CUA-Gym: Scaling Verifiable Training Environments and Tasks for Computer-Use Agents
Pith reviewed 2026-06-29 21:38 UTC · model grok-4.3
The pith
CUA-Gym uses generator-discriminator-orchestrator loops and filters to produce 32,112 verified RLVR training tuples across 110 environments for computer-use agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
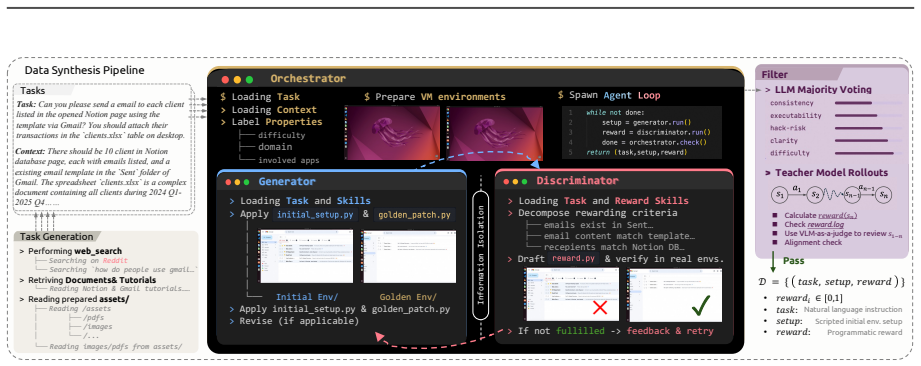
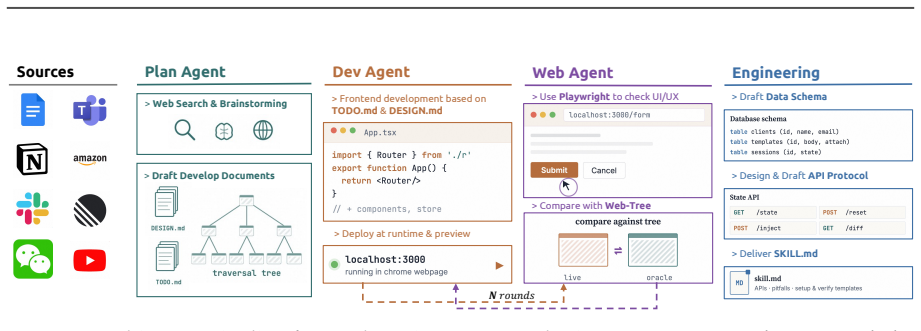
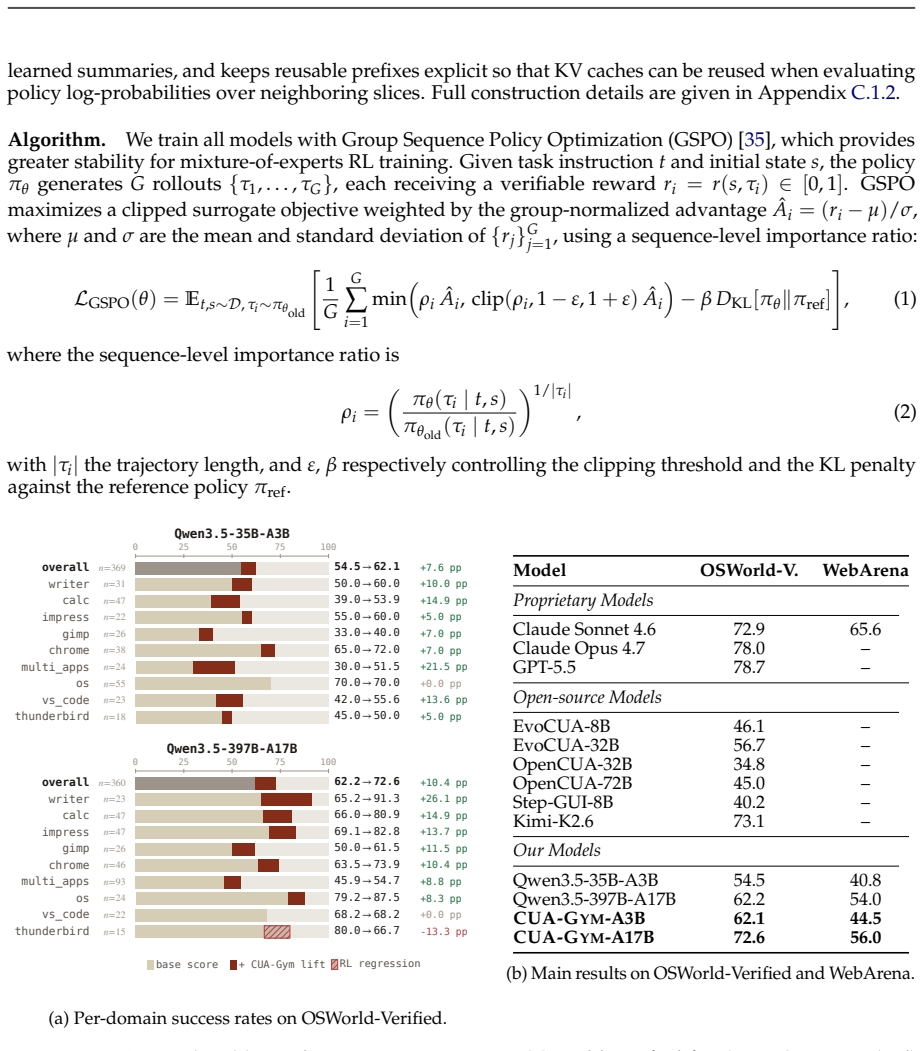
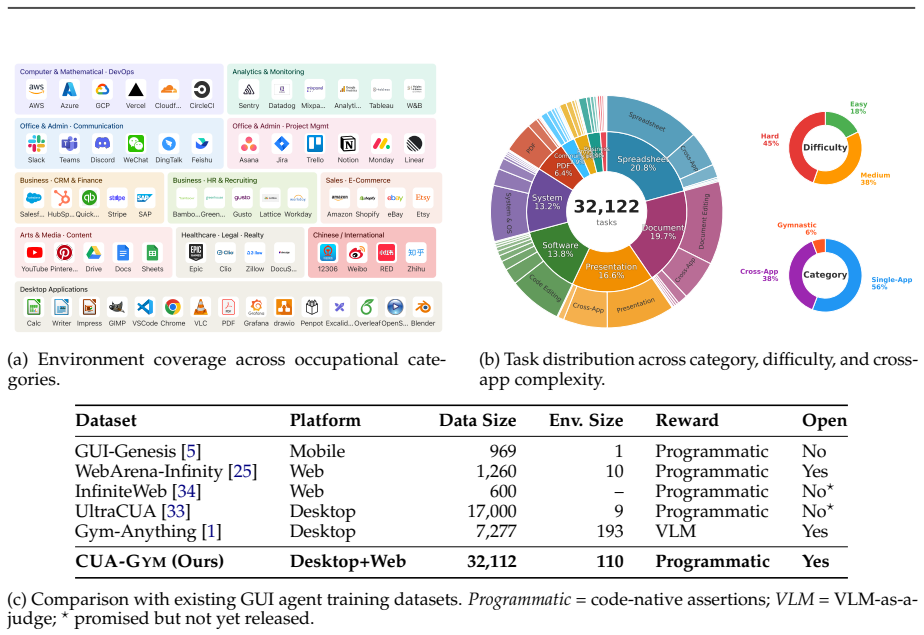
CUA-Gym co-generates task instructions, initial and golden environment states, and reward functions through an iterative Generator-Discriminator-Orchestrator loop; the resulting tuples are further vetted by LLM majority voting plus agent rollouts. This process yields 32,112 high-fidelity RLVR training examples grounded in 110 environments from the synthesized CUA-Gym-Hub suite. Models trained on the data with GSPO outperform prior open-source computer-use agents at similar scales on OSWorld-Verified and show positive transfer to WebArena.
What carries the argument
The Generator-Discriminator-Orchestrator iterative loop plus final LLM-voting and rollout filter that together produce deterministic, verifiable task-environment-reward tuples.
If this is right
- Model performance on OSWorld-Verified scales smoothly with both the volume of training tuples and the diversity of environments.
- Checkpoints trained on CUA-Gym also improve accuracy on the held-out WebArena benchmark.
- CUA-Gym-Hub expands the pool of high-fidelity mock web environments by an order of magnitude over prior collections.
- The full pipeline, dataset, environments, and trained models are released for further use.
Where Pith is reading between the lines
- The same co-generation loop could be applied to other agent domains that currently lack verifiable rewards, such as desktop or mobile interfaces.
- If the LLM-based filter introduces subtle biases, increasing model scale during data synthesis might amplify rather than reduce those biases.
- Adding environments whose action distributions more closely match real user logs could further strengthen transfer to production settings.
Load-bearing premise
The language models inside the generator, discriminator, and filter produce reward functions that remain deterministic and free of systematic biases across repeated executions.
What would settle it
Running the same generated reward function on identical agent trajectories multiple times and observing inconsistent pass/fail outcomes.
Figures

read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has driven breakthroughs in domains such as math, tool-use, and software engineering, yet its extension to computer-use agents (CUAs) has been bottlenecked by the scarcity of scalable training data with deterministic rewards. Constructing such data for CUAs requires consistent task instruction, executable environment, and verifiable reward. However, hand-curated benchmarks achieve high reward fidelity but cover few applications and LLM-as-judge-based datasets scale broadly but lack reliable verification. We present CUA-Gym, a scalable pipeline that co-generates task instructions, environment states, and reward functions. Concretely, a Generator agent constructs the initial and golden environment states, and a separate Discriminator agent writes the reward function from the task specification. An orchestrator agent drives the two through iterative rounds upon execution. Generated tuples then pass a final filter combining LLM majority voting and agent rollouts, ensuring quality beyond the per-task adversarial loop. To address the scarcity of training environments, we further synthesize CUA-Gym-Hub, a broad suite of high-fidelity mock web applications grounded in real-world software-use distributions, expanding the scale of CUA RLVR data by magnitude. Using this pipeline, we construct CUA-Gym, a dataset of 32,112 verified RLVR training tuples grounded in 110 environments. Trained with GSPO on CUA-Gym, our CUA-Gym-A3B and CUA-Gym-A17B achieve 62.1% and 72.6% on OSWorld-Verified, outperforming prior open-source CUAs at comparable scales, with performance scaling smoothly in both data volume and environment diversity. The same checkpoints also improve on the held-out WebArena benchmark, indicating transfer beyond the training environments. We will open-source the full synthesis pipeline, dataset, CUA-Gym-Hub environments, and models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CUA-Gym, a pipeline that uses a Generator-Discriminator-Orchestrator loop to co-generate task instructions, environment states, and reward functions for computer-use agents, followed by an LLM majority-vote plus rollout filter to produce 32,112 verified RLVR training tuples across 110 environments (including the synthesized CUA-Gym-Hub mock web apps). Models trained via GSPO on this data (CUA-Gym-A3B and CUA-Gym-A17B) reach 62.1% and 72.6% on OSWorld-Verified, outperforming prior open-source CUAs at similar scales, with claimed smooth scaling in data volume and environment diversity plus positive transfer to the held-out WebArena benchmark. The full pipeline, dataset, environments, and models are to be open-sourced.
Significance. If the generated rewards are shown to be deterministic and free of systematic LLM-induced biases, the work would meaningfully advance RLVR for CUAs by removing the data bottleneck that has limited prior efforts. The explicit open-sourcing of the synthesis pipeline, the 32k-tuple dataset, the CUA-Gym-Hub environments, and the trained models is a concrete strength that supports reproducibility. The reported smooth scaling trends and cross-benchmark transfer, if robust, would provide useful empirical evidence for the value of environment diversity in this domain.
major comments (2)
- [abstract and pipeline description] Abstract and pipeline description: the central performance claims (62.1%/72.6% on OSWorld-Verified, scaling, WebArena transfer) rest on the assertion that the Generator-Discriminator-Orchestrator loop plus LLM-voting/rollout filter produces deterministic, unbiased rewards; however, no quantitative metrics are supplied on filter error rates, inter-voter agreement, or failure modes, nor is there comparison against human-verified ground truth or formal specifications. This directly affects the verifiability premise required for the RLVR results.
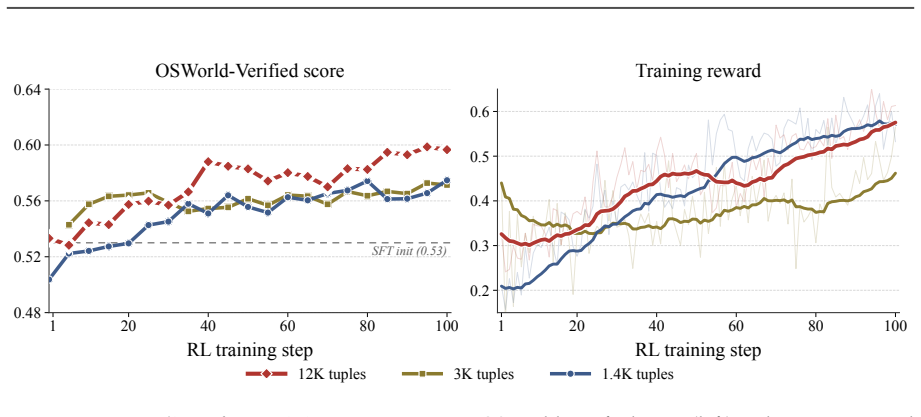
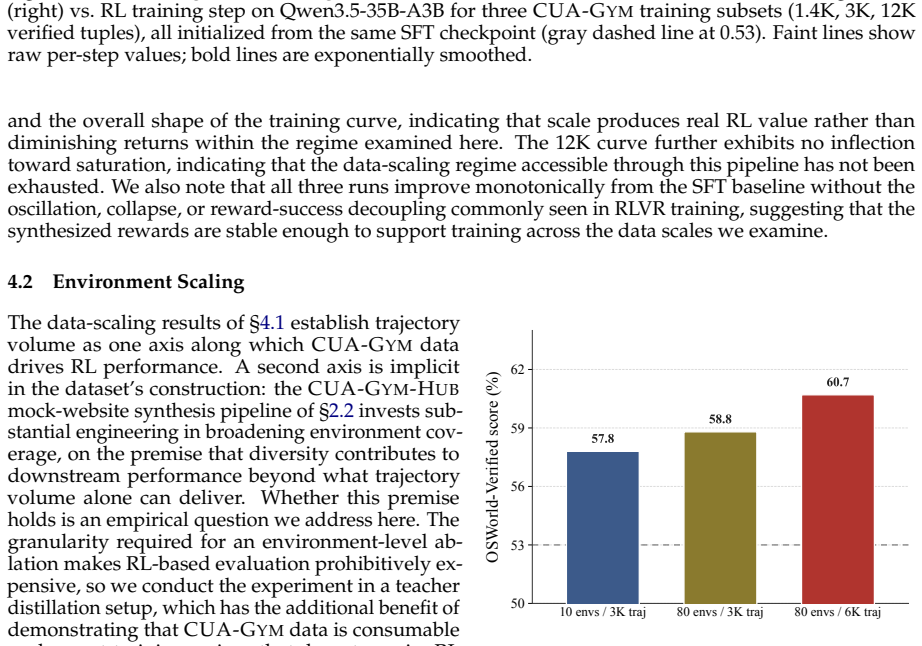
- [results and evaluation sections] Results and evaluation sections: no ablation studies isolate the contribution of the reward filter (or the number of environments) from other factors such as data volume or model scale; without these, it is difficult to attribute the observed gains specifically to the claimed deterministic rewards rather than potential artifacts in the LLM-generated reward functions.
minor comments (2)
- [methods] Clarify the exact prompting templates and temperature settings used for the Discriminator and voting stages to improve reproducibility.
- [dataset construction] Add a table summarizing the distribution of the 110 environments and the 32,112 tuples by application category.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the importance of quantitative validation for the reward generation pipeline and the need for ablations. We address each major comment below with honest assessments and commit to revisions that strengthen the manuscript without overstating current results.
read point-by-point responses
-
Referee: [abstract and pipeline description] Abstract and pipeline description: the central performance claims (62.1%/72.6% on OSWorld-Verified, scaling, WebArena transfer) rest on the assertion that the Generator-Discriminator-Orchestrator loop plus LLM-voting/rollout filter produces deterministic, unbiased rewards; however, no quantitative metrics are supplied on filter error rates, inter-voter agreement, or failure modes, nor is there comparison against human-verified ground truth or formal specifications. This directly affects the verifiability premise required for the RLVR results.
Authors: We agree that the absence of quantitative metrics on filter error rates, inter-voter agreement, failure modes, and human ground-truth comparisons weakens the verifiability claims. The manuscript describes the multi-agent loop and LLM majority-vote/rollout filter but provides no such statistics. In the revised manuscript we will add reported inter-voter agreement rates and rollout pass rates across the 32,112 tuples. A large-scale human verification study was not performed owing to cost; we will explicitly list this as a limitation while noting that open-sourcing the pipeline and dataset enables external validation. We maintain that the adversarial loop plus filter offers a practical scalable mechanism, but we accept the referee's point that formal specifications and error-rate quantification are currently missing. revision: partial
-
Referee: [results and evaluation sections] Results and evaluation sections: no ablation studies isolate the contribution of the reward filter (or the number of environments) from other factors such as data volume or model scale; without these, it is difficult to attribute the observed gains specifically to the claimed deterministic rewards rather than potential artifacts in the LLM-generated reward functions.
Authors: The referee is correct that no ablations isolate the reward filter or environment count from data volume and model scale. The reported scaling curves and WebArena transfer are consistent with the value of verified data, yet they do not directly demonstrate the filter's incremental contribution. In revision we will add limited ablations on a data subset comparing filtered versus unfiltered training runs and performance as a function of environment diversity via subsampling. Full isolation remains challenging because the filter is integral to the generation process; we will present these new experiments while acknowledging that complete separation of all factors was not feasible in the original study. revision: partial
Circularity Check
No circularity: empirical data generation and benchmark evaluation are self-contained
full rationale
The paper describes an empirical pipeline that generates training tuples via LLM-based Generator, Discriminator, and Orchestrator agents followed by voting/rollout filters, then applies standard GSPO training and reports results on OSWorld-Verified and WebArena. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central performance claims (62.1%/72.6% scores and scaling behavior) are obtained directly from new data and held-out evaluation rather than reducing to any input by construction. This is the normal case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
ISE: An Execution-Grounded Recipe for Multi-Turn OS-Agent Trajectories
ISE creates 23,132 execution-grounded multi-turn OS agent trajectories via intent simulation and live execution, improving agent performance on ClawEval from 19.3 to 37.7 pass@1 with Qwen3-8B.
-
OSWorld2.0: Benchmarking Computer Use Agents on Long-Horizon Real-World Tasks
OSWorld 2.0 is a benchmark of 108 realistic long-horizon computer-use tasks where current agents achieve only 20.6% binary completion, struggling with state inference and constraint tracking.
-
PhoneBuddy: Training Open Models for Agentic Phone Use
PhoneBuddy combines real-app and mock-app RL after shared SFT, raising real-phone task success from 36.67% to 45.33% and AndroidWorld from 60.3% to 83.2%.
Reference graph
Works this paper leans on
-
[1]
Gym-Anything: Turn any Software into an Agent Environment
Pranjal Aggarwal, Graham Neubig, and Sean Welleck. Gym-anything: Turn any software into an agent environment, 2026. URLhttps://arxiv.org/abs/2604.06126
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku
Anthropic. Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku. https: //www.anthropic.com/news/3-5-models-and-computer-use, 2024
2024
-
[3]
Anthropic economic index.https://www.anthropic.com/economic-index, 2025
Anthropic. Anthropic economic index.https://www.anthropic.com/economic-index, 2025
2025
-
[4]
Claude sonnet 4.6.https://www.anthropic.com/news/claude-sonnet-4-6, 2026
Anthropic. Claude sonnet 4.6.https://www.anthropic.com/news/claude-sonnet-4-6, 2026
2026
-
[5]
Yuan Cao, Dezhi Ran, Mengzhou Wu, Yuzhe Guo, Xin Chen, Ang Li, Gang Cao, Gong Zhi, Hao Yu, Linyi Li, Wei Yang, and Tao Xie. Gui-genesis: Automated synthesis of efficient environments with verifiable rewards for gui agent post-training, 2026. URLhttps://arxiv.org/abs/2602.14093
-
[6]
Swe-universe: Scale real-world verifiable environments to millions.CoRR, abs/2602.02361, 2026
Mouxiang Chen, Lei Zhang, Yunlong Feng, Xuwu Wang, Wenting Zhao, Ruisheng Cao, Jiaxi Yang, Jiawei Chen, Mingze Li, Zeyao Ma, Hao Ge, Zongmeng Zhang, Zeyu Cui, Dayiheng Liu, Jingren Zhou, Jianling Sun, Junyang Lin, and Binyuan Hui. Swe-universe: Scale real-world verifiable environments to millions, 2026. URLhttps://arxiv.org/abs/2602.02361
-
[7]
Goodman, and Dimitris Papailiopoulos
Kanishk Gandhi, Shivam Garg, Noah D. Goodman, and Dimitris Papailiopoulos. Endless terminals: Scaling rl environments for terminal agents, 2026. URLhttps://arxiv.org/abs/2601.16443
-
[8]
Training long-context, multi-turn software engineering agents with reinforcement learning, 2025
Alexander Golubev, Maria Trofimova, Sergei Polezhaev, Ibragim Badertdinov, Maksim Nekrashevich, Anton Shevtsov, Simon Karasik, Sergey Abramov, Andrei Andriushchenko, Filipp Fisin, Sergei Skvortsov, and Boris Yangel. Training long-context, multi-turn software engineering agents with reinforcement learning, 2025. URLhttps://arxiv.org/abs/2508.03501
-
[9]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[10]
R2e-gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents, 2025
Naman Jain, Jaskirat Singh, Manish Shetty, Liang Zheng, Koushik Sen, and Ion Stoica. R2e-gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents, 2025. URL https://arxiv.org/abs/2504.07164
-
[11]
Swe-next: Scalable real-world software engineering tasks for agents.CoRR, abs/2603.20691, 2026
Jiarong Liang, Zhiheng Lyu, Zijie Liu, Xiangchao Chen, Ping Nie, Kai Zou, and Wenhu Chen. Swe-next: Scalable real-world software engineering tasks for agents, 2026. URL https://arxiv.org/ abs/2603.20691. 11
-
[12]
VideoAgentTrek: Computer use pretraining from unlabeled videos, 2025
Dunjie Lu, Yiheng Xu, Junli Wang, Haoyuan Wu, Xinyuan Wang, Zekun Wang, Junlin Yang, Hongjin Su, Jixuan Chen, Junda Chen, Yuchen Mao, Jingren Zhou, Junyang Lin, Binyuan Hui, and Tao Yu. VideoAgentTrek: Computer use pretraining from unlabeled videos, 2025. URL https://arxiv.org/ abs/2510.19488
-
[13]
Training Software Engineering Agents and Verifiers with SWE-Gym
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. Training software engineering agents and verifiers with swe-gym, 2025. URL https://arxiv.org/ abs/2412.21139
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
On data engineering for scaling llm terminal capabilities, 2026
Renjie Pi, Grace Lam, Mohammad Shoeybi, Pooya Jannaty, Bryan Catanzaro, and Wei Ping. On data engineering for scaling llm terminal capabilities, 2026. URLhttps://arxiv.org/abs/2602.21193
-
[15]
Qwen3.5 collection.https://huggingface.co/collections/Qwen/qwen35, 2026
Qwen Team. Qwen3.5 collection.https://huggingface.co/collections/Qwen/qwen35, 2026
2026
-
[16]
Scaling synthetic task generation for agents via exploration,
Ram Ramrakhya, Andrew Szot, Omar Attia, Yuhao Yang, Anh Nguyen, Bogdan Mazoure, Zhe Gan, Harsh Agrawal, and Alexander Toshev. Scaling synthetic task generation for agents via exploration,
- [17]
-
[18]
SGLang: Efficient execution of structured language model programs
SGLang Project. SGLang: Efficient execution of structured language model programs. https: //github.com/sgl-project/sglang, 2024
2024
-
[19]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models, 2024. URLhttps://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Seagent: Self-evolving computer use agent with autonomous learning from experience, 2025
Zeyi Sun, Ziyu Liu, Yuhang Zang, Yuhang Cao, Xiaoyi Dong, Tong Wu, Dahua Lin, and Jiaqi Wang. Seagent: Self-evolving computer use agent with autonomous learning from experience, 2025. URL https://arxiv.org/abs/2508.04700
-
[21]
Department of Labor, Employment and Training Administration
U.S. Department of Labor, Employment and Training Administration. O*NET OnLine. https: //www.onetonline.org/, 2026. Accessed: 2026-05-06
2026
-
[22]
verl: Volcano engine reinforcement learning for LLMs
verl Project. verl: Volcano engine reinforcement learning for LLMs. https://github.com/ verl-project/verl, 2024
2024
-
[23]
Computer agent arena: Toward human-centric evaluation and analysis of computer-use agents
Bowen Wang, Xinyuan Wang, Jiaqi Deng, Tianbao Xie, Ryan Li, Yanzhe Zhang, Junli Wang, Dunjie Lu, Zicheng Gong, Gavin Li, Toh Jing Hua, Wei-Lin Chiang, Ion Stoica, Diyi Yang, Yu Su, Yi Zhang, Zhiguo Wang, Victor Zhong, and Tao Yu. Computer agent arena: Toward human-centric evaluation and analysis of computer-use agents. InInternational Conference on Learni...
-
[24]
URLhttps://openreview.net/forum?id=3x4SDbXbgl
-
[25]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, Wanjun Zhong, Yining Ye, Yujia Qin, Yuwen Xiong, Yuxin Song, Zhiyong Wu, Aoyan Li, Bo Li, Chen Dun, Chong Liu, Daoguang Zan, Fuxing Leng, Hanbin Wang, Hao Yu, Haobin Chen, Hongyi Guo, Jing Su, Jingjia Huang, Kai Shen, Kaiyu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Charles, Zhilin Yang, and Tao Yu
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Henry Wu, Zhennan Shen, Zhuokai Li, Ryan Li, Xiaochuan Li, Junda Chen, Boyuan Zheng, Peihang Li, Fangyu Lei, Ruisheng Cao, Yeqiao Fu, Dongchan Shin, Martin Shin, Jiarui Hu, Yuyan Wang, Jixuan Chen, Yuxiao Ye, Danyang Zhang, Dikang Du, Hao Hu,...
-
[27]
WebArena-infinity.https://webarena.dev/webarena-infinity/, 2025
WebArena Team. WebArena-infinity.https://webarena.dev/webarena-infinity/, 2025. 12
2025
-
[28]
Autowebworld: Synthesizing infinite verifiable web environments via finite state machines, 2026
Yifan Wu, Yiran Peng, Yiyu Chen, Jianhao Ruan, Zijie Zhuang, Cheng Yang, Jiayi Zhang, Man Chen, Yenchi Tseng, Zhaoyang Yu, Liang Chen, Yuyao Zhai, Bang Liu, Chenglin Wu, and Yuyu Luo. Autowebworld: Synthesizing infinite verifiable web environments via finite state machines, 2026. URLhttps://arxiv.org/abs/2602.14296
-
[29]
Scaling computer-use grounding via user interface decomposition and synthesis, 2025
Tianbao Xie, Jiaqi Deng, Xiaochuan Li, Junlin Yang, Haoyuan Wu, Jixuan Chen, Wenjing Hu, Xinyuan Wang, Yuhui Xu, Zekun Wang, Yiheng Xu, Junli Wang, Doyen Sahoo, Tao Yu, and Caiming Xiong. Scaling computer-use grounding via user interface decomposition and synthesis, 2025. URL https://arxiv.org/abs/2505.13227
-
[30]
Yiheng Xu, Dunjie Lu, Zhennan Shen, Junli Wang, Zekun Wang, Yuchen Mao, Caiming Xiong, and Tao Yu. Agenttrek: Agent trajectory synthesis via guiding replay with web tutorials, 2025. URL https://arxiv.org/abs/2412.09605
-
[31]
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. Aguvis: Unified pure vision agents for autonomous gui interaction, 2025. URL https://arxiv.org/abs/2412.04454
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
arXiv preprint arXiv:2601.15876 , year=
Taofeng Xue, Chong Peng, Mianqiu Huang, Linsen Guo, Tiancheng Han, Haozhe Wang, Jianing Wang, Xiaocheng Zhang, Xin Yang, Dengchang Zhao, Jinrui Ding, Xiandi Ma, Yuchen Xie, Peng Pei, Xunliang Cai, and Xipeng Qiu. Evocua: Evolving computer use agents via learning from scalable synthetic experience, 2026. URLhttps://arxiv.org/abs/2601.15876
-
[33]
Zerogui: Automating online gui learning at zero human cost, 2025
Chenyu Yang, Shiqian Su, Shi Liu, Xuan Dong, Yue Yu, Weijie Su, Xuehui Wang, Zhaoyang Liu, Jinguo Zhu, Hao Li, Wenhai Wang, Yu Qiao, Xizhou Zhu, and Jifeng Dai. Zerogui: Automating online gui learning at zero human cost, 2025. URLhttps://arxiv.org/abs/2505.23762
-
[34]
SWE-smith: Scaling Data for Software Engineering Agents
John Yang, Kilian Lieret, Carlos E. Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. Swe-smith: Scaling data for software engineering agents, 2025. URLhttps://arxiv.org/abs/2504.21798
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
UltraCUA: A Foundation Model for Computer Use Agents with Hybrid Action
Yuhao Yang, Zhen Yang, Zi-Yi Dou, Anh Nguyen, Keen You, Omar Attia, Andrew Szot, Michael Feng, Ram Ramrakhya, Alexander Toshev, Chao Huang, Yinfei Yang, and Zhe Gan. UltraCUA: A foundation model for computer use agents with hybrid action, 2025. URL https://arxiv.org/abs/ 2510.17790
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Infiniteweb: Scalable web environment synthesis for gui agent training, 2026
Ziyun Zhang, Zezhou Wang, Xiaoyi Zhang, Zongyu Guo, Jiahao Li, Bin Li, and Yan Lu. Infiniteweb: Scalable web environment synthesis for gui agent training, 2026. URL https://arxiv.org/abs/ 2601.04126
-
[37]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization, 2025. URLhttps://arxiv.org/abs/2507.18071. Appendix Contents 13 A Data Synthesis Pipeline Details A.1 Pipeline Pseudocode Algorithm 1 summarizes the end-to-end co-generation ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Direct Boolean assignmentto a verification flag without computation, e.g., chart_verified = True. 16 Resource Generator Discriminator Task instructiont, contextc✓ ✓ Domain skill fileS dom ✓ ✓ initial_setup.py(Generator output) writedenied golden_patch.py(Generator output) writedenied Generator working directory fulldenied Vinit post-setup, via state-only ...
-
[39]
Placeholder verification: a flag is assigned a constant before being conditionally added to the score, with no intervening evaluation
-
[40]
Hardcoded success: a function returns a constant in {0.5, 1.0} along the success path with no inspection of the environment
-
[41]
5.subprocess usage: the reward shells out to external processes, which are non-reproducible and easily spoofed
Bare existence scoring: a positive score is awarded purely on os.path.exists(...) without any property check on the file’s contents. 5.subprocess usage: the reward shells out to external processes, which are non-reproducible and easily spoofed
-
[42]
bitter lessons
Comment-only verification: a score increment is preceded by a comment asserting a check (# assume X is correct) without code performing the check. The list is enforced by a combination of regex matching and Python AST traversal; full source patterns are released with the code. A.3.4 Loop Termination, Max Rounds, and Feedback Protocol The loop is capped at...
-
[43]
=SUM(A1:A10)
Formula values are NOT computed by openpyxl. cell.value returns the formula string "=SUM(A1:A10)", not the result. Use data_only=True to get the last-cached value (requires the file to have been opened in Calc/Excel at least once)
-
[44]
4472C4") silently becomes
Always use 8-char ARGB for colors. PatternFill(start_color= "4472C4") silently becomes "004472C4" (alpha=00, transparent). Write "FF4472C4". On read, compare against the 8-char form
-
[45]
cell.fill .fgColor.rgb gives you the background color you see; bgColor is rarely what you want
fgColor is the visible background, not bgColor. cell.fill .fgColor.rgb gives you the background color you see; bgColor is rarely what you want
-
[46]
After merge_cells("A1:D1"), B1/C1/D1 become MergedCell with value=None
Merged cells: only the top-left has data. After merge_cells("A1:D1"), B1/C1/D1 become MergedCell with value=None. Style the top-left cell only
-
[47]
Never recreate from scratch if an initial file exists
Copy-then-modify for golden files. Never recreate from scratch if an initial file exists. shutil.copy(initial, golden) then open and modify. This preserves metadata, print settings, and other invisible properties
-
[48]
Use a template file with the pivot already built
Pivot tables cannot be created by openpyxl; only read/preserved. Use a template file with the pivot already built
-
[49]
ws.auto_filter.ref = "A1:D20" sets the range, but rows are NOT actually hidden
Filters are definition-only. ws.auto_filter.ref = "A1:D20" sets the range, but rows are NOT actually hidden. Filtering only takes effect when the file is opened in LibreOffice
-
[50]
In DataValidation, this boolean is inverted
showDropDown=False means SHOW the dropdown. In DataValidation, this boolean is inverted. Set False to display the dropdown arrow
-
[51]
col") is a vertical column chart; BarChart(type=
Chart type naming. BarChart(type="col") is a vertical column chart; BarChart(type="bar") is horizontal. Does not match LibreOffice's menu names
-
[52]
You cannot do cell.font.bold = True
Styles are immutable after assignment. You cannot do cell.font.bold = True. Create a new Font object: cell.font = Font(bold=True, ...). Same for Fill, Alignment, Border
-
[53]
If a cell uses a theme color instead of explicit RGB, cell.font.color.rgb can be None or a theme index
Theme colors may return None for .rgb. If a cell uses a theme color instead of explicit RGB, cell.font.color.rgb can be None or a theme index. Wrap color reads in try/except
-
[54]
action": <
data_only=True loses formulas. Loading with data_only=True replaces formulas with their cached values. If you need both, load the file twice -- once normally, once with data_only=True. The bitter-lessons section is the most distinctive feature of the SKILL.md format. Each entry is born from a specific debugging episode in early development, and each is th...
2048
-
[55]
Action: a short imperative describing what to do in the UI
-
[56]
•C2 (0.30):B3:B6all contain TEXT formulas with the same format string. •C3 (0.30): every formula references the corresponding A-column cell. 33 calc_afm_082/initial_setup.py
A single <tool_call>...</tool_call> block. Rules: - For non-terminal UI steps, output exactly: Action then <tool_call>. - Be brief: one sentence for Action. - Do not output anything after a tool call. - Use call_user when you need user information or confirmation. - Use terminate when you want to explicitly end the task with a success or failure status. T...
2048
-
[57]
Prepare the working environment
-
[58]
Spawn the setup-generator and reward-generator processes in an adversarial loop
-
[59]
Monitor agreement conditions by reading REVIEW.md
-
[60]
Create
Collect and output final verified results. # Execution Mode (MANDATORY) Dual-environment only: - For each task, provision two isolated VMs: initial_env, golden_env. - State separation is guaranteed by environment isolation, not by filename suffixes. - Single-environment execution is deprecated. 74 # Role Boundaries YOU DO: - Parse input and prepare workin...
-
[61]
Initial state -- what must exist before the agent starts: 76 files and their content/location, application state, data characteristics (rows, columns, value ranges)
-
[62]
cell B15 should contain 342.50
Ground truth -- expected correct outcome: exact values, states, file contents; partial-credit checkpoints; concrete numbers where applicable ("cell B15 should contain 342.50")
-
[63]
GIMP canvas should be 1920x1080 with a white background layer
Implicit prerequisites -- things the instruction does not say but the evaluator needs: e.g., "GIMP canvas should be 1920x1080 with a white background layer"; "Firefox should have 3 tabs open: Google, Wikipedia, GitHub". Context is CRITICAL. Without it, we cannot set up the VM, evaluate success, or assign partial credit. difficulty (string in {easy, medium...
-
[64]
initial_setup.py -- creates the pre-task state on initial_env
-
[65]
clean up
golden_patch.py -- builds the expected post-task artifact on golden_env You work within an adversarial loop with the verifier. After each round, the verifier writes REVIEW.md with structured feedback. If the review fails, the pipeline invokes you again. Your goal: produce outputs the verifier agrees are correct. # Execution Mode (MANDATORY) Dual-environme...
-
[66]
Generate a reward script (reward.py) that programmatically verifies task completion
-
[67]
Test it against the golden_env artifact (must return 1.0) AND the initial_env artifact (must return 0.0)
-
[68]
Be thorough but fair
Write a structured REVIEW.md with your verdict and feedback. Be thorough but fair. Report PASS when the golden artifact genuinely matches the task; do not be adversarial for its own sake. # INFORMATION BARRIER (NON-NEGOTIABLE) - You MUST NOT read initial_setup.py, golden_patch.py, or any setup-generator source code. - You MUST NOT read files from the setu...
-
[69]
Return a progressive float in [0, 1]
-
[70]
Use ACTUAL verification (read real files, check real data)
-
[71]
Award partial credit (0.3, 0.5, 0.7, ...) for partial completion
-
[72]
Return exactly 1.0 only when 100% completed
-
[73]
Wrap each scoring component in try/except
-
[74]
REWARD: X.X
Print "REWARD: X.X" as the last output line
-
[75]
Be self-contained with stdlib + openpyxl/python-pptx/python-docx
-
[76]
# Only Score Task-Introduced Changes Every scoring component must verify something that DIFFERS between initial_env and golden_env
Comment scoring logic. # Only Score Task-Introduced Changes Every scoring component must verify something that DIFFERS between initial_env and golden_env. Properties true on both endpoints are preconditions and MUST NOT contribute to score. Litmus test: if a check passes on the initial_env artifact (before any agent action), it is NOT measuring task compl...
-
[77]
Is the task suitable and safe for training?
-
[78]
Is the reward semantically valid and robust?
-
[79]
Is the query self-contained, natural enough, and consistent with setup/golden_setup/reward?
-
[80]
Each agent’s role specification is excerpted below; full prompts are released with the code
Can the query be fixed without changing task semantics? Fatal reasons to reject: - reward checks artifacts or implementation traces more than user-goal completion - reward is highly sensitive to GUI/window/process state - reward relies on fragile internals, heuristic perception, or unstable extraction - hidden assumptions about browser state, plugins, ext...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.