Dual-Pathway Geometry-Aware MLLM for Spatial Intelligence
Pith reviewed 2026-06-29 22:59 UTC · model grok-4.3
The pith
GAMSI internalizes both 3D structure and metric scale from RGB images alone by separating query pathways and using training-time alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
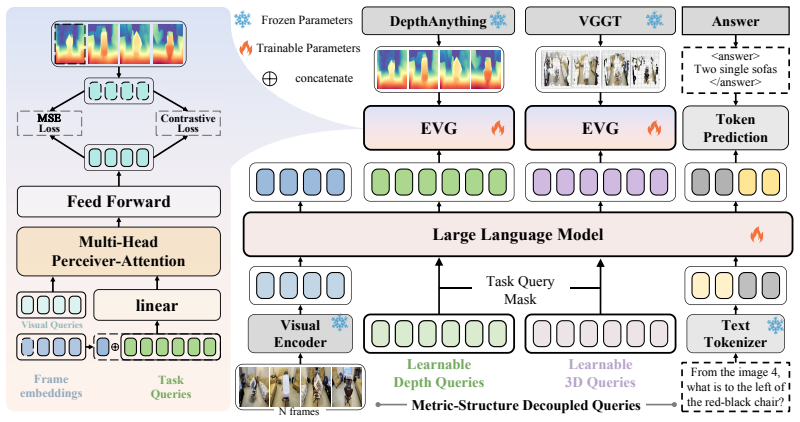
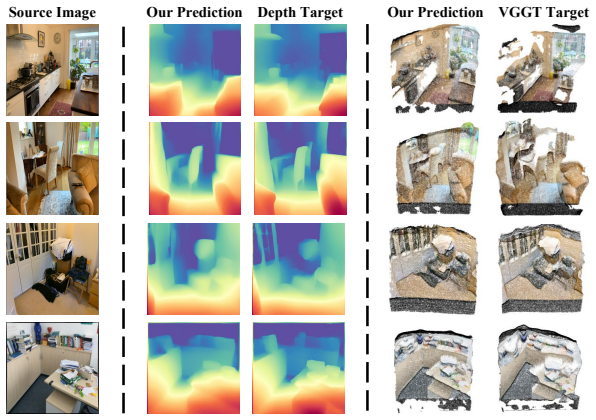
GAMSI is a dual-pathway Geometry-Aware MLLM that takes only RGB images as input while internalizing both holistic 3D structural perception and fine-grained metric scale estimation within a unified autoregressive backbone, achieved through Metric-Structure Decoupled Queries that employ two groups of learnable queries to extract dense metric signals and sparse structural cues separately under a task-decoupled attention mask, followed by an Expert-Guided Visual Grounding module that projects the cues back to visual features and aligns them with vision foundation models used solely as training-time supervision.
What carries the argument
Metric-Structure Decoupled Queries, two groups of learnable queries that extract dense metric signals and sparse structural cues from shared RGB context while a task-decoupled attention mask prevents cross-contamination.
If this is right
- The model performs spatial tasks at inference without ingesting depth maps or point clouds.
- Computational overhead drops because vision foundation models are used only for training supervision.
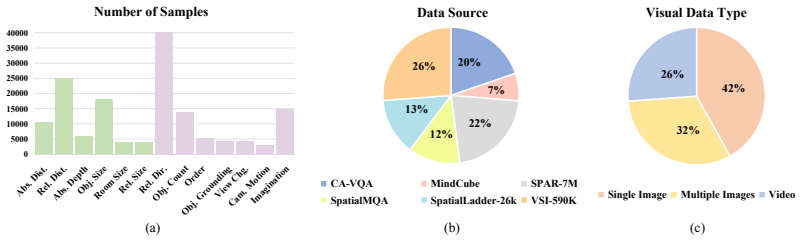
- A consolidated multi-task dataset of 152,776 samples across 13 task types supports instruction tuning for spatial capabilities.
- Two-stage curriculum training enables the model to reach state-of-the-art results on seven spatial intelligence benchmarks.
Where Pith is reading between the lines
- The same decoupling pattern could be applied to separate additional visual properties beyond metric and structure.
- Training-time supervision from foundation models might be swapped for other sources of geometric signal without changing the inference architecture.
- Adding further decoupled query groups could allow the backbone to internalize still more distinct forms of scene understanding.
Load-bearing premise
The two groups of learnable queries can extract and keep separate dense metric signals and sparse structural cues from the same RGB features without one pathway contaminating the other, and that alignment to external vision models only at training time is enough for the model to retain both forms of geometric knowledge.
What would settle it
An ablation that removes the task-decoupled attention mask or the Expert-Guided Visual Grounding module and then measures whether performance on the seven spatial intelligence benchmarks falls to the level of single-pathway baselines.
Figures


read the original abstract
Spatial understanding of the physical world from 2D visual inputs hinges on two complementary forms of geometric knowledge: holistic 3D structural perception and fine-grained metric scale estimation. Existing multimodal large language models (MLLMs) typically address only one facet, ingesting either depth maps or point clouds as additional model inputs, which incurs substantial computational overhead and inherits the generalization limitations of upstream prediction models. We propose GAMSI, a dual-pathway Geometry-Aware MLLM for Spatial Intelligence that takes only RGB images as input while internalizing both forms of geometric prior within a unified autoregressive backbone. Specifically, we introduce Metric-Structure Decoupled Queries (MSDQ) which employ two groups of learnable queries to respectively extract dense metric signals and sparse structural cues from the shared visual context, with a task-decoupled attention mask further preventing the two pathways from contaminating each other. Building on this, an Expert-Guided Visual Grounding (EVG) module projects the aggregated cues back to frame-level visual features and aligns them with vision foundation models, which serve purely as training-time supervision, rather than as model inputs. We further build a multi-task spatial instruction-tuning dataset (MTS) comprising 152{,}776 samples spanning 13 task types and three visual modalities, consolidated from six public datasets. Trained with a two-stage curriculum, GAMSI achieves state-of-the-art performance on seven spatial intelligence benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GAMSI, a dual-pathway Geometry-Aware MLLM for spatial intelligence that ingests only RGB images. It introduces Metric-Structure Decoupled Queries (MSDQ) using two groups of learnable queries with a task-decoupled attention mask to separately extract dense metric signals and sparse structural cues, plus an Expert-Guided Visual Grounding (EVG) module that aligns aggregated cues to vision foundation models solely at training time. A consolidated multi-task spatial instruction-tuning dataset (MTS) of 152,776 samples across 13 tasks is introduced, and a two-stage curriculum yields state-of-the-art results on seven spatial intelligence benchmarks.
Significance. If the empirical results hold, the work would be significant for enabling MLLMs to internalize complementary geometric priors (holistic 3D structure and metric scale) directly from RGB without incurring the overhead or generalization limits of depth/point-cloud inputs at inference. The training-only use of external vision-model supervision and the consolidated public-data MTS dataset are positive features that keep the central claim independent of self-referential fitting.
minor comments (2)
- The abstract states that the task-decoupled attention mask 'further preventing the two pathways from contaminating each other,' but does not quantify how effectively the separation is maintained (e.g., via cross-pathway attention statistics or ablation removing the mask). Adding such analysis would strengthen the central architectural claim without altering scope.
- The MTS dataset is described as 'consolidated from six public datasets'; a table listing the source datasets, task-type breakdown, and train/val/test splits would improve reproducibility and allow readers to assess coverage of the 13 task types.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the work's significance, and recommendation for minor revision. The referee's description of GAMSI, MSDQ, EVG, and the MTS dataset is accurate.
Circularity Check
No significant circularity
full rationale
The paper presents an architectural proposal (MSDQ with task-decoupled queries and mask, plus EVG supervision used only at training time) and reports empirical SOTA results after two-stage training on a consolidated public dataset (MTS). No equations, uniqueness theorems, or derivations are described that reduce by construction to fitted inputs, self-citations, or renamed known results. The central performance claim rests on external benchmark evaluation rather than any self-referential step, making the work self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
2025
-
[2]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Spatialladder: Progressive training for spatial reasoning in vision-language models.arXiv preprint arXiv:2510.08531, 2025
-
[4]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
2024
-
[5]
Maniplvm-r1: Reinforcement learning for reasoning in embodied manipulation with large vision-language models
Zirui Song, Guangxian Ouyang, Mingzhe Li, Yuheng Ji, Chenxi Wang, Zixiang Xu, Zeyu Zhang, Xiaoqing Zhang, Qian Jiang, Fengxian Ji, et al. Maniplvm-r1: Reinforcement learning for reasoning in embodied manipulation with large vision-language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18558–18566, 2026
2026
-
[6]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
A comprehensive review on autonomous navigation.ACM Computing Surveys, 57(9):1–67, 2025
Saeid Nahavandi, Roohallah Alizadehsani, Darius Nahavandi, Shady Mohamed, Navid Mohajer, Mohammad Rokonuzzaman, and Ibrahim Hossain. A comprehensive review on autonomous navigation.ACM Computing Surveys, 57(9):1–67, 2025
2025
-
[8]
Virtualnexus: Enhancing 360-degree video ar/vr collaboration with environment cutouts and virtual replicas
Xincheng Huang, Michael Yin, Ziyi Xia, and Robert Xiao. Virtualnexus: Enhancing 360-degree video ar/vr collaboration with environment cutouts and virtual replicas. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology, pages 1–12, 2024
2024
-
[9]
Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
Rui Yang, Ziyu Zhu, Yanwei Li, Jingjia Huang, Shen Yan, Siyuan Zhou, Zhe Liu, Xiangtai Li, Shuangye Li, Wenqian Wang, et al. Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
-
[10]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
2024
-
[11]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: En- hancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
2022
-
[13]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Spatialbot: Precise spatial understanding with vision language models
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9490–9498. IEEE, 2025. 10
2025
-
[16]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024
2024
-
[17]
Depth anything v2.Advances in Neural Information Processing Systems, 37:21875– 21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.Advances in Neural Information Processing Systems, 37:21875– 21911, 2024
2024
-
[18]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[19]
Yang Liu, Ming Ma, Xiaomin Yu, Pengxiang Ding, Han Zhao, Mingyang Sun, Siteng Huang, and Donglin Wang. Ssr: Enhancing depth perception in vision-language models via rationale- guided spatial reasoning.arXiv preprint arXiv:2505.12448, 2025
-
[20]
Mm-spatial: Exploring 3d spatial understanding in multimodal llms
Erik Daxberger, Nina Wenzel, David Griffiths, Haiming Gang, Justin Lazarow, Gefen Kohavi, Kai Kang, Marcin Eichner, Yinfei Yang, Afshin Dehghan, et al. Mm-spatial: Exploring 3d spatial understanding in multimodal llms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7395–7408, 2025
2025
-
[21]
3d-llm: Injecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494, 2023
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Injecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494, 2023
2023
-
[22]
Scaling spatial intelligence with multimodal foundation models.arXiv preprint arXiv:2511.13719, 2025
Zhongang Cai, Ruisi Wang, Chenyang Gu, Fanyi Pu, Junxiang Xu, Yubo Wang, Wanqi Yin, Zhitao Yang, Chen Wei, Qingping Sun, et al. Scaling spatial intelligence with multimodal foundation models.arXiv preprint arXiv:2511.13719, 2025
-
[23]
Spatial mental modeling from limited views
Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, et al. Spatial mental modeling from limited views. InStructural Priors for Vision Workshop at ICCV’25, 2025
2025
-
[24]
Jiahui Zhang, Yurui Chen, Yanpeng Zhou, Yueming Xu, Ze Huang, Jilin Mei, Junhui Chen, Yu- Jie Yuan, Xinyue Cai, Guowei Huang, et al. From flatland to space: Teaching vision-language models to perceive and reason in 3d.arXiv preprint arXiv:2503.22976, 2025
-
[25]
Jingping Liu, Ziyan Liu, Zhedong Cen, Yan Zhou, Yinan Zou, Weiyan Zhang, Haiyun Jiang, and Tong Ruan. Can multimodal large language models understand spatial relations? InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 620–632, 2025
2025
-
[26]
Cambrian-s: Towards spatial supersensing in video
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis L Brown II, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, et al. Cambrian-s: Towards spatial supersensing in video. InThe Fourteenth International Conference on Learning Representations, 2025
2025
-
[27]
Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai C Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024
2024
-
[28]
Mllms need 3d-aware representation supervision for scene understanding.arXiv e-prints, pages arXiv–2506, 2025
Xiaohu Huang, Jingjing Wu, Qunyi Xie, and Kai Han. Mllms need 3d-aware representation supervision for scene understanding.arXiv e-prints, pages arXiv–2506, 2025
2025
-
[29]
Zhangquan Chen, Manyuan Zhang, Xinlei Yu, Xufang Luo, Mingze Sun, Zihao Pan, Xiang An, Yan Feng, Peng Pei, Xunliang Cai, et al. Think with 3d: Geometric imagination grounded spatial reasoning from limited views.arXiv preprint arXiv:2510.18632, 2025
-
[30]
Yunnan Wang, Fan Lu, Kecheng Zheng, Ziyuan Huang, Ziqiang Li, Wenjun Zeng, and Xin Jin. Vision-centric activation and coordination for multimodal large language models.arXiv preprint arXiv:2510.14349, 2025. 11
-
[31]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[32]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR, 2021
2021
-
[33]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
2021
-
[34]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
2023
-
[36]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias Müller. Zoedepth: Zero-shot transfer by combining relative and metric depth.arXiv preprint arXiv:2302.12288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. InEuropean conference on computer vision, pages 71–91. Springer, 2024
2024
-
[39]
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. Perceiver io: A general architecture for structured inputs & outputs.arXiv preprint arXiv:2107.14795, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[40]
Zimmermann, and Wieland Brendel
Evgenia Rusak, Patrik Reizinger, Attila Juhos, Oliver Bringmann, Roland S Zimmermann, and Wieland Brendel. Infonce: Identifying the gap between theory and practice.arXiv preprint arXiv:2407.00143, 2024
-
[41]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. Spacer: Reinforcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing
Junfei Wu, Jian Guan, Kaituo Feng, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, and Tieniu Tan. Reinforcing spatial reasoning in vision-language models with interwoven thinking and visual drawing.arXiv preprint arXiv:2506.09965, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Holistic evaluation of multimodal llms on spatial intelligence.arXiv preprint arXiv:2508.13142, 2025
Zhongang Cai, Yubo Wang, Qingping Sun, Ruisi Wang, Chenyang Gu, Wanqi Yin, Zhiqian Lin, Zhitao Yang, Chen Wei, Oscar Qian, et al. Holistic evaluation of multimodal llms on spatial intelligence.arXiv preprint arXiv:2508.13142, 2025
-
[45]
Dingming Li, Hongxing Li, Zixuan Wang, Yuchen Yan, Hang Zhang, Siqi Chen, Guiyang Hou, Shengpei Jiang, Wenqi Zhang, Yongliang Shen, et al. Viewspatial-bench: Evaluating multi- perspective spatial localization in vision-language models.arXiv preprint arXiv:2505.21500, 2025. 12 Table 3: Statistics of the MTS Dataset by task type. The dataset contains 152,77...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.