Helix4D: Complex 4D Mesh Generation
Pith reviewed 2026-06-29 22:15 UTC · model grok-4.3
The pith
Helix4D generates dynamic 4D meshes from video by anchoring cross-frame attention on the first frame and repurposing spatial position bands for time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
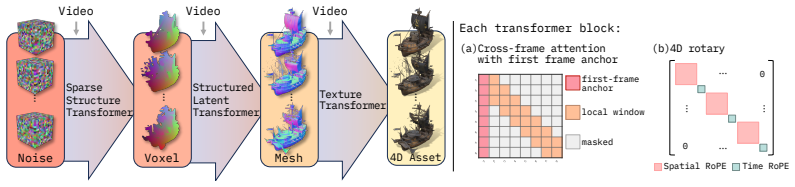
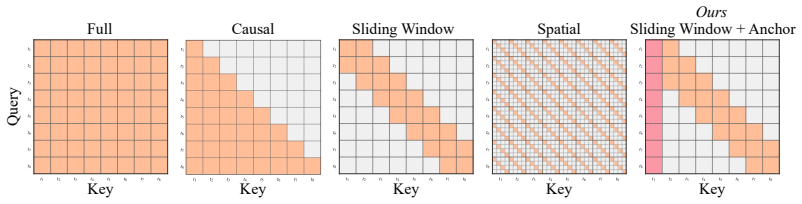
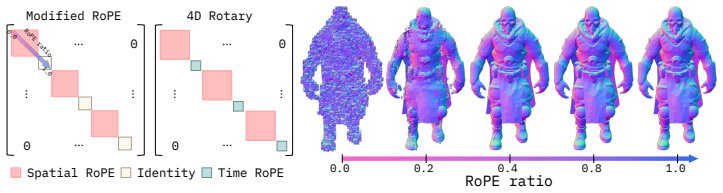
Helix4D enables high-quality dynamic mesh generation for complex topology changes, transparent materials, thin structures, and inner surfaces by using sliding-window cross-frame attention anchored on the first frame generated by the base model and a 4D temporal encoding that repurposes redundant low-frequency spatial RoPE bands.
What carries the argument
Sliding-window cross-frame attention anchored on the first generated frame, paired with repurposing of low-frequency spatial RoPE bands into a 4D temporal encoding.
If this is right
- The base model's performance on rare cases such as transparent objects transfers to the full video sequence via the anchored attention.
- Temporal information is added to the positional encoding with zero additional learned parameters.
- The resulting meshes exhibit coherent dynamics across frames on both standard action benchmarks and custom sets with complex changes.
- Inner surfaces and thin structures remain visible and consistent through the temporal extension.
Where Pith is reading between the lines
- The same anchoring and band-reuse pattern could be tested on other pretrained 3D mesh generators to check whether the quality transfer generalizes.
- The frequency-band reuse technique might extend to other sequential tasks where a pretrained spatial encoder must gain a time dimension.
- Longer video sequences would provide a direct test of whether the fixed sliding window maintains coherence without drift.
Load-bearing premise
The sliding-window cross-frame attention anchored on the first frame will transfer the base model's quality on rare cases into the video-conditioned setting without new artifacts, and the repurposed RoPE bands will add temporal information without breaking the pretrained spatial capabilities.
What would settle it
Meshes generated on videos containing transparent objects or inner surfaces show increased artifacts or lost detail relative to single-frame output from the base model alone.
Figures



read the original abstract
Current video-to-4D methods struggle with complex topology changes, transparent materials, thin structures, and inner surfaces. We present Helix4D, a dynamic mesh generation framework by inheriting the expressive representation of Trellis2, adapting it from image-to-3D to video-conditioned 4D generation. Our design arises from two key questions: (a) how to enable Trellis2's frame-local attention to share information across frames while preserving its pretrained quality on rare cases such as transparent objects and inner surfaces, and (b) how to inject temporal information into a purely 3D positional encoding without breaking pretrained capabilities. We address (a) with a sliding-window cross-frame attention and anchor on the first frame. The first frame is generated by the base Trellis2 model and injected into our model, letting it inherit Trellis2's quality in rare cases through cross-frame attention. We address (b) with a 4D temporal encoding that repurposes redundant low-frequency spatial RoPE bands for time, extending the encoding from 3D with no additional parameters. Extensive experiments show the effectiveness of Helix4D for high-quality dynamic mesh generation on ActionBench and our own challenging complex dynamics set.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Helix4D, a video-conditioned 4D dynamic mesh generation framework that adapts the Trellis2 image-to-3D model. It introduces a sliding-window cross-frame attention mechanism anchored on the first frame (generated unmodified by Trellis2) to share information across frames while preserving quality on rare cases such as transparent objects and inner surfaces, together with a parameter-free 4D temporal encoding that repurposes redundant low-frequency spatial RoPE bands for time. The authors claim this enables high-quality results on complex topology changes, transparent materials, thin structures, and inner surfaces, supported by experiments on ActionBench and a custom complex-dynamics dataset.
Significance. If the central claims hold, the work would be significant for extending pretrained 3D generative models to the 4D setting without introducing new parameters or retraining, while addressing persistent failure modes (topology change, transparency, inner surfaces) that current video-to-4D methods exhibit. The explicit reuse of an external pretrained model and the parameter-free temporal encoding are concrete strengths that could be directly adopted if the anchoring mechanism proves robust.
major comments (2)
- [method description of sliding-window cross-frame attention] The central construction (abstract and method description of sliding-window cross-frame attention) anchors all subsequent frames on the first mesh produced by unmodified Trellis2. For the claim of successful transfer under complex topology changes to hold, this anchor must remain informative even when later frames exhibit different topology or visibility; the manuscript supplies no ablation that removes or perturbs the anchor (while retaining video conditioning) to test whether cross-frame attention can recover from a topologically mismatched first frame.
- [Abstract and experimental section] The abstract states that 'extensive experiments show the effectiveness' yet supplies no quantitative metrics, error analysis, ablation tables, or comparison numbers. Without these data it is impossible to assess whether the proposed components actually improve over the Trellis2 baseline or over existing video-to-4D baselines on the claimed failure cases.
minor comments (2)
- [Experimental setup] The custom 'challenging complex dynamics set' is mentioned but its construction, size, and selection criteria are not described, preventing reproducibility.
- [4D temporal encoding description] Notation for the repurposed RoPE bands (which frequencies are reassigned to time, how the 4D positional encoding is formed) should be made explicit with an equation or pseudocode.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on the anchoring mechanism and the lack of quantitative evaluation. We address each major comment below and commit to revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: The central construction anchors all subsequent frames on the first mesh produced by unmodified Trellis2. For the claim of successful transfer under complex topology changes to hold, this anchor must remain informative even when later frames exhibit different topology or visibility; the manuscript supplies no ablation that removes or perturbs the anchor (while retaining video conditioning) to test whether cross-frame attention can recover from a topologically mismatched first frame.
Authors: We agree that an ablation perturbing or removing the anchor would provide stronger evidence for the robustness of the cross-frame attention under topology changes. The current design intentionally uses the unmodified Trellis2 output for the first frame to preserve quality on rare cases. In the revised manuscript, we will include an ablation study that replaces the first frame with a perturbed version or a frame from a different model while keeping video conditioning, to demonstrate recovery capability. revision: yes
-
Referee: The abstract states that 'extensive experiments show the effectiveness' yet supplies no quantitative metrics, error analysis, ablation tables, or comparison numbers. Without these data it is impossible to assess whether the proposed components actually improve over the Trellis2 baseline or over existing video-to-4D baselines on the claimed failure cases.
Authors: The manuscript currently emphasizes qualitative results on challenging cases like topology changes and transparency, as these are the key failure modes addressed. However, we acknowledge the value of quantitative metrics for objective assessment. We will add quantitative comparisons against Trellis2 baseline and other video-to-4D methods on ActionBench, including metrics such as Chamfer distance for geometry and temporal consistency scores, along with ablation tables for the proposed components. revision: yes
Circularity Check
No circularity: derivation builds on external Trellis2 and introduces independent components
full rationale
The paper's central construction explicitly anchors on the unmodified external Trellis2 model to generate the first frame and then adds two new mechanisms (sliding-window cross-frame attention and repurposed RoPE bands for 4D encoding) whose definitions and claimed benefits are stated independently of the target outputs. No equation or claim reduces a fitted parameter to a renamed prediction, no load-bearing premise rests solely on self-citation, and the adaptation from image-to-3D to video-4D is presented as an engineering extension rather than a tautological redefinition. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sherwin Bahmani, Ivan Skorokhodov, Victor Rong, Gordon Wetzstein, Leonidas Guibas, Peter Wonka, Sergey Tulyakov, Jeong Joon Park, Andrea Tagliasacchi, and David B. Lindell. 4D-fy: Text-to-4D generation using hybrid score distillation sampling. InProc. CVPR, 2024. 2
2024
-
[2]
Motion 3-to-4: 3D motion reconstruction for 4D synthesis.arXiv preprint arXiv:2601.14253, 2026
Hongyuan Chen, Xingyu Chen, Youjia Zhang, Zexiang Xu, and Anpei Chen. Motion 3-to-4: 3D motion reconstruction for 4D synthesis.arXiv preprint arXiv:2601.14253, 2026. 2, 3, 4, 6, 7, 8, 14, 18
-
[3]
V2M4: 4D mesh animation reconstruction from a single monocular video
Jianqi Chen, Biao Zhang, Xiangjun Tang, and Peter Wonka. V2M4: 4D mesh animation reconstruction from a single monocular video. InProc. ICCV, 2025. 3
2025
-
[4]
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. DreamSim: Learning new dimensions of human visual similarity using synthetic data.arXiv preprint arXiv:2306.09344, 2023. 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Team Hunyuan3D, Shuhui Yang, Mingxin Yang, Yifei Feng, Xin Huang, Sheng Zhang, Zebin He, Di Luo, Haolin Liu, Yunfei Zhao, et al. Hunyuan3D 2.1: From images to high-fidelity 3D assets with production-ready PBR material.arXiv preprint arXiv:2506.15442, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Yanqin Jiang, Li Zhang, Jin Gao, Weimin Hu, and Yao Yao. Consistent4D: Consistent 360° dynamic object generation from monocular video.arXiv preprint arXiv:2311.02848, 2023. 2
-
[7]
Zeren Jiang, Chuanxia Zheng, Iro Laina, Diane Larlus, and Andrea Vedaldi. Mesh4D: 4D mesh recon- struction and tracking from monocular video.arXiv preprint arXiv:2601.05251, 2026. 2, 3, 4, 6, 7, 8, 14, 18
-
[8]
Diffuman4D: 4D consistent human view synthesis from sparse-view videos with spatio-temporal diffusion models
Yudong Jin, Sida Peng, Xuan Wang, Tao Xie, Zhen Xu, Yifan Yang, Yujun Shen, Hujun Bao, and Xiaowei Zhou. Diffuman4D: 4D consistent human view synthesis from sparse-view videos with spatio-temporal diffusion models. InProc. ICCV, 2025. 2, 3
2025
-
[9]
Hunyuan3D 2.5: Towards High-Fidelity 3D Assets Generation with Ultimate Details
Zeqiang Lai, Yunfei Zhao, Haolin Liu, Zibo Zhao, Qingxiang Lin, Huiwen Shi, Xianghui Yang, Mingxin Yang, Shuhui Yang, Yifei Feng, et al. Hunyuan3D 2.5: Towards high-fidelity 3D assets generation with ultimate details.arXiv preprint arXiv:2506.16504, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
ReRoPE: Repurposing RoPE for relative camera control.arXiv preprint arXiv:2602.08068, 2026
Chunyang Li, Yuanbo Yang, Jiahao Shao, Hongyu Zhou, Katja Schwarz, and Yiyi Liao. ReRoPE: Repurposing RoPE for relative camera control.arXiv preprint arXiv:2602.08068, 2026. 2, 4, 6
-
[11]
Step1X-3D: Towards high-fidelity and controllable generation of textured 3D assets
Weiyu Li, Xuanyang Zhang, Zheng Sun, Di Qi, Hao Li, Wei Cheng, Weiwei Cai, Shihao Wu, Jiarui Liu, Zihao Wang, et al. Step1X-3D: Towards high-fidelity and controllable generation of textured 3D assets. arXiv preprint arXiv:2505.07747, 2025. 3
-
[12]
TripoSG: High-fidelity 3D shape synthesis using large-scale rectified flow models.TPAMI, 2025
Yangguang Li, Zi-Xin Zou, Zexiang Liu, Dehu Wang, Yuan Liang, Zhipeng Yu, Xingchao Liu, Yuan-Chen Guo, Ding Liang, Wanli Ouyang, et al. TripoSG: High-fidelity 3D shape synthesis using large-scale rectified flow models.TPAMI, 2025. 3
2025
-
[13]
SS4D: Native 4D generative model via structured spacetime latents.TOG, 2025
Zhibing Li, Mengchen Zhang, Tong Wu, Jing Tan, Jiaqi Wang, and Dahua Lin. SS4D: Native 4D generative model via structured spacetime latents.TOG, 2025. 2, 3, 4, 6, 7, 8, 14
2025
-
[14]
Align your Gaussians: Text-to-4D with dynamic 3D Gaussians and composed diffusion models
Huan Ling, Seung Wook Kim, Antonio Torralba, Sanja Fidler, and Karsten Kreis. Align your Gaussians: Text-to-4D with dynamic 3D Gaussians and composed diffusion models. InProc. CVPR, 2024. 2
2024
-
[15]
Free4D: Tuning-free 4D scene generation with spatial-temporal consistency
Tianqi Liu, Zihao Huang, Zhaoxi Chen, Guangcong Wang, Shoukang Hu, Liao Shen, Huiqiang Sun, Zhiguo Cao, Wei Li, and Ziwei Liu. Free4D: Tuning-free 4D scene generation with spatial-temporal consistency. InProc. ICCV, 2025. 2, 3
2025
-
[16]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. DreamFusion: Text-to-3D using 2D diffusion.arXiv preprint arXiv:2209.14988, 2022. 2 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InProc. ICML, 2021. 8
2021
-
[19]
DreamGaussian4D: Generative 4D gaussian splatting.arXiv preprint arXiv:2312.17142, 2023
Jiawei Ren, Liang Pan, Jiaxiang Tang, Chi Zhang, Ang Cao, Gang Zeng, and Ziwei Liu. DreamGaussian4D: Generative 4D gaussian splatting.arXiv preprint arXiv:2312.17142, 2023. 2
-
[20]
L4GM: Large 4D Gaussian reconstruction model
Jiawei Ren, Kevin Xie, Ashkan Mirzaei, Hanxue Liang, Xiaohui Zeng, Karsten Kreis, Ziwei Liu, Antonio Torralba, Sanja Fidler, Seung W Kim, et al. L4GM: Large 4D Gaussian reconstruction model. InProc. NeurIPS, 2024. 3
2024
-
[21]
ActionMesh: Animated 3D mesh generation with temporal 3D diffusion
Remy Sabathier, David Novotny, Niloy J Mitra, and Tom Monnier. ActionMesh: Animated 3D mesh generation with temporal 3D diffusion. InProc. CVPR, 2026. 2, 3, 4, 6, 7, 8, 14, 18
2026
-
[22]
Text-to-4D dynamic scene generation.arXiv preprint arXiv:2301.11280, 2023
Uriel Singer, Shelly Sheynin, Adam Polyak, Oron Ashual, Iurii Makarov, Filippos Kokkinos, Naman Goyal, Andrea Vedaldi, Devi Parikh, Justin Johnson, et al. Text-to-4D dynamic scene generation.arXiv preprint arXiv:2301.11280, 2023. 2
-
[23]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 2024. 2, 5
2024
-
[24]
DimensionX: Create any 3D and 4D scenes from a single image with decoupled video diffusion
Wenqiang Sun, Shuo Chen, Fangfu Liu, Zilong Chen, Yueqi Duan, Jun Zhu, Jun Zhang, and Yikai Wang. DimensionX: Create any 3D and 4D scenes from a single image with decoupled video diffusion. InProc. ICCV, 2025. 2, 3
2025
-
[25]
FVD: A new metric for video generation
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. FVD: A new metric for video generation. 2019. 8
2019
-
[26]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Vidu4D: Single generated video to high-fidelity 4D reconstruction with dynamic gaussian surfels
Yikai Wang, Xinzhou Wang, Zilong Chen, Zhengyi Wang, Fuchun Sun, and Jun Zhu. Vidu4D: Single generated video to high-fidelity 4D reconstruction with dynamic gaussian surfels. InProc. NeurIPS, 2024. 2
2024
-
[28]
Barron, and Aleksander Holynski
Rundi Wu, Ruiqi Gao, Ben Poole, Alex Trevithick, Changxi Zheng, Jonathan T. Barron, and Aleksander Holynski. CAT4D: Create anything in 4D with multi-view video diffusion models. InProc. CVPR, 2025. 2, 3
2025
-
[29]
Direct3D-S2: Gigascale 3D generation made easy with spatial sparse attention
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Yikang Yang, Yajie Bao, Jiachen Qian, Siyu Zhu, Xun Cao, Philip Torr, et al. Direct3D-S2: Gigascale 3D generation made easy with spatial sparse attention. arXiv preprint arXiv:2505.17412, 2025. 3
-
[30]
Native and Compact Structured Latents for 3D Generation
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, et al. Native and compact structured latents for 3D generation.arXiv preprint arXiv:2512.14692, 2025. 2, 3, 5, 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Structured 3D latents for scalable and versatile 3D generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3D latents for scalable and versatile 3D generation. InProc. CVPR, 2025. 3
2025
-
[33]
ULIP: Learning a unified representation of language, images, and point clouds for 3D understanding
Le Xue, Mingfei Gao, Chen Xing, Roberto Martín-Martín, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. ULIP: Learning a unified representation of language, images, and point clouds for 3D understanding. InProc. CVPR, 2023. 2, 8
2023
-
[34]
SV4D 2.0: Enhancing spatio-temporal consistency in multi-view video diffusion for high-quality 4D generation
Chun-Han Yao, Yiming Xie, Vikram V oleti, Huaizu Jiang, and Varun Jampani. SV4D 2.0: Enhancing spatio-temporal consistency in multi-view video diffusion for high-quality 4D generation. InProc. ICCV,
-
[35]
ShapeGen4D: Towards high quality 4D shape generation from videos
Jiraphon Yenphraphai, Ashkan Mirzaei, Jianqi Chen, Jiaxu Zou, Sergey Tulyakov, Raymond A Yeh, Peter Wonka, and Chaoyang Wang. ShapeGen4D: Towards high quality 4D shape generation from videos. In Proc. ICLR, 2026. 2, 3, 4, 6, 7, 8, 14
2026
-
[36]
Sculpt4D: Generating 4D Shapes via Sparse-Attention Diffusion Transformers
Minghao Yin, Wenbo Hu, Jiale Xu, Ying Shan, and Kai Han. Sculpt4D: Generating 4D shapes via sparse-attention diffusion transformers.arXiv preprint arXiv:2604.21592, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Yuyang Yin, Dejia Xu, Zhangyang Wang, Yao Zhao, and Yunchao Wei. 4DGen: Grounded 4D content generation with spatial-temporal consistency.arXiv preprint arXiv:2312.17225, 2023. 2
-
[38]
GAvatar: Animatable 3D Gaussian avatars with implicit mesh learning
Ye Yuan, Xueting Li, Yangyi Huang, Shalini De Mello, Koki Nagano, Jan Kautz, and Umar Iqbal. GAvatar: Animatable 3D Gaussian avatars with implicit mesh learning. InProc. CVPR, 2024. 2
2024
-
[39]
STAG4D: Spatial-temporal anchored generative 4D gaussians
Yifei Zeng, Yanqin Jiang, Siyu Zhu, Yuanxun Lu, Youtian Lin, Hao Zhu, Weiming Hu, Xun Cao, and Yao Yao. STAG4D: Spatial-temporal anchored generative 4D gaussians. InProc. ECCV, 2024. 2
2024
-
[40]
3DShape2VecSet: A 3D shape represen- tation for neural fields and generative diffusion models.TOG, 2023
Biao Zhang, Jiapeng Tang, Matthias Niessner, and Peter Wonka. 3DShape2VecSet: A 3D shape represen- tation for neural fields and generative diffusion models.TOG, 2023. 3
2023
-
[41]
Bowen Zhang, Sicheng Xu, Chuxin Wang, Jiaolong Yang, Feng Zhao, Dong Chen, and Baining Guo. Gaussian variation field diffusion for high-fidelity video-to-4D synthesis.arXiv preprint arXiv:2507.23785,
-
[42]
4Diffusion: Multi-view video diffusion model for 4D generation
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, and Yu Qiao. 4Diffusion: Multi-view video diffusion model for 4D generation. InProc. NeurIPS, 2024. 2
2024
-
[43]
Yibo Zhang, Li Zhang, Rui Ma, and Nan Cao. Texverse: A universe of 3D objects with high-resolution textures.arXiv preprint arXiv:2508.10868, 2025. 6, 13
-
[44]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zibo Zhao, Zeqiang Lai, Qingxiang Lin, Yunfei Zhao, Haolin Liu, Shuhui Yang, Yifei Feng, Mingxin Yang, Sheng Zhang, Xianghui Yang, et al. Hunyuan3D 2.0: Scaling diffusion models for high resolution textured 3D assets generation.arXiv preprint arXiv:2501.12202, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
A unified approach for text- and image-guided 4D scene generation
Yufeng Zheng, Xueting Li, Koki Nagano, Sifei Liu, Otmar Hilliges, and Shalini De Mello. A unified approach for text- and image-guided 4D scene generation. InProc. CVPR, 2024. 2
2024
-
[46]
Uni3D: Exploring unified 3D representation at scale.arXiv preprint arXiv:2310.06773, 2023
Junsheng Zhou, Jinsheng Wang, Baorui Ma, Yu-Shen Liu, Tiejun Huang, and Xinlong Wang. Uni3D: Exploring unified 3D representation at scale.arXiv preprint arXiv:2310.06773, 2023. 2, 8 12 Appendix Table A1:Ablation on the RoPE ratio.We evaluate on 32 held-out objects from TexVerse [ 43]. We use the full spatial RoPE setting (ratio = 1.0) as the reference and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.