Where Rollouts Begin: Low-Load, High-Leverage First-Token Diversification for RLVR
Pith reviewed 2026-06-29 11:52 UTC · model grok-4.3
The pith
Uniform sampling of the first token after the reasoning marker broadens rollout diversity in RLVR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
REFT improves aggregate Pass@1, Pass@8, and Pass@64 over DAPO and GRPO baselines across four base models (0.5B-7B) and three difficulty regimes by sampling first tokens uniformly from the policy's own top-N candidates and allocating rollouts evenly.
What carries the argument
REFT, a method that samples the first token uniformly from the top-N candidates in the policy's distribution at the position right after the reasoning marker.
If this is right
- Training on the diversified rollouts yields higher pass rates at multiple evaluation budgets.
- The improvement holds across base models from 0.5B to 7B parameters.
- The same gains appear in easy, medium, and hard difficulty regimes.
- REFT adds negligible compute because only the first token choice changes.
- Every other component of the RLVR pipeline remains unchanged.
Where Pith is reading between the lines
- If the first-token effect generalizes, similar low-cost diversification could be applied at other early positions in the sequence.
- Models that already exhibit less peaked first-token distributions may see smaller gains from this approach.
- The method could be combined with existing temperature or prefix adjustments for further coverage.
- Verification cost stays the same because the number of rollouts per prompt does not increase.
Load-bearing premise
The first token after the reasoning marker is sharply peaked in probability yet largely decoupled from whether the final answer is correct.
What would settle it
Running the same RLVR training with and without REFT on the same base models and seeing no difference in final Pass@1, Pass@8, or Pass@64 scores would falsify the claim.
Figures

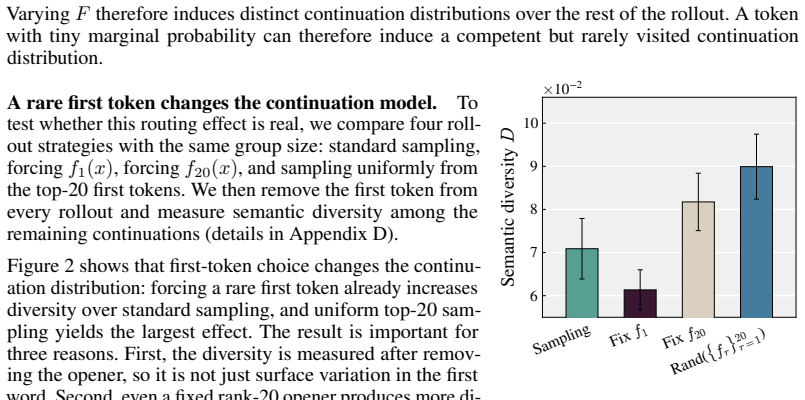
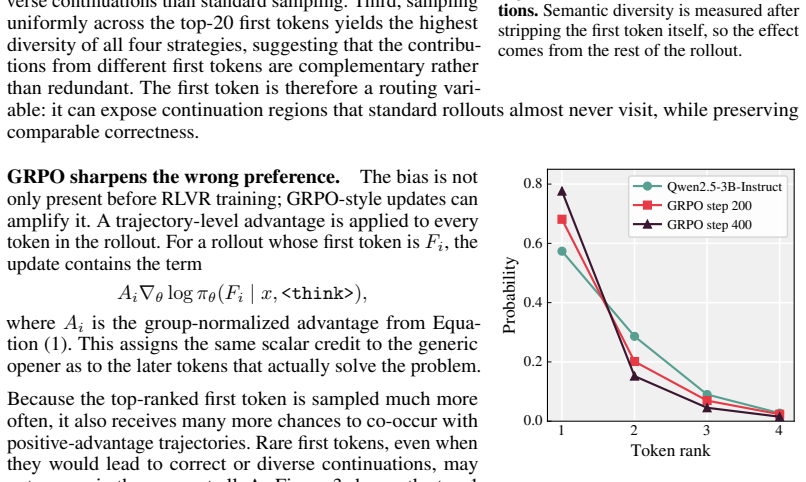
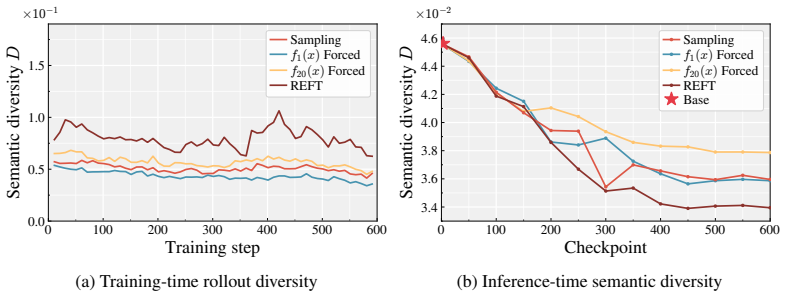
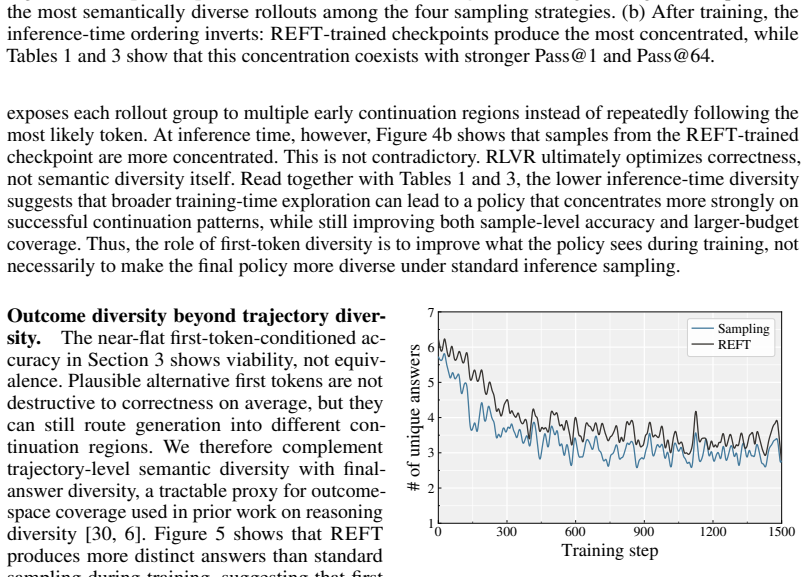
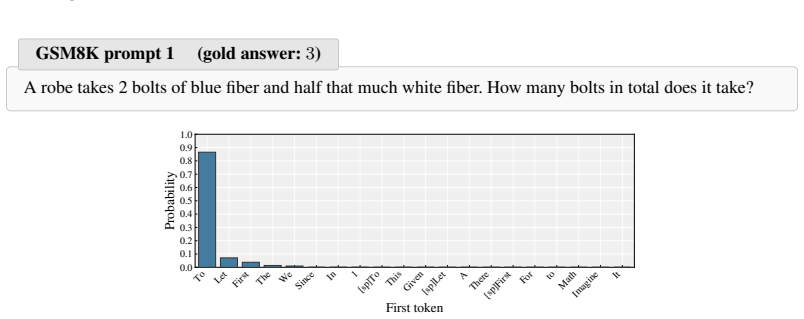
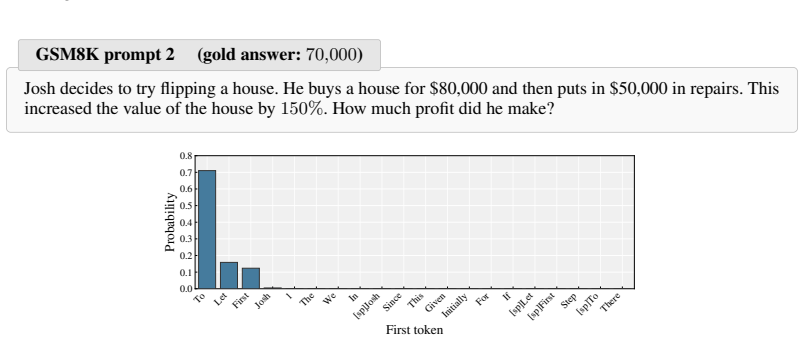
read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) trains reasoning models without labeled trajectories, relying on grouped rollouts to expose the policy to alternative reasoning paths and a verifier to score them. Rollout diversity has accordingly emerged as a central bottleneck in RLVR, with most existing methods broadening exploration through temperature, prefix, or rollout-selection adjustments. We identify a structurally distinguished but overlooked position for broadening this diversity: the first token after the reasoning marker. The policy's first-token distribution exhibits a sharply peaked yet correctness-decoupled phenomenon, and this first token position can broaden the regions a rollout group covers without altering the correctness signal. We introduce REFT (Rollout Exploration with First-Token Diversification), a light addition to the RLVR pipeline that samples first tokens uniformly from the policy's own top-$N$ candidates and allocates rollouts evenly, leaving every other component unchanged. Trained on the resulting diversified rollouts, REFT improves aggregate Pass@1, Pass@8, and Pass@64 over DAPO and GRPO baselines across four base models (0.5B-7B) and three difficulty regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in RLVR the first token after the reasoning marker exhibits a sharply peaked yet correctness-decoupled distribution. It introduces REFT, which samples first tokens uniformly from the policy's top-N candidates while allocating rollouts evenly, leaving other pipeline components unchanged. This is asserted to broaden rollout coverage without altering the correctness signal and yields improved aggregate Pass@1, Pass@8, and Pass@64 over DAPO and GRPO baselines across four base models (0.5B-7B) and three difficulty regimes.
Significance. If the decoupling holds and the gains are robust, REFT supplies a computationally light, pipeline-compatible way to increase rollout diversity at a structurally distinguished position. This directly targets a recognized bottleneck in RLVR and could be practically useful for training reasoning models, provided the empirical improvements survive controls and the assumption is measured.
major comments (2)
- [Abstract] Abstract: the central justification rests on the claim that the first-token distribution is 'sharply peaked yet correctness-decoupled,' yet the manuscript supplies no supporting measurement (correlation, mutual information, or conditional Pass rate between first-token identity and final verifier outcome). Without this datum the assertion that uniform top-N sampling preserves the reward distribution while only broadening coverage remains unsubstantiated.
- [Abstract] Abstract / experimental description: the reported consistent gains across models and regimes are presented without any information on number of runs, statistical significance testing, or controls for confounds such as effective temperature, total compute budget, or changes in the verifier-score distribution induced by the re-sampling.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on substantiating the core claim and improving experimental reporting. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central justification rests on the claim that the first-token distribution is 'sharply peaked yet correctness-decoupled,' yet the manuscript supplies no supporting measurement (correlation, mutual information, or conditional Pass rate between first-token identity and final verifier outcome). Without this datum the assertion that uniform top-N sampling preserves the reward distribution while only broadening coverage remains unsubstantiated.
Authors: We agree that the current manuscript does not provide explicit quantitative measurements to support the correctness-decoupling claim. In the revision we will add Pearson correlation, mutual information, and conditional Pass rates between first-token identity and verifier outcome, stratified across models and difficulty levels, to demonstrate that uniform top-N sampling broadens coverage without biasing the reward distribution. revision: yes
-
Referee: [Abstract] Abstract / experimental description: the reported consistent gains across models and regimes are presented without any information on number of runs, statistical significance testing, or controls for confounds such as effective temperature, total compute budget, or changes in the verifier-score distribution induced by the re-sampling.
Authors: We acknowledge that these experimental details are absent. The revised manuscript will report the number of independent runs with seeds, include statistical significance tests (e.g., paired t-tests), and add controls confirming matched effective temperature, total compute budget, and verifier-score distributions between REFT and baselines. revision: yes
Circularity Check
No significant circularity; empirical method stands on experimental results
full rationale
The paper presents REFT as a lightweight empirical modification to RLVR rollouts, asserting an observed first-token distribution property and reporting measured Pass@K gains on multiple models. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps exist that would reduce the reported improvements to re-expressions of the inputs by construction. The central justification rests on experimental outcomes rather than any mathematical reduction or ansatz smuggled via citation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The first-token distribution is sharply peaked yet correctness-decoupled
Reference graph
Works this paper leans on
-
[1]
A. Albalak, D. Phung, N. Lile, R. Rafailov, K. Gandhi, L. Castricato, A. Singh, C. Blagden, V . Xiang, D. Mahan, et al. Big-math: A large-scale, high-quality math dataset for reinforcement learning in language models.arXiv preprint arXiv:2502.17387, 2025
- [2]
- [3]
- [4]
-
[5]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
X. Dang, C. Baek, J. Z. Kolter, and A. Raghunathan. Assessing diversity collapse in reasoning. InICLR 2025 Workshop on SSI-FM, 2025
2025
-
[7]
Y . Fang, J. Lin, X. Fu, C. Qin, H. Shi, C. Hu, L. Pan, K. Zeng, and X. Cai. How to allocate, how to learn? dynamic rollout allocation and advantage modulation for policy optimization.arXiv preprint arXiv:2602.19208, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
H. Gu, H. Wang, J. Liu, L. Li, Q. Zhu, B. Liu, B. Xu, L. Wang, X. Yang, S. Lin, et al. Qarl: Rollout-aligned quantization-aware rl for fast and stable training under training–inference mismatch.arXiv preprint arXiv:2604.07853, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Z. Hou, Z. Hu, Y . Li, R. Lu, J. Tang, and Y . Dong. TreeRL: LLM reinforcement learning with on-policy tree search. InACL, 2025
2025
-
[12]
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InICLR, 2022
2022
-
[13]
J. Hu, Y . Zhang, Q. Han, D. Jiang, X. Zhang, and H.-Y . Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model. InNeurIPS, 2025
2025
-
[14]
Z. Hu, S. Zhang, Y . Li, J. Yan, X. Hu, L. Cui, X. Qu, C. Chen, Y . Cheng, and Z. Wang. Diversity-incentivized exploration for versatile reasoning. InICLR, 2026
2026
-
[15]
Huang and X
B. Huang and X. Wan. Pros: Towards compute-efficient rlvr via rollout prefix reuse. InICLR, 2026
2026
-
[16]
Huang, Y
W. Huang, Y . Ge, S. Yang, Y . Xiao, H. Mao, Y . Lin, H. Ye, S. Liu, K. C. Cheung, H. Yin, et al. Qerl: Beyond efficiency–quantization-enhanced reinforcement learning for llms. InICLR, 2026
2026
-
[17]
Where does output diversity collapse in post-training?
C. Karouzos, X. Tan, and N. Aletras. Where does output diversity collapse in post-training? arXiv preprint arXiv:2604.16027, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
R. Kirk, I. Mediratta, C. Nalmpantis, J. Luketina, E. Hambro, E. Grefenstette, and R. Raileanu. Understanding the effects of rlhf on llm generalisation and diversity. InICLR, 2024. 10
2024
-
[19]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with pagedattention. InSOSP, 2023
2023
-
[20]
T.-L. V . Le, M. Jeon, K. Vu, V . Lai, and E. Yang. No prompt left behind: Exploiting zero- variance prompts in llm reinforcement learning via entropy-guided advantage shaping. InICLR, 2026
2026
-
[21]
J. Li, E. Beeching, L. Tunstall, B. Lipkin, R. Soletskyi, S. Huang, K. Rasul, L. Yu, A. Q. Jiang, Z. Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions. https://huggingface.co/datasets/AI-MO/ NuminaMath-TIR, 2024. Hugging Face dataset repository
2024
-
[22]
Lightman, V
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. InICLR, 2024
2024
- [23]
- [24]
-
[25]
Rajbhandari, J
S. Rajbhandari, J. Rasley, O. Ruwase, and Y . He. Zero: memory optimizations toward training trillion parameter models. InSC20, 2020
2020
-
[26]
Reimers and I
N. Reimers and I. Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InEMNLP, 2019
2019
- [27]
-
[28]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
K. Song, X. Tan, T. Qin, J. Lu, and T.-Y . Liu. Mpnet: Masked and permuted pre-training for language understanding. InNeurIPS, 2020
2020
- [30]
- [31]
-
[32]
S. Wang, L. Yu, C. Gao, C. Zheng, S. Liu, R. Lu, K. Dang, X.-H. Chen, J. Yang, Z. Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning. InNeurIPS, 2025
2025
- [33]
- [34]
-
[35]
S. Xing, S. Wang, C. Yang, X. Dai, and X. Ren. Lookahead tree-based rollouts for enhanced trajectory-level exploration in reinforcement learning with verifiable rewards. InICLR, 2026
2026
-
[36]
Y . E. Xu, Y . Savani, F. Fang, and J. Z. Kolter. Not all rollouts are useful: Down-sampling rollouts in llm reinforcement learning.arXiv preprint arXiv:2504.13818, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [38]
-
[39]
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Zuo, Y . Yue, W. Dai, T. Fan, G. Liu, J. Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. InNeurIPS, 2025
2025
-
[40]
S. Yu, L. Li, W. Zhao, and Z. Yang. Erpo: Token-level entropy-regulated policy optimization for large reasoning models.arXiv preprint arXiv:2603.28204, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Y . Yue, Z. Chen, R. Lu, A. Zhao, Z. Wang, S. Song, and G. Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? InNeurIPS, 2025
2025
-
[42]
Zhang and Math-AI
Y . Zhang and Math-AI. American invitational mathematics examination (aime) 2024.https: //huggingface.co/datasets/math-ai/aime24, 2024. Hugging Face dataset repository
2024
-
[43]
Zhang and Math-AI
Y . Zhang and Math-AI. American invitational mathematics examination (aime) 2025.https: //huggingface.co/datasets/math-ai/aime25, 2025. Hugging Face dataset repository
2025
-
[44]
Improving sampling efficiency in rlvr through adaptive rollout and response reuse
Y . Zhang, W. Yao, C. Yu, Y . Liu, Q. Yin, B. Yin, H. Yun, and L. Li. Improving sampling efficiency in rlvr through adaptive rollout and response reuse.arXiv preprint arXiv:2509.25808, 2025
-
[45]
Z. Zhao, Z. Ren, J. Zou, L. Yang, Z. Xu, X. Ge, Z. Chen, X. Ma, D. Shi, S. Wang, et al. Rein- forced efficient reasoning via semantically diverse exploration.arXiv preprint arXiv:2601.05053, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Zheng, Y
H. Zheng, Y . Zhou, B. R. Bartoldson, B. Kailkhura, F. Lai, J. Zhao, and B. Chen. Act only when it pays: Efficient reinforcement learning for llm reasoning via selective rollouts. InNeurIPS, 2025
2025
-
[47]
X. Zhu, M. Xia, Z. Wei, W.-L. Chen, D. Chen, and Y . Meng. The surprising effectiveness of negative reinforcement in llm reasoning. InNeurIPS, 2025
2025
-
[48]
H. Zhuang, Y . Zhou, T. Guo, Y . Huang, F. Liu, K. Song, and X. Zhang. Exploring multi-temperature strategies for token-and rollout-level control in rlvr.arXiv preprint arXiv:2510.08892, 2025. 12 A Experimental Details A.1 RL Training and Evaluation Details We evaluate REFT as a drop-in rollout-sampling modification on top of DAPO [39] and GRPO [28]. The ...
-
[49]
John drinks water at the following times: breakfast, lunch, dinner, and before bed. 2. Therefore, John drinks water4 times a day. 3. There are 5 weekdays and 2 weekend days. 4. On weekdays: 5×4 = 20 glasses. 5. On weekends, he switches from water to soda for dinner, so he drinks3glasses each weekend day,2×3 = 6glasses. 20 + 6 = 26glasses. </think> <answer...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.