ProSR: Process-Shaped Spatial Reasoning for Reliable Chain-of-Thought in VLMs
Pith reviewed 2026-06-29 22:20 UTC · model grok-4.3
The pith
Adding process penalties for visual grounding and trajectory stability makes spatial reasoning in vision-language models more reliable and accurate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
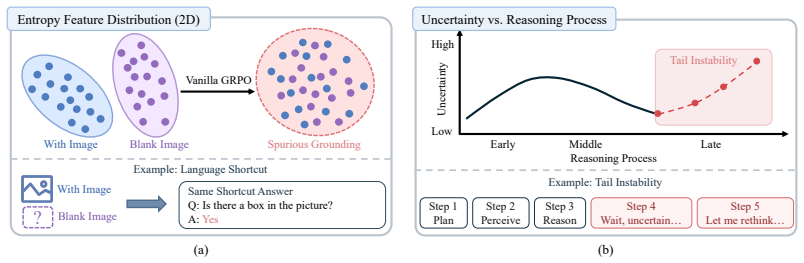
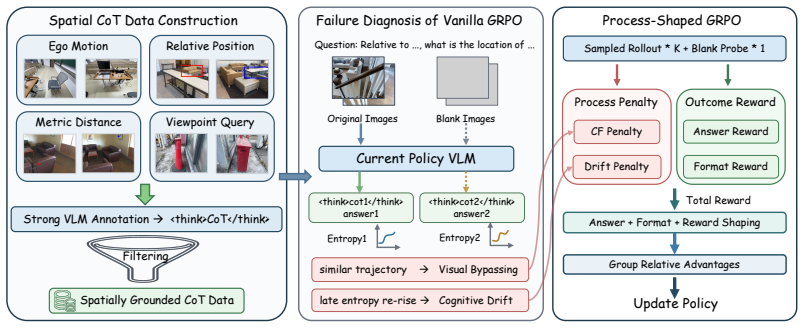
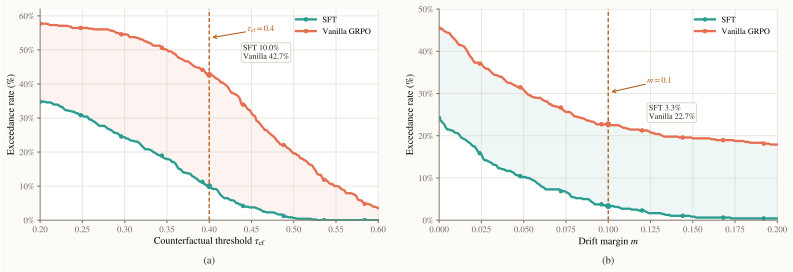
By diagnosing Spurious Grounding and Tail Instability as key degradation modes in reinforcement learning for chain-of-thought, the authors show that a Counterfactual Invariance Penalty and a Tail Drift Penalty can extend the objective to enforce visual dependence and trajectory stability, resulting in higher answer accuracy and more reliable reasoning trajectories on complex and out-of-distribution spatial reasoning benchmarks.
What carries the argument
The ProSR framework, which uses a Counterfactual Invariance Penalty to enforce visual dependence and a Tail Drift Penalty to enforce trajectory stability during process-shaped optimization.
If this is right
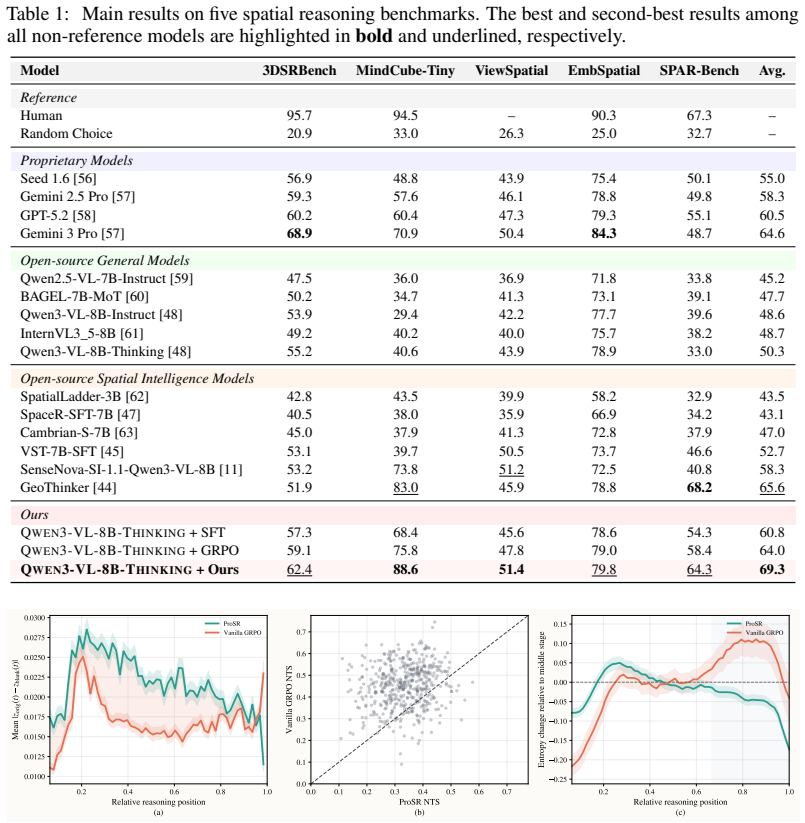
- Answer accuracy increases on multiple complex spatial reasoning benchmarks.
- Generated reasoning trajectories become more stable.
- Reasoning becomes more dependent on visual evidence rather than spurious patterns.
- The optimization objective now includes process-level dimensions beyond single answer correctness.
Where Pith is reading between the lines
- Similar process penalties could be tested on other reasoning domains like temporal or causal reasoning in VLMs.
- If the penalties generalize, they might reduce the need for large outcome-aligned datasets in training.
- The diagnosis of degradation modes might apply to non-spatial tasks where visual or evidence grounding is required.
Load-bearing premise
The two degradation modes are the primary causes of unreliable spatial reasoning and can be reliably mitigated by the proposed penalties without side effects on other capabilities.
What would settle it
Running the ProSR training and finding that the generated reasoning traces still show high rates of spurious grounding or tail instability, or that accuracy does not improve on the benchmarks.
Figures

read the original abstract
Reliable spatial reasoning remains a core bottleneck for vision-language models (VLMs). Existing mainstream training paradigms for spatial reasoning largely rely on outcome alignment or process imitation, lacking explicit constraints on the reasoning process, and therefore struggle to ensure genuine visual dependence and stable reasoning trajectories. In this paper, we construct a high-quality CoT dataset covering diverse spatial phenomena and diagnose the model's reasoning process, revealing two typical types of process degradation during reinforcement learning optimization: Spurious Grounding, which bypasses visual evidence, and Tail Instability, where uncertainty abnormally rises in the later stage of reasoning. To address these issues, we propose ProSR, a process-shaping optimization framework for spatial reasoning. Through a Counterfactual Invariance Penalty and a Tail Drift Penalty, ProSR extends the optimization objective from single answer correctness to two process-level dimensions: visual dependence and trajectory stability. Experiments on multiple complex and out-of-distribution spatial reasoning benchmarks show that ProSR improves answer accuracy while generating reasoning trajectories that are more stable and more dependent on visual evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that mainstream VLM training for spatial reasoning relies on outcome alignment or process imitation without explicit process constraints, leading to unreliable CoT. It diagnoses two degradation modes during RL—Spurious Grounding (bypassing visual evidence) and Tail Instability (abnormal uncertainty rise in later reasoning stages)—via a new high-quality CoT dataset. ProSR introduces a Counterfactual Invariance Penalty and Tail Drift Penalty to extend the objective to visual dependence and trajectory stability, with experiments on complex and OOD spatial benchmarks reportedly showing gains in answer accuracy plus more stable, visually grounded trajectories.
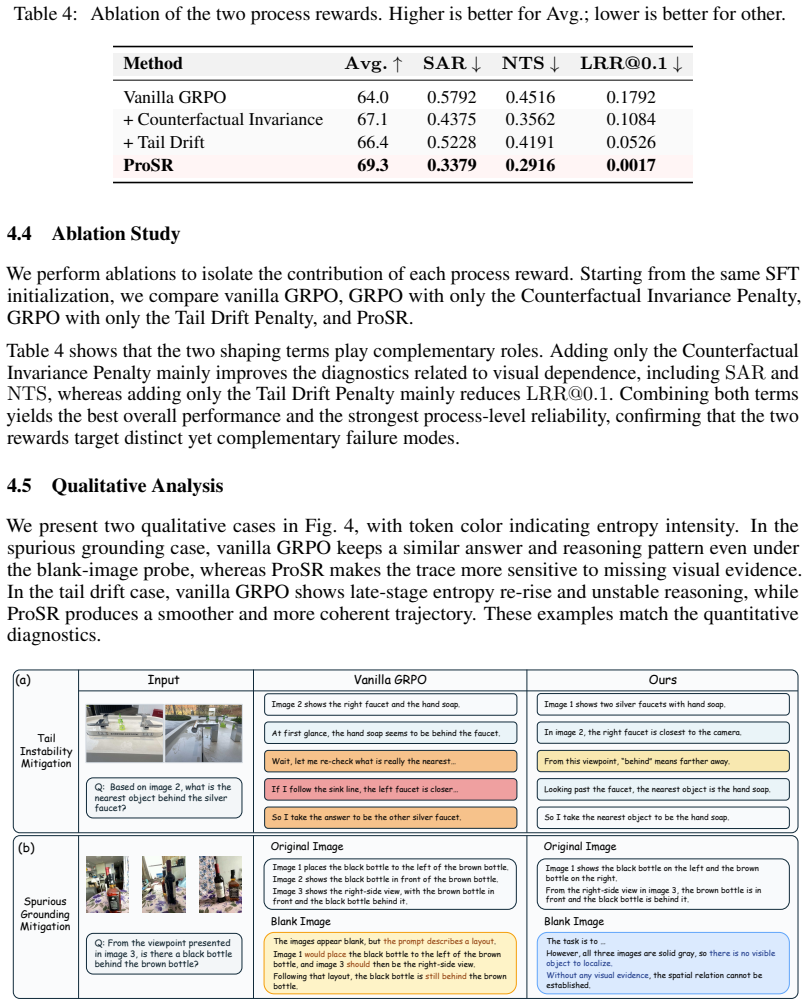
Significance. If the claimed gains are supported by ablations isolating each penalty, quantitative diagnosis metrics for the two modes, and controls ruling out dataset or standard RL effects, the work could meaningfully advance reliable process-level shaping for VLM CoT beyond outcome supervision. The absence of any such evidence in the provided manuscript text, however, leaves the significance unassessable.
major comments (3)
- [Abstract] Abstract: the central claim that the two penalties mitigate Spurious Grounding and Tail Instability (and thereby improve accuracy and visual dependence) rests entirely on unshown experimental evidence; no accuracy deltas, ablation tables, error bars, or implementation/weighting details for the penalties are supplied, so it is impossible to verify that gains arise from the process-shaping terms rather than the new CoT dataset or standard RL.
- [Abstract] Abstract: the optimization objective is described only at a high level ('extends the optimization objective from single answer correctness to two process-level dimensions') with no equations, no formulation of Counterfactual Invariance Penalty or Tail Drift Penalty, and no demonstration that these terms impose independent constraints rather than quantities already optimized in standard RL; this directly undermines the circularity assessment and the claim that the penalties specifically enforce the diagnosed modes.
- [Abstract] Abstract / § on diagnosis: the assertion that Spurious Grounding and Tail Instability are the primary causes of unreliable spatial reasoning is presented without quantitative diagnosis metrics, prevalence statistics across models, or controls showing that mitigating them does not degrade other capabilities; the weakest assumption therefore remains untested.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We acknowledge that the abstract would benefit from greater specificity regarding experimental outcomes, formulations, and supporting metrics to allow independent assessment of the claims. We respond to each major comment below and will incorporate revisions to address the points raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the two penalties mitigate Spurious Grounding and Tail Instability (and thereby improve accuracy and visual dependence) rests entirely on unshown experimental evidence; no accuracy deltas, ablation tables, error bars, or implementation/weighting details for the penalties are supplied, so it is impossible to verify that gains arise from the process-shaping terms rather than the new CoT dataset or standard RL.
Authors: The full manuscript reports accuracy improvements on the evaluated benchmarks together with ablation studies that isolate the contribution of each penalty. To make these results directly verifiable from the abstract, we will revise it to report representative accuracy deltas and to note that the ablations confirm gains attributable to the process-shaping terms beyond the dataset and standard RL. revision: yes
-
Referee: [Abstract] Abstract: the optimization objective is described only at a high level ('extends the optimization objective from single answer correctness to two process-level dimensions') with no equations, no formulation of Counterfactual Invariance Penalty or Tail Drift Penalty, and no demonstration that these terms impose independent constraints rather than quantities already optimized in standard RL; this directly undermines the circularity assessment and the claim that the penalties specifically enforce the diagnosed modes.
Authors: The mathematical definitions of the Counterfactual Invariance Penalty and Tail Drift Penalty appear in Section 3 of the manuscript. We will revise the abstract to provide a more precise description of the extended objective and to indicate how the two penalties introduce constraints distinct from standard outcome-based RL. revision: yes
-
Referee: [Abstract] Abstract / § on diagnosis: the assertion that Spurious Grounding and Tail Instability are the primary causes of unreliable spatial reasoning is presented without quantitative diagnosis metrics, prevalence statistics across models, or controls showing that mitigating them does not degrade other capabilities; the weakest assumption therefore remains untested.
Authors: Quantitative metrics used to identify the two degradation modes are already included in the diagnosis section. We will augment the revised manuscript with prevalence statistics across the models examined and with additional controls confirming that the penalties do not degrade performance on non-spatial tasks. revision: yes
Circularity Check
No circularity; method claims rest on external empirical benchmarks without self-referential reduction
full rationale
The paper identifies two degradation modes during RL and introduces Counterfactual Invariance Penalty plus Tail Drift Penalty to extend the objective toward visual dependence and trajectory stability. No equations, derivations, or self-citations appear in the supplied text that would make either penalty or the reported accuracy gains equivalent to the input data or standard RL terms by construction. The central claims are framed as outcomes of experiments on multiple out-of-distribution benchmarks, which are externally falsifiable and therefore not tautological. No load-bearing self-citation, fitted-input-as-prediction, or ansatz-smuggling pattern is present.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
DataClaw0: Agentic Tailoring Multimodal Data from Raw Streams
DataClaw0 introduces an agentic data-tailoring paradigm, a 9B model trained on a synthetically generated dataset, and a new benchmark, claiming improved downstream adaptation in video generation, VQA, and GUI navigati...
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
2022
-
[2]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[3]
Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023
2023
-
[4]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[5]
Zheyuan Zhang, Fengyuan Hu, Jayjun Lee, Freda Shi, Parisa Kordjamshidi, Joyce Chai, and Ziqiao Ma. Do vision-language models represent space and how? evaluating spatial frame of reference under ambiguities.arXiv preprint arXiv:2410.17385, 2024
-
[6]
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models.arXiv preprint arXiv:2506.03135, 2025
-
[7]
ReMoT: Reinforcement Learning with Motion Contrast Triplets
Cong Wan, Zeyu Guo, Jiangyang Li, SongLin Dong, Yifan Bai, Lin Peng, Zhiheng Ma, and Yihong Gong. Remot: Reinforcement learning with motion contrast triplets.arXiv preprint arXiv:2603.00461, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Jiangyang Li, Cong Wan, SongLin Dong, Chenhao Ding, Qiang Wang, Zhiheng Ma, and Yihong Gong. Trajectory-diversity-driven robust vision-and-language navigation.arXiv preprint arXiv:2603.15370, 2026
-
[9]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[10]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Scaling spatial intelligence with multimodal foundation models.arXiv preprint arXiv:2511.13719, 2025
Zhongang Cai, Ruisi Wang, Chenyang Gu, Fanyi Pu, Junxiang Xu, Yubo Wang, Wanqi Yin, Zhitao Yang, Chen Wei, Qingping Sun, et al. Scaling spatial intelligence with multimodal foundation models.arXiv preprint arXiv:2511.13719, 2025
-
[12]
Right for the Right Reasons: Training Differentiable Models by Constraining their Explanations
Andrew Slavin Ross, Michael C Hughes, and Finale Doshi-Velez. Right for the right rea- sons: Training differentiable models by constraining their explanations.arXiv preprint arXiv:1703.03717, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[14]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Mul- timodal chain-of-thought reasoning in language models.arXiv preprint arXiv:2302.00923, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Unleashing chain-of-thought reasoning in multi-modal language models.arXiv preprint arXiv:2403.16999, 2, 2024. 10
-
[16]
Grounded chain-of-thought for multimodal large language models.arXiv preprint arXiv:2503.12799, 2025
Qiong Wu, Xiangcong Yang, Yiyi Zhou, Chenxin Fang, Baiyang Song, Xiaoshuai Sun, and Rongrong Ji. Grounded chain-of-thought for multimodal large language models.arXiv preprint arXiv:2503.12799, 2025
-
[17]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
2023
-
[19]
Don’t just assume; look and answer: Overcoming priors for visual question answering
Aishwarya Agrawal, Dhruv Batra, Devi Parikh, and Aniruddha Kembhavi. Don’t just assume; look and answer: Overcoming priors for visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4971–4980, 2018
2018
-
[20]
Beyond question-based biases: Assessing multimodal shortcut learning in visual question answering
Corentin Dancette, Remi Cadene, Damien Teney, and Matthieu Cord. Beyond question-based biases: Assessing multimodal shortcut learning in visual question answering. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1574–1583, 2021
2021
-
[21]
Reducing language biases in visual question answering with visually-grounded question encoder
Gouthaman Kv and Anurag Mittal. Reducing language biases in visual question answering with visually-grounded question encoder. InEuropean Conference on Computer Vision, pages 18–34. Springer, 2020
2020
-
[22]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[23]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023
2023
-
[26]
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pag...
2024
-
[27]
Duo Zheng, Shijia Huang, Yanyang Li, and Liwei Wang. Learning from videos for 3d world: Enhancing mllms with 3d vision geometry priors.arXiv preprint arXiv:2505.24625, 2025
-
[28]
Wenbo Hu, Jingli Lin, Yilin Long, Yunlong Ran, Lihan Jiang, Yifan Wang, Chenming Zhu, Runsen Xu, Tai Wang, and Jiangmiao Pang. G 2VLM: Geometry grounded vision language model with unified 3d reconstruction and spatial reasoning.arXiv preprint arXiv:2511.21688, 2025
-
[29]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Jiahui Zhang, Yurui Chen, Yanpeng Zhou, Yueming Xu, Ze Huang, Jilin Mei, Junhui Chen, Yu- Jie Yuan, Xinyue Cai, Guowei Huang, et al. From flatland to space: Teaching vision-language models to perceive and reason in 3d.arXiv preprint arXiv:2503.22976, 2025. 11
-
[31]
Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models
Mengfei Du, Binhao Wu, Zejun Li, Xuan-Jing Huang, and Zhongyu Wei. Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 2: Short Papers), pages 346–355, 2024
2024
-
[32]
Site: towards spatial intelligence thorough evaluation
Wenqi Wang, Reuben Tan, Pengyue Zhu, Jianwei Yang, Zhengyuan Yang, Lijuan Wang, Andrey Kolobov, Jianfeng Gao, and Boqing Gong. Site: towards spatial intelligence thorough evaluation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9058–9069, 2025
2025
-
[33]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
2025
-
[34]
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Shijie Zhou, Dilin Wang, et al. Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction.arXiv preprint arXiv:2505.20279, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
OpenSpatial: A Principled Data Engine for Empowering Spatial Intelligence
Jianhui Liu, Haoze Sun, Wenbo Li, Yanbing Zhang, Rui Yang, Zhiliang Zhu, Yijun Yang, Shenghe Zheng, Nan Jiang, Jiaxiu Jiang, et al. Openspatial: A principled data engine for empowering spatial intelligence.arXiv preprint arXiv:2604.07296, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
2024
-
[37]
Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai C Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024
2024
-
[38]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024
2024
-
[39]
3dsrbench: A comprehensive 3d spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3dsrbench: A comprehensive 3d spatial reasoning benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6924–6934, 2025
2025
-
[40]
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, et al. Mmsi-bench: A benchmark for multi-image spatial intelligence.arXiv preprint arXiv:2505.23764, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Spatial mental modeling from limited views
Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, et al. Spatial mental modeling from limited views. InStructural Priors for Vision Workshop at ICCV’25, 2025
2025
-
[42]
Dingming Li, Hongxing Li, Zixuan Wang, Yuchen Yan, Hang Zhang, Siqi Chen, Guiyang Hou, Shengpei Jiang, Wenqi Zhang, Yongliang Shen, et al. Viewspatial-bench: Evaluating multi- perspective spatial localization in vision-language models.arXiv preprint arXiv:2505.21500, 2025
-
[43]
Zhangquan Chen, Manyuan Zhang, Xinlei Yu, Xufang Luo, Mingze Sun, Zihao Pan, Xiang An, Yan Feng, Peng Pei, Xunliang Cai, et al. Think with 3d: Geometric imagination grounded spatial reasoning from limited views.arXiv preprint arXiv:2510.18632, 2025
-
[44]
Thinking with Geometry: Active Geometry Integration for Spatial Reasoning
Haoyuan Li, Qihang Cao, Tao Tang, Kun Xiang, Zihan Guo, Jianhua Han, Hang Xu, and Xiaodan Liang. Thinking with geometry: Active geometry integration for spatial reasoning. arXiv preprint arXiv:2602.06037, 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
Rui Yang, Ziyu Zhu, Yanwei Li, Jingjia Huang, Shen Yan, Siyuan Zhou, Zhe Liu, Xiangtai Li, Shuangye Li, Wenqian Wang, et al. Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
-
[46]
Meng Cao, Xingyu Li, Xue Liu, Ian Reid, and Xiaodan Liang. Spatialdreamer: Incentivizing spatial reasoning via active mental imagery.arXiv preprint arXiv:2512.07733, 2025
-
[47]
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. Spacer: Reinforcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning
Debjit Paul, Robert West, Antoine Bosselut, and Boi Faltings. Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 15012–15032, 2024
2024
-
[50]
Making slow thinking faster: Compressing llm chain-of-thought via step entropy
Zeju Li, Jianyuan Zhong, Ziyang Zheng, Xiangyu Wen, Zhijian Xu, Yingying Cheng, Fan Zhang, and Qiang Xu. Making slow thinking faster: Compressing llm chain-of-thought via step entropy. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[51]
Zihang Li, Yuhang Wang, Yikun Zong, Wenhan Yu, Xiaokun Yuan, Runhan Jiang, Zirui Liu, Tong Yang, and Arthur Jiang. Entrocot: Enhancing chain-of-thought via adaptive entropy-guided segmentation.arXiv preprint arXiv:2601.03769, 2026
-
[52]
Hongxi Yan, Qingjie Liu, and Yunhong Wang. Entrocut: Entropy-guided adaptive truncation for efficient chain-of-thought reasoning in small-scale large reasoning models.arXiv preprint arXiv:2601.22617, 2026
-
[53]
Xinghao Zhao. Entropy trajectory shape predicts llm reasoning reliability: A diagnostic study of uncertainty dynamics in chain-of-thought.arXiv preprint arXiv:2603.18940, 2026
-
[54]
A chain-of-thought is as strong as its weakest link: A benchmark for verifiers of reasoning chains
Alon Jacovi, Yonatan Bitton, Bernd Bohnet, Jonathan Herzig, Or Honovich, Michael Tseng, Michael Collins, Roee Aharoni, and Mor Geva. A chain-of-thought is as strong as its weakest link: A benchmark for verifiers of reasoning chains. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 46...
2024
-
[55]
Sheldon Yu, Yuxin Xiong, Junda Wu, Xintong Li, Tong Yu, Xiang Chen, Ritwik Sinha, Jingbo Shang, and Julian McAuley. Explainable chain-of-thought reasoning: An empirical analysis on state-aware reasoning dynamics.arXiv preprint arXiv:2509.00190, 2025
-
[56]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report, 2025.URL https://arxiv. org/abs/2502.13923, 6:13–23, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Spatialladder: Progressive training for spatial reasoning in vision-language models.arXiv preprint arXiv:2510.08531, 2025
-
[63]
wait”, “let me reconsider
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis L Brown II, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, et al. Cambrian-s: Towards spatial supersensing in video. InThe F ourteenth International Conference on Learning Representations, 2025. 14 A Data Construction and Filtering A.1 Source Benchmarks and Coverage We construct the sp...
2025
-
[64]
State the task briefly first: Use one sentence to identify the spatial relation, movement direction, viewpoint correspondence, or target that must be determined
-
[65]
Do not summarize every image just for completeness
Use only necessary evidence: Describe only the images and objects that are truly useful for solving the question. Do not summarize every image just for completeness
-
[66]
Do not write vague summary sentences without concrete spatial support
Every step must be grounded: Each reasoning step must explicitly rely on visible objects, viewpoints, or relative spatial relations. Do not write vague summary sentences without concrete spatial support
-
[67]
Introduce a coordinate system or global directions only when it is truly necessary for multi-view integration, rotation, or direction mapping
Prefer direct spatial anchors: Prefer direct relations such as left, right, above, below, in front of, behind, beside, clockwise, counterclockwise, and from image X’s viewpoint. Introduce a coordinate system or global directions only when it is truly necessary for multi-view integration, rotation, or direction mapping. For tasks involving marked points, c...
-
[68]
Do not repeat descriptions, do not keep changing your mind, and do not loop without new evidence
Keep the reasoning short and effective: Aim for 3 to 6 short steps. Do not repeat descriptions, do not keep changing your mind, and do not loop without new evidence
-
[69]
If there is slight ambiguity, mention it briefly and then answer based on the strongest available evidence
Do not fabricate: If the visual evidence is insufficient, do not invent nonexistent objects, directions, or layouts. If there is slight ambiguity, mention it briefly and then answer based on the strongest available evidence
-
[70]
The output format must be exactly: <think> [concise, grounded, step-by-step reasoning] </think> <answer>X</answer> Where X must be exactly one of A, B, C, or D
End with a clear conclusion: The final answer must be exactly one letter: A, B, C, or D. The output format must be exactly: <think> [concise, grounded, step-by-step reasoning] </think> <answer>X</answer> Where X must be exactly one of A, B, C, or D. Do not output anything after the<answer></answer>tag. B Additional Experiments B.1 Effect of CoT Data Filte...
2069
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.