DRScaffold: Boosting Dense-Scene Reasoning in Lightweight Vision Language Models
Pith reviewed 2026-06-29 22:51 UTC · model grok-4.3
The pith
Four-stage supervision lets a 3B vision-language model outperform a frozen 32B model on dense-scene reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
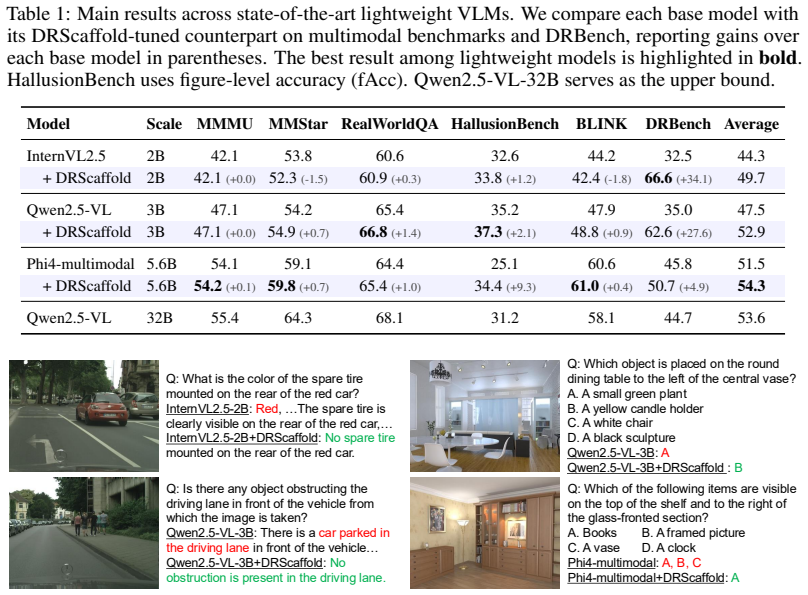
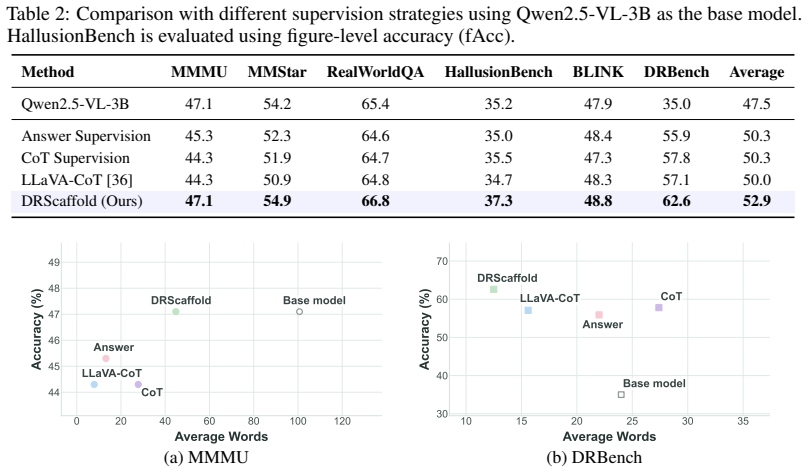
We introduce DRBench, a benchmark of 14,573 questions across 2,943 images spanning five task categories and three reasoning layers, and DRScaffold, a supervised fine-tuning framework that decomposes the target into four causally ordered stages. These stages enforce explicit grounding between reasoning steps and visual entities without any architectural change. On three lightweight VLMs, DRScaffold produces substantial gains on DRBench while preserving or improving results on general benchmarks; notably, the 3B model trained this way surpasses the frozen 32B model on DRBench.
What carries the argument
DRScaffold, a supervised fine-tuning framework that decomposes the supervision target into four causally ordered stages enforcing grounded reasoning.
If this is right
- Structured supervision can close much of the performance gap between small and large models on dense-scene tasks.
- The same lightweight backbone can be reused across general and dense-reasoning workloads without trade-offs.
- No model architecture changes are required to obtain the reported gains.
- The approach generalizes across at least three different lightweight vision-language models.
Where Pith is reading between the lines
- If the causal stages truly produce grounded chains, the same decomposition could be tested on non-visual reasoning benchmarks that also suffer from unanchored steps.
- Success here suggests that targeted supervision schedules may reduce reliance on scale for other multi-step grounding problems in perception.
- The benchmark categories could be used to diagnose which specific layer of reasoning (object, attribute, or relation) still limits current models.
Load-bearing premise
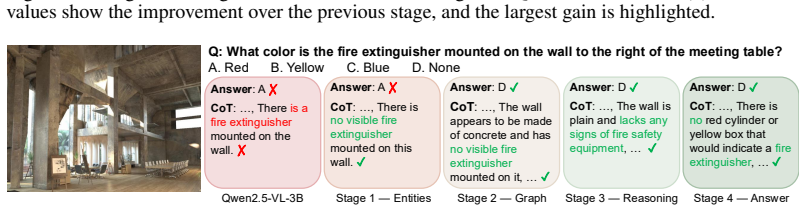
The four causally ordered supervision stages actually enforce explicit grounding between reasoning steps and visual entities rather than simply supplying extra training signal.
What would settle it
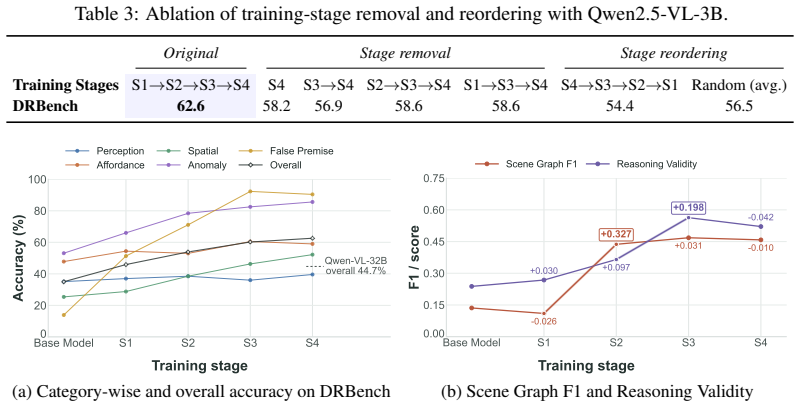
An ablation that removes the causal ordering of the four stages or randomizes their sequence while keeping total training data fixed, then measures whether DRBench scores remain unchanged.
Figures


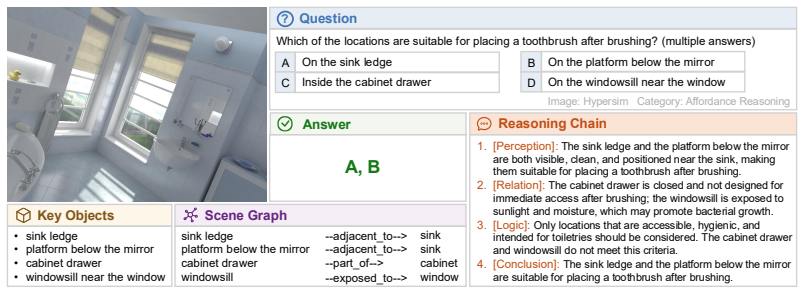
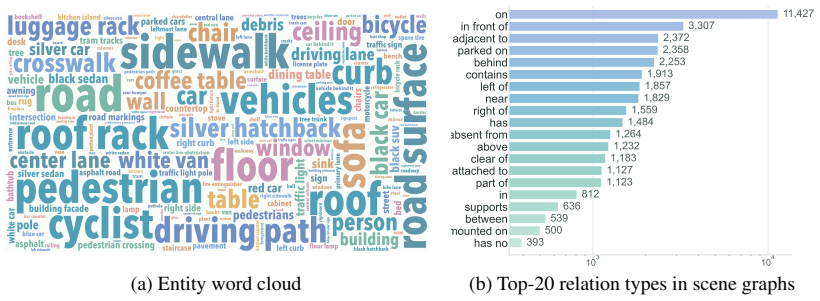
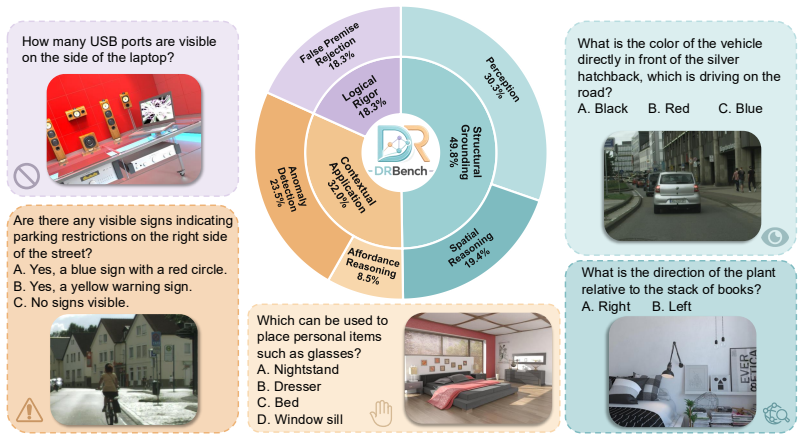
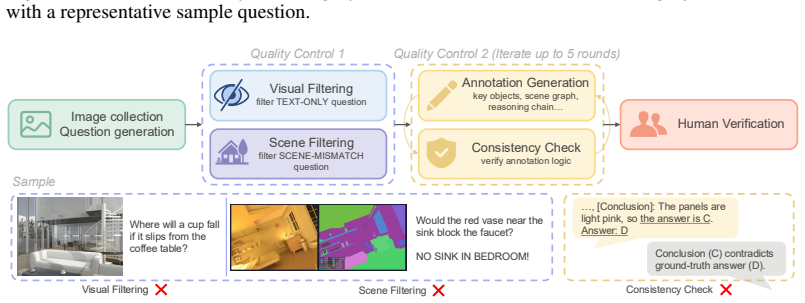







read the original abstract
Lightweight vision-language models perform competitively on standard benchmarks yet fail systematically in dense-scene reasoning, where multiple objects, attributes, and relations must be jointly grounded and resolved through multi-step inference. Such capability is critical for real-world applications where models must reliably interpret cluttered environments. Yet existing training signals provide no explicit grounding between reasoning steps and the underlying visual entities and relations, leaving lightweight models free to generate fluent but visually unanchored reasoning chains. To address this gap, we first introduce DRBench, a benchmark of 14,573 questions across 2,943 images, organized into five task categories spanning three progressive reasoning layers. Building on DRBench, we propose DRScaffold, a supervised fine-tuning framework that decomposes the supervision target into four causally ordered stages, enforcing grounded reasoning without architectural modification. Experiments on three lightweight VLMs demonstrate substantial gains on DRBench while preserving or improving performance on general-purpose benchmarks. Notably, Qwen2.5-VL-3B trained with DRScaffold surpasses the frozen Qwen2.5-VL-32B on DRBench, demonstrating that structured supervision can substitute for a significant portion of model scale in dense-scene reasoning. Our code and models are available at https://github.com/irene-shi/DRScaffold .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DRBench, a benchmark of 14,573 questions across 2,943 images spanning five task categories and three reasoning layers, and proposes DRScaffold, a supervised fine-tuning framework that decomposes targets into four causally ordered stages to enforce explicit grounding between reasoning steps and visual entities/relations in lightweight VLMs. Experiments on three lightweight models report substantial gains on DRBench, with Qwen2.5-VL-3B fine-tuned via DRScaffold surpassing the frozen Qwen2.5-VL-32B while preserving or improving general-purpose benchmark performance; code and models are released.
Significance. If the central empirical result holds under controlled conditions, the demonstration that structured supervision can substitute for a substantial fraction of model scale in dense-scene reasoning would be a meaningful contribution to efficient VLM development. The public release of code and models is a clear strength that supports reproducibility.
major comments (3)
- [Experiments] The claim that the four causally ordered stages produce explicit step-to-entity grounding (rather than simply supplying additional training signal) is load-bearing for the substitution-for-scale interpretation, yet the experimental section provides no ablation that holds total supervision tokens, question distribution, and format fixed while varying only the causal decomposition. Without this control, the reported 3B > 32B result on DRBench remains underdetermined.
- [Experiments] The comparison between the fine-tuned 3B model and the frozen 32B model does not report whether the 32B model was evaluated under identical prompting or whether any additional inference-time scaffolding was applied; this detail is required to interpret the scale-substitution result.
- [DRScaffold framework] Implementation details of the four supervision stages (exact prompt templates, loss weighting across stages, and how causal ordering is enforced during data construction) are not supplied, preventing independent verification that the reported gains arise from the proposed mechanism.
minor comments (1)
- [Abstract] The abstract states 'substantial gains' without quantifying effect sizes or reporting statistical significance; adding these numbers would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify key areas for strengthening experimental controls and reproducibility, which we address point by point below.
read point-by-point responses
-
Referee: [Experiments] The claim that the four causally ordered stages produce explicit step-to-entity grounding (rather than simply supplying additional training signal) is load-bearing for the substitution-for-scale interpretation, yet the experimental section provides no ablation that holds total supervision tokens, question distribution, and format fixed while varying only the causal decomposition. Without this control, the reported 3B > 32B result on DRBench remains underdetermined.
Authors: We agree that an ablation holding total supervision tokens, question distribution, and format fixed while varying only the causal decomposition would more cleanly isolate whether gains arise from explicit grounding rather than additional training signal volume. Our current experiments compare DRScaffold to standard SFT baselines with matched data volume, but do not include this precise control. We will add the requested ablation in the revised manuscript. revision: yes
-
Referee: [Experiments] The comparison between the fine-tuned 3B model and the frozen 32B model does not report whether the 32B model was evaluated under identical prompting or whether any additional inference-time scaffolding was applied; this detail is required to interpret the scale-substitution result.
Authors: The frozen 32B model was evaluated using identical zero-shot prompting with no additional inference-time scaffolding. We will explicitly state this evaluation protocol in the revised experimental setup section. revision: yes
-
Referee: [DRScaffold framework] Implementation details of the four supervision stages (exact prompt templates, loss weighting across stages, and how causal ordering is enforced during data construction) are not supplied, preventing independent verification that the reported gains arise from the proposed mechanism.
Authors: We agree these details are necessary for independent verification. We will add the exact prompt templates, loss weighting scheme across stages, and data construction procedure for enforcing causal ordering to the revised manuscript (expanding Section 3 and the appendix). revision: yes
Circularity Check
No circularity: empirical results rest on direct model comparisons, not self-referential definitions or fits.
full rationale
The paper introduces DRBench and the DRScaffold training framework as an empirical intervention, then reports performance numbers from fine-tuning lightweight VLMs and comparing them to baselines including a larger frozen model. No equations, parameter fits, or derivations are present in the provided text; the central claim (3B model surpassing 32B on DRBench) is a straightforward experimental outcome rather than a quantity defined in terms of itself or recovered from a self-citation chain. None of the enumerated circularity patterns apply.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Decomposing the supervision target into four causally ordered stages enforces grounded reasoning without architectural modification.
Reference graph
Works this paper leans on
-
[1]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, et al. Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras.arXiv preprint arXiv:2503.01743, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Kesheng Chen, Yamin Hu, Qi Zhou, Zhenqian Zhu, and Wenjian Luo. Cdh-bench: A commonsense- driven hallucination benchmark for evaluating visual fidelity in vision-language models.arXiv preprint arXiv:2603.27982, 2026
-
[5]
Are we on the right way for evaluating large vision-language models?NeurIPS, 37, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?NeurIPS, 37, 2024
2024
-
[6]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
Xiangxiang Chu, Limeng Qiao, Xinyu Zhang, Shuang Xu, Fei Wei, Yang Yang, Xiaofei Sun, Yiming Hu, Xinyang Lin, Bo Zhang, et al. Mobilevlm v2: Faster and stronger baseline for vision language model. arXiv preprint arXiv:2402.03766, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InCVPR, 2016
2016
-
[10]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. In ECCV, 2024
2024
-
[11]
Specializing smaller language models towards multi-step reasoning
Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, and Tushar Khot. Specializing smaller language models towards multi-step reasoning. InICML, 2023
2023
-
[12]
Akshay Gopalkrishnan, Ross Greer, and Mohan Trivedi. Multi-frame, lightweight & efficient vision- language models for question answering in autonomous driving.arXiv preprint arXiv:2403.19838, 2024
-
[13]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InCVPR, 2017
2017
-
[14]
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InCVPR, 2024
2024
-
[15]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
Large language models are reasoning teachers
Namgyu Ho, Laura Schmid, and Se-Young Yun. Large language models are reasoning teachers. InACL, 2023
2023
-
[17]
Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InACL Findings, 2023
2023
-
[18]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InCVPR, 2019. 10
2019
-
[19]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InEMNLP, 2023
2023
-
[20]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InCVPR, 2024
2024
-
[22]
Visual instruction tuning.NeurIPS, 36, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.NeurIPS, 36, 2023
2023
-
[23]
Mmbench: Is your multi-modal model an all-around player? In ECCV, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? In ECCV, 2024
2024
-
[24]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Learn to explain: Multimodal reasoning via thought chains for science question answering.NeurIPS, 35, 2022
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.NeurIPS, 35, 2022
2022
-
[26]
Yijia Luo, Yulin Song, Xingyao Zhang, Jiaheng Liu, Weixun Wang, GengRu Chen, Wenbo Su, and Bo Zheng. Deconstructing long chain-of-thought: A structured reasoning optimization framework for long cot distillation.arXiv preprint arXiv:2503.16385, 2025
-
[27]
M., Ahmadi, R., Ghafouri, M., Babaei, A
Amir M Mansourian, Rozhan Ahmadi, Masoud Ghafouri, Amir Mohammad Babaei, Elaheh Badali Golezani, Zeynab Yasamani Ghamchi, Vida Ramezanian, Alireza Taherian, Kimia Dinashi, Amirali Miri, et al. A comprehensive survey on knowledge distillation.arXiv preprint arXiv:2503.12067, 2025
-
[28]
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. Orca: Progressive learning from complex explanation traces of gpt-4.arXiv preprint arXiv:2306.02707, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InICCV, 2021
2021
-
[30]
FitNets: Hints for Thin Deep Nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets.arXiv preprint arXiv:1412.6550, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[31]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github .com/tatsu-lab/stanford_alpaca, 2023
2023
-
[32]
Zephyr: Direct Distillation of LM Alignment
Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanse- viero, Alexander M. Rush, and Thomas Wolf. Zephyr: Direct distillation of lm alignment.arXiv preprint arXiv:2310.16944, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Jiaqi Wang, Haiyang Xu, Ming Yan, Ji Zhang, et al. Amber: An llm-free multi-dimensional benchmark for mllms hallucination evaluation.arXiv preprint arXiv:2311.07397, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Lingo-2: Driving with natural language
Wayve AI. Lingo-2: Driving with natural language. https://wayve.ai/thinking/lingo-2-drivi ng-with-language, 2024
2024
-
[35]
Realworldqa.https://huggingface.co/datasets/xai-org/RealworldQA, 2024
xAI. Realworldqa.https://huggingface.co/datasets/xai-org/RealworldQA, 2024
2024
-
[36]
Llava-cot: Let vision language models reason step-by-step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step. InICCV, 2025
2025
-
[37]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InCVPR, 2024
2024
-
[38]
Ddcot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models.NeurIPS, 36, 2023
Ge Zheng, Bin Yang, Jiajin Tang, Hong-Yu Zhou, and Sibei Yang. Ddcot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models.NeurIPS, 36, 2023. 11 Table of Contents 1.Dataset Construction. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 (a) Source Im...
2023
-
[39]
Do NOT ask about objects that are too small, heavily occluded, or in extreme shadow
-
[40]
Answers must be uniquely supportable by unambiguous visible evidence
-
[41]
Question Design (5 Categories; at least 2 per category)
Prefer large, salient anchors (furniture, fixtures occupying enough pixels). Question Design (5 Categories; at least 2 per category)
-
[42]
Which objects near the sink are blue?
Perception – e.g. “Which objects near the sink are blue?”; format: multiple-choice or multi-select
-
[43]
What is the direction of the plant relative to the stack of books?
Spatial Reasoning – e.g. “What is the direction of the plant relative to the stack of books?”; must involve spatial relation, may involve simple physics
-
[44]
Where is the best place to put a towel for easy access after washing hands?
Affordance Reasoning – e.g. “Where is the best place to put a towel for easy access after washing hands?”; must rely on object relationships
-
[45]
Is there any potentially unsafe or unreasonable object placement around the bathtub?
Anomaly Detection – e.g. “Is there any potentially unsafe or unreasonable object placement around the bathtub?”; open-ended but MUST be grounded in visible evidence
-
[46]
What color is the luggage rack on the roof of the car?
False Premise Rejection – inquire about an object or spatial relationship completely absent from the image as if it were present; prefer objects not visible but logically plausible in the scene (e.g. accessories on a visible object); use referring expressions tied to what is visible so the model must search the image before concluding the part/object is a...
-
[47]
Scene / room-type mismatch: question presupposes an object a reasonable person would NOT expect in this kind of room
-
[48]
inferring direction of water/ball flow from floor slope; inferring precise temperature, airflow, or sub-visible details from a normal photograph)
Unreasonable / non-commonsense reasoning: depends on physical or numerical assumptions real rooms generally do not support (e.g. inferring direction of water/ball flow from floor slope; inferring precise temperature, airflow, or sub-visible details from a normal photograph)
-
[49]
results”: [{“id
Internally inconsistent: question premise contradicts itself or the given options/answer. If NONE of the above clearly applies, do NOT mark as bad; leave it for visual verification. Default: bad_question=false. Output STRICT JSON: {“results”: [{“id”, “bad_question”: bool, “reason”: “...”}]} For Cityscapes, the structure is the same as Prompt 3b with some ...
-
[50]
If the answer is not visually annotation-supported, fix it (b) or delete (c)
Ground everything in what you SEE or what the GT labels confirm. If the answer is not visually annotation-supported, fix it (b) or delete (c)
-
[51]
Delete if the question references objects/settings clearly absent from the image or GT labels, or relies on unsupported assumptions (precise slope/flow on a level floor; unreadable text; micro-physics)
-
[52]
Camera may be tilted; mentally re-level the scene first
-
[53]
A” / “B” / “A,B
For multi-choice, keep answer as letters like “A” / “B” / “A,B”
-
[54]
Only change the answer if the fixed answer is clearly correct and supported by image + GT
-
[55]
Do not output id / type / category / etc
You may only change question / options / answer. Do not output id / type / category / etc. Cityscapes additions (same base structure; additional hard rules for street scenes):
-
[56]
the car on the right
For questions depending on a specific object/instance, DELETE or MODIFY when: - the target is TOO SMALL or too far away to be reliably identified; - the target’s SPATIAL LOCATION is ambiguous (e.g. “the car on the right” when several exist); - the target’s COLOR / identity is not clearly distinguishable (harsh lighting, 16 shadow, motion blur, JPEG). If b...
-
[57]
results”: [{“id
Do NOT discuss camera tilt; treat the view as the driver would see it. Output STRICT JSON only (all input ids must appear exactly once): {“results”: [{“id”, “bad_question”: bool, “is_modified”: bool, “question”, “answer”, “options”, “reason”}]} A.5 Step 4: Structured Field Generation and Consistency Verification After Steps 2–3 some questions have their a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.