Understanding the Impact of Geometric Foundation Models on Vision-Language-Action Models
Pith reviewed 2026-06-30 13:38 UTC · model grok-4.3
The pith
Current VLAs lack measurable geometric understanding that can be quantified via linear probing and bridged through specific injection architectures from GFMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that VLAs exhibit a quantifiable geometric gap relative to GFMs, that three distinct injection architectures produce different performance effects when geometry is added to a VLA, and that non-architectural factors including training data, camera number, and reconstruction quality also influence the success of the resulting geometric VLAs.
What carries the argument
Linear probing of VLA features to measure the geometric gap, together with three injection architectures that differ in the stage and manner of geometry feature addition from the GFM.
If this is right
- Linear probing can now be used to quantify the geometric gap between any VLA and GFM pair.
- Architecture choice for geometry injection is not interchangeable and produces measurable differences in final VLA performance.
- Increasing training data, camera count, or reconstruction quality each provides an independent lever for improving geometric VLAs.
Where Pith is reading between the lines
- The same probing method could be applied to future VLAs to decide whether geometry injection is still needed.
- Results may generalize to other 3D-aware robotics benchmarks that rely on spatial consistency.
- Designers could prioritize reconstruction quality over camera count when compute is limited, based on the relative effect sizes reported.
Load-bearing premise
That linear probing performed on GR00T-N1.5 and VGGT supplies a representative measure of geometric understanding that extends to other VLAs, GFMs, and downstream tasks.
What would settle it
A replication that applies the same linear probing protocol to additional VLAs and GFMs and finds either no consistent gap or that all three injection architectures yield statistically identical performance would undermine the central claims.
Figures
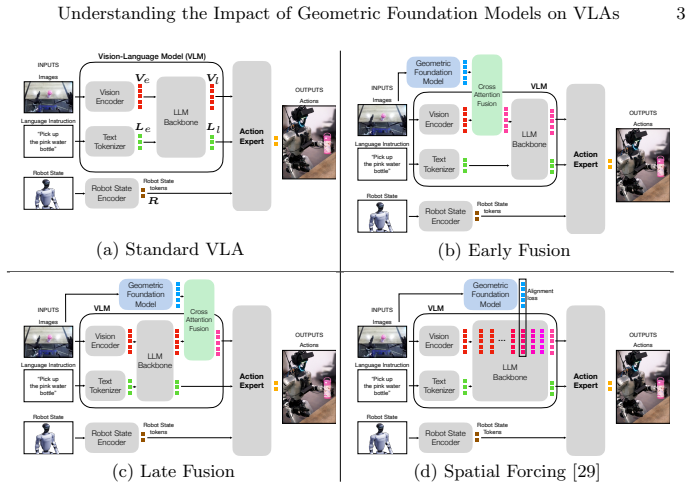
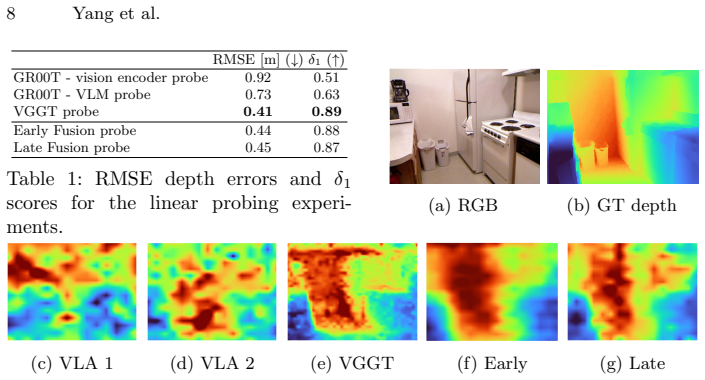
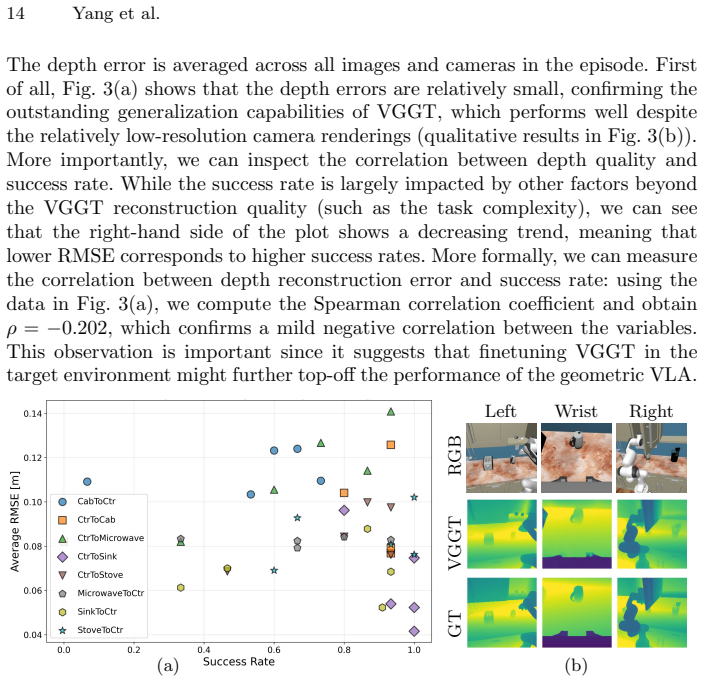
read the original abstract
Recent work explores new opportunities at the intersection of vision-language-action models (VLAs) and geometric foundation models (GFMs) for 3D reconstruction, such as VGGT. While the resulting geometric VLAs often show improved performance, it remains unclear (i) if modern VLAs already have sufficient geometric understanding to start with, (ii) what is the best architecture to inject geometric understanding into a VLA, and (iii) what is the effect of other design choices that affect geometric VLAs. In this paper we provide a rigorous experimental analysis to shed light on these questions, for a specific choice of VLA (GR00T-N1.5) and GFM (VGGT). Our first contribution is to formalize prior work's intuition that current VLAs lack geometric understanding, by providing a rigorous analysis based on linear probing. The analysis quantifies, for the first time, the "geometric gap" between VLAs and GFMs. Our second contribution is to identify and compare different strategies to bridge GFMs with VLAs. We implement three different architectures, which differ in the way they inject geometry in the VLA, while keeping low-level implementation details as similar as possible, to ensure a fair comparison. Finally, we analyze the impact of non-architectural choices (e.g., training data, number of cameras, reconstruction quality) on the performance of the geometric VLAs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current VLAs lack sufficient geometric understanding, formalized via linear probing that quantifies a 'geometric gap' between a VLA (GR00T-N1.5) and a GFM (VGGT). It compares three architectures for injecting geometry from GFMs into VLAs under controlled conditions and ablates the effects of training data, camera count, and reconstruction quality on downstream performance.
Significance. If the results hold, the work supplies the first quantitative linear-probing measure of the geometric gap and a controlled comparison of injection strategies, which could guide future geometric VLA design. The emphasis on keeping low-level implementation details similar across architectures is a methodological strength that supports fair comparisons.
major comments (1)
- [Abstract, §3] Abstract and §3 (Linear Probing Analysis): The central claim that 'current VLAs lack geometric understanding' rests on linear probing performed exclusively with GR00T-N1.5 and VGGT. No other VLAs (e.g., OpenVLA or RT-X variants) are probed, and no argument is supplied that GR00T-N1.5's feature geometry is representative of the broader class. This single-model scope directly limits whether the reported 'geometric gap' generalizes, making the headline claim load-bearing on an untested assumption.
minor comments (2)
- [§4] §4 (Architecture Variants): A diagram or table explicitly listing the feature-injection points and parameter counts for the three architectures would improve clarity of the controlled comparison.
- [Figures] Figure captions throughout: Several figures lack explicit mention of the exact layers or tokens used for linear probing, which would aid reproducibility of the gap quantification.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the concern regarding the scope of the linear probing analysis below, noting that the manuscript already frames the study around a specific VLA and GFM while providing a controlled comparison of injection strategies.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Linear Probing Analysis): The central claim that 'current VLAs lack geometric understanding' rests on linear probing performed exclusively with GR00T-N1.5 and VGGT. No other VLAs (e.g., OpenVLA or RT-X variants) are probed, and no argument is supplied that GR00T-N1.5's feature geometry is representative of the broader class. This single-model scope directly limits whether the reported 'geometric gap' generalizes, making the headline claim load-bearing on an untested assumption.
Authors: We thank the referee for highlighting this scope limitation. The manuscript is explicit from the abstract onward that the linear probing, architectural comparisons, and ablations are performed for the specific VLA GR00T-N1.5 and GFM VGGT. GR00T-N1.5 is a recent high-capacity transformer-based VLA, and the linear probing protocol is designed to be model-agnostic so that the quantified gap serves as a case study. However, we agree that no explicit argument for representativeness is supplied. In the revised manuscript we will (i) add a short discussion in §3 on shared architectural traits (vision-language backbone, tokenization) with other VLAs such as OpenVLA, and (ii) qualify the abstract claim to refer to “modern VLAs such as GR00T-N1.5.” We view this as a partial revision because we do not introduce new probing experiments on additional VLAs, which would require substantial additional compute outside the current controlled setting. revision: partial
Circularity Check
No circularity: purely experimental comparisons with no derivations or fitted predictions
full rationale
The paper conducts linear probing to quantify a geometric gap, compares three injection architectures, and runs ablations on data/camera/reconstruction factors. All steps are empirical measurements on GR00T-N1.5 + VGGT; no equations, no parameter fitting presented as prediction, and no self-citation chains invoked to justify uniqueness or ansatzes. The central claim rests on experimental outcomes rather than any reduction to inputs by construction. Generalization concerns (one VLA/GFM pair) affect external validity but do not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.14117 (2025)
Abouzeid, A., Mansour, M., Sun, Z., Song, D.: GeoAware-VLA: Implicit geometry aware vision-language-action model. arXiv preprint arXiv:2509.14117 (2025)
-
[2]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., Finn, C., Fu, C., Gopalakrishnan, K., Hausman, K., et al.: Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Bjorck, J., Blukis, V., Casta˜ neda, F., Cherniadev, N., Da, X., Ding, R., Fan, L.J., Fang, Y., Fox, D., et al.: GR00T-N1.5: An improved open foundation model for gen- eralist humanoid robots.https://research.nvidia.com/labs/gear/gr00t-n1_ 5/(2025)
2025
-
[4]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Casta˜ neda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y., Fox, D., Hu, F., Huang, S., et al.: GR00T-N1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al.:π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
In: Robotics: Science and Systems (RSS) (2025)
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π 0: A Vision-Language-Action flow model for general robot control. In: Robotics: Science and Systems (RSS) (2025)
2025
-
[7]
RT-1: Robotics Transformer for Real-World Control at Scale
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakr- ishnan, K., Hausman, K., Herzog, A., Hsu, J., et al.: Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Cai, W., Ponomarenko, I., Yuan, J., Li, X., Yang, W., Dong, H., Zhao, B.: Spa- tialbot: Precise spatial understanding with vision language models. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 9490–9498. IEEE (2025)
2025
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
Chen, B., Xu, Z., Kirmani, S., Ichter, B., Sadigh, D., Guibas, L., Xia, F.: Spa- tialVLM: Endowing vision-language models with spatial reasoning capabilities. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR). pp. 14455–14465 (June 2024)
2024
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, S., Garcia, R., Laptev, I., Schmid, C.: Sugar: Pre-training 3d visual repre- sentations for robotics. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18049–18060 (2024)
2024
-
[11]
In: Robotics: Science and Systems (RSS) (2023)
Chi, C., Feng, S., Du, Y., Xu, Z., Cousineau, E., Burchfiel, B., Song, S.: Diffusion policy: Visuomotor policy learning via action diffusion. In: Robotics: Science and Systems (RSS) (2023)
2023
-
[12]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
In: Proceedings of the 40th International Conference on Machine Learning
Driess, D., Xia, F., Sajjadi, M.S., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al.: PaLM-E: an embodied multimodal language model. In: Proceedings of the 40th International Conference on Machine Learning. pp. 8469–8488 (2023)
2023
-
[14]
arXiv preprint arXiv:2507.16290 (2025)
Fang, X., Gao, J., Wang, Z., Chen, Z., Ren, X., Lyu, J., Ren, Q., Yang, Z., Yang, X., Yan, Y., Lyu, C.: Dens3R: A foundation model for 3d geometry prediction. arXiv preprint arXiv:2507.16290 (2025)
-
[15]
Figure AI: Helix: A vision-language-action model for generalist humanoid control (February 20 2025),https://www.figure.ai/news/helix, accessed: 2026-01-21 Understanding the Impact of Geometric Foundation Models on VLAs 17
2025
-
[16]
arXiv preprint arXiv:2509.18778 (2025)
Ge, S., Zhang, Y., Xie, S., Zhang, W., Zhou, M., Wang, Z.: VGGT-DP: Generaliz- able robot control via vision foundation models. arXiv preprint arXiv:2509.18778 (2025)
-
[17]
arXiv preprint arXiv:2406.08545 (2024)
Goyal, A., Blukis, V., Xu, J., Guo, Y., Chao, Y.W., Fox, D.: RVT-2: Learning precise manipulation from few demonstrations. arXiv preprint arXiv:2406.08545 (2024)
-
[18]
arXiv preprint arXiv:2410.15549 (2024)
Han, B., Kim, J., Jang, J.: A dual process VLA: Efficient robotic manipulation leveraging VLM. arXiv preprint arXiv:2410.15549 (2024)
-
[19]
In: International Conference on Learning Representations (2022)
Hu, E.J., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: LoRA: Low-rank adaptation of large language models. In: International Conference on Learning Representations (2022)
2022
-
[20]
In: IEEE Conf
Hu, W., Lin, J., Long, Y., Ran, Y., Jiang, L., Wang, Y., Zhu, C., Xu, R., Wang, T., Pang, J.: G 2VLM: Geometry grounded vision language model with unified 3d reconstruction and spatial reasoning. In: IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (2026)
2026
-
[21]
arXiv preprint arXiv:2511.19971 (2025)
Hu, Y., Cheng, C., Yu, S., Guo, X., Wang, H.: VGGT4D: Mining motion cues in visual geometry transformers for 4d scene reconstruction. arXiv preprint arXiv:2511.19971 (2025)
-
[22]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Hu, Y., Guo, Y., Wang, P., Chen, X., Wang, Y.J., Zhang, J., Sreenath, K., Lu, C., Chen, J.: Video prediction policy: A generalist robot policy with predictive visual representations. arXiv preprint arXiv:2412.14803 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
arXiv preprint arXiv:2411.18623 (2024)
Jia, Y., Liu, J., Chen, S., Gu, C., Wang, Z., Luo, L., Lee, L., Wang, P., Wang, Z., Zhang, R., et al.: Lift3d foundation policy: Lifting 2d large-scale pre-trained models for robust 3d robotic manipulation. arXiv preprint arXiv:2411.18623 (2024)
-
[24]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Keetha, N., M¨ uller, N., Sch¨ onberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., Luiten, J., Lopez-Antequera, M., Rota Bul` o, S., Richardt, C., Ramanan, D., Scherer, S., Kontschieder, P.: Mapanything: Universal feed-forward metric 3d reconstruction. arXiv preprint arXiv:2509.13414 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., Vuong, Q., Kollar, T., Burchfiel, B., Tedrake, R., Sadigh, D., Levine, S., Liang, P., Finn, C.: OpenVLA: An open- source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Contrastive Representation Regularization for Vision-Language-Action Models
Kim, T., Lee, J., Koo, M., Kim, D., Lee, K., Kim, C., Seo, Y., Shin, J.: Contrastive representation regularization for vision-language-action models. arXiv preprint arXiv:2510.01711 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
In: European Conf
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with MASt3R. In: European Conf. on Computer Vision (ECCV). vol. 15130, pp. 71–91 (2024)
2024
-
[28]
Li, C., Wen, J., Peng, Y., Peng, Y., Feng, F., Zhu, Y.: Pointvla: Injecting the 3d world into vision-language-action models. arXiv preprint arXiv:2503.07511 (2025)
-
[29]
arXiv preprint arXiv:2510.12276 (2025)
Li, F., Song, W., Zhao, H., Wang, J., Ding, P., Wang, D., Zeng, L., Li, H.: Spatial forcing: Implicit spatial representation alignment for vision-language-action model. arXiv preprint arXiv:2510.12276 (2025)
-
[30]
arXiv preprint arXiv:2507.00416 (2025)
Lin, T., Li, G., Zhong, Y., Zou, Y., Du, Y., Liu, J., Gu, E., Zhao, B.: Evo-0: Vision-language-action model with implicit spatial understanding. arXiv preprint arXiv:2507.00416 (2025)
-
[31]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., Stone, P.: Libero: Benchmark- ing knowledge transfer for lifelong robot learning. arXiv preprint arXiv:2306.03310 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Psychometrika12(2), 153–157 (1947) 18 Yang et al
McNemar, Q.: Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika12(2), 153–157 (1947) 18 Yang et al
1947
-
[33]
In: Robotics: Science and Systems (RSS) (2024)
Nasiriany, S., Maddukuri, A., Zhang, L., Parikh, A., Lo, A., Joshi, A., Mandlekar, A., Zhu, Y.: Robocasa: Large-scale simulation of everyday tasks for generalist robots. In: Robotics: Science and Systems (RSS) (2024)
2024
-
[34]
arXiv preprint arXiv:2510.15530 (2025)
Ni, Z., He, Y., Qian, L., Mao, J., Fu, F., Sui, W., Su, H., Peng, J., Wang, Z., He, B.: Vo-dp: Semantic-geometric adaptive diffusion policy for vision-only robotic manipulation. arXiv preprint arXiv:2510.15530 (2025)
-
[35]
arXiv preprint arXiv:2511.10560 (2025)
Peng, H., Li, H., Dai, Y., Lan, Y., Luo, Y., Qi, T., Zhang, Z., Zhan, Y., Zhang, J., Xu, W., Liu, Z.: Omnivggt: Omni-modality driven visual geometry grounded transformer. arXiv preprint arXiv:2511.10560 (2025)
-
[36]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Pertsch, K., Stachowicz, K., Ichter, B., Driess, D., Nair, S., Vuong, Q., Mees, O., Finn, C., Levine, S.: Fast: Efficient action tokenization for vision-language-action models. arXiv preprint arXiv:2501.09747 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Physical Intelligence: Physical intelligence (π) (2026),https://www.pi.website/, accessed: 2026-01-21
2026
-
[38]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Qu, D., Song, H., Chen, Q., Yao, Y., Ye, X., Ding, Y., Wang, Z., Gu, J., Zhao, B., Wang, D., et al.: SpatialVLA: Exploring spatial representations for visual- language-action model. arXiv preprint arXiv:2501.15830 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
arXiv preprint arXiv:2508.16433 (2025)
Rojas, S., Armando, M., Ghamen, B., Weinzaepfel, P., Leroy, V., Rogez, G.: HAMSt3R: Human-aware multi-view stereo 3d reconstruction. arXiv preprint arXiv:2508.16433 (2025)
-
[40]
Snyder, D., Hancock, A.J., Badithela, A., Dixon, E., Miller, P., Ambrus, R.A., Majumdar, A., Itkina, M., Nishimura, H.: Is your imitation learning policy better than mine? policy comparison with near-optimal stopping (2025),https://arxiv. org/abs/2503.10966
-
[41]
arXiv preprint arXiv:2509.20297 (2025)
Steiner, R., Millane, A., Tingdahl, D., Volk, C., Ramasamy, V., Yao, X., Du, P., Pouya, S., Sheng, S.: mindmap: Spatial memory in deep feature maps for 3d action policies. arXiv preprint arXiv:2509.20297 (2025)
-
[42]
Tesla, Inc.: Ai & robotics (2026),https://www.tesla.com/en_eu/AI, accessed: 2026-01-21
2026
-
[43]
TRI LBM Team, Barreiros, J., Beaulieu, A., Bhat, A., Cory, R., Cousineau, E., Dai, H., Fang, C.H., Hashimoto, K., Irshad, M.Z., Itkina, M., Kuppuswamy, N., Lee, K.H., Liu, K., McConachie, D., McMahon, I., Nishimura, H., Phillips-Grafflin, C., Richter, C., Shah, P., Srinivasan, K., Wulfe, B., Xu, C., Zhang, M., Alspach, A., Angeles, M., Arora, K., Guizilin...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
AMB3R: accurate feed-forward metric-scale 3D reconstruction with backend
Wang, H., Agapito, L.: AMB3R: Accurate feed-forward metric-scale 3d reconstruc- tion with backend. arXiv preprint arXiv:2511.20343 (2025)
-
[45]
arXiv preprint arXiv:2503.11651 (2025)
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novony, D.: VGGT: Visual geometry grounded transformer. arXiv preprint arXiv:2503.11651 (2025)
-
[46]
In: IEEE Conf
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: DUSt3R: Geometric 3d vision made easy. In: IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). pp. 20697–20709 (2024) Understanding the Impact of Geometric Foundation Models on VLAs 19
2024
-
[47]
In: IEEE International Conference on Robotics and Automation (ICRA) (2019)
Wofk, D., Ma, F., Yang, T.J., Karaman, S., Sze, V.: FastDepth: Fast Monocular Depth Estimation on Embedded Systems. In: IEEE International Conference on Robotics and Automation (ICRA) (2019)
2019
-
[48]
In: Advances in Neural Information Processing Systems (NeurIPS) (2025)
Wu, D., Liu, F., Hung, Y.H., Duan, Y.: Spatial-MLLM: Boosting MLLM capa- bilities in visual-based spatial intelligence. In: Advances in Neural Information Processing Systems (NeurIPS) (2025)
2025
-
[49]
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. arXiv: 2406.09414 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Ze, Y., Zhang, G., Zhang, K., Hu, C., Wang, M., Xu, H.: 3d diffusion policy: Gen- eralizable visuomotor policy learning via simple 3d representations. arXiv preprint arXiv:2403.03954 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
arXiv preprint arXiv:2510.17439 (2025)
Zhang, Z., Li, H., Dai, Y., Zhu, Z., Zhou, L., Liu, C., Wang, D., Tay, F.E.H., Chen, S., Liu, Z., Liu, Y., Li, X., Zhou, P.: From spatial to actions: Ground- ing vision-language-action model in spatial foundation priors. arXiv preprint arXiv:2510.17439 (2025)
-
[52]
3D-VLA: A 3D Vision-Language-Action Generative World Model
Zhen, H., Qiu, X., Chen, P., Yang, J., Yan, X., Du, Y., Hong, Y., Gan, C.: 3D-VLA: A 3d vision-language-action generative world model. arXiv preprint arXiv:2403.09631 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
In: Advances in Neural Information Processing Systems (NeurIPS) (2025)
Zheng, D., Huang, S., Li, Y., Wang, L.: Learning from videos for 3D world: Enhanc- ing MLLMs with 3D vision geometry priors. In: Advances in Neural Information Processing Systems (NeurIPS) (2025)
2025
-
[54]
arXiv preprint arXiv:2409.18125 (2024)
Zhu, C., Wang, T., Zhang, W., Pang, J., Liu, X.: LLaVA-3d: A simple yet effective pathway to empowering lmms with 3d capabilities. arXiv preprint arXiv:2409.18125 (2024)
-
[55]
Zust, L., Cabon, Y., Marrie, J., Antsfeld, L., Chidlovskii, B., Revaud, J., Csurka, G.: PanSt3R: Multi-view consistent panoptic segmentation. arXiv preprint arXiv:2506.21348 (2025) 20 Yang et al. A Appendix: Details about Architectures This appendix complements the discussion in Section 3, where we introduced the Early and Late Fusion models, and discusse...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.