When Gradients Collide: Failure Modes of Multi-Objective Prompt Optimization for LLM Judges
Pith reviewed 2026-06-29 21:11 UTC · model grok-4.3
The pith
Multi-objective prompt optimization for LLM judges fails due to gradient dilution at optimization and instruction interference at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
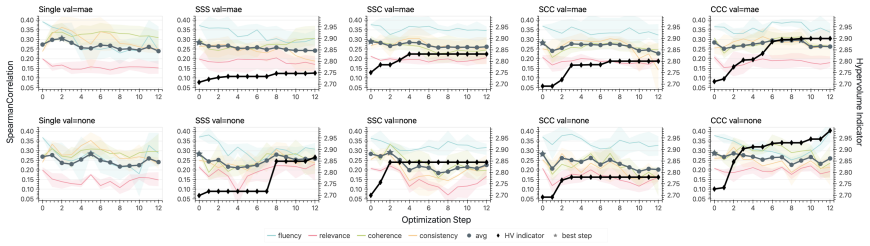
Extending TextGrad to the multi-objective setting shows that gradient task-focus drops substantially when the gradient LLM must address multiple criteria at once, and that merging single-objective optimized instructions into one prompt reduces correlation performance, identifying optimization-time gradient dilution and inference-time instruction interference as separable failure modes.
What carries the argument
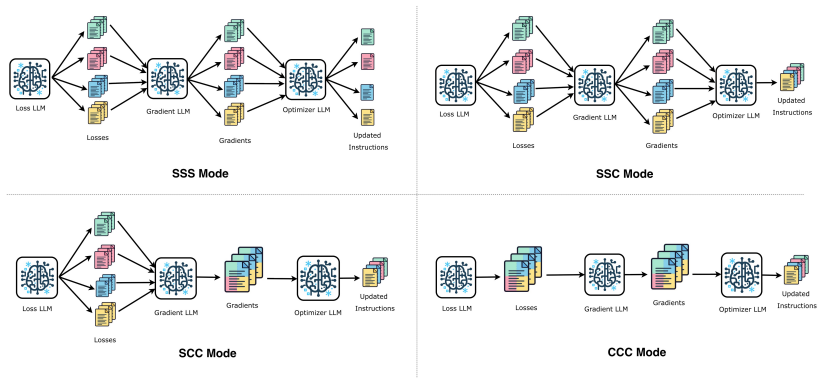
Four decomposition modes of textual gradient optimizers that vary cross-objective information sharing among the loss, gradient, and optimizer LLMs.
If this is right
- The gradient LLM's ability to focus on individual tasks decreases markedly in joint multi-objective feedback.
- Naive combination of single-objective prompts leads to degraded evaluation correlation.
- The design space for multi-objective textual gradient optimization is constrained by these two failure modes.
- Separable failure modes suggest that optimization and inference stages require distinct handling strategies.
Where Pith is reading between the lines
- Optimizers could benefit from processing objectives separately during gradient computation to avoid dilution.
- Prompt composition techniques might reduce interference when merging optimized instructions.
- Similar issues may arise in other multi-criteria LLM optimization tasks beyond judges.
Load-bearing premise
The four decomposition modes provide a valid test of multi-objective textual gradient behavior without introducing uncontrolled biases from the underlying LLMs themselves.
What would settle it
Observing no drop in gradient task-focus when using joint multi-criteria feedback, or no degradation in Spearman rho when combining single-objective prompts, would falsify the identified failure modes.
Figures

read the original abstract
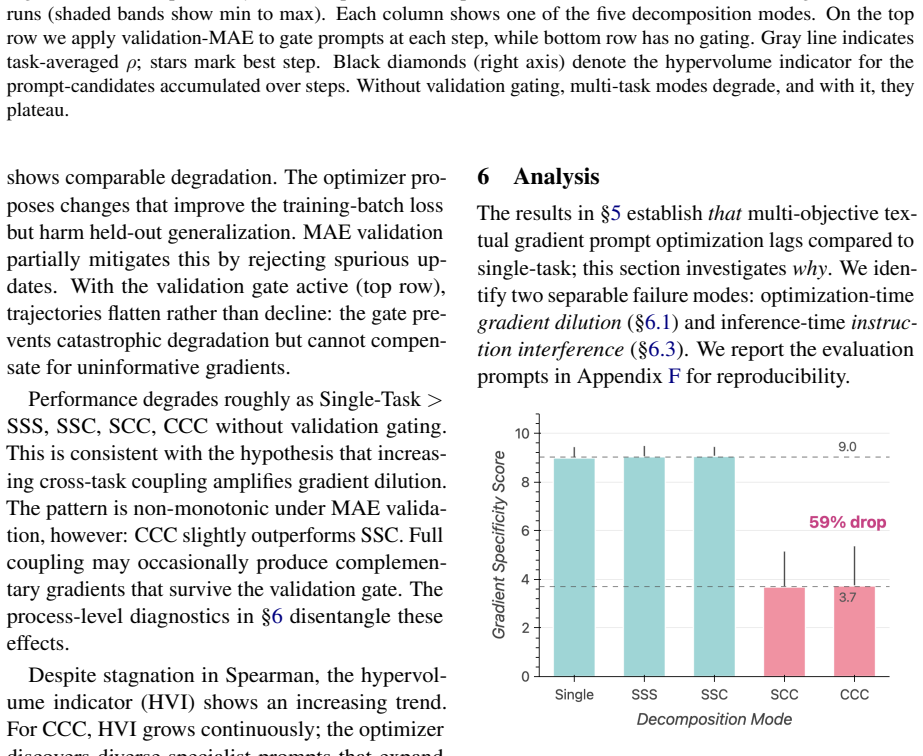
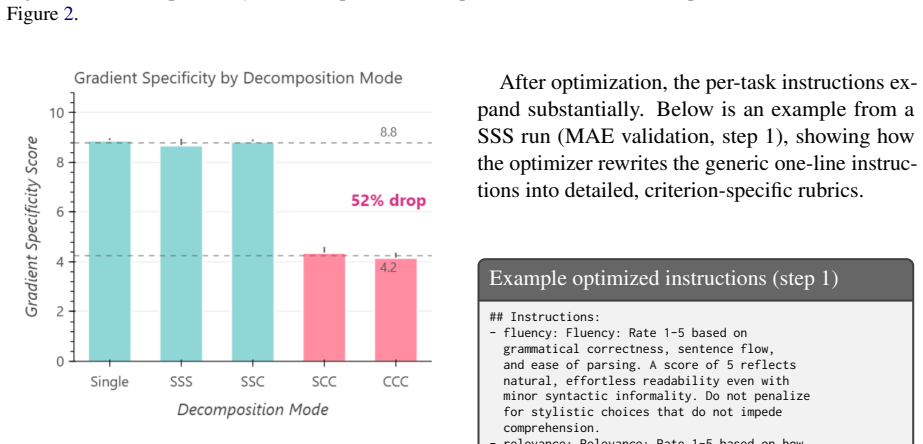
Customizing an LLM judge to a specific problem or domain often involves optimizing its prompt across multiple evaluation criteria simultaneously. Textual gradient methods automate this for a single judge criterion, however they produce natural-language critiques, not numerical vectors. Thus, the conflict-resolution toolkit of multi-task learning (PCGrad, MGDA) does not apply to this multi-objective textual gradient setting. We extend TextGrad to the multi-objective setting and test four decomposition modes of textual gradient optimizers by varying how much cross-objective information the loss, gradient and optimizer LLMs share. We find the gradient's task-focus drops by 59% (9.0 to 3.7 out of 10) when the gradient LLM must provide feedback on multiple criteria jointly. Separately, we observe that naively combining single-objective optimized instructions into a single prompt degrades Spearman rho from 0.305 to 0.220 (-0.085). These results identify two separable failure modes: optimization-time gradient dilution and inference-time instruction interference, which together constrain the design space for multi-objective judge optimization using textual feedback.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends TextGrad to multi-objective prompt optimization for LLM judges by testing four decomposition modes that vary the degree of cross-objective information sharing among the loss, gradient, and optimizer LLMs. It reports two main empirical findings: a 59% drop in the gradient LLM's task-focus score (9.0 to 3.7 out of 10) when feedback must address multiple criteria jointly, and a drop in Spearman rho from 0.305 to 0.220 when single-objective optimized instructions are naively combined at inference time. These are interpreted as separable failure modes of optimization-time gradient dilution and inference-time instruction interference that constrain the design space for multi-objective textual-gradient judge optimization.
Significance. If the reported quantitative drops prove robust after controls for base-LLM confounds, the work provides a concrete empirical constraint on multi-objective textual gradient methods, showing that standard multi-task learning conflict-resolution tools cannot be directly ported and that new mechanisms for handling objective interference in natural-language feedback are needed. The identification of two distinct failure modes (one at optimization time, one at inference time) is a useful organizing observation for future prompt-optimization research.
major comments (2)
- [Methods / Experimental Design] The central claim that the four decomposition modes isolate multi-objective textual-gradient effects rests on the untested assumption that observed drops (task-focus 9.0→3.7; rho 0.305→0.220) are not primarily caused by the base LLMs' limited ability to parse or generate multi-criterion instructions. No ablation that swaps the underlying models or validates the task-focus metric against human judgments is described, which directly undermines the attribution to gradient mechanics rather than base-model limitations.
- [Results] The quantitative results that support the two failure modes are presented without dataset descriptions, number of evaluation instances, number of optimization runs, statistical tests, or variance estimates. Because the abstract itself states these specific numbers (59% drop, -0.085 rho), the absence of these details makes it impossible to determine whether the measured effects are reliable enough to ground the design-space constraint claim.
minor comments (2)
- [Abstract / Results] The abstract and results sections should explicitly define how the task-focus score (out of 10) is computed and whether it is itself produced by an LLM judge, as this metric is load-bearing for the gradient-dilution claim.
- [Methods] Clarify the exact information-sharing protocol for each of the four decomposition modes (e.g., what text is passed between loss/gradient/optimizer LLMs) so that the modes can be reproduced or extended.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, providing the strongest honest defense of the manuscript while acknowledging where clarification or additions are warranted.
read point-by-point responses
-
Referee: [Methods / Experimental Design] The central claim that the four decomposition modes isolate multi-objective textual-gradient effects rests on the untested assumption that observed drops (task-focus 9.0→3.7; rho 0.305→0.220) are not primarily caused by the base LLMs' limited ability to parse or generate multi-criterion instructions. No ablation that swaps the underlying models or validates the task-focus metric against human judgments is described, which directly undermines the attribution to gradient mechanics rather than base-model limitations.
Authors: The four decomposition modes hold the base LLMs fixed while varying only the degree of cross-objective information sharing in the loss, gradient, and optimizer stages. Therefore, differences in task-focus (9.0 vs. 3.7) and downstream Spearman rho are attributable to the decomposition strategy rather than base-model limitations. The task-focus score is an internal rating produced by the same gradient LLM under single- versus multi-criterion prompts, providing a controlled comparison. We will revise the Methods section to state explicitly that base models are constant across conditions and to note the lack of external human validation of the task-focus metric as a limitation, with model-swap experiments planned for future work. revision: partial
-
Referee: [Results] The quantitative results that support the two failure modes are presented without dataset descriptions, number of evaluation instances, number of optimization runs, statistical tests, or variance estimates. Because the abstract itself states these specific numbers (59% drop, -0.085 rho), the absence of these details makes it impossible to determine whether the measured effects are reliable enough to ground the design-space constraint claim.
Authors: We agree that the Results section omitted these details. The revised manuscript will add: dataset descriptions, exact counts of evaluation instances, number of independent optimization runs, statistical tests performed, and variance estimates (means ± standard deviation). These additions will allow readers to evaluate the reliability of the reported 59% task-focus drop and −0.085 rho change. revision: yes
Circularity Check
No circularity: purely empirical measurements of LLM prompt optimization
full rationale
The paper reports direct experimental observations from four decomposition modes of textual gradient optimizers, measuring drops in task-focus (9.0 to 3.7) and Spearman rho (0.305 to 0.220). No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. The central claims are falsifiable empirical outcomes on specific LLM behaviors, not reductions to inputs by construction. This is self-contained empirical work with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Synthetic Data Creation with 1,000,000,000 Personas
Prediction-powered inference.Science, 382(6671):669–674. Anthropic. 2026. Introducing claude sonnet 4.6. An- thropic Blog. Jill Baumann and Oliver Kramer. 2024. Evolutionary multi-objective optimization of large language model prompts for balancing sentiments. InApplications of Evolutionary Computation (EvoApplications), pages 212–224. Springer. Pierre Bo...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
CorrSynth: A correlated sampling method for diverse dataset generation from LLMs. InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Mi- ami, FL, USA, November 12-16, 2024, pages 16076– 16095. Association for Computational Linguistics. Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. 2021....
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
VESTA: Visual Exploration with Statistical Tool Agents
Vesta: Visual exploration with statistical tool agents.Preprint, arXiv:2606.00384. Ozan Sener and Vladlen Koltun. 2018. Multi-task learn- ing as multi-objective optimization. InAdvances in Neural Information Processing Systems, volume 31. Curran Associates, Inc. Prith Sharma and Austin Z. Henley. 2026. Modular prompt optimization: Optimizing structured pr...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
J1: Incentivizing thinking in LLM-as-a-judge via reinforcement learning. InThe Fourteenth Inter- national Conference on Learning Representations. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Ji...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias
Large language models as optimizers. InIn- ternational Conference on Learning Representations, volume 2024, pages 12028–12068. Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. 2020. Gradient surgery for multi-task learning. InAd- vances in Neural Information Processing Systems, volume 33, pages 5824–5836. Curran As...
-
[6]
Consider every strength and flaw you find when making your evaluation
-
[7]
fluency": 1|2|3|4|5,
Based on the number and severity of the strengths and flaws, assign a value. Use the Instructions below to perform your evaluation. Output a JSON with the requested scores. Do NOT include reasoning or explanations. ## Output format (follow this EXACTLY): { "fluency": 1|2|3|4|5, "relevance": 1|2|3|4|5, "coherence": 1|2|3|4|5, "consistency": 1|2|3|4|5 } ## ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.