Does Seeing More Mean Knowing More? Mono-Anchored Advantage Normalization for Multi-Source Visual Reasoning
Pith reviewed 2026-06-29 22:51 UTC · model grok-4.3
The pith
Treating mono-source rewards as dynamic anchors in advantage normalization lets multi-source visual reasoning distinguish information gain from interference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
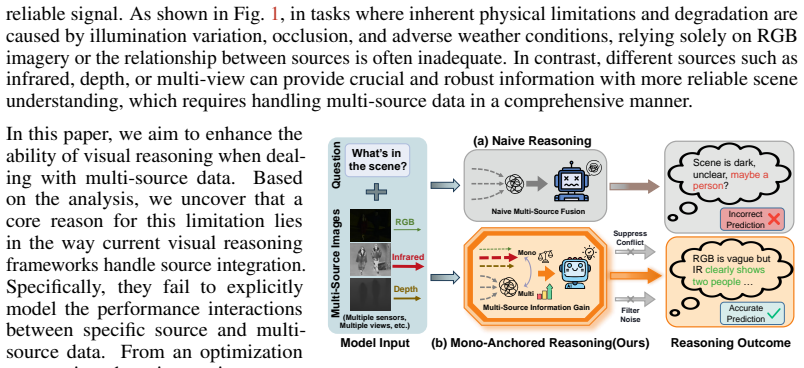
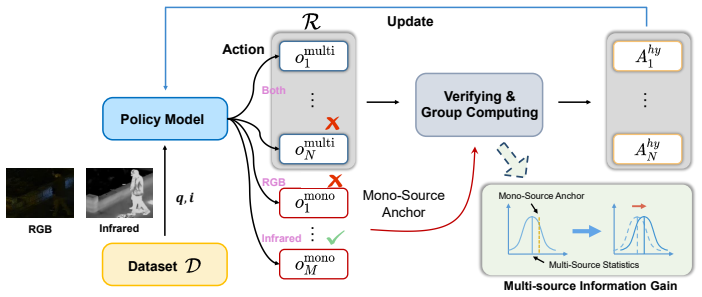
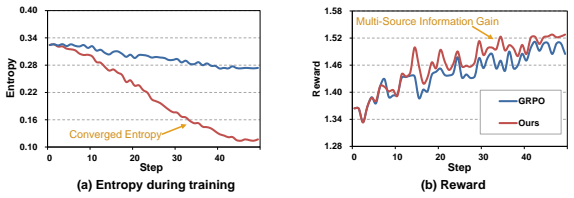
By treating mono-source rewards as dynamic anchors, MARS explicitly incorporates the information gain introduced by multi-source fusion into advantage normalization and adaptively emphasizes mutual promotion between sources while suppressing potential noise or conflicts during RLVR. From theoretical analysis, the method effectively quantifies information gain introduced by multi-source integration in gradient estimation, enabling consistent modality regulation.
What carries the argument
Mono-anchored advantage normalization, which uses rewards from single-modality reasoning as dynamic reference points to scale advantages when multiple visual sources are fused.
If this is right
- Gradient estimation now includes an explicit term for information gain from multi-source fusion.
- Modality regulation becomes consistent because anchors adapt during training.
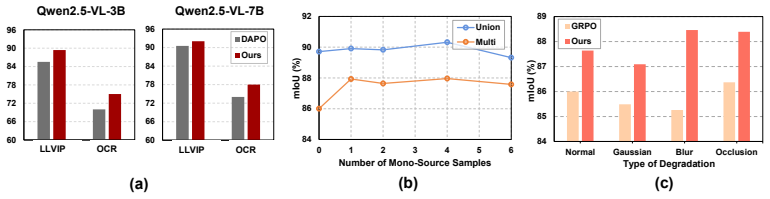
- Performance improves by 3.2 percent on GRPO and 4.9 percent on DAPO across tested datasets.
- The framework distinguishes cases where adding a source yields net gain versus net interference.
Where Pith is reading between the lines
- The anchoring technique could be tested on reinforcement-learning problems that combine non-visual sensors.
- It may reduce reliance on hand-tuned fusion weights in other multi-input training pipelines.
- Applying the same anchor logic to three or more sources at once would test scalability of the gain quantification.
Load-bearing premise
Mono-source rewards supply unbiased dynamic anchors that correctly separate information gain from interference even when the sources differ substantially in physical properties and semantics.
What would settle it
A controlled test on a dataset with highly dissimilar sources where the anchored method produces no gain or lower accuracy than the strongest single source alone.
Figures

read the original abstract
Visual reasoning through reinforcement learning with verifiable rewards (RLVR) has achieved remarkable progress. However, when dealing with multi-source inputs, existing approaches tend to treat them as a mere accumulation of information, lacking explicit mechanisms to distinguish whether integrating additional sources yields information gain or introduces interference. Therefore, they struggle to effectively model dynamic interaction when integrating multiple sources, particularly when they differ significantly in physical properties and semantics, e.g., infrared and depth, leading to inferior performance to mono-source reasoning when a certain source holds the dominant signal. To address this issue, we propose MARS, a novel mono-anchored multi-source reasoning framework that models each visual modality as an independent information source. Specifically, by treating mono-source rewards as dynamic anchors, our method explicitly incorporates the information gain introduced by multi-source fusion into advantage normalization and adaptively emphasizes mutual promotion between sources while suppressing potential noise or conflicts during RLVR. From theoretical analysis, our method effectively quantifies information gain introduced by multi-source integration in gradient estimation, enabling consistent modality regulation. Empirical results also show impressive 3.2% and 4.9% performance gains on GRPO and DAPO across diverse datasets, confirming effectiveness of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MARS, a mono-anchored multi-source reasoning framework for visual reasoning via RLVR. It models each modality as an independent source, uses mono-source rewards as dynamic anchors to incorporate information gain from multi-source fusion into advantage normalization, and claims this enables consistent modality regulation by quantifying gain versus interference. The manuscript asserts a theoretical analysis of information gain in gradient estimation and reports empirical gains of 3.2% on GRPO and 4.9% on DAPO across datasets.
Significance. If the theoretical quantification of information gain proves non-circular and the empirical gains hold under proper controls, the approach could provide a useful mechanism for regulating multi-modal inputs with differing physical and semantic properties in RLVR, addressing limitations in methods that treat sources as simple accumulation.
major comments (2)
- [Abstract] Abstract: The manuscript asserts a 'theoretical analysis' that 'quantifies information gain introduced by multi-source integration in gradient estimation', yet provides no equations, derivation steps, or proof sketch. This prevents evaluation of whether the quantification is independent of the normalization definition or reduces to it by construction, which is load-bearing for the central claim of explicit gain/interference separation.
- [Abstract] Abstract: The claim that mono-source rewards serve as 'unbiased, dynamic anchors' that correctly separate gain from interference is presented without analysis or controls for cases where sources differ substantially in physical properties and semantics; this assumption underpins the advantage normalization step but lacks supporting derivation or ablation.
Simulated Author's Rebuttal
We thank the referee for their comments on the abstract claims. We address each major point below, clarifying where the supporting material appears in the manuscript and noting any planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts a 'theoretical analysis' that 'quantifies information gain introduced by multi-source integration in gradient estimation', yet provides no equations, derivation steps, or proof sketch. This prevents evaluation of whether the quantification is independent of the normalization definition or reduces to it by construction, which is load-bearing for the central claim of explicit gain/interference separation.
Authors: The full derivation appears in Section 3.2, starting from the policy gradient and expressing the information gain as the expected difference in advantage between the multi-source policy and the mono-source baseline; the mono-anchor term is subtracted explicitly, making the gain term independent by construction rather than tautological. A concise proof sketch can be added to the abstract or a new appendix paragraph. revision: partial
-
Referee: [Abstract] Abstract: The claim that mono-source rewards serve as 'unbiased, dynamic anchors' that correctly separate gain from interference is presented without analysis or controls for cases where sources differ substantially in physical properties and semantics; this assumption underpins the advantage normalization step but lacks supporting derivation or ablation.
Authors: Section 4.3 and the supplementary material contain ablations across modality pairs with large physical and semantic gaps (RGB-infrared, RGB-depth). The unbiasedness argument is given in Section 3.1: each mono-source reward is computed from an independent policy rollout that never observes the other sources, functioning as a control variate whose expectation matches the single-source baseline. revision: no
Circularity Check
No significant circularity identified
full rationale
The provided abstract and context describe a mono-anchored advantage normalization method that treats mono-source rewards as dynamic anchors to model information gain versus interference in multi-source RLVR. The central claim of a theoretical analysis quantifying information gain in gradient estimation is presented as enabling consistent modality regulation, with separate empirical gains reported. No equations, derivations, or self-citations are visible in the given text that would reduce the quantification to a definitional fit, a renamed input, or a self-citation chain. The derivation chain therefore appears self-contained against external benchmarks, with no load-bearing step exhibiting the required reduction by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mono-source rewards serve as unbiased dynamic anchors that correctly measure information gain versus interference when sources are fused.
Reference graph
Works this paper leans on
-
[1]
Muhammad Adeel Azam, Khan Bahadar Khan, Sana Salahuddin, Eid Rehman, Sajid Ali Khan, Muhammad Attique Khan, Seifedine Kadry, and Amir H Gandomi. A review on multimodal medical image fusion: Compendious analysis of medical modalities, multimodal databases, fusion techniques and quality metrics.Computers in biology and medicine, 144:105253, 2022
2022
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Sule Bai, Mingxing Li, Yong Liu, Jing Tang, Haoji Zhang, Lei Sun, Xiangxiang Chu, and Yansong Tang. Univg-r1: Reasoning guided universal visual grounding with reinforcement learning.arXiv preprint arXiv:2505.14231, 2025
-
[5]
Visual question answering on image sets
Ankan Bansal, Yuting Zhang, and Rama Chellappa. Visual question answering on image sets. InEuropean Conference on Computer Vision, pages 51–67. Springer, 2020
2020
-
[6]
Rgb-d and thermal sensor fusion: A systematic literature review.IEEE Access, 11:82410–82442, 2023
Martin Brenner, Napoleon H Reyes, Teo Susnjak, and Andre LC Barczak. Rgb-d and thermal sensor fusion: A systematic literature review.IEEE Access, 11:82410–82442, 2023
2023
-
[7]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
2020
-
[8]
Spatialbot: Precise spatial understanding with vision language models
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9490–9498. IEEE, 2025
2025
-
[9]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024
2024
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Llvip: A visible-infrared paired dataset for low-light vision
Xinyu Jia, Chuang Zhu, Minzhen Li, Wenqi Tang, and Wenli Zhou. Llvip: A visible-infrared paired dataset for low-light vision. InProceedings of the IEEE/CVF international conference on computer vision, pages 3496–3504, 2021
2021
-
[12]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Imagination Helps Visual Reasoning, But Not Yet in Latent Space
You Li, Chi Chen, Yanghao Li, Fanhu Zeng, Kaiyu Huang, Jinan Xu, and Maosong Sun. Imagination helps visual reasoning, but not yet in latent space.arXiv preprint arXiv:2602.22766, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
You Li, Heyu Huang, Chi Chen, Kaiyu Huang, Chao Huang, Zonghao Guo, Zhiyuan Liu, Jinan Xu, Yuhua Li, Ruixuan Li, et al. Migician: Revealing the magic of free-form multi-image grounding in multimodal large language models.arXiv preprint arXiv:2501.05767, 2025
-
[16]
Yuqi Liu, Tianyuan Qu, Zhisheng Zhong, Bohao Peng, Shu Liu, Bei Yu, and Jiaya Jia. Vision- reasoner: Unified visual perception and reasoning via reinforcement learning.arXiv preprint arXiv:2505.12081, 2025
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[19]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[21]
Llava-cot: Let vision language models reason step-by-step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2087–2098, 2025
2087
-
[22]
Learning to Reason under Off-Policy Guidance
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance.arXiv preprint arXiv:2504.14945, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, et al. R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization.arXiv preprint arXiv:2503.10615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Youngjoon Yu, Sangyun Chung, Byung-Kwan Lee, and Yong Man Ro. Spark: Multi-vision sensor perception and reasoning benchmark for large-scale vision-language models.arXiv preprint arXiv:2408.12114, 2024
-
[26]
Improving rgb- infrared object detection with cascade alignment-guided transformer.Information Fusion, 105:102246, 2024
Maoxun Yuan, Xiaorong Shi, Nan Wang, Yinyan Wang, and Xingxing Wei. Improving rgb- infrared object detection with cascade alignment-guided transformer.Information Fusion, 105:102246, 2024
2024
-
[27]
Runzhe Zhan, Yafu Li, Zhi Wang, Xiaoye Qu, Dongrui Liu, Jing Shao, Derek F Wong, and Yu Cheng. Exgrpo: Learning to reason from experience.arXiv preprint arXiv:2510.02245, 2025
-
[28]
Multi-source remote sensing data fusion: status and trends.International journal of image and data fusion, 1(1):5–24, 2010
Jixian Zhang. Multi-source remote sensing data fusion: status and trends.International journal of image and data fusion, 1(1):5–24, 2010
2010
-
[29]
Multi-source heterogeneous data fusion
Lili Zhang, Yuxiang Xie, Luan Xidao, and Xin Zhang. Multi-source heterogeneous data fusion. In2018 International conference on artificial intelligence and big data (ICAIBD), pages 47–51. IEEE, 2018
2018
-
[30]
Yi-Fan Zhang, Xingyu Lu, Xiao Hu, Chaoyou Fu, Bin Wen, Tianke Zhang, Changyi Liu, Kaiyu Jiang, Kaibing Chen, Kaiyu Tang, et al. R1-reward: Training multimodal reward model through stable reinforcement learning.arXiv preprint arXiv:2505.02835, 2025
-
[31]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.