POINav: Benchmarking and Enhancing Final-Meters Arrival in Real-World Vision-Language Navigation
Pith reviewed 2026-06-29 11:46 UTC · model grok-4.3
The pith
POINav-Bench and the Brain-Action Framework enable precise POI-goal navigation in reconstructed real-world environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
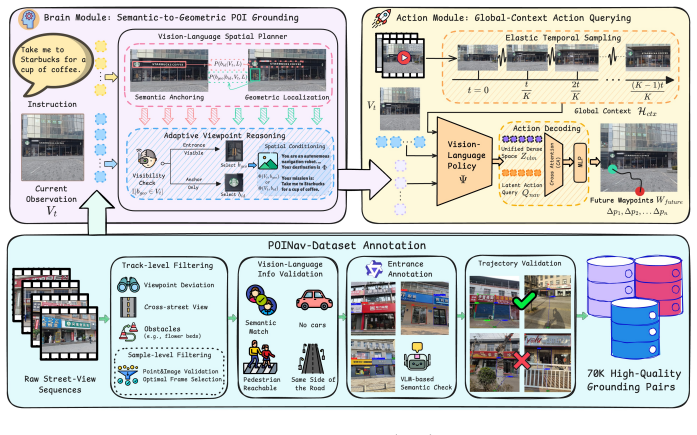
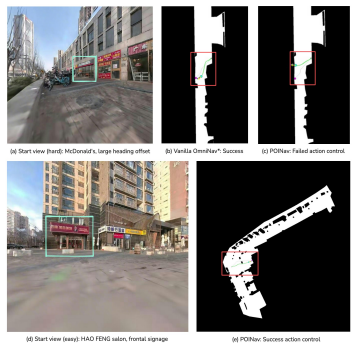
POINav-Bench provides the first closed-loop evaluation platform for real-world POI-goal navigation using high-fidelity 3DGS reconstructions of 11 commercial areas with traversability-aware annotations and reference trajectories. The POINav Brain-Action Framework employs a Brain module for POI-grounded reasoning to direct an Action module in generating continuous waypoints. Together with the POINav-Dataset of 70K real-world signage-entrance pairs, these tools demonstrate a viable approach to refining final-meters arrival in POI-rich environments.
What carries the argument
The POINav Brain-Action Framework, with its Brain module performing POI-grounded reasoning and Action module predicting continuous waypoints.
Load-bearing premise
The 3D Gaussian Splatting models of the commercial areas accurately reflect real-world traversability, lighting, and dynamic conditions so that results transfer to physical robots.
What would settle it
A physical robot executing the framework in one of the 11 commercial areas showing substantially different success rates or paths compared to its performance on the corresponding POINav-Bench reconstruction.
Figures







read the original abstract
Real-world navigation is fundamentally driven by Points of Interest (POIs), yet reaching a precise POI remains a critical "final-meters" challenge. Existing Vision-Language Navigation (VLN) benchmarks of POI-goal navigation often suffer from coarse granularity or significant sim-to-real gaps due to generated scene. To bridge this gap, we present POINav-Bench, the first benchmark designed for closed-loop evaluation of real-world POI-goal navigation. It comprises 11 commercial areas reconstructed from real-world captures using 3D Gaussian Splatting (3DGS), covering 126,398 $m^{2}$ in total and spanning 163 distinct POIs. With traversability-aware annotations and reference trajectories, POINav-Bench enables high-fidelity evaluation of navigation agents in realistic, POI-rich real-world environments. Building on this, we propose the POINav Brain-Action Framework where a Brain module performs POI-grounded reasoning to guide an Action module in predicting continuous waypoints for real-world execution. We further curate the POINav-Dataset, containing 70K real-world signage-entrance pairs. Experiments show that our framework provides a viable path toward refining real-world POI-goal navigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces POINav-Bench, the first closed-loop benchmark for real-world POI-goal navigation, consisting of 11 commercial areas (126,398 m² total) reconstructed via 3D Gaussian Splatting with traversability-aware annotations and reference trajectories spanning 163 POIs. It proposes the POINav Brain-Action Framework, in which a Brain module performs POI-grounded reasoning to guide an Action module that outputs continuous waypoints, and curates POINav-Dataset (70K real-world signage-entrance pairs). The abstract states that experiments demonstrate the framework provides a viable path toward refining real-world POI-goal navigation.
Significance. If the sim-to-real transfer holds, the benchmark and framework could meaningfully advance VLN research by supplying high-fidelity, POI-rich environments that address coarse granularity and sim-to-real gaps in existing benchmarks, with potential downstream impact on practical robotic navigation in commercial spaces. The scale of the 3DGS reconstructions and the introduction of traversability annotations represent concrete contributions to evaluation infrastructure.
major comments (1)
- [Abstract] Abstract: The central claim that the framework 'provides a viable path toward refining real-world POI-goal navigation' is load-bearing yet unsupported by any described physical robot deployment, quantitative sim-to-real comparison (success rate, trajectory error, etc.), or ablation on unmodeled factors such as dynamic obstacles, specular reflections, or fine-grained traversability (curbs, wet floors). All experiments appear confined to the benchmark, leaving the transfer assumption untested.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the major comment below and will make corresponding revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the framework 'provides a viable path toward refining real-world POI-goal navigation' is load-bearing yet unsupported by any described physical robot deployment, quantitative sim-to-real comparison (success rate, trajectory error, etc.), or ablation on unmodeled factors such as dynamic obstacles, specular reflections, or fine-grained traversability (curbs, wet floors). All experiments appear confined to the benchmark, leaving the transfer assumption untested.
Authors: We agree that the current experiments are performed within the POINav-Bench rather than on physical robots. The benchmark itself is constructed from real-world captures of 11 commercial areas (126,398 m²) using 3D Gaussian Splatting, with traversability annotations and reference trajectories derived directly from those captures; the 70K signage-entrance pairs are likewise real-world data. The Brain-Action framework is evaluated in closed-loop on this high-fidelity benchmark to demonstrate improved POI-grounded reasoning and waypoint prediction. We acknowledge that no physical robot deployment, explicit sim-to-real quantitative metrics, or ablations on dynamic obstacles, specular reflections, or fine-grained surface conditions are reported. To address this, we will revise the abstract (and relevant sections) to state that the framework shows promise on the high-fidelity real-world-derived benchmark as a concrete step toward real-world POI-goal navigation, rather than claiming direct refinement of physical systems without further validation. revision: yes
Circularity Check
No significant circularity; benchmark and framework are constructive contributions
full rationale
The paper introduces POINav-Bench (11 commercial areas via 3DGS, traversability annotations, reference trajectories) and the POINav Brain-Action Framework (Brain module for POI-grounded reasoning, Action module for waypoints) plus POINav-Dataset (70K signage-entrance pairs). No equations, fitted parameters, or derivation chains are present in the abstract or described structure. Claims rest on benchmark construction and internal experiments rather than any self-referential reduction of predictions to inputs. This is self-contained against external benchmarks with no load-bearing self-citations or ansatzes invoked.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Anderson, P., Wu, Q., Teney, D., Bruce, J., Johnson, M., Sünderhauf, N., Reid, I., Gould, S., Van Den Hengel, A.: Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3674–3683 (2018)
2018
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
ObjectNav revisited: On evaluation of embodied agents navigating to objects,
Batra, D., Gokaslan, A., Kembhavi, A., Maksymets, O., Mottaghi, R., Savva, M., Toshev, A., Wijmans, E.: Objectnav revisited: On evaluation of embodied agents navigating to objects. arXiv preprint arXiv:2006.13171 (2020)
-
[5]
arXiv preprint arXiv:2309.16634 (2023)
Bono, G., Antsfeld, L., Chidlovskii, B., Weinzaepfel, P., Wolf, C.: End-to-end (instance)-image goal navigation through correspondence as an emergent phe- nomenon. arXiv preprint arXiv:2309.16634 (2023)
-
[6]
Advances in Neural Information Processing Systems33, 4247–4258 (2020)
Chaplot, D.S., Gandhi, D.P., Gupta, A., Salakhutdinov, R.R.: Object goal navi- gation using goal-oriented semantic exploration. Advances in Neural Information Processing Systems33, 4247–4258 (2020)
2020
-
[7]
arXiv preprint arXiv:2511.21135 (2025)
Chen, Z., Guo, Y., Chu, Z., Luo, M., Shen, Y., Sun, M., Hu, J., Xie, S., Yang, K., Shi, P., et al.: Socialnav: Training human-inspired foundation model for socially- aware embodied navigation. arXiv preprint arXiv:2511.21135 (2025)
-
[8]
NaVILA: Legged robot vision-language-action model for navigation,
Cheng,A.C.,Ji,Y.,Yang,Z.,Gongye,Z.,Zou,X.,Kautz,J.,Bıyık,E.,Yin,H.,Liu, S., Wang, X.: Navila: Legged robot vision-language-action model for navigation. arXiv preprint arXiv:2412.04453 (2024)
-
[9]
ABot-N0: Technical report on the VLA foundation model for versatile embodied navigation,
Chu, Z., Xie, S., Wu, X., Shen, Y., Luo, M., Wang, Z., Liu, F., Leng, X., Hu, J., Yin, M., et al.: Abot-n0: Technical report on the vla foundation model for versatile embodied navigation. arXiv preprint arXiv:2602.11598 (2026)
-
[10]
arXiv preprint arXiv:2211.16649 (2022)
Dorbala, V.S., Sigurdsson, G., Piramuthu, R., Thomason, J., Sukhatme, G.S.: Clip-nav: Using clip for zero-shot vision-and-language navigation. arXiv preprint arXiv:2211.16649 (2022)
-
[11]
Guo, D., Wu, F., Zhu, F., Leng, F., Shi, G., Chen, H., Fan, H., Wang, J., Jiang, J., Wang, J., Chen, J., Huang, J., Lei, K., Yuan, L., Luo, L., Liu, P., Ye, Q., Qian, R., Yan, S., Zhao, S., Peng, S., Li, S., Yuan, S., Wu, S., Cheng, T., Liu, W., Wang, W., Zeng, X., Liu, X., Qin, X., Ding, X., Xiao, X., Zhang, X., Zhang, X., Xiong, X., Peng, Y., Chen, Y., ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Huang,Z.,Zhang,Y.,Liu,J.,Song,R.,Tang,C.,Ma,J.:Tic-vla:Athink-in-control vision-language-actionmodelforrobotnavigationindynamicenvironments(2026), https://arxiv.org/abs/2602.02459
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
arXiv preprint arXiv:2504.15643 (2025)
Ieong,I.T.,Tang,H.:Multimodalperceptionforgoal-orientednavigation:Asurvey. arXiv preprint arXiv:2504.15643 (2025)
-
[14]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[15]
arXiv preprint arXiv:2211.15876 (2022)
Krantz, J., Lee, S., Malik, J., Batra, D., Chaplot, D.S.: Instance-specific image goal navigation: Training embodied agents to find object instances. arXiv preprint arXiv:2211.15876 (2022)
-
[16]
In: European Confer- ence on Computer Vision
Krantz, J., Wijmans, E., Majumdar, A., Batra, D., Lee, S.: Beyond the nav-graph: Vision-and-language navigation in continuous environments. In: European Confer- ence on Computer Vision. pp. 104–120. Springer (2020)
2020
-
[17]
In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Ku, A., Anderson, P., Patel, R., Ie, E., Baldridge, J.: Room-across-room: Multi- lingual vision-and-language navigation with dense spatiotemporal grounding. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 4392–4412 (2020)
2020
-
[18]
Lin, S., Li, Z., Zhao, X., Zhou, G., Wang, L., Wei, R., Tang, R., Li, J., Wang, H., Pang, J., van den Hengel, A., Liu, J., Wu, Q.: Vlnverse: A benchmark for vision- language navigation with versatile, embodied, realistic simulation and evaluation (2025),https://arxiv.org/abs/2512.19021
-
[19]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, X., Li, J., Jiang, Y., Sujay, N., Yang, Z., Zhang, J., Abanes, J., Zhang, J., Feng, C.: Citywalker: Learning embodied urban navigation from web-scale videos. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6875–6885 (2025)
2025
-
[20]
arXiv preprint arXiv:2406.04882 (2024)
Long, Y., Cai, W., Wang, H., Zhan, G., Dong, H.: Instructnav: Zero-shot sys- tem for generic instruction navigation in unexplored environment. arXiv preprint arXiv:2406.04882 (2024)
- [21]
-
[22]
NVIDIA: Isaac Sim,https://github.com/isaac-sim/IsaacSim
- [23]
-
[24]
Team, V., Hong, W., Yu, W., Gu, X., Wang, G., Gan, G., Tang, H., Cheng, J., Qi, J., Ji, J., Pan, L., Duan, S., Wang, W., Wang, Y., Cheng, Y., He, Z., Su, Z., Yang, Z., Pan, Z., Zeng, A., Wang, B., Chen, B., Shi, B., Pang, C., Zhang, C., Yin, D., Yang, F., Chen, G., Li, H., Zhu, J., Chen, J., Xu, J., Xu, J., Chen, J., Lin, J., Chen, J., Wang, J., Chen, J.,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, R., Xu, S., Dai, C., Xiang, J., Deng, Y., Tong, X., Yang, J.: Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5261–5271 (2025)
2025
- [26]
-
[27]
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., Wang, Z., Chen, Z., Zhang, H., Yang, G., Wang, H., Wei, Q., Yin, J., Li, W., Cui, E., Chen, G., Ding, Z., Tian, C., Wu, Z., Xie, J., Li, Z., Yang, B., Duan, Y., Wang, X., Hou, Z., Hao, H., Zhang, T., Li, S., Zhao, X., Duan, H., Deng, N., Fu, B., He, Y., Wang, Y., He,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, X., Liu, Y., Song, X., Liu, Y., Zhang, S., Jiang, S.: An interactive navi- gation method with effect-oriented affordance. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16446–16456 (2024)
2024
-
[29]
Wei, M., Wan, C., Peng, J., Yu, X., Yang, Y., Feng, D., Cai, W., Zhu, C., Wang, T., Pang, J., et al.: Ground slow, move fast: A dual-system foundation model for generalizable vision-and-language navigation. arXiv preprint arXiv:2512.08186 (2025)
-
[30]
StreamVLN: Streaming vision-and-language navigation via SlowFast context model- ing,
Wei,M.,Wan,C.,Yu,X.,Wang,T.,Yang,Y.,Mao,X.,Zhu,C.,Cai,W.,Wang,H., Chen, Y., et al.: Streamvln: Streaming vision-and-language navigation via slowfast context modeling. arXiv preprint arXiv:2507.05240 (2025)
-
[31]
arXiv preprint arXiv:1911.00357 (2019)
Wijmans, E., Kadian, A., Morcos, A., Lee, S., Essa, I., Parikh, D., Savva, M., Batra, D.: Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames. arXiv preprint arXiv:1911.00357 (2019)
-
[32]
OmniNav: A unified framework for prospective exploration and visual-language navigation,
Xue, X., Hu, J., Luo, M., Xie, S., Chen, J., Xie, Z., Quan, K., Guo, W., Xu, M., Chu, Z.: Omninav: A unified framework for prospective exploration and visual- language navigation. arXiv preprint arXiv:2509.25687 (2025)
-
[33]
In: 2024 IEEE International Con- ference on Robotics and Automation (ICRA)
Yokoyama, N., Ha, S., Batra, D., Wang, J., Bucher, B.: Vlfm: Vision-language frontier maps for zero-shot semantic navigation. In: 2024 IEEE International Con- ference on Robotics and Automation (ICRA). pp. 42–48. IEEE (2024) 24
2024
-
[34]
In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Yokoyama, N., Ramrakhya, R., Das, A., Batra, D., Ha, S.: Hm3d-ovon: A dataset and benchmark for open-vocabulary object goal navigation. In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 5543–
2024
-
[35]
NavFoM: Towards a navigation foundation model for unified embodied navigation,
Zhang, J., Li, A., Qi, Y., Li, M., Liu, J., Wang, S., Liu, H., Zhou, G., Wu, Y., Li, X., et al.: Embodied navigation foundation model. arXiv preprint arXiv:2509.12129 (2025)
-
[36]
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
Zhang, J., Wang, K., Wang, S., Li, M., Liu, H., Wei, S., Wang, Z., Zhang, Z., Wang, H.: Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks. arXiv preprint arXiv:2412.06224 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhao, X., Agrawal, H., Batra, D., Schwing, A.G.: The surprising effectiveness of visual odometry techniques for embodied pointgoal navigation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 16127–16136 (2021)
2021
- [38]
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zheng, D., Huang, S., Zhao, L., Zhong, Y., Wang, L.: Towards learning a generalist model for embodied navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13624–13634 (2024) 25
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.