Diagnosing Multi-step Reasoning Failures in Black-box LLMs via Stepwise Confidence Attribution
Pith reviewed 2026-05-20 06:39 UTC · model grok-4.3
pith:U7YYKK4M Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{U7YYKK4M}
Prints a linked pith:U7YYKK4M badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Stepwise Confidence Attribution assigns per-step confidence to LLM reasoning traces by checking alignment with consensus patterns from correct solutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Stepwise Confidence Attribution (SCA) is a framework that assigns step-level confidence scores to reasoning traces generated by black-box LLMs using the Information Bottleneck principle. Steps that align with consensus structures across correct solutions receive high confidence while deviations are flagged as potentially erroneous. Two complementary methods, NIBS (non-parametric) and GIBS (graph-based with differentiable masks), implement this without any internal model access. On mathematical reasoning and multi-hop question answering, the resulting low-confidence steps correlate strongly with reasoning errors, and guiding self-correction with these step scores improves success rates by up
What carries the argument
Stepwise Confidence Attribution (SCA) applies the Information Bottleneck principle to generated reasoning traces, scoring each step by its consistency with consensus structures drawn from correct solutions.
If this is right
- Low-confidence steps identified by SCA can be targeted directly for self-correction in multi-step tasks.
- Self-correction success improves measurably when step-level scores replace final-answer feedback.
- The same approach applies to both mathematical reasoning problems and multi-hop question answering.
- NIBS works without building graphs while GIBS captures logical variability through learned subgraphs.
Where Pith is reading between the lines
- The method could be tested on longer or more open-ended reasoning chains to see whether error accumulation becomes easier to spot.
- Combining step-level scores with other black-box signals such as token-level entropy might further localize failures.
- The consensus-pattern idea suggests a general route for debugging black-box models in domains like code generation where step errors also occur.
Load-bearing premise
The premise that steps matching common patterns seen in correct solutions are trustworthy while deviations are likely mistakes remains valid when the method looks only at the model's own generated traces.
What would settle it
Manually label a large collection of reasoning traces for the exact step where each error occurs; if the steps SCA marks low-confidence do not match those human labels at high rates, or if step-guided correction fails to beat answer-level feedback, the claim does not hold.
Figures




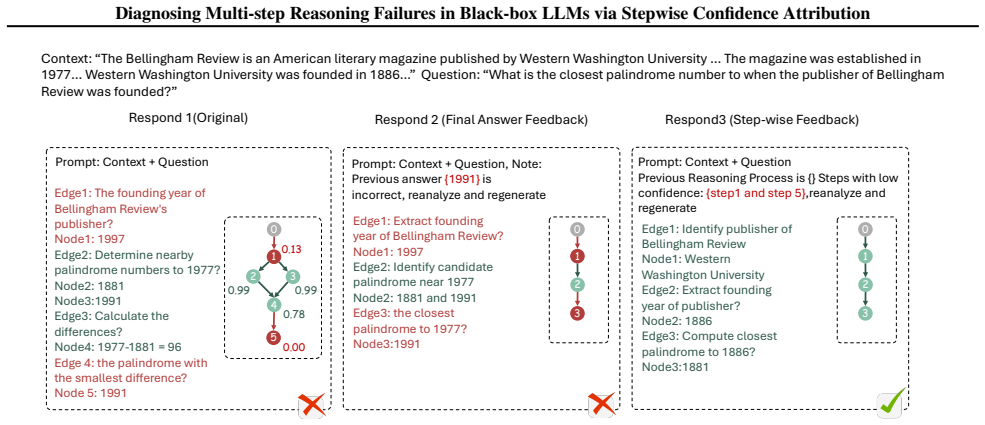
read the original abstract
Large Language Models have achieved strong performance on reasoning tasks with objective answers by generating step-by-step solutions, but diagnosing where a multi-step reasoning trace might fail remains difficult. Confidence estimation offers a diagnostic signal, yet existing methods are restricted to final answers or require internal model access. In this paper, we introduce Stepwise Confidence Attribution (SCA), a framework for closed-source LLMs that assigns step-level confidence based only on generated reasoning traces. SCA applies the Information Bottleneck principle: steps aligning with consensus structures across correct solutions receive high confidence, while deviations are flagged as potentially erroneous. We propose two complementary methods: (1) NIBS, a non-parametric IB approach measuring consistency without graph structures, and (2) GIBS, a graph-based IB model that learns subgraphs through a differentiable mask to capture logical variability. Extensive experiments on mathematical reasoning and multi-hop question answering show that SCA reliably identifies low-confidence steps strongly correlated with reasoning errors. Moreover, using step-level confidence to guide self-correction improves the correction success rate by up to 13.5\% over answer-level feedback.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Stepwise Confidence Attribution (SCA), a black-box framework that applies the Information Bottleneck principle to assign per-step confidence scores to LLM reasoning traces. Steps consistent with consensus structures extracted from pools of correct solutions receive high confidence; deviations are treated as potential errors. Two instantiations are presented: NIBS (non-parametric consistency) and GIBS (differentiable graph-subgraph masking). Experiments on mathematical reasoning and multi-hop QA tasks report that low-confidence steps correlate with actual errors and that step-level guidance improves self-correction success rates by up to 13.5% relative to answer-level baselines.
Significance. If the reported correlations and correction gains prove robust, SCA would supply a practical diagnostic and intervention tool for closed-source models on multi-step tasks. The information-theoretic grounding and the two complementary implementations (NIBS/GIBS) constitute a clear technical contribution that could be adopted or extended by the community.
major comments (2)
- [§3] §3 (SCA formulation): The core IB objective defines high-confidence steps via alignment with consensus structures derived from a pool of correct traces. This construction is not a direct error detector; it presupposes that correct solutions share sufficiently similar step-level structures. When problems admit multiple combinatorially distinct but valid paths (common in GSM8K-style arithmetic), minority valid paths may receive low confidence, weakening both the error-correlation claim and the self-correction improvement.
- [Experimental results] Experimental results section: The abstract and main claims cite a 13.5% absolute improvement in correction success rate, yet the provided description supplies no error bars, dataset sizes, number of runs, or statistical tests. Without these, it is impossible to judge whether the gain is reliable or driven by a few outlier problems.
minor comments (2)
- [§3.1] Clarify the exact size of the correct-solution pool used to compute the consensus structures and whether it is held out from the test set.
- [Discussion] Add a limitations paragraph discussing failure modes when correct traces exhibit high structural diversity.
Simulated Author's Rebuttal
We thank the referee for the detailed and insightful comments on our manuscript. We have carefully considered each point and provide point-by-point responses below. Where appropriate, we have revised the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [§3] §3 (SCA formulation): The core IB objective defines high-confidence steps via alignment with consensus structures derived from a pool of correct traces. This construction is not a direct error detector; it presupposes that correct solutions share sufficiently similar step-level structures. When problems admit multiple combinatorially distinct but valid paths (common in GSM8K-style arithmetic), minority valid paths may receive low confidence, weakening both the error-correlation claim and the self-correction improvement.
Authors: We appreciate this observation. The SCA framework is indeed designed around the principle that correct reasoning traces exhibit structural consistency, which is a reasonable assumption for many reasoning tasks as supported by prior work on solution clustering. While it is true that some problems may have multiple valid paths, our empirical results demonstrate that low-confidence steps still correlate strongly with actual errors across the evaluated datasets, including GSM8K. To strengthen the manuscript, we have added a new subsection in §3 discussing the handling of solution diversity and included additional experiments on problems known to have multiple solution strategies, showing that the method remains effective. revision: yes
-
Referee: [Experimental results] Experimental results section: The abstract and main claims cite a 13.5% absolute improvement in correction success rate, yet the provided description supplies no error bars, dataset sizes, number of runs, or statistical tests. Without these, it is impossible to judge whether the gain is reliable or driven by a few outlier problems.
Authors: We agree that providing statistical details is essential for assessing the reliability of the reported improvements. In the revised manuscript, we have updated the experimental results section to include error bars computed over multiple runs, specified the dataset sizes and number of independent runs (5 runs per experiment), and added statistical significance tests (e.g., Wilcoxon signed-rank test) confirming that the improvements are statistically significant (p < 0.05). These additions ensure the claims are robustly supported. revision: yes
Circularity Check
No significant circularity; SCA derives step confidence from IB on traces with independent empirical validation
full rationale
The paper defines SCA via the Information Bottleneck principle applied to generated reasoning traces, with NIBS and GIBS as concrete implementations that measure consistency against consensus structures extracted from correct solutions. This construction uses ground-truth final answers only to curate the correct-solution pool for building the reference structure, then applies the resulting attribution to flag deviations in other traces. The central claims—that low-confidence steps correlate with actual reasoning errors and that step-level guidance improves self-correction by up to 13.5%—are supported by separate experiments on GSM8K and multi-hop QA rather than following tautologically from the definition. No equation or step reduces the reported performance gains to a renaming or refitting of the input data; the method remains falsifiable against external error annotations and correction outcomes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Steps that align with consensus structures across correct solutions are high-confidence and deviations indicate errors.
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
G-Eval: NLG Evaluation using Gpt-4 with Better Human Alignment , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
-
[3]
Nature Machine Intelligence , volume=
Factuality challenges in the era of large language models and opportunities for fact-checking , author=. Nature Machine Intelligence , volume=. 2024 , publisher=
work page 2024
-
[4]
Computational Linguistics , pages=
Llm-based nlg evaluation: Current status and challenges , author=. Computational Linguistics , pages=. 2025 , publisher=
work page 2025
-
[5]
Aligning large language models with human: A survey.arXiv preprint arXiv:2307.12966, 2023
Aligning large language models with human: A survey , author=. arXiv preprint arXiv:2307.12966 , year=
-
[6]
arXiv preprint arXiv:2405.20267 , year=
Auto-arena: Automating llm evaluations with agent peer battles and committee discussions , author=. arXiv preprint arXiv:2405.20267 , year=
-
[7]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[8]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [9]
-
[10]
IFIP International Conference on Artificial Intelligence Applications and Innovations , pages=
Enhancing answer reliability through inter-model consensus of large language models , author=. IFIP International Conference on Artificial Intelligence Applications and Innovations , pages=. 2025 , organization=
work page 2025
-
[11]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2406.13397 , year=
Morehopqa: More than multi-hop reasoning , author=. arXiv preprint arXiv:2406.13397 , year=
-
[13]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
FOLIO: Natural Language Reasoning with First-Order Logic , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[14]
arXiv preprint arXiv:2502.17026 , year=
Understanding the uncertainty of llm explanations: A perspective based on reasoning topology , author=. arXiv preprint arXiv:2502.17026 , year=
-
[15]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
work page 2019
-
[16]
Transactions on Machine Learning Research , year=
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models , author=. Transactions on Machine Learning Research , year=
-
[17]
The Eleventh International Conference on Learning Representations , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. The Eleventh International Conference on Learning Representations , year=
-
[18]
Proceedings of the AAAI conference on artificial intelligence , volume=
Graph of thoughts: Solving elaborate problems with large language models , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[19]
Uncertainty-Aware Step-wise Verification with Generative Reward Models , author=. ICLR Workshop: Quantify Uncertainty and Hallucination in Foundation Models: The Next Frontier in Reliable AI , year=
-
[20]
arXiv preprint arXiv:2508.12040 , year=
Mind the Generation Process: Fine-Grained Confidence Estimation During LLM Generation , author=. arXiv preprint arXiv:2508.12040 , year=
-
[21]
arXiv preprint arXiv:2412.06559 , year=
Processbench: Identifying process errors in mathematical reasoning , author=. arXiv preprint arXiv:2412.06559 , year=
-
[22]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Large Language Models are Better Reasoners with Self-Verification , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
work page 2023
-
[23]
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods
Llms-as-judges: a comprehensive survey on llm-based evaluation methods , author=. arXiv preprint arXiv:2412.05579 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
arXiv preprint arXiv:2507.22940 , year=
Trustworthy Reasoning: Evaluating and Enhancing Factual Accuracy in LLM Intermediate Thought Processes , author=. arXiv preprint arXiv:2507.22940 , year=
-
[25]
Advances in neural information processing systems , volume=
Gnnexplainer: Generating explanations for graph neural networks , author=. Advances in neural information processing systems , volume=
-
[26]
Advances in neural information processing systems , volume=
Predictive uncertainty estimation via prior networks , author=. Advances in neural information processing systems , volume=
-
[27]
international conference on machine learning , pages=
Dropout as a bayesian approximation: Representing model uncertainty in deep learning , author=. international conference on machine learning , pages=. 2016 , organization=
work page 2016
-
[28]
arXiv preprint arXiv:2406.01806 , year=
Contextualized sequence likelihood: Enhanced confidence scores for natural language generation , author=. arXiv preprint arXiv:2406.01806 , year=
-
[29]
MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
work page 2019
-
[30]
The Twelfth International Conference on Learning Representations , year=
Teaching Large Language Models to Self-Debug , author=. The Twelfth International Conference on Learning Representations , year=
-
[31]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[32]
Measuring Mathematical Problem Solving With the MATH Dataset , author=. NeurIPS , year=
-
[33]
arXiv preprint arXiv:2403.19094 , year=
Learning from correctness without prompting makes LLM efficient reasoner , author=. arXiv preprint arXiv:2403.19094 , year=
-
[34]
international conference on machine learning , pages=
Confidence-aware learning for deep neural networks , author=. international conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[35]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Selectively Answering Ambiguous Questions , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
-
[36]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[38]
arXiv preprint arXiv:2503.08679 , year=
Chain-of-thought reasoning in the wild is not always faithful , author=. arXiv preprint arXiv:2503.08679 , year=
-
[39]
arXiv preprint arXiv:2502.05078 , year=
Adaptive graph of thoughts: Test-time adaptive reasoning unifying chain, tree, and graph structures , author=. arXiv preprint arXiv:2502.05078 , year=
-
[40]
Interactive program synthesis , author=. arXiv preprint arXiv:1703.03539 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
arXiv preprint arXiv:2503.23617 , year=
Graph-Eq: Discovering Mathematical Equations using Graph Generative Models , author=. arXiv preprint arXiv:2503.23617 , year=
-
[42]
Limitations of the LLM-as-a-Judge Approach for Evaluating LLM Outputs in Expert Knowledge Tasks , author=. 2024 , eprint=
work page 2024
-
[43]
On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks , author=. 2024 , eprint=
work page 2024
-
[44]
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. 2023 , eprint=
work page 2023
-
[45]
arXiv preprint arXiv:2402.00559 , year=
A chain-of-thought is as strong as its weakest link: A benchmark for verifiers of reasoning chains , author=. arXiv preprint arXiv:2402.00559 , year=
-
[46]
Solving math word problems with process- and outcome-based feedback
Solving math word problems with process-and outcome-based feedback , author=. arXiv preprint arXiv:2211.14275 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
arXiv preprint arXiv:2408.15240 , year=
Generative verifiers: Reward modeling as next-token prediction , author=. arXiv preprint arXiv:2408.15240 , year=
-
[48]
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Math-shepherd: Verify and reinforce llms step-by-step without human annotations , author=. arXiv preprint arXiv:2312.08935 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Rewarding progress: Scaling automated process verifiers for llm reasoning , author=. arXiv preprint arXiv:2410.08146 , year=
-
[50]
arXiv preprint arXiv:2308.09267 , year=
Graphreason: Enhancing reasoning capabilities of large language models through a graph-based verification approach , author=. arXiv preprint arXiv:2308.09267 , year=
-
[51]
arXiv preprint arXiv:2506.12509 , year=
Graph of Verification: Structured Verification of LLM Reasoning with Directed Acyclic Graphs , author=. arXiv preprint arXiv:2506.12509 , year=
-
[52]
arXiv preprint arXiv:2311.08516 , year=
LLMs cannot find reasoning errors, but can correct them given the error location , author=. arXiv preprint arXiv:2311.08516 , year=
-
[53]
Deep Variational Information Bottleneck
Deep variational information bottleneck , author=. arXiv preprint arXiv:1612.00410 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Proceedings of the 26th International Joint Conference on Artificial Intelligence , pages=
A partitioning algorithm for maximum common subgraph problems , author=. Proceedings of the 26th International Joint Conference on Artificial Intelligence , pages=
-
[56]
Advances in neural information processing systems , volume=
Selective classification for deep neural networks , author=. Advances in neural information processing systems , volume=
-
[57]
Proceedings of the 23rd international conference on Machine learning , pages=
The relationship between Precision-Recall and ROC curves , author=. Proceedings of the 23rd international conference on Machine learning , pages=
-
[58]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Phi-4-reasoning Technical Report
Phi-4-reasoning technical report , author=. arXiv preprint arXiv:2504.21318 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [60]
-
[61]
The Twelfth International Conference on Learning Representations , year=
Let's verify step by step , author=. The Twelfth International Conference on Learning Representations , year=
-
[62]
International Conference on Learning Representations , year =
DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION , author=. International Conference on Learning Representations , year =
-
[63]
The Eleventh International Conference on Learning Representations , year =
ROSCOE: A Suite of Metrics for Scoring Step-by-Step Reasoning , author=. The Eleventh International Conference on Learning Representations , year =
-
[64]
Forty-second International Conference on Machine Learning , year =
Premise-Augmented Reasoning Chains Improve Error Identification in Math reasoning with LLMs , author=. Forty-second International Conference on Machine Learning , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.