StakeBench: Evaluating Language Understanding Grounded in Market Commitment
Pith reviewed 2026-06-29 21:41 UTC · model grok-4.3
The pith
StakeBench links market comments to trading records to test whether language models recover commitment signals rather than perceived sentiment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
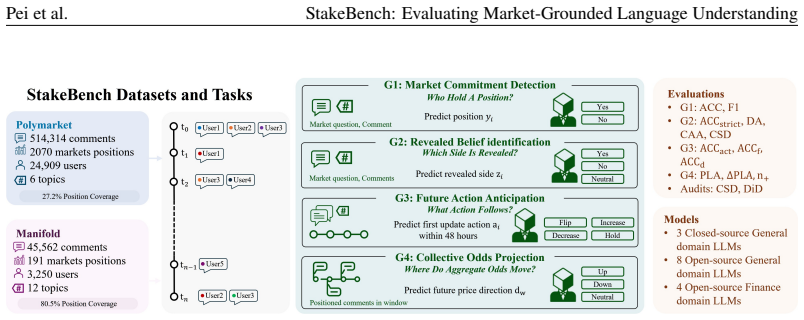
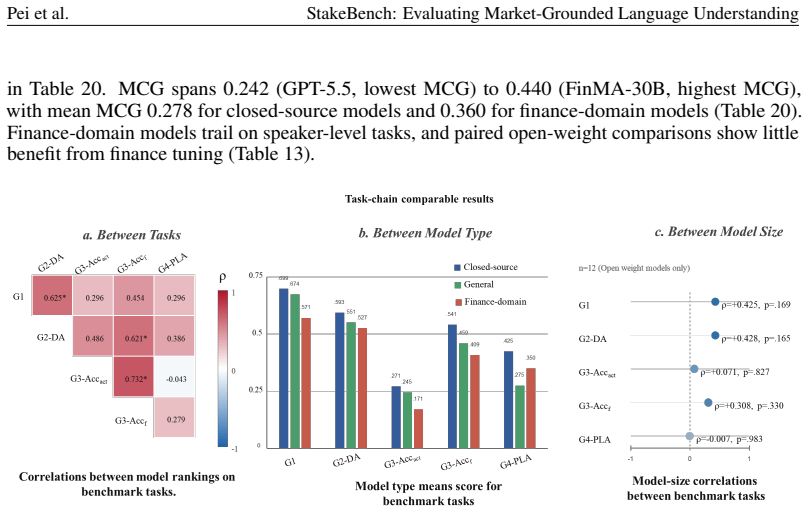
StakeBench creates four tasks from observable market records linked to comments: commitment detection, revealed-side identification, future-action anticipation, and collective odds projection. Evaluation finds partial recovery of position-side signals at Directed Accuracy 0.506–0.599 yet collapse to one or two labels in action anticipation for ten of fifteen models, with no model consistently exceeding the naive odds-direction baseline in projection. Validity audits separate these observable signals from latent belief and causal impact.
What carries the argument
StakeBench, the framework that replaces human annotation with supervision derived from verified market positions, post-comment actions, and odds trajectories after validity audits.
If this is right
- Models recover position-side signals at low accuracy but exhibit label collapse on future action anticipation.
- Finance-domain tuning does not improve identification of revealed sides.
- Platform incentives shape performance on higher-order tasks more than model scale.
- No model consistently exceeds the naive odds-direction baseline in collective projection.
Where Pith is reading between the lines
- If the benchmark holds, language-understanding evaluations could shift from perceptual labels toward behavioral outcomes as ground truth.
- The separation of observable commitment from latent belief suggests future work could test whether models trained on such data generalize to non-market commitment expressions.
- Platform-specific incentive differences imply that cross-platform generalization may require explicit modeling of market rules rather than language alone.
Load-bearing premise
Observable market positions, actions, and odds trajectories after a comment supply valid supervision for the commitment expressed in that language once validity audits have been applied.
What would settle it
A controlled experiment in which models fine-tuned on StakeBench data show consistent gains over the naive baseline on both action anticipation and odds projection across held-out markets and platforms would falsify the reported structural failures.
Figures
read the original abstract
Existing financial NLP benchmarks often rely on labels supplied by outside observers, measuring how language is perceived rather than what speakers have committed to in the market. We introduce StakeBench, an evaluation framework for language understanding grounded in market commitment. StakeBench links 560,876 comments from 2,261 resolved markets to verified position, action, and market-odds records across Polymarket and Manifold. Supervision is derived from observable market behavior. Position sides, post-comment trading actions, and market-odds trajectories replace human annotation. Four diagnostic tasks test whether models detect market commitment, identify the revealed side, anticipate future action, and perform collective odds projection. Three commitment-aware metrics measure alignment with revealed preferences rather than perceived sentiment. Validity audits and explicit interpretation boundaries help distinguish observable commitment signals from latent belief and causal market-odds impact. Across 15 LLMs and 18 topics and platform settings, models partially recover position-side signals, with Directed Accuracy from 0.506 to 0.599, but show structural failures on later tasks. Ten of the fifteen models collapse to one or two action labels in future action anticipation, and no model consistently improves on the naive odds-direction baseline in collective odds projection. Model scale is not correlated with performance, finance-domain tuning does not improve revealed-side identification, and platform incentives strongly shape higher-order results. StakeBench is packaged with evaluation code and dataset under CC-BY 4.0.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StakeBench, a benchmark linking 560,876 comments from 2,261 resolved markets on Polymarket and Manifold to verified position sides, post-comment trading actions, and odds trajectories as supervision. It defines four tasks (commitment detection, revealed-side identification, future-action anticipation, collective odds projection) and three commitment-aware metrics, with validity audits and interpretation boundaries to separate observable commitment from latent belief or causal impact. Evaluation of 15 LLMs across 18 topic/platform settings reports Directed Accuracy of 0.506-0.599 on side identification, label collapse to 1-2 actions in 10 models for anticipation, and no consistent improvement over naive odds-direction baselines for projection; scale and finance tuning show no benefit while platform incentives shape results. The dataset and code are released under CC-BY 4.0.
Significance. If the audits and linking procedure hold, the work supplies a scalable, annotation-free framework for evaluating grounded language understanding via revealed market preferences rather than perceived sentiment. It ships reproducible code and data, enabling direct verification of the per-model results and platform-effect observations. The findings on structural failures in higher-order tasks provide falsifiable evidence against assumptions of LLM market-reasoning capability.
minor comments (1)
- [Abstract] Abstract: the sentence on validity audits could briefly note the scale of the audit (e.g., number of markets reviewed or exclusion rate) to give readers immediate context before the methods section.
Simulated Author's Rebuttal
We thank the referee for their thorough summary of the paper, recognition of its significance as a scalable annotation-free framework, and recommendation for minor revision. The report contains no enumerated major comments, so we provide no point-by-point responses below. We are encouraged by the positive evaluation of the dataset release, reproducibility, and the falsifiable evidence on structural failures in higher-order tasks.
Circularity Check
No significant circularity identified
full rationale
The paper's core derivation chain obtains supervision directly from external platform records (positions, post-comment actions, odds trajectories on Polymarket and Manifold) after validity audits, with tasks and commitment-aware metrics defined in terms of those observables rather than author-fitted parameters or self-referential constructs. No equations, self-citations, or ansatzes reduce the reported metrics (Directed Accuracy, label-collapse counts, baseline comparisons) to quantities defined by the authors' own choices. The manuscript is self-contained against external benchmarks, with platform effects presented as empirical observations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Observable market positions, actions, and odds trajectories reflect speaker commitment after validity audits separate them from latent belief and causal impact
Reference graph
Works this paper leans on
-
[1]
Claude Haiku 4.5 System Card
Anthropic. Claude Haiku 4.5 System Card. https://www-cdn.anthropic.com/ 7aad69bf12627d42234e01ee7c36305dc2f6a970.pdf, 2025. Accessed: 2026-05-04
2025
-
[2]
Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal statistical society: series B (Methodological), 57(1):289–300, 1995
Yoav Benjamini and Yosef Hochberg. Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal statistical society: series B (Methodological), 57(1):289–300, 1995
1995
-
[3]
Wallstreetbets: assessing the collective intelligence of reddit for investment advice.ACM Transactions on Social Computing, 7(1-4):1–23, 2024
Tolga Buz and Gerard de Melo. Wallstreetbets: assessing the collective intelligence of reddit for investment advice.ACM Transactions on Social Computing, 7(1-4):1–23, 2024
2024
-
[4]
Daixuan Cheng, Shaohan Huang, and Furu Wei. Adapting large language models to domains via reading comprehension.arXiv preprint arXiv:2309.09530, 2023
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Llms to the moon? reddit market sentiment analysis with large language models
Xiang Deng, Vasilisa Bashlovkina, Feng Han, Simon Baumgartner, and Michael Bendersky. Llms to the moon? reddit market sentiment analysis with large language models. InCompanion Proceedings of the ACM Web Conference 2023, pages 1014–1019, 2023
2023
-
[7]
Bootstrap methods: another look at the jackknife
Bradley Efron. Bootstrap methods: another look at the jackknife. InBreakthroughs in statistics: Methodology and distribution, pages 569–593. Springer, 1992
1992
-
[8]
Strategic information transmis- sion networks.Journal of Economic Theory, 148(5):1751–1769, 2013
Andrea Galeotti, Christian Ghiglino, and Francesco Squintani. Strategic information transmis- sion networks.Journal of Economic Theory, 148(5):1751–1769, 2013
2013
-
[9]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Approaching human-level forecasting with language models.Advances in Neural Information Processing Systems, 37: 50426–50468, 2024
Danny Halawi, Fred Zhang, Chen Yueh-Han, and Jacob Steinhardt. Approaching human-level forecasting with language models.Advances in Neural Information Processing Systems, 37: 50426–50468, 2024
2024
-
[12]
Vader: A parsimonious rule-based model for sentiment analysis of social media text
Clayton Hutto and Eric Gilbert. Vader: A parsimonious rule-based model for sentiment analysis of social media text. InProceedings of the international AAAI conference on web and social media, volume 8, pages 216–225, 2014
2014
-
[13]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. URL https://arxi...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Ezra Karger, Houtan Bastani, Chen Yueh-Han, Zachary Jacobs, Danny Halawi, Fred Zhang, and Philip E Tetlock. Forecastbench: A dynamic benchmark of ai forecasting capabilities.arXiv preprint arXiv:2409.19839, 2024
-
[15]
The doge of wall street: Analysis and detection of pump and dump cryptocurrency manipulations.ACM Transac- tions on Internet Technology, 23(1):1–28, 2023
Massimo La Morgia, Alessandro Mei, Francesco Sassi, and Julinda Stefa. The doge of wall street: Analysis and detection of pump and dump cryptocurrency manipulations.ACM Transac- tions on Internet Technology, 23(1):1–28, 2023. 10 Pei et al. StakeBench: Evaluating Market-Grounded Language Understanding
2023
-
[16]
Semeval-2016 task 6: Detecting stance in tweets
Saif Mohammad, Svetlana Kiritchenko, Parinaz Sobhani, Xiaodan Zhu, and Colin Cherry. Semeval-2016 task 6: Detecting stance in tweets. InProceedings of the 10th international workshop on semantic evaluation (SemEval-2016), pages 31–41, 2016
2016
-
[17]
GPT-5.5 System Card
OpenAI. GPT-5.5 System Card. https://openai.com/index/gpt-5-5-system-card/ ,
-
[18]
Accessed: 2026-05-04
2026
-
[19]
Lingfei Qian, Weipeng Zhou, Yan Wang, Xueqing Peng, Han Yi, Yilun Zhao, Jimin Huang, Qianqian Xie, and Jian-yun Nie. Fino1: On the transferability of reasoning-enhanced llms and reinforcement learning to finance.arXiv preprint arXiv:2502.08127, 2025
-
[20]
Event2mind: Commonsense inference on events, intents, and reactions
Hannah Rashkin, Maarten Sap, Emily Allaway, Noah A Smith, and Yejin Choi. Event2mind: Commonsense inference on events, intents, and reactions. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 463–473, 2018
2018
-
[21]
Consumption theory in terms of revealed preference.Economica, 15(60): 243–253, 1948
Paul A Samuelson. Consumption theory in terms of revealed preference.Economica, 15(60): 243–253, 1948
1948
-
[22]
Social iqa: Commonsense reasoning about social interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social iqa: Commonsense reasoning about social interactions. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 4463–4473, 2019
2019
-
[23]
Job market signaling
Michael Spence. Job market signaling. InUncertainty in economics, pages 281–306. Elsevier, 1978
1978
-
[24]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Llms can teach themselves to better predict the future.arXiv preprint arXiv:2502.05253, 2025
Benjamin Turtel, Danny Franklin, and Philipp Schoenegger. Llms can teach themselves to better predict the future.arXiv preprint arXiv:2502.05253, 2025
-
[26]
Pixiu: A comprehensive benchmark, instruction dataset and large language model for finance.Advances in Neural Information Processing Systems, 36:33469–33484, 2023
Qianqian Xie, Weiguang Han, Xiao Zhang, Yanzhao Lai, Min Peng, Alejandro Lopez-Lira, and Jimin Huang. Pixiu: A comprehensive benchmark, instruction dataset and large language model for finance.Advances in Neural Information Processing Systems, 36:33469–33484, 2023
2023
-
[27]
Finben: A holistic financial benchmark for large language models.Advances in Neural Information Processing Systems, 37:95716–95743, 2024
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, et al. Finben: A holistic financial benchmark for large language models.Advances in Neural Information Processing Systems, 37:95716–95743, 2024
2024
-
[28]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Yi Yang, Mark Christopher Siy Uy, and Allen Huang. Finbert: A pretrained language model for financial communications.arXiv preprint arXiv:2006.08097, 2020
-
[30]
Sentiment analysis in the era of large language models: A reality check
Wenxuan Zhang, Yue Deng, Bing Liu, Sinno Pan, and Lidong Bing. Sentiment analysis in the era of large language models: A reality check. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 3881–3906, 2024
2024
-
[31]
wordle”, “nyt crossword
Andy Zou, Tristan Xiao, Ryan Jia, Joe Kwon, Mantas Mazeika, Richard Li, Dawn Song, Jacob Steinhardt, Owain Evans, and Dan Hendrycks. Forecasting future world events with neural networks.Advances in Neural Information Processing Systems, 35:27293–27305, 2022. 11 Pei et al. StakeBench: Evaluating Market-Grounded Language Understanding A Related Work Forecas...
2022
-
[32]
Price decrease = NO
Price increase = YES. Price decrease = NO
-
[33]
To the moon
"To the moon" / "mooning" = YES. "dump" / "crash" = NO
-
[34]
maybe",
Hedging language ("maybe", "could go either way") uses the abstention label
-
[35]
{question}
Pure information without directional opinion uses the abstention label. Reply with exactly ONE allowed label. F.3G 3: Future Action Anticipation You are predicting how a prediction market trader will adjust their position after making a comment. Market question: "{question}" Comment: "{text}" 19 Pei et al. StakeBench: Evaluating Market-Grounded Language U...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.