Learning When to Think While Listening in Large Audio-Language Models
Pith reviewed 2026-06-29 18:34 UTC · model grok-4.3
The pith
A controller for audio-language models learns to decide during speech when to wait, output reasoning, or answer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a learnable wait-think-answer controller, optimized over complete trajectories rather than final answers alone, can simultaneously raise accuracy and shorten visible deliberation time in streaming spoken question answering.
What carries the argument
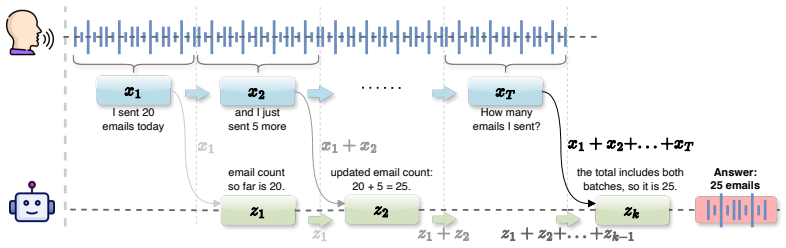
The wait-think-answer control formulation, which maps partial audio evidence to discrete actions of waiting, emitting a reasoning update, or answering.
If this is right
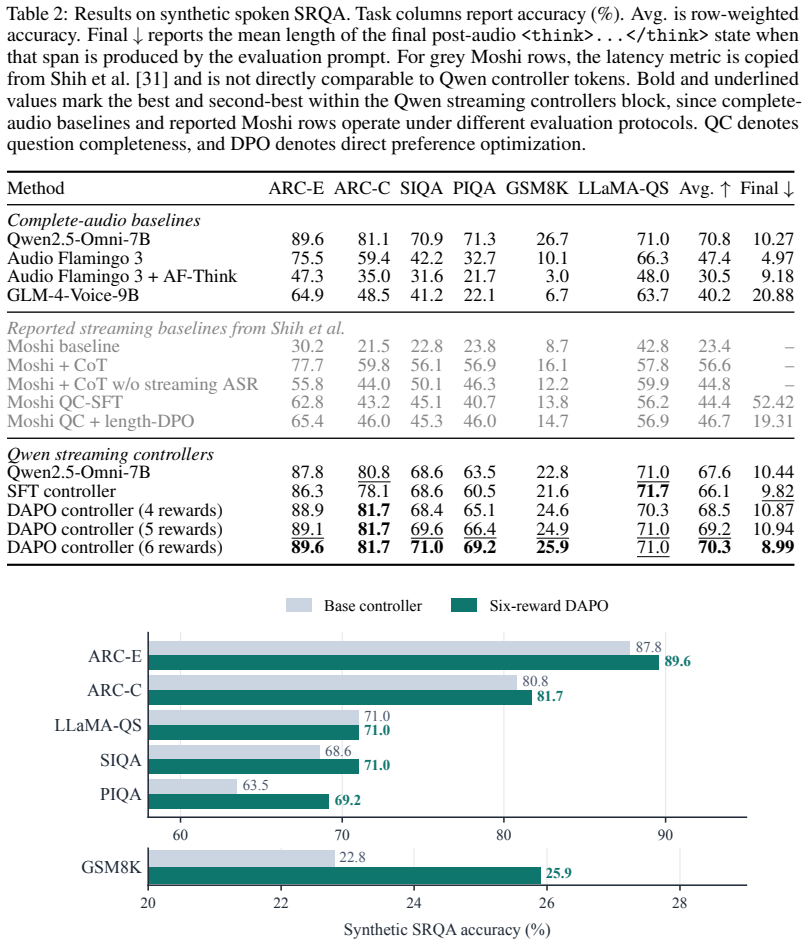
- Optimizing the full wait-think-answer trajectory improves row-weighted accuracy on synthetic spoken reasoning tasks from 67.6 percent to 70.3 percent.
- The same optimization reduces post-endpoint final-think length by 14 percent under identical deployment conditions.
- On human-recorded audio the six-reward controller is the only learned variant whose final-think length falls below the base model.
- Supervised fine-tuning alone yields the highest accuracy on real audio, while DAPO adds the latency reduction.
Where Pith is reading between the lines
- The timing controller could be applied to other streaming modalities such as video or sensor streams where evidence arrives incrementally.
- Reducing unnecessary post-endpoint reasoning steps may lower overall compute per conversation turn.
- The approach suggests that future streaming models should expose explicit intermediate reasoning as a controllable output rather than an internal process only.
Load-bearing premise
The six-part reward can be jointly optimized to produce stable controller behavior without hidden trade-offs between its components.
What would settle it
An experiment in which increasing the weight on the latency-synchronization term causes a statistically significant drop in answer correctness on held-out spoken reasoning tasks.
Figures

read the original abstract
Recent advances in Large Audio-Language Models (LALMs) have made real-time, streaming spoken interaction increasingly practical. In this setting, reasoning quality and responsiveness are tightly coupled: delaying reasoning until the speech endpoint can improve answer quality but moves deliberation into user-visible response delay, while answering too early risks committing before decisive evidence arrives. We introduce a learnable wait-think-answer control formulation for LALMs. Motivated by the incremental nature of human conversation, the controller decides under partial audio evidence when to wait, when to externalize a compact reasoning update, and when to answer. Using Qwen2.5-Omni-7B as the base model, we construct aligned wait-think-answer traces from spoken reasoning data, train the controller with supervised fine-tuning (SFT), and then apply Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO). The reward combines answer correctness, action validity, update timing, latency synchronization, reasoning quality, and chain consistency, optimizing the complete wait-think-answer trajectory and not the final answer alone. On a six-task synthetic spoken reasoning question answering (SRQA) benchmark, the six-reward DAPO controller improves the row-weighted accuracy from 67.6% to 70.3% while reducing post-endpoint final-think length by 14% under the same Qwen deployment harness. On a 186-item human-recorded Real Audio Bench, a transfer check beyond text-to-speech (TTS)-rendered speech, the controller family remains functional: SFT achieves the strongest accuracy, while the six-reward DAPO controller is the only learned variant whose final-think length falls below the base. These results suggest that a streaming model should learn when to make intermediate reasoning explicit during the audio stream.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a wait-think-answer control formulation for Large Audio-Language Models (LALMs) to manage the trade-off between reasoning quality and responsiveness in streaming spoken interactions. Using Qwen2.5-Omni-7B as base, the authors construct aligned wait-think-answer traces from spoken reasoning data, apply supervised fine-tuning (SFT), and then optimize the full trajectory with Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO) under a six-component reward (answer correctness, action validity, update timing, latency synchronization, reasoning quality, chain consistency). On a six-task synthetic spoken reasoning QA (SRQA) benchmark the six-reward DAPO controller raises row-weighted accuracy from 67.6% to 70.3% while cutting post-endpoint final-think length by 14%; a 186-item human-recorded Real Audio Bench transfer check shows the controller family remains functional, with SFT strongest on accuracy and the DAPO variant the only learned model whose final-think length falls below the base.
Significance. If the results hold, the work supplies a concrete, trajectory-level method for learning when to externalize reasoning during audio streams, directly addressing the latency-quality tension in real-time spoken systems. The explicit use of a composite reward on the complete wait-think-answer trajectory and the inclusion of a non-TTS real-audio transfer evaluation are strengths that increase the practical relevance of the findings.
major comments (2)
- [SRQA benchmark results] SRQA benchmark results: the reported gains (67.6% → 70.3% row-weighted accuracy and 14% shorter post-endpoint think length) are given without error bars, ablation tables on the six reward components, or statistical tests. This information is load-bearing for the central claim that the composite reward produces stable joint improvement rather than an artifact of weighting or task-specific scaling.
- [DAPO objective and reward definition] DAPO objective and reward definition: no per-component reward curves, sensitivity sweeps on the six reward weights, or analysis of potential Pareto conflicts are supplied. Because the optimization directly tunes the controller to the composite reward on the training distribution, the absence of these diagnostics leaves the assumption that the components admit a stable optimum without hidden trade-offs or synthetic-benchmark overfitting untested.
minor comments (2)
- [Abstract] The abstract states that the controller family 'remains functional' on the Real Audio Bench but supplies no quantitative definition of 'functional' beyond the final-think length comparison for the DAPO variant.
- [Experimental setup] The description of the six-task SRQA benchmark would benefit from an explicit table listing the tasks and their individual accuracies rather than only the row-weighted aggregate.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical relevance of the wait-think-answer formulation. Below we respond point-by-point to the two major comments, committing to concrete additions that directly address the concerns about empirical robustness.
read point-by-point responses
-
Referee: [SRQA benchmark results] SRQA benchmark results: the reported gains (67.6% → 70.3% row-weighted accuracy and 14% shorter post-endpoint think length) are given without error bars, ablation tables on the six reward components, or statistical tests. This information is load-bearing for the central claim that the composite reward produces stable joint improvement rather than an artifact of weighting or task-specific scaling.
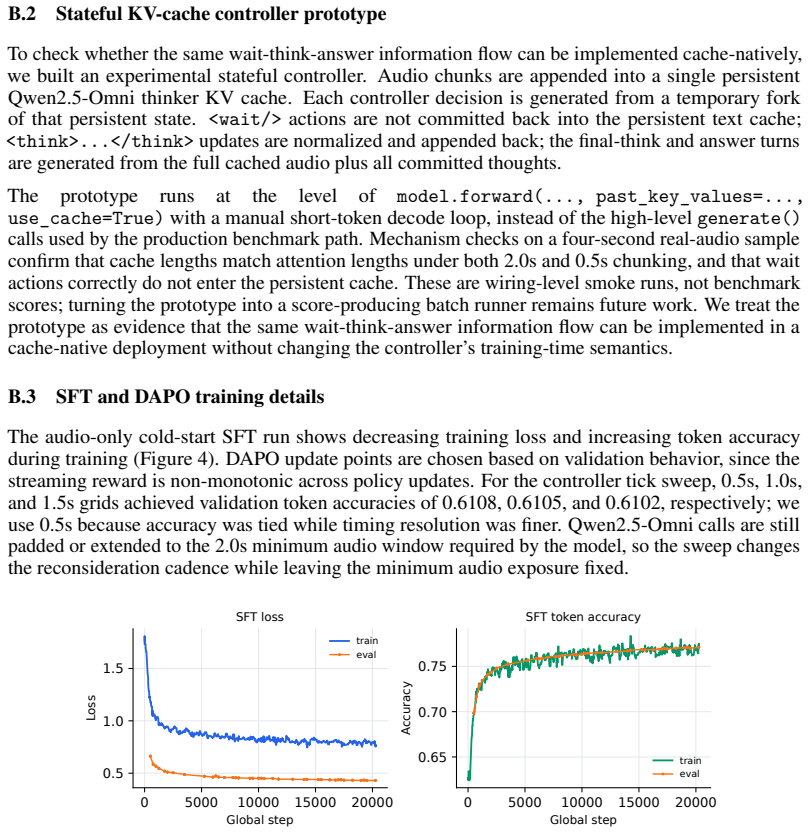
Authors: We agree that error bars, component ablations, and statistical tests are necessary to substantiate the claim of stable joint improvement. In the revised manuscript we will (i) report mean and standard error over at least three independent training runs for both accuracy and post-endpoint length, (ii) add a full ablation table that isolates each of the six reward terms, and (iii) include paired statistical tests (McNemar for accuracy, Wilcoxon signed-rank for length) across the six SRQA tasks to confirm that the observed gains are not artifacts of particular weightings or task subsets. revision: yes
-
Referee: [DAPO objective and reward definition] DAPO objective and reward definition: no per-component reward curves, sensitivity sweeps on the six reward weights, or analysis of potential Pareto conflicts are supplied. Because the optimization directly tunes the controller to the composite reward on the training distribution, the absence of these diagnostics leaves the assumption that the components admit a stable optimum without hidden trade-offs or synthetic-benchmark overfitting untested.
Authors: We acknowledge that the lack of per-component diagnostics leaves the stability of the composite optimum unverified. The revision will add (i) training curves showing the evolution of each individual reward term throughout DAPO, (ii) a sensitivity sweep over the six reward weights centered on the values used in the main experiments, and (iii) an explicit analysis of any observed trade-offs or Pareto conflicts (e.g., correctness versus latency) together with the same diagnostics evaluated on the 186-item Real Audio Bench to test for synthetic-distribution overfitting. revision: yes
Circularity Check
No significant circularity; empirical results are benchmark-validated
full rationale
The paper's central claims consist of measured accuracy and latency improvements on a held-out six-task SRQA benchmark plus a separate 186-item real-audio transfer set after SFT + DAPO training. The composite reward (correctness, validity, timing, etc.) is applied during optimization on training trajectories, but evaluation occurs on distinct test distributions with no reduction of the reported numbers to the training rewards by construction. No self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation; the method is a standard RL pipeline whose outputs are externally falsifiable on the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yi Su, Jisheng Bai, Qisheng Xu, Kele Xu, and Yong Dou. Audio-language models for audio- centric tasks: A systematic survey.arXiv preprint arXiv:2501.15177, 2025
-
[2]
Towards Holistic Evaluation of Large Audio-Language Models: A Comprehensive Survey
Chih-Kai Yang, Neo S. Ho, and Hung-yi Lee. Towards holistic evaluation of large audio- language models: A comprehensive survey.arXiv preprint arXiv:2505.15957, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Schegloff, and Gail Jefferson
Harvey Sacks, Emanuel A. Schegloff, and Gail Jefferson. A simplest systematics for the organization of turn-taking for conversation.Language, 50(4):696–735, 1974
1974
-
[4]
Tanya Stivers, N. J. Enfield, Penelope Brown, Christina Englert, Makoto Hayashi, Trine Heine- mann, Gertie Hoymann, Federico Rossano, Jan Peter de Ruiter, Kyung-Eun Yoon, and Stephen C. Levinson. Universals and cultural variation in turn-taking in conversation.Proceedings of the National Academy of Sciences, 106(26):10587–10592, 2009
2009
-
[5]
Levinson and Francisco Torreira
Stephen C. Levinson and Francisco Torreira. Timing in turn-taking and its implications for processing models of language.Frontiers in Psychology, 6:731, 2015
2015
-
[6]
Levinson
Lilla Magyari, Jan Peter de Ruiter, and Stephen C. Levinson. Temporal preparation for speaking in question-answer sequences.Frontiers in Psychology, 8:211, 2017
2017
-
[7]
Levinson
Sara Bögels, Lilla Magyari, and Stephen C. Levinson. Neural signatures of response planning occur midway through an incoming question in conversation.Scientific Reports, 5:12881, 2015
2015
-
[8]
Castellucci, Christopher K
Gregg A. Castellucci, Christopher K. Kovach, Matthew A. Howard III, Jeremy D. W. Greenlee, and Michael A. Long. A speech planning network for interactive language use.Nature, 602:117–122, 2022
2022
-
[9]
Stephens, Lauren J
Greg J. Stephens, Lauren J. Silbert, and Uri Hasson. Speaker-listener neural coupling underlies successful communication.Proceedings of the National Academy of Sciences, 107(32):14425– 14430, 2010
2010
-
[10]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Defossez, Laurent Mazare, Manu Orsini, Amelie Royer, Patrick Perez, Herve Jegou, Edouard Grave, and Neil Zeghidour. Moshi: A speech-text foundation model for real-time dialogue.arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Mini-omni: Language models can hear, talk while thinking in streaming, 2024,
Zhifei Xie and Changqiao Wu. Mini-Omni: Language models can hear, talk while thinking in streaming.arXiv preprint arXiv:2408.16725, 2024
-
[12]
Freeze-omni: A smart and low latency speech-to-speech dia- logue model with frozen llm,
Xiong Wang, Yangze Li, Chaoyou Fu, Yunhang Shen, Lei Xie, Ke Li, Xing Sun, and Long Ma. Freeze-Omni: A smart and low latency speech-to-speech dialogue model with frozen LLM. arXiv preprint arXiv:2411.00774, 2024
-
[13]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-Audio: Advancing universal audio understanding via unified large-scale audio-language models.arXiv preprint arXiv:2311.07919, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen2-Audio technical report. arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-Omni technical report.arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, and others. Qwen3-Omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Qwen3.6-35B-A3B: Agentic coding power, now open to all
Qwen Team. Qwen3.6-35B-A3B: Agentic coding power, now open to all. Hugging Face model card, 2026. URLhttps://huggingface.co/Qwen/Qwen3.6-35B-A3B. 10
2026
-
[18]
Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong Wang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, Xinyu Zhang, Pei Zhang, Baosong Yang, Jin Xu, Jingren Zhou, and Junyang Lin. Qwen3-TTS technical report.arXiv preprint arXiv:2601.15621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
OpenAI. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
Aohan Zeng, Zhengxiao Du, Mingdao Liu, Kedong Wang, Shengmin Jiang, Lei Zhao, Yuxiao Dong, and Jie Tang. GLM-4-V oice: Towards intelligent and human-like end-to-end spoken chatbot.arXiv preprint arXiv:2412.02612, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang-gil Lee, Chao- Han Huck Yang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, and Bryan Catanzaro. Audio Flamingo 3: Advancing audio intelligence with fully open large audio language models. arXiv preprint arXiv:2507.08128, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Ziyang Ma, Zhuo Chen, Yuping Wang, Eng Siong Chng, and Xie Chen. Audio-CoT: Exploring chain-of-thought reasoning in large audio language model.arXiv preprint arXiv:2501.07246, 2025
-
[23]
Audio- reasoner: Improving reasoning capability in large audio language models,
Zhifei Xie, Mingbao Lin, Zihang Liu, Pengcheng Wu, Shuicheng Yan, and Chunyan Miao. Audio-Reasoner: Improving reasoning capability in large audio language models.arXiv preprint arXiv:2503.02318, 2025
-
[24]
Audio- Thinker: Guiding audio language model when and how to think via reinforcement learning
Shu Wu, Chenxing Li, Wenfu Wang, Hao Zhang, Hualei Wang, Meng Yu, and Dong Yu. Audio- Thinker: Guiding audio language model when and how to think via reinforcement learning. arXiv preprint arXiv:2508.08039, 2025
-
[25]
Zhifeng Kong, Arushi Goel, Joao Felipe Santos, Sreyan Ghosh, Rafael Valle, Wei Ping, and Bryan Catanzaro. Audio Flamingo Sound-CoT technical report: Improving chain-of-thought reasoning in sound understanding.arXiv preprint arXiv:2508.11818, 2025
-
[26]
Cheng Wen, Tingwei Guo, Shuaijiang Zhao, Wei Zou, and Xiangang Li. SARI: Structured audio reasoning via curriculum-guided reinforcement learning.arXiv preprint arXiv:2504.15900, 2025
-
[27]
Gijs Wijngaard, Elia Formisano, Michele Esposito, and Michel Dumontier. AudSemThinker: Enhancing audio-language models through reasoning over semantics of sound.arXiv preprint arXiv:2505.14142, 2025
-
[28]
Gang Li, Jizhong Liu, Heinrich Dinkel, Yadong Niu, Junbo Zhang, and Jian Luan. Reinforce- ment learning outperforms supervised fine-tuning: A case study on audio question answering. arXiv preprint arXiv:2503.11197, 2025
-
[29]
Omni-R1: Do you really need audio to fine-tune your audio LLM?arXiv preprint arXiv:2505.09439, 2025
Andrew Rouditchenko, Saurabhchand Bhati, Edson Araujo, Samuel Thomas, Hilde Kuehne, Rogerio Feris, and James Glass. Omni-R1: Do you really need audio to fine-tune your audio LLM?arXiv preprint arXiv:2505.09439, 2025
-
[30]
Step-Audio-R1 technical report
Fei Tian, Xiangyu Tony Zhang, Yuxin Zhang, Haoyang Zhang, Yuxin Li, Daijiao Liu, Yayue Deng, Donghang Wu, Jun Chen, Liang Zhao, Chengyuan Yao, Hexin Liu, Eng Siong Chng, Xuerui Yang, Xiangyu Zhang, Daxin Jiang, and Gang Yu. Step-Audio-R1 technical report. arXiv preprint arXiv:2511.15848, 2025
-
[31]
Can speech LLMs think while listening? InInternational Conference on Learning Representations, 2026
Yi-Jen Shih, Desh Raj, Chunyang Wu, Wei Zhou, SK Bong, Yashesh Gaur, Jay Mahadeokar, Ozlem Kalinli, and Mike Seltzer. Can speech LLMs think while listening? InInternational Conference on Learning Representations, 2026
2026
-
[32]
STITCH: Simultaneous thinking and talking with chunked reasoning for spoken language models
Cheng-Han Chiang, Xiaofei Wang, Linjie Li, Chung-Ching Lin, Kevin Lin, Shujie Liu, Zhen- dong Wang, Zhengyuan Yang, Hung-yi Lee, and Lijuan Wang. STITCH: Simultaneous thinking and talking with chunked reasoning for spoken language models. InInternational Conference on Learning Representations, 2026
2026
-
[33]
Cheng-Han Chiang, Xiaofei Wang, Linjie Li, Chung-Ching Lin, Kevin Lin, Shujie Liu, Zhen- dong Wang, Zhengyuan Yang, Hung-yi Lee, and Lijuan Wang. SHANKS: Simultaneous hearing and thinking for spoken language models.arXiv preprint arXiv:2510.06917, 2025. 11
-
[34]
Junlong Tong, Yingqi Fan, Anhao Zhao, Yunpu Ma, and Xiaoyu Shen. StreamingThinker: Large language models can think while reading.arXiv preprint arXiv:2510.17238, 2025
-
[35]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, 2022
2022
-
[36]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[37]
SWIFT: A scalable lightWeight infrastructure for fine-tuning.arXiv preprint arXiv:2408.05517, 2024
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Hong Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. SWIFT: A scalable lightWeight infrastructure for fine-tuning.arXiv preprint arXiv:2408.05517, 2024
-
[38]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, and others. DeepSeek-R1: Incentivizing reasonin...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, and others. DAPO: An open-source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks
Alex Graves, Santiago Fernandez, Faustino Gomez, and Jurgen Schmidhuber. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. InProceedings of the International Conference on Machine Learning, 2006
2006
-
[42]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? Try ARC, the AI2 Reasoning Challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
PIQA: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: Reasoning about physical commonsense in natural language. InProceedings of the AAAI Conference on Artificial Intelligence, 2020
2020
-
[44]
Social IQa: Commonsense reasoning about social interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social IQa: Commonsense reasoning about social interactions. InProceedings of EMNLP-IJCNLP, 2019
2019
-
[45]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[46]
Eliya Nachmani, Alon Levkovitch, Roy Hirsch, Julian Salazar, Chulayuth Asawaroengchai, Soroosh Mariooryad, Ehud Rivlin, RJ Skerry-Ryan, and Michelle Tadmor Ramanovich. Spoken question answering and speech continuation using spectrogram-powered LLM.arXiv preprint arXiv:2305.15255, 2023. 12 A Benchmark task and data details The synthetic spoken SRQA benchma...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.