accountability, and transparency , pages=
Careless whisper: Speech-to-text hallucination harms , author=. Proceedings of the 2024 ACM conference on fairness, accountability, and transparency , pages=
work page 2024
-
[8]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[9]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Z...
-
[10]
Bai, Shuai and Cai, Yuxuan and Chen, Ruizhe and Chen, Keqin and Chen, Xionghui and Cheng, Zesen and Deng, Lianghao and Ding, Wei and Gao, Chang and Ge, Chunjiang and Ge, Wenbin and Guo, Zhifang and Huang, Qidong and Huang, Jie and Huang, Fei and Hui, Binyuan and Jiang, Shutong and Li, Zhaohai and Li, Mingsheng and Li, Mei and Li, Kaixin and Lin, Zicheng a...
-
[11]
Zhu, Jinguo and Wang, Weiyun and Chen, Zhe and Liu, Zhaoyang and Ye, Shenglong and Gu, Lixin and Tian, Hao and Duan, Yuchen and Su, Weijie and Shao, Jie and Gao, Zhangwei and Cui, Erfei and Cao, Yue and Liu, Yangzhou and Wei, Xingguang and Zhang, Hongjie and Wang, Haomin and Xu, Weiye and Li, Hao and Wang, Jiahao and others , journal =
-
[12]
Robust Speech Recognition via Large-Scale Weak Supervision
Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya , title =. 2022 , copyright =. doi:10.48550/ARXIV.2212.04356 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.04356 2022
-
[13]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Video Instruction Tuning with Synthetic Data , author =. arXiv preprint arXiv:2410.02713 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Li, Bo and Zhang, Yuanhan and Guo, Dong and Zhang, Renrui and Li, Feng and Zhang, Hao and Zhang, Kaichen and Li, Yanwei and Liu, Ziwei and Li, Chunyuan , journal =
-
[15]
arXiv preprint arXiv:2504.00939 , year=
Wikivideo: Article generation from multiple videos , author=. arXiv preprint arXiv:2504.00939 , year=
-
[16]
Shen, Xiaoqian and Xiong, Yunyang and Zhao, Changsheng and Wu, Lemeng and Chen, Jun and Zhu, Chenchen and Liu, Zechun and Xiao, Fanyi and Varadarajan, Balakrishnan and Bordes, Florian and Liu, Zhuang and Xu, Hu and Kim, Hyunwoo J. and Soran, Bilge and Krishnamoorthi, Raghuraman and Elhoseiny, Mohamed and Chandra, Vikas , journal =
-
[17]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[18]
Shu, Yan and Zhang, Peitian and Liu, Zheng and Qin, Minghao and Zhou, Junjie and Liang, Zhengyang and Huang, Tiejun and Zhao, Bo , journal =
-
[19]
Song, Enxin and Chai, Wenhao and Wang, Guanhong and Zhang, Yucheng and Zhou, Haoyang and Wu, Feiyang and Chi, Haozhe and Guo, Xun and Ye, Tian and Zhang, Yanting and Lu, Yan and Hwang, Jenq-Neng and Wang, Gaoang , booktitle =. 2024 , pages =
work page 2024
-
[20]
He, Bo and Li, Hengduo and Jang, Young Kyun and Jia, Menglin and Cao, Xuefei and Shah, Ashish and Shrivastava, Abhinav and Lim, Ser-Nam , booktitle =
-
[21]
Qwen3-ASR Technical Report , author=. arXiv preprint arXiv:2601.21337 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Adaptive Keyframe Sampling for Long Video Understanding , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[23]
Gao, Hong and Wang, Yiming and Hu, Xin and Cao, Xun and Tao, Mingkui , journal =. 2025 , note =
work page 2025
-
[24]
Uncertain Natural Language Inference
Chen, Tongfei and Jiang, Zhengping and Poliak, Adam and Sakaguchi, Keisuke and Van Durme, Benjamin. Uncertain Natural Language Inference. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.774
-
[25]
Wang, Ziyang and Yu, Shoubin and Stengel-Eskin, Elias and Yoon, Jaehong and Cheng, Feng and Bertasius, Gedas and Bansal, Mohit , booktitle =. 2025 , pages =
work page 2025
-
[26]
Sun, Hui and Lu, Shiyin and Wang, Huanyu and Chen, Qing-Guo and Xu, Zhao and Luo, Weihua and Zhang, Kaifu and Li, Ming , journal =. 2025 , note =
work page 2025
-
[27]
Zhang, Shaojie and Yang, Jiahui and Yin, Jianqin and Luo, Zhenbo and Luan, Jian , journal =. 2025 , note =
work page 2025
-
[28]
Pengcheng He and Jianfeng Gao and Weizhu Chen , year=. De. International Conference on Learning Representations (
-
[29]
Zhang, Xian and Wu, Zexi and Li, Zinuo and Xu, Hongming and Gong, Luqi and Boussaid, Farid and Werghi, Naoufel and Bennamoun, Mohammed , journal =
-
[30]
International Conference on Learning Representations (ICLR) , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations (ICLR) , year=
-
[31]
Text Summarization Branches Out: Proceedings of the ACL-04 Workshop , pages=
ROUGE: A Package for Automatic Evaluation of Summaries , author=. Text Summarization Branches Out: Proceedings of the ACL-04 Workshop , pages=
-
[32]
Ragas: Automated Evaluation of Retrieval Augmented Generation
RAGAs: Automated Evaluation of Retrieval Augmented Generation , author=. arXiv preprint arXiv:2309.15217 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Unified Multimodal Uncertain Inference
Unified Multimodal Uncertain Inference , author=. arXiv preprint arXiv:2604.08701 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
arXiv preprint arXiv:2510.24870 , year=
Seeing Through the MiRAGE: Evaluating Multimodal Retrieval Augmented Generation , author=. arXiv preprint arXiv:2510.24870 , year=
- [35]
-
[36]
Wang, Xiaohan and Zhang, Yuhui and Zohar, Orr and Yeung-Levy, Serena , booktitle =
-
[37]
Min, Juhong and Buch, Shyamal and Nagrani, Arsha and Cho, Minsu and Schmid, Cordelia , booktitle =. 2024 , pages =
work page 2024
-
[38]
Zhi, Zhuo and Wu, Qiangqiang and Shen, Minghe and Li, Wenbo and Li, Yinchuan and Shao, Kun and Zhou, Kaiwen , journal =
-
[39]
Deep Video Discovery: Agentic Search with Tool Use for Long-Form Video Understanding , author =. arXiv preprint arXiv:2505.18079 , year =
-
[40]
Yuan, Huaying and Liu, Zheng and Zhou, Junjie and Qian, Hongjin and Wen, Ji-Rong and Dou, Zhicheng , journal =
- [42]
-
[43]
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh , booktitle =. Self-
-
[44]
Corrective Retrieval Augmented Generation
Corrective Retrieval Augmented Generation , author =. arXiv preprint arXiv:2401.15884 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Liu, Ye and Lin, Kevin Qinghong and Chen, Chang Wen and Shou, Mike Zheng , booktitle =
-
[46]
Dang, Jisheng and Song, Huilin and Xiao, Junbin and Wang, Bimei and Peng, Han and Li, Haoxuan and Yang, Xun and Wang, Meng and Chua, Tat-Seng , journal =
-
[47]
Qwen3-Omni Technical Report , author=. arXiv preprint arXiv:2509.17765 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Correctness is not Faithfulness in Retrieval Augmented Generation Attributions , author =. Proceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Retrieval (ICTIR) , year =
work page 2025
-
[49]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding , author=. arXiv preprint arXiv:2601.10611 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Gemma: Open Models Based on Gemini Research and Technology
Gemma: Open models based on gemini research and technology , author=. arXiv preprint arXiv:2403.08295 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[52]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =
MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =
work page 2024
-
[53]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[54]
Wang, Yuxuan and Wang, Yueqian and Zhao, Dongyan and Xie, Cihang and Zheng, Zilong , journal =
-
[55]
Zhang, Jiacheng and Jiao, Yang and Chen, Shaoxiang and Zhao, Na and Tan, Zhiyu and Li, Hao and Ma, Xingjun and Chen, Jingjing , journal =
-
[56]
Li, Chaoyu and Im, Eun Woo and Fazli, Pooyan , booktitle =. 2025 , pages =
work page 2025
-
[57]
Kriz, Reno and Sanders, Kate and Etter, David and Murray, Kenton and Carpenter, Cameron and Van Ochten, Kelly and Recknor, Hannah and Guallar-Blasco, Jimena and Martin, Alexander and Colaianni, Ronald and King, Nolan and Yang, Eugene and Van Durme, Benjamin , booktitle =
-
[58]
Samuel, Saron and DeGenaro, Dan and Guallar-Blasco, Jimena and Sanders, Kate and Eisape, Oluwaseun and Spendlove, Tanner and Reddy, Arun and Martin, Alexander and Yates, Andrew and Yang, Eugene and Carpenter, Cameron and Etter, David and Kayi, Efsun and Wiesner, Matthew and Murray, Kenton and Kriz, Reno , booktitle =
-
[59]
Jeong, Soyeong and Kim, Kangsan and Baek, Jinheon and Hwang, Sung Ju , booktitle =. 2025 , pages =
work page 2025
-
[60]
Ren, Xubin and Xu, Lingrui and Xia, Long and Wang, Shuaiqiang and Yin, Dawei and Huang, Chao , journal =
-
[61]
Zeng, Nianbo and Hou, Haowen and Yu, Fei Richard and Shi, Si and He, Ying Tiffany , journal =
-
[62]
arXiv preprint arXiv:2510.02262 , year =
From Frames to Clips: Efficient Key Clip Selection for Long-Form Video Understanding , author =. arXiv preprint arXiv:2510.02262 , year =
-
[63]
arXiv preprint arXiv:2407.15047 , year =
End-to-End Video Question Answering with Frame Scoring Mechanisms and Adaptive Sampling , author =. arXiv preprint arXiv:2407.15047 , year =
-
[64]
Zou, Yuanhao and Liu, Yifan and Liu, Yang and Zhang, Yifan and Zhang, Han and Chen, Chen , journal =
-
[65]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Re-Thinking Temporal Search for Long-Form Video Understanding , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.