Afford-VLA: Action-Aligned Visual Planning via Internalized Affordance
Pith reviewed 2026-06-30 15:33 UTC · model grok-4.3
The pith
Afford-VLA internalizes affordance as an action-aligned visual planning interface inside VLA models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
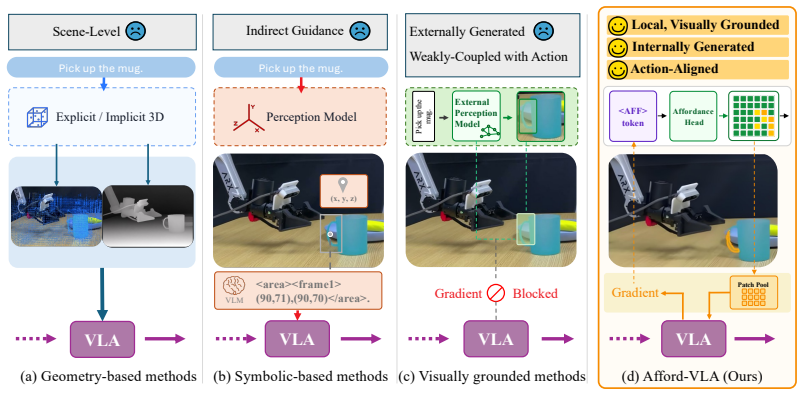
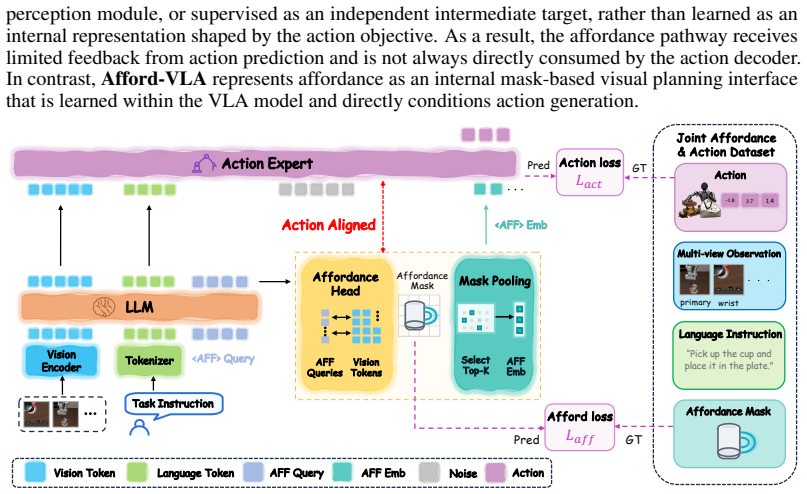
Afford-VLA shows that task-conditioned affordance can serve as an explicit visual planning interface when it is generated inside the VLA itself: learnable <AFF> tokens query task-relevant interaction regions, affordance masks are decoded directly from multimodal features, and the resulting compact embeddings are fed forward to condition action generation, creating a tightly coupled pathway that is jointly optimized with downstream control.
What carries the argument
learnable <AFF> tokens that query task-relevant regions, decode affordance masks from internal multimodal features, and convert those masks into embeddings that directly condition action generation
If this is right
- Affordance planning becomes local and generated from the same features used for action rather than from global geometry or external modules.
- The perception-action pathway can be optimized end-to-end without separate affordance labels at inference time.
- The same internal generation mechanism supports both simulation benchmarks and real-world deployment without additional signals.
- Joint training of affordance and action improves the quality of the visual planning signal for control.
Where Pith is reading between the lines
- The approach could extend to other intermediate representations such as object-centric or temporal plans if they are also generated internally from the same features.
- Removing reliance on external visual planners may simplify deployment on resource-limited robots by reducing the number of separate modules.
- If the masks produced by the tokens align with human-annotated interaction points on new tasks, it would support the claim that the signal is genuinely task-conditioned rather than generic.
- The method might generalize beyond manipulation to navigation or assembly if the same token-based querying is applied to different action spaces.
Load-bearing premise
The assumption that the <AFF> tokens will reliably locate task-relevant regions and produce masks whose embeddings improve action prediction even without any external supervision or post-processing.
What would settle it
A controlled ablation that removes the <AFF> pathway and its joint optimization while keeping all other model components identical; if performance on LIBERO and real-robot tasks stays the same or improves, the central claim does not hold.
Figures



read the original abstract
Vision-language-action (VLA) models have shown strong potential for generalist robot manipulation, yet they remain limited by insufficient spatial reasoning, particularly in determining where to interact in complex visual scenes. While recent efforts introduce various forms of visual planning to address this issue, existing approaches either rely on global geometric cues, symbolic intermediate representations, or externally generated visual signals, which are often weakly coupled with downstream action prediction. In this work, we revisit visual planning in VLA systems and argue that effective planning should be local, visually grounded, internally generated, and directly aligned with action. Based on this insight, we propose Afford-VLA, a unified framework that internalizes task-conditioned affordance as an explicit visual planning interface within VLA models. Concretely, we introduce learnable <AFF> tokens to query task-relevant interaction regions, decode affordance masks from multimodal features, and convert them into compact embeddings that directly condition action generation. This design enables affordance to be both generated and utilized within the VLA, forming a tightly coupled perception-action pathway. To further support this integration, we adopt a training strategy that allows the affordance pathway to be jointly optimized with action prediction, improving its effectiveness for downstream control. We evaluate our method on multiple simulation benchmarks, including LIBERO, LIBERO-Plus, and SimplerEnv, achieving consistent state-of-the-art performance, along with strong real-world results. These findings demonstrate that internalizing affordance as action-aligned visual planning provides a powerful paradigm for improving VLA systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Afford-VLA, a unified framework for vision-language-action (VLA) models that internalizes task-conditioned affordance as an explicit visual planning interface. It introduces learnable <AFF> tokens to query task-relevant interaction regions, decode affordance masks from multimodal features, and convert them into embeddings that condition action generation. The affordance pathway is jointly optimized with action prediction. The method is claimed to achieve consistent state-of-the-art performance on simulation benchmarks including LIBERO, LIBERO-Plus, and SimplerEnv, as well as strong real-world results, demonstrating the value of internalizing affordance for improving VLA systems.
Significance. If the empirical claims hold, this work offers a new paradigm for visual planning in VLA systems by making it local, visually grounded, internally generated, and directly aligned with action prediction. This could address limitations in spatial reasoning for robot manipulation without relying on external geometric cues or post-hoc signals. The approach of using learnable tokens for affordance internalization is a potentially impactful contribution to generalist robot policies.
major comments (2)
- [Abstract] Abstract: The abstract asserts 'consistent state-of-the-art performance' on multiple benchmarks (LIBERO, LIBERO-Plus, SimplerEnv) but supplies no quantitative results, ablation details, baseline comparisons, or error analysis. This absence is load-bearing for the central claim that internalizing affordance via <AFF> tokens improves downstream action prediction.
- [Abstract] Abstract (training strategy paragraph): The description states that the affordance pathway is 'jointly optimized with action prediction' but provides no indication of an auxiliary loss, mask supervision, or isolation mechanism. Without such a signal, it remains unclear whether the <AFF> token embeddings causally enforce task-relevant, action-aligned affordances or simply correlate via added capacity, undermining the 'tightly coupled perception-action pathway' claim.
minor comments (1)
- [Abstract] Abstract: The benchmark 'LIBERO-Plus' is referenced without definition or citation to prior work defining the variant.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts 'consistent state-of-the-art performance' on multiple benchmarks (LIBERO, LIBERO-Plus, SimplerEnv) but supplies no quantitative results, ablation details, baseline comparisons, or error analysis. This absence is load-bearing for the central claim that internalizing affordance via <AFF> tokens improves downstream action prediction.
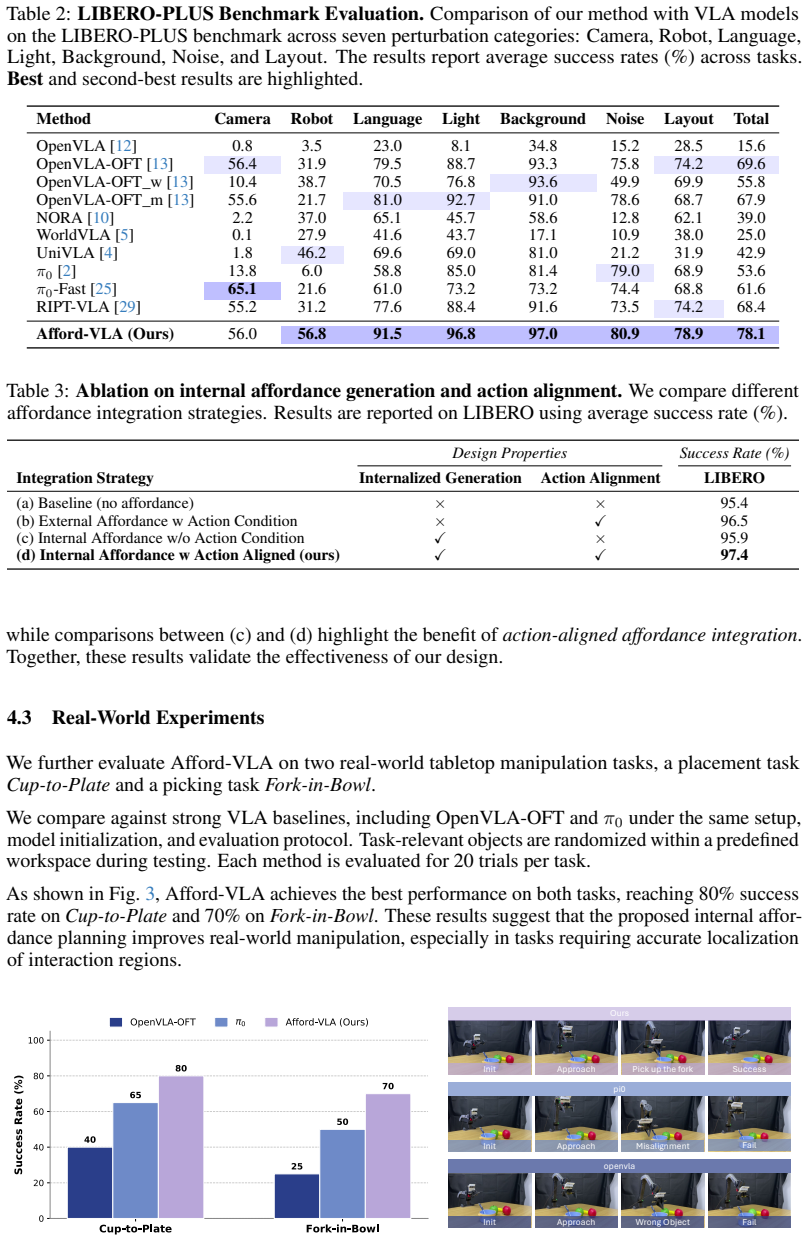
Authors: We agree that the abstract, being a high-level summary, omits specific metrics. The full manuscript reports quantitative results, including success rates, baseline comparisons, and ablations in Sections 4.1–4.3 and Tables 1–3, which support the SOTA claims on LIBERO, LIBERO-Plus, and SimplerEnv. To make the central claim more self-contained, we will revise the abstract to include key performance highlights (e.g., average success rate improvements) while preserving its brevity. revision: yes
-
Referee: [Abstract] Abstract (training strategy paragraph): The description states that the affordance pathway is 'jointly optimized with action prediction' but provides no indication of an auxiliary loss, mask supervision, or isolation mechanism. Without such a signal, it remains unclear whether the <AFF> token embeddings causally enforce task-relevant, action-aligned affordances or simply correlate via added capacity, undermining the 'tightly coupled perception-action pathway' claim.
Authors: The manuscript details the joint optimization in Section 3.3, where the affordance decoder and action head share the multimodal transformer backbone, with <AFF> embeddings directly concatenated into the action prediction pathway and optimized end-to-end via the primary action loss. No separate auxiliary mask loss is used; supervision flows implicitly through action prediction gradients. We acknowledge that the abstract paragraph is terse on this mechanism. We will expand the abstract and add a clarifying sentence in Section 3.3 to explicitly describe the absence of auxiliary losses and the direct conditioning path, thereby reinforcing the causal alignment argument. revision: yes
Circularity Check
No circularity: new architectural design with independent empirical claims
full rationale
The paper proposes Afford-VLA as a new framework introducing learnable <AFF> tokens that query regions, decode masks from internal features, and produce embeddings to condition action generation, with joint optimization of the affordance pathway and action prediction. No equations, fitted parameters, or derivations are shown that reduce a claimed result to its own inputs by construction. Claims rest on the described design choices and performance on external benchmarks (LIBERO, SimplerEnv), without self-citation load-bearing steps or renaming of known results. The derivation chain is self-contained.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
LA4VLA: Learning to Act without Seeing via Language-Action Pretraining
LA4VLA pretrains on language-action pairs from decomposed demonstrations to create reusable action priors, yielding up to 45 percentage point gains in real-world VLA success rates when mixed with standard training.
-
LA4VLA: Learning to Act without Seeing via Language-Action Pretraining
LA4VLA creates a 33K language-action dataset from existing demos and shows that pretraining on language-action pairs before or alongside vision-language-action training boosts success rates in sim and real robot tasks.
Reference graph
Works this paper leans on
-
[1]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[7]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision-language- action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Chongkai Gao, Zixuan Liu, Zhenghao Chi, Junshan Huang, Xin Fei, Yiwen Hou, Yuxuan Zhang, Yudi Lin, Zhirui Fang, Zeyu Jiang, et al. Vla-os: Structuring and dissecting planning repre- sentations and paradigms in vision-language-action models.arXiv preprint arXiv:2506.17561, 2025
-
[9]
Roboground: Robotic manipulation with grounded vision- language priors
Haifeng Huang, Xinyi Chen, Yilun Chen, Hao Li, Xiaoshen Han, Zehan Wang, Tai Wang, Jiangmiao Pang, and Zhou Zhao. Roboground: Robotic manipulation with grounded vision- language priors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22540–22550, 2025
2025
-
[10]
NORA: A Small Open-Sourced Generalist Vision Language Action Model for Embodied Tasks
Chia-Yu Hung, Qi Sun, Pengfei Hong, Amir Zadeh, Chuan Li, U Tan, Navonil Majumder, Soujanya Poria, et al. Nora: A small open-sourced generalist vision language action model for embodied tasks.arXiv preprint arXiv:2504.19854, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5:a vision-language- action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Pointvla: Injecting the 3d world into vision-language-action models.IEEE Robotics and Automation Letters, 11(3): 2506–2513, 2026
Chengmeng Li, Junjie Wen, Yaxin Peng, Yan Peng, and Yichen Zhu. Pointvla: Injecting the 3d world into vision-language-action models.IEEE Robotics and Automation Letters, 11(3): 2506–2513, 2026
2026
-
[15]
Coa-vla: Improving vision-language-action models via visual-text chain-of-affordance
Jinming Li, Yichen Zhu, Zhibin Tang, Junjie Wen, Minjie Zhu, Xiaoyu Liu, Chengmeng Li, Ran Cheng, Yaxin Peng, Yan Peng, et al. Coa-vla: Improving vision-language-action models via visual-text chain-of-affordance. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9759–9769, 2025
2025
-
[16]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Evaluating Real-World Robot Manipulation Policies in Simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Sp-vla: A joint model scheduling and token pruning approach for vla model acceleration
Ye Li, Yuan Meng, Zewen Sun, Kangye Ji, Chen Tang, Jiajun Fan, Xinzhu Ma, Shutao Xia, Zhi Wang, and Wenwu Zhu. Sp-vla: A joint model scheduling and token pruning approach for vla model acceleration.arXiv preprint arXiv:2506.12723, 2025
-
[19]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[20]
Fangchen Liu, Kuan Fang, Pieter Abbeel, and Sergey Levine. Moka: Open-world robotic manipulation through mark-based visual prompting.arXiv preprint arXiv:2403.03174, 2024
-
[21]
Towards generalist robot policies: What matters in building vision-language-action models
Huaping Liu, Xinghang Li, Peiyan Li, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Tao Kong, and Hanbo Zhang. Towards generalist robot policies: What matters in building vision-language-action models. 2025
2025
-
[22]
Teli Ma, Jia Zheng, Zifan Wang, Ziyao Gao, Jiaming Zhou, and Junwei Liang. Glover++: Unleashing the potential of affordance learning from human behaviors for robotic manipulation. arXiv preprint arXiv:2505.11865, 2025
-
[23]
Rt-affordance: Affordances are versatile intermediate representations for robot manipulation
Soroush Nasiriany, Sean Kirmani, Tianli Ding, Laura Smith, Yuke Zhu, Danny Driess, Dorsa Sadigh, and Ted Xiao. Rt-affordance: Affordances are versatile intermediate representations for robot manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8249–8257. IEEE, 2025
2025
-
[24]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[25]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Yichao Shen, Fangyun Wei, Zhiying Du, Yaobo Liang, Yan Lu, Jiaolong Yang, Nanning Zheng, and Baining Guo. Videovla: Video generators can be generalizable robot manipulators.arXiv preprint arXiv:2512.06963, 2025
-
[28]
Kite: Keypoint- conditioned policies for semantic manipulation.arXiv preprint arXiv:2306.16605, 2023
Priya Sundaresan, Suneel Belkhale, Dorsa Sadigh, and Jeannette Bohg. Kite: Keypoint- conditioned policies for semantic manipulation.arXiv preprint arXiv:2306.16605, 2023
-
[29]
Interactive Post-Training for Vision-Language-Action Models
Shuhan Tan, Kairan Dou, Yue Zhao, and Philipp Krähenbühl. Interactive post-training for vision-language-action models.arXiv preprint arXiv:2505.17016, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
OFlow: Injecting Object-Aware Temporal Flow Matching for Robust Robotic Manipulation
Kuanning Wang, Ke Fan, Chenhao Qiu, Zeyu Shangguan, Yuqian Fu, Yanwei Fu, Daniel Seita, and Xiangyang Xue. Oflow: Injecting object-aware temporal flow matching for robust robotic manipulation.arXiv preprint arXiv:2604.17876, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Afforddp: Generalizable diffusion policy with transferable affordance
Shijie Wu, Yihang Zhu, Yunao Huang, Kaizhen Zhu, Jiayuan Gu, Jingyi Yu, Ye Shi, and Jingya Wang. Afforddp: Generalizable diffusion policy with transferable affordance. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6971–6980, 2025
2025
-
[33]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Magma: A foundation model for multimodal ai agents
Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, et al. Magma: A foundation model for multimodal ai agents. InProceedings of the computer vision and pattern recognition conference, pages 14203–14214, 2025
2025
-
[35]
Tianyuan Yuan, Yicheng Liu, Chenhao Lu, Zhuoguang Chen, Tao Jiang, and Hang Zhao. Depthvla: Enhancing vision-language-action models with depth-aware spatial reasoning.arXiv preprint arXiv:2510.13375, 2025
-
[36]
Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Arsalan Mousavian, and Dieter Fox. Robopoint: A vision-language model for spatial affordance prediction for robotics.arXiv preprint arXiv:2406.10721, 2024
-
[37]
Transporter networks: Rearranging the visual world for robotic manipulation
Andy Zeng, Pete Florence, Jonathan Tompson, Stefan Welker, Jonathan Chien, Maria Attarian, Travis Armstrong, Ivan Krasin, Dan Duong, Vikas Sindhwani, et al. Transporter networks: Rearranging the visual world for robotic manipulation. InConference on Robot Learning, pages 726–747. PMLR, 2021
2021
-
[38]
Jiahui Zhang, Yurui Chen, Yueming Xu, Ze Huang, Yanpeng Zhou, Yu-Jie Yuan, Xinyue Cai, Guowei Huang, Xingyue Quan, Hang Xu, et al. 4d-vla: Spatiotemporal vision-language-action pretraining with cross-scene calibration.arXiv preprint arXiv:2506.22242, 2025
-
[39]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[40]
TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies.arXiv preprint arXiv:2412.10345, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[42]
Yanwen Zou, Zhaoye Zhou, Chenyang Shi, Zewei Ye, Junda Huang, Yan Ding, and Bo Zhao. U-arm: Ultra low-cost general teleoperation interface for robot manipulation.arXiv preprint arXiv:2509.02437, 2025. A Details of LIBERO-Plus Benchmark LIBERO-Plus is designed to evaluate whether vision-language-action policies remain reliable when the evaluation environme...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.