Touch-R1: Reinforcing Touch Reasoning in MLLMs
Pith reviewed 2026-06-29 18:51 UTC · model grok-4.3
The pith
Touch-R1 trains a 7B multimodal model with a GRPO reward that credits only genuine tactile inputs over removed or shuffled controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
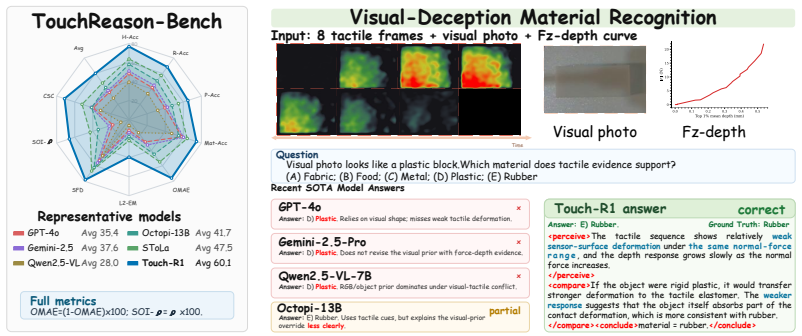
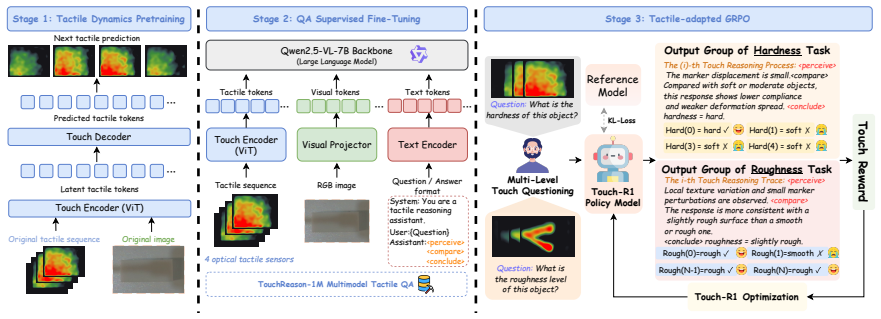
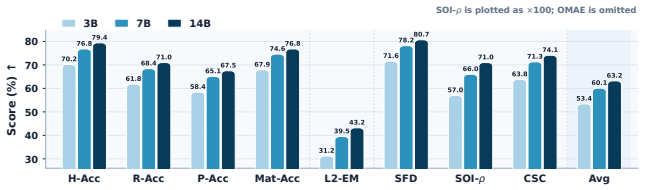
Touch-R1, built on Qwen2.5-VL-7B, is trained via a tactile-grounded GRPO objective combining ordinal-aware accuracy, cross-sensor consistency, format control, and an input-side grounding term; the tactile-use reward gives credit solely when real tactile streams improve correctness relative to removed, shuffled, or noise-masked controls. On TouchReason-Bench the resulting 7B model exceeds Octopi-13B by 18.4 percent and GPT-4o by 24.7 percent on average, with reasoning traces exhibiting emergent probing, comparison, and revision behaviors.
What carries the argument
tactile-use reward inside the GRPO objective that assigns credit only when authentic tactile inputs outperform counterfactual controls (removed, shuffled, or noise-masked)
If this is right
- Structured reasoning traces emerge that include probing, comparison, and revision steps.
- The 7B model achieves 18.4 percent higher average accuracy than Octopi-13B and 24.7 percent higher than GPT-4o on the benchmark.
- Predictions become grounded in physical contact rather than relying on potentially misleading visual priors.
- Cross-sensor physical consistency is maintained across four distinct tactile hardware types.
Where Pith is reading between the lines
- The same counterfactual-reward pattern could be tested on other sensory streams where removal or corruption of the signal is straightforward.
- Robotic systems that must resolve visual-tactile conflicts in real time might benefit from the same structured traces.
- The benchmark could serve as a diagnostic for whether vision-language models default to visual heuristics even when touch data is supplied.
Load-bearing premise
The tactile-use reward correctly forces physical grounding instead of simply rewarding patterns that happen to appear in the training data.
What would settle it
A controlled ablation in which the tactile-use reward is removed yet the model still shows the same accuracy gains and emergent behaviors on TouchReason-Bench.
Figures

read the original abstract
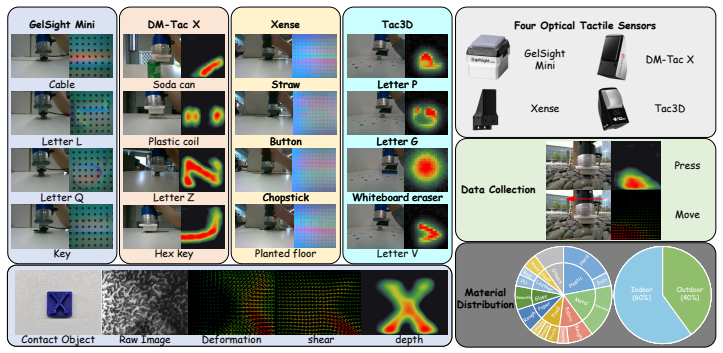
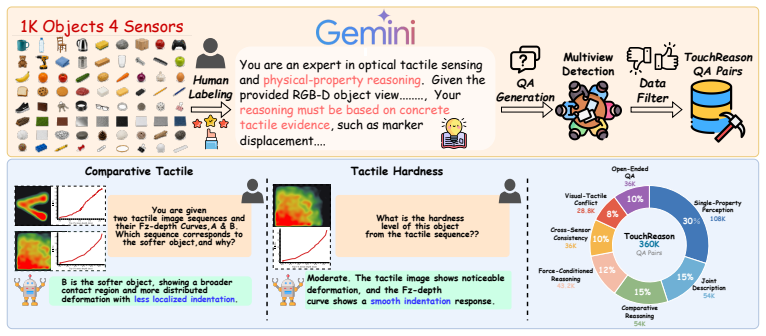
While rule-based reinforcement learning has recently catalyzed explicit reasoning in multimodal models, tactile reasoning remains largely underexplored. Existing tactile-language models primarily rely on supervised or contrastive objectives, which limits their capacity to ground predictions in physical evidence or rectify misleading visual priors. Tactile reasoning introduces two modality-specific challenges: the ordinal nature of physical attributes (e.g., hardness, roughness) and the cross-sensor distribution shifts inherent in optical tactile hardware. In this work, we introduce TouchReason-1M, a large-scale multimodal dataset comprising over 1M synchronized tactile pairs across four distinct sensors, and TouchReason-Bench, a rigorous framework for evaluating tactile perception and visual-tactile conflict resolution. Building upon these, we propose Touch-R1, a tactile reasoning MLLM based on Qwen2.5-VL-7B. Touch-R1 is trained via a tactile-grounded GRPO objective that combines ordinal-aware accuracy, cross-sensor physical consistency, structured-format control, and an input-side tactile grounding objective. Specifically, the tactile-use reward assigns credit only when authentic tactile inputs yield superior correctness relative to counterfactual controls where the tactile stream is removed, shuffled, or noise-masked. On TouchReason-Bench, Touch-R1-7B outperforms Octopi-13B by 18.4\% and GPT-4o by 24.7\% on average. Its structured reasoning traces reveal emergent behaviors of probing, comparison, and revision, demonstrating that R1-style reasoning can be effectively grounded in physical contact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the TouchReason-1M dataset (>1M synchronized tactile pairs across four sensors) and TouchReason-Bench for tactile perception and visual-tactile conflict resolution. It proposes Touch-R1 (Qwen2.5-VL-7B) trained via tactile-grounded GRPO combining ordinal-aware accuracy, cross-sensor physical consistency, structured-format control, and a tactile-use reward that assigns credit only when authentic tactile inputs outperform counterfactual controls (removed, shuffled, noise-masked). On TouchReason-Bench the 7B model outperforms Octopi-13B by 18.4% and GPT-4o by 24.7% on average and exhibits emergent probing/comparison/revision behaviors in reasoning traces.
Significance. If the central claims hold after verification of the reward mechanism, the work would be significant for demonstrating that R1-style RL can ground multimodal reasoning in ordinal physical attributes and mitigate sensor shifts, moving beyond supervised/contrastive tactile models.
major comments (2)
- [Abstract] Abstract (tactile-use reward paragraph): the design credits the policy only when correctness with real tactile exceeds the three controls, but provides no analysis showing that outperformance requires extraction of ordinal properties (hardness, roughness) rather than detection of unperturbed stream signatures (sensor noise statistics or pairing patterns in the 1M pairs). This is load-bearing for the physical-grounding claim.
- [GRPO objective] GRPO objective description: the cross-sensor consistency and ordinal-aware accuracy terms are stated to be added, but no equations or ablations demonstrate they are sufficient to block a meta-detector that recognizes authentic input distributions without consulting tactile values; the four distinct sensor distributions make this a concrete risk.
minor comments (2)
- [Results] Performance numbers (18.4%, 24.7%) are reported without error bars, statistical tests, or baseline implementation details.
- [Dataset] Dataset construction details for TouchReason-1M (synchronization across sensors, annotation protocol) are referenced but lack sufficient specificity for reproducibility.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the evidence for physical grounding in the tactile-use reward and GRPO objective.
read point-by-point responses
-
Referee: [Abstract] Abstract (tactile-use reward paragraph): the design credits the policy only when correctness with real tactile exceeds the three controls, but provides no analysis showing that outperformance requires extraction of ordinal properties (hardness, roughness) rather than detection of unperturbed stream signatures (sensor noise statistics or pairing patterns in the 1M pairs). This is load-bearing for the physical-grounding claim.
Authors: We agree that direct analysis is needed to confirm reliance on ordinal properties rather than sensor signatures. The controls (removed, shuffled, noise-masked) target information content while attempting to retain distribution cues, but we will add ablations in the revision that preserve noise statistics and pairing patterns yet disrupt ordinal values (e.g., label permutation within sensor types). These will quantify the performance drop and support the grounding claim. revision: yes
-
Referee: [GRPO objective] GRPO objective description: the cross-sensor consistency and ordinal-aware accuracy terms are stated to be added, but no equations or ablations demonstrate they are sufficient to block a meta-detector that recognizes authentic input distributions without consulting tactile values; the four distinct sensor distributions make this a concrete risk.
Authors: We acknowledge the absence of explicit equations and ablations. In the revised manuscript we will include the full mathematical formulation of the GRPO objective with each term and report ablations that isolate the cross-sensor consistency and ordinal-aware accuracy components. These will demonstrate increased vulnerability to distribution-based meta-detection when the terms are removed, addressing the risk across the four sensors. revision: yes
Circularity Check
No significant circularity; derivation introduces independent components
full rationale
The paper defines a new dataset (TouchReason-1M), benchmark (TouchReason-Bench), and GRPO objective with a tactile-use reward that credits only when real tactile inputs outperform three explicit counterfactual controls. No equations, fitted parameters renamed as predictions, or self-citations appear in the provided text that would reduce the claimed performance gains or emergent behaviors to tautological inputs. The reward construction is presented as a design choice rather than derived from prior results by the same authors. The central empirical claims rest on outperformance against external baselines (Octopi-13B, GPT-4o) on the newly introduced benchmark, which supplies an independent evaluation axis. This meets the criteria for a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Claude 3.5 Sonnet
Anthropic. Claude 3.5 Sonnet. [Online]. Available: https://www.anthropic.com/news/ claude-3-5-sonnet, 2024. Accessed: 2026-05-06
2024
-
[2]
S Bai, K Chen, X Liu, J Wang, W Ge, S Song, K Dang, P Wang, S Wang, J Tang, et al. Qwen2. 5-vl technical report (no. arxiv: 2502.13923). arxiv, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Roberto Calandra, Andrew Owens, Manu Upadhyaya, Wenzhen Yuan, Justin Lin, Edward H Adelson, and Sergey Levine. The feeling of success: Does touch sensing help predict grasp outcomes?arXiv preprint arXiv:1710.05512, 2017
-
[4]
Yi Chen, Yuying Ge, Rui Wang, Yixiao Ge, Junhao Cheng, Ying Shan, and Xihui Liu. Grpo- care: Consistency-aware reinforcement learning for multimodal reasoning.arXiv preprint arXiv:2506.16141, 2025
-
[5]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shen- glong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Stola: Self-adaptive touch-language framework for tactile commonsense reasoning in open-ended scenarios
Ning Cheng, Jinan Xu, Jialing Chen, Bin Fang, and Wenjuan Han. Stola: Self-adaptive touch-language framework for tactile commonsense reasoning in open-ended scenarios. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18198–18206, 2026
2026
-
[7]
Touch100k: A large-scale touch-language-vision dataset for touch-centric multimodal representation.Information Fusion, 124:103305, 2025
Ning Cheng, Jinan Xu, Changhao Guan, Jing Gao, Weihao Wang, You Li, Fandong Meng, Jie Zhou, Bin Fang, and Wenjuan Han. Touch100k: A large-scale touch-language-vision dataset for touch-centric multimodal representation.Information Fusion, 124:103305, 2025
2025
-
[8]
DM-Tac X
Daimon (Shenzhen) Robotics Technology Co., Ltd. DM-Tac X. [Online]. Available: https: //www.dmrobot.com/en/product/p1/dm-tac-x.html, 2026. Accessed: 2026-05-01
2026
-
[9]
Stochastic video generation with a learned prior
Emily Denton and Rob Fergus. Stochastic video generation with a learned prior. InInternational conference on machine learning, pages 1174–1183. PMLR, 2018
2018
-
[10]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Anytouch: Learning unified static-dynamic representation across multiple visuo-tactile sensors
Ruoxuan Feng, Jiangyu Hu, Wenke Xia, Tianci Gao, Ao Shen, Yuhao Sun, Bin Fang, and Di Hu. Anytouch: Learning unified static-dynamic representation across multiple visuo-tactile sensors. arXiv preprint arXiv:2502.12191, 2025
-
[12]
A touch, vision, and language dataset for multimodal alignment.arXiv preprint arXiv:2402.13232, 2024
Letian Fu, Gaurav Datta, Huang Huang, William Chung-Ho Panitch, Jaimyn Drake, Joseph Ortiz, Mustafa Mukadam, Mike Lambeta, Roberto Calandra, and Ken Goldberg. A touch, vision, and language dataset for multimodal alignment.arXiv preprint arXiv:2402.13232, 2024
-
[13]
Comparing correspondences: Video pre- diction with correspondence-wise losses
Daniel Geng, Max Hamilton, and Andrew Owens. Comparing correspondences: Video pre- diction with correspondence-wise losses. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3365–3376, 2022
2022
-
[14]
Gemini 2.5 Pro Preview 05-06
Google DeepMind. Gemini 2.5 Pro Preview 05-06. [Online]. Available: https://ai. google.dev/gemini-api/docs/models#gemini-2.5-pro-preview-05-06 , 2025. Ac- cessed: 2026-05-06
2025
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Carolina Higuera, Akash Sharma, Chaithanya Krishna Bodduluri, Taosha Fan, Patrick Lan- caster, Mrinal Kalakrishnan, Michael Kaess, Byron Boots, Mike Lambeta, Tingfan Wu, et al. Sparsh: Self-supervised touch representations for vision-based tactile sensing.arXiv preprint arXiv:2410.24090, 2024. 10
-
[17]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Xu Tang, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation.IEEE Robotics and Automation Letters, 5(3):3838–3845, 2020
Mike Lambeta, Po-Wei Chou, Stephen Tian, Brian Yang, Benjamin Maloon, Victoria Rose Most, Dave Stroud, Raymond Santos, Ahmad Byagowi, Gregg Kammerer, et al. Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation.IEEE Robotics and Automation Letters, 5(3):3838–3845, 2020
2020
-
[20]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Connecting touch and vision via cross-modal prediction
Yunzhu Li, Jun-Yan Zhu, Russ Tedrake, and Antonio Torralba. Connecting touch and vision via cross-modal prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10609–10618, 2019
2019
-
[22]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Visual-rft: Visual reinforcement fine-tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-rft: Visual reinforcement fine-tuning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2034–2044, 2025
2034
-
[24]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Photon - Tactile Sensor
Xense Robotics. Photon - Tactile Sensor. https://www.xenserobotics.com/product/ 367222/detail/15, 2025. Accessed: 2026-05-06
2025
-
[27]
Jiaer Xia, Yuhang Zang, Peng Gao, Sharon Li, and Kaiyang Zhou. Visionary-r1: Mitigating shortcuts in visual reasoning with reinforcement learning.arXiv preprint arXiv:2505.14677, 2025
-
[28]
Universal visuo-tactile video understanding for embodied interaction, 2025
Yifan Xie, Mingyang Li, Shoujie Li, Xingting Li, Guangyu Chen, Fei Ma, Fei Richard Yu, and Wenbo Ding. Universal visuo-tactile video understanding for embodied interaction, 2025
2025
-
[29]
Fengyu Yang, Chao Feng, Ziyang Chen, Hyoungseob Park, Daniel Wang, Yiming Dou, Ziyao Zeng, Xien Chen, Rit Gangopadhyay, Andrew Owens, and Alex Wong. Binding touch to everything: Learning unified multimodal tactile representations.arXiv:2401.18084, 2024
-
[30]
Touch and go: Learning from human-collected vision and touch.arXiv preprint arXiv:2211.12498, 2022
Fengyu Yang, Chenyang Ma, Jiacheng Zhang, Jing Zhu, Wenzhen Yuan, and Andrew Owens. Touch and go: Learning from human-collected vision and touch.arXiv preprint arXiv:2211.12498, 2022
-
[31]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Samson Yu, Kelvin Lin, Anxing Xiao, Jiafei Duan, and Harold Soh. Octopi: Object property reasoning with large tactile-language models.arXiv preprint arXiv:2405.02794, 2024
-
[33]
Gelsight: High-resolution robot tactile sensors for estimating geometry and force.Sensors, 17(12):2762, 2017
Wenzhen Yuan, Siyuan Dong, and Edward H Adelson. Gelsight: High-resolution robot tactile sensors for estimating geometry and force.Sensors, 17(12):2762, 2017. 11
2017
-
[34]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Lunwei Zhang, Yue Wang, and Yao Jiang. Tac3d: A novel vision-based tactile sensor for measuring forces distribution and estimating friction coefficient distribution.arXiv preprint arXiv:2202.06211, 2022
-
[36]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data, 2024.URL https://arxiv. org/abs/2410.02713, 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Jialiang Zhao, Yuxiang Ma, Lirui Wang, and Edward H Adelson. Transferable tactile transform- ers for representation learning across diverse sensors and tasks.arXiv preprint arXiv:2406.13640, 2024
-
[38]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Junyi Zong, Qingxuan Jia, Meixian Shi, Tong Li, Jiayuan Li, Zihang Lv, Gang Chen, and Fang Deng. Vitatouch: Property-aware vision-tactile-language model for robotic quality inspection in manufacturing.arXiv preprint arXiv:2604.03322, 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.