Mobile-Aptus: Confidence-Driven Proactive and Robust Interaction in MLLM-based Mobile-Using Agents
Pith reviewed 2026-06-29 12:44 UTC · model grok-4.3
The pith
Mobile-Aptus trains agents to output confidence scores and corrects their bias for balanced interaction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
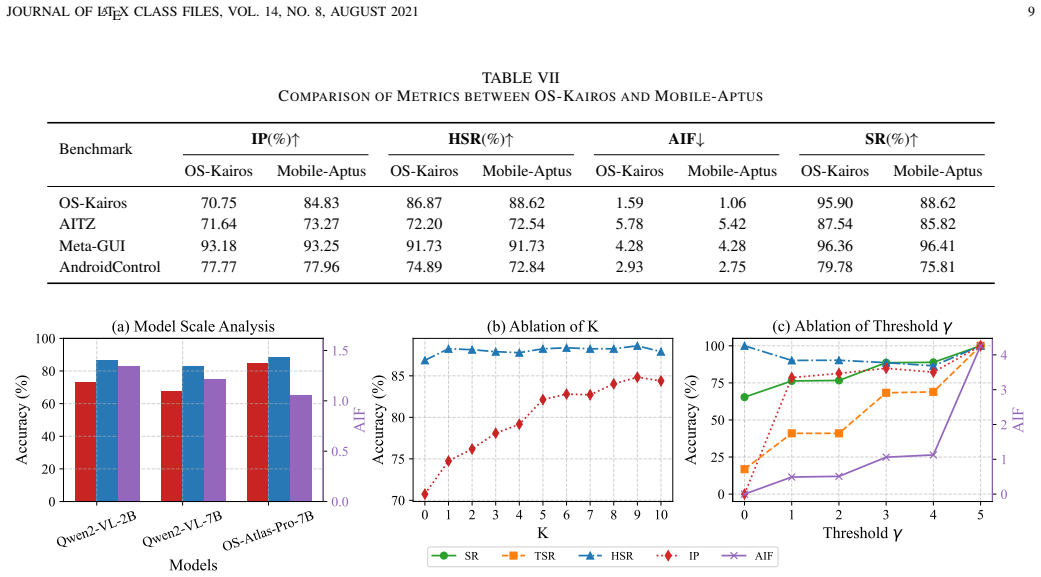
The central claim is that a universal confidence integration framework with interaction capability empowerment through supervised fine-tuning followed by confidence bias correction via semantic similarity retrieval and direct preference optimization produces agents that interact proactively and robustly, delivering state-of-the-art results on OS-Kairos, AITZ, Meta-GUI, and AndroidControl with an average task success rate gain exceeding 17 percent and a 26 percent gain in real-world dynamic tests using only 0.64 intervention steps per instruction.
What carries the argument
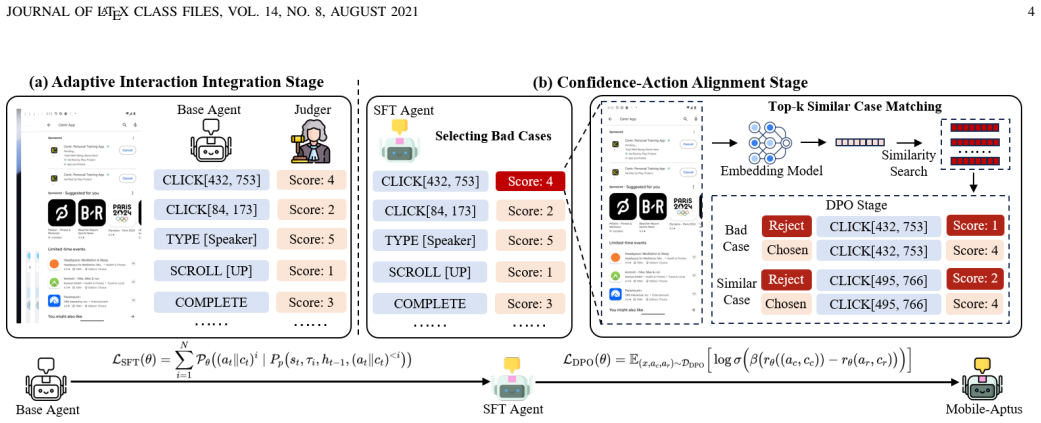
The confidence integration framework that combines supervised fine-tuning for joint action-and-confidence output with bias correction through retrieval and preference optimization.
If this is right
- Agents reach higher success rates than prior methods across the four named benchmarks.
- Average task success improves by more than 17 percent in offline evaluation.
- Real-world success exceeds the baseline by 26 percent while keeping interventions low at 0.64 steps per instruction.
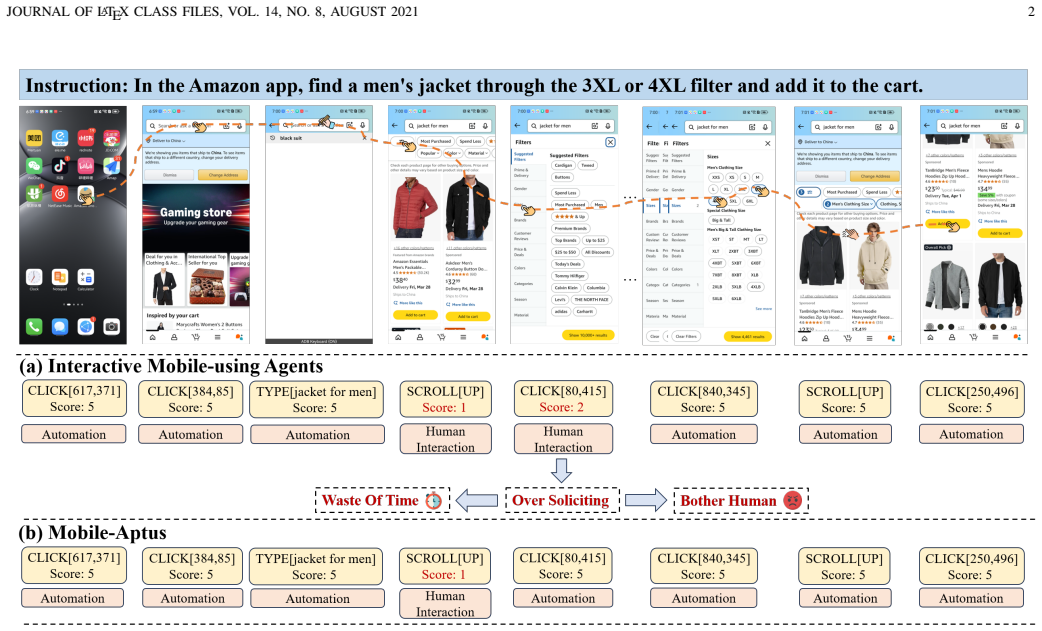
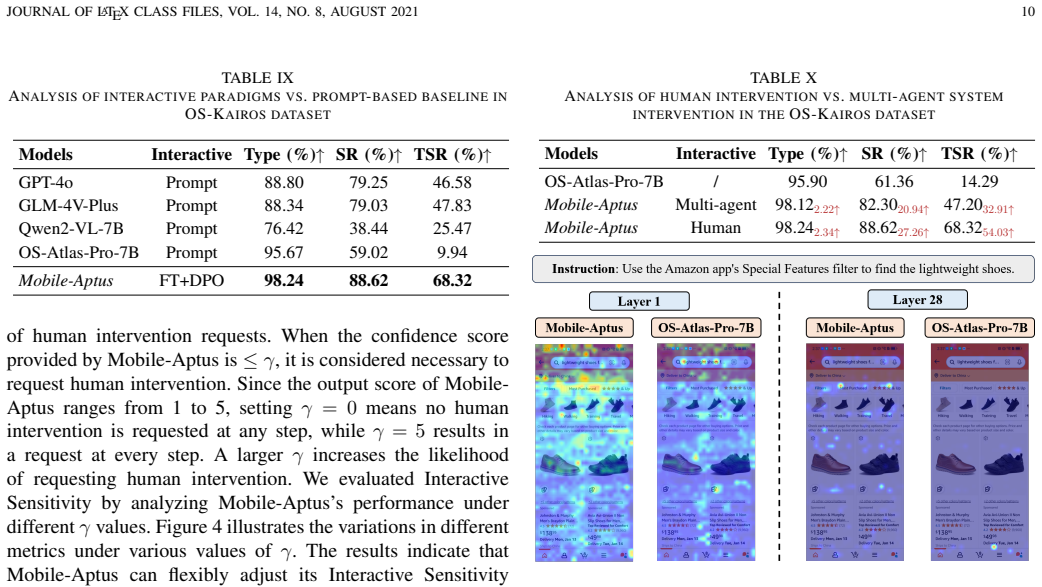
- Both excessive autonomous attempts and excessive human requests are reduced at the same time.
Where Pith is reading between the lines
- The same confidence correction steps could be tested on non-mobile agent tasks such as web navigation or robotics.
- If the scores prove reliable, they might be used to trigger other safety checks before execution begins.
- Different retrieval methods could be swapped into the bias-correction stage to measure further gains.
Load-bearing premise
The combination of supervised fine-tuning to produce confidence scores and later bias correction through retrieval and optimization will create accurate estimates that hold up on new data.
What would settle it
Run the trained agent on a fresh set of mobile tasks and check whether its reported confidence values reliably predict actual success or failure rates.
Figures

read the original abstract
Recent advancements in multimodal large language models (MLLMs) have shown exceptional potential in enabling mobile-using agents to autonomously execute human instructions. However, fully automated agents often try to execute tasks even when they are unable to resolve them, leading to the problem of over-execution. Previous studies solve it by training a interactive mobile-using agents to let agents request human interaction when agents can not complete user instructions. However, we find that these interactive agents tend to exhibit over-soliciting behavior, relying excessively on human intervention. To mitigate both over-execution and over-soliciting, we propose a universal confidence integration framework that enables confidence-driven proactive and robust interaction in MLLM-based mobile-using agents. The framework consists of two stages: interaction capability empowerment and confidence bias correction. In the interaction capability empowerment stage, agents learn through supervised fine-tuning to output both actions and confidence scores. In the confidence bias correction stage, agents learn to output more accurate confidence scores by combining semantic similarity retrieval with direct preference optimization. Experimental results show Mobile-Aptus achieves state-of-the-art performance on the four popular mobile-using agent benchmarks: OS-Kairos, AITZ, Meta-GUI, and AndroidControl. Mobile-Aptus consistently outperforms all baselines in offline benchmarks, with an average improvement over 17\% in task success rate. In real-world dynamic experiments, Mobile-Aptus surpasses the baseline by 26% in task success rate with only 0.64 intervention steps per instruction. The codes are available at https://github.com/Wuzheng02/Mobile-Aptus.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Mobile-Aptus, a two-stage framework for MLLM-based mobile-using agents. The first stage uses supervised fine-tuning to enable agents to output both actions and confidence scores. The second stage applies semantic similarity retrieval combined with direct preference optimization to correct biases in those confidence scores. The goal is to reduce both over-execution (attempting unresolvable tasks) and over-soliciting (excessive human requests). The manuscript reports state-of-the-art results on four benchmarks (OS-Kairos, AITZ, Meta-GUI, AndroidControl) with >17% average task success improvement over baselines, plus a 26% gain in real-world dynamic experiments at 0.64 intervention steps per instruction.
Significance. If the confidence estimates prove accurate and generalizable, the framework could meaningfully advance reliable mobile agents by enabling proactive, calibrated human intervention. The public code release at https://github.com/Wuzheng02/Mobile-Aptus is a positive contribution that supports reproducibility.
major comments (2)
- [Abstract] Abstract: The headline performance claims (>17% average task success improvement across four benchmarks and +26% in real-world experiments) are load-bearing for the central contribution, yet the abstract supplies no methodological details on how confidence scores were validated, no error analysis, no ablation isolating the semantic-retrieval + DPO bias-correction stage, and no quantitative evidence (e.g., calibration metrics or held-out generalization results) that the two-stage pipeline produces accurate, unbiased estimates beyond the SFT training distribution.
- [Abstract] The weakest assumption—that SFT followed by semantic-similarity retrieval + DPO yields confidence scores that generalize and reduce both over-execution and over-soliciting—is not supported by any reported validation. Without such evidence, the reported gains cannot be confidently attributed to the proposed confidence-driven interaction rather than other implementation factors.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and the validation of our confidence calibration approach. We address each point below and will revise the abstract to better summarize the supporting evidence from the full manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance claims (>17% average task success improvement across four benchmarks and +26% in real-world experiments) are load-bearing for the central contribution, yet the abstract supplies no methodological details on how confidence scores were validated, no error analysis, no ablation isolating the semantic-retrieval + DPO bias-correction stage, and no quantitative evidence (e.g., calibration metrics or held-out generalization results) that the two-stage pipeline produces accurate, unbiased estimates beyond the SFT training distribution.
Authors: We agree the abstract is concise and could better reference the validation details. The full paper describes the SFT stage in Section 3.1 and the semantic similarity retrieval + DPO bias-correction stage in Section 3.2. Section 4.3 presents ablations that isolate the contribution of the bias-correction stage, Section 4.2 reports results on four held-out benchmarks demonstrating generalization, and Section 4.5 includes error analysis on over-execution and over-soliciting rates. We will revise the abstract to add a brief clause noting the two-stage validation and the ablation-supported gains from bias correction. revision: yes
-
Referee: [Abstract] The weakest assumption—that SFT followed by semantic-similarity retrieval + DPO yields confidence scores that generalize and reduce both over-execution and over-soliciting—is not supported by any reported validation. Without such evidence, the reported gains cannot be confidently attributed to the proposed confidence-driven interaction rather than other implementation factors.
Authors: The manuscript does report supporting validation. Ablations in Section 4.3 directly compare the full two-stage model against the SFT-only baseline and show additional reductions in over-execution and over-soliciting attributable to the retrieval + DPO stage. Results on four held-out benchmarks plus the real-world dynamic experiments (0.64 intervention steps) provide evidence of generalization beyond the SFT distribution. These controlled comparisons allow attribution to the confidence-driven mechanism rather than other factors. We do not report traditional calibration metrics such as ECE, but the downstream task metrics serve as the primary validation of utility. revision: no
Circularity Check
No circularity: empirical pipeline with no derivations or self-referential equations
full rationale
The paper presents an empirical two-stage training pipeline (SFT for action+confidence, then semantic-retrieval + DPO for bias correction) and reports benchmark gains. No equations, uniqueness theorems, or derivation steps appear in the provided text. Performance claims rest on experimental results rather than any mathematical reduction that collapses to fitted inputs or self-citations by construction. The central assumption about generalization of confidence scores is an empirical claim open to falsification, not a definitional or self-referential loop. This is the normal non-circular case for applied ML papers without formal derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning, pp. 19730– 19742, PMLR, 2023
2023
-
[2]
Image as a foreign language: Beit pretraining for vision and vision-language tasks,
W. Wang, H. Bao, L. Dong, J. Bjorck, Z. Peng, Q. Liu, K. Aggarwal, O. K. Mohammed, S. Singhal, S. Som,et al., “Image as a foreign language: Beit pretraining for vision and vision-language tasks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 19175–19186, 2023
2023
-
[3]
Palm-e: An embodied multimodal language model,
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang,et al., “Palm-e: An embodied multimodal language model,” 2023
2023
-
[4]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausman,et al., “Do as i can, not as i say: Grounding language in robotic affordances,”arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” Advances in neural information processing systems, vol. 36, pp. 34892– 34916, 2023
2023
-
[6]
Unifying structure reasoning and language pre-training for complex reasoning tasks,
S. Wang, Z. Wei, J. Xu, T. Li, and Z. Fan, “Unifying structure reasoning and language pre-training for complex reasoning tasks,”IEEE ACM Trans. Audio Speech Lang. Process., vol. 32, pp. 1586–1595, 2024
2024
-
[7]
You only look at screens: Multimodal chain- of-action agents,
Z. Zhang and A. Zhang, “You only look at screens: Multimodal chain- of-action agents,” inFindings of the Association for Computational Linguistics: ACL 2024(L.-W. Ku, A. Martins, and V . Srikumar, eds.), (Bangkok, Thailand), pp. 3132–3149, Association for Computational Linguistics, Aug. 2024
2024
-
[8]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Z. Wu, Z. Wu, F. Xu, Y . Wang, Q. Sun, C. Jia, K. Cheng, Z. Ding, L. Chen, P. P. Liang,et al., “Os-atlas: A foundation action model for generalist gui agents,”arXiv preprint arXiv:2410.23218, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Y . Qin, Y . Ye, J. Fang, H. Wang, S. Liang, S. Tian, J. Zhang, J. Li, Y . Li, S. Huang,et al., “Ui-tars: Pioneering automated gui interaction with native agents,”arXiv preprint arXiv:2501.12326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Mobile-Agent-v3: Fundamental Agents for GUI Automation
J. Ye, X. Zhang, H. Xu, H. Liu, J. Wang, Z. Zhu, Z. Zheng, F. Gao, J. Cao, Z. Lu,et al., “Mobile-agent-v3: Fundamental agents for gui automation,”arXiv preprint arXiv:2508.15144, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
jrapture: A cap- ture/replay tool for observation-based testing,
J. Steven, P. Chandra, B. Fleck, and A. Podgurski, “jrapture: A cap- ture/replay tool for observation-based testing,” inProceedings of the 2000 ACM SIGSOFT international symposium on Software testing and analysis, pp. 158–167, 2000. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12
2000
-
[12]
Dart: a frame- work for regression testing
A. Memon, I. Banerjee, N. Hashmi, and A. Nagarajan, “Dart: a frame- work for regression testing” nightly/daily builds” of gui applications,” in International Conference on Software Maintenance, 2003. ICSM 2003. Proceedings., pp. 410–419, IEEE, 2003
2003
-
[13]
Hierarchical gui test case generation using automated planning,
A. M. Memon, M. E. Pollack, and M. L. Soffa, “Hierarchical gui test case generation using automated planning,”IEEE transactions on software engineering, vol. 27, no. 2, pp. 144–155, 2001
2001
-
[14]
Rule-based exploratory testing of graphical user interfaces,
T. D. Hellmann and F. Maurer, “Rule-based exploratory testing of graphical user interfaces,” in2011 Agile Conference, pp. 107–116, IEEE, 2011
2011
-
[16]
D. Nguyen, J. Chen, Y . Wang, G. Wu, N. Park, Z. Hu, H. Lyu, J. Wu, R. Aponte, Y . Xia,et al., “Gui agents: A survey,”arXiv preprint arXiv:2412.13501, 2024
-
[17]
Gui agents with foundation models: A compre- hensive survey,
S. Wang, W. Liu, J. Chen, W. Gan, X. Zeng, S. Yu, X. Hao, K. Shao, Y . Wang, and R. Tang, “Gui agents with foundation models: A compre- hensive survey,”arXiv preprint arXiv:2411.04890, 2024
-
[18]
Smoothing grounding and reasoning for mllm-powered gui agents with query- oriented pivot tasks,
Z. Wu, P. Cheng, Z. Wu, T. Ju, Z. Zhang, and G. Liu, “Smoothing grounding and reasoning for mllm-powered gui agents with query- oriented pivot tasks,”arXiv preprint arXiv:2503.00401, 2025
-
[19]
Gui-g2: Gaussian reward modeling for gui grounding,
F. Tang, Z. Gu, Z. Lu, X. Liu, S. Shen, C. Meng, W. Wang, W. Zhang, Y . Shen, W. Lu,et al., “Gui-g2: Gaussian reward modeling for gui grounding,”arXiv preprint arXiv:2507.15846, 2025
-
[20]
Gui-g1: Understanding r1-zero-like training for visual grounding in gui agents,
Y . Zhou, S. Dai, S. Wang, K. Zhou, Q. Jia, and J. Xu, “Gui-g1: Understanding r1-zero-like training for visual grounding in gui agents,” arXiv preprint arXiv:2505.15810, 2025
-
[21]
Cogagent: A visual language model for gui agents,
W. Hong, W. Wang, Q. Lv, J. Xu, W. Yu, J. Ji, Y . Wang, Z. Wang, Y . Dong, M. Ding,et al., “Cogagent: A visual language model for gui agents,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14281–14290, 2024
2024
-
[22]
CoCo-agent: A comprehensive cog- nitive MLLM agent for smartphone GUI automation,
X. Ma, Z. Zhang, and H. Zhao, “CoCo-agent: A comprehensive cog- nitive MLLM agent for smartphone GUI automation,” inFindings of the Association for Computational Linguistics: ACL 2024(L.-W. Ku, A. Martins, and V . Srikumar, eds.), (Bangkok, Thailand), pp. 9097– 9110, Association for Computational Linguistics, Aug. 2024
2024
-
[23]
Android in the zoo: Chain-of-action-thought for GUI agents,
J. Zhang, J. Wu, T. Yihua, M. Liao, N. Xu, X. Xiao, Z. Wei, and D. Tang, “Android in the zoo: Chain-of-action-thought for GUI agents,” inFindings of the Association for Computational Linguistics: EMNLP 2024(Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, eds.), (Miami, Florida, USA), pp. 12016–12031, Association for Computational Linguistics, Nov. 2024
2024
-
[24]
Mobile-agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration,
J. Wang, H. Xu, H. Jia, X. Zhang, M. Yan, W. Shen, J. Zhang, F. Huang, and J. Sang, “Mobile-agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration,”Advances in Neural Information Processing Systems, vol. 37, pp. 2686–2710, 2025
2025
-
[25]
Appagent v2: Advanced agent for flexible mobile interactions,
Y . Li, C. Zhang, W. Yang, B. Fu, P. Cheng, X. Chen, L. Chen, and Y . Wei, “Appagent v2: Advanced agent for flexible mobile interactions,” arXiv preprint arXiv:2408.11824, 2024
-
[26]
Mobile-agent-e: Self-evolving mobile assistant for complex tasks,
Z. Wang, H. Xu, J. Wang, X. Zhang, M. Yan, J. Zhang, F. Huang, and H. Ji, “Mobile-agent-e: Self-evolving mobile assistant for complex tasks,”arXiv preprint arXiv:2501.11733, 2025
-
[27]
N. Li, X. Qu, J. Zhou, J. Wang, M. Wen, K. Du, X. Lou, Q. Peng, and W. Zhang, “Mobileuse: A gui agent with hierarchical reflection for autonomous mobile operation,”arXiv preprint arXiv:2507.16853, 2025
-
[28]
Large Language Model-Brained GUI Agents: A Survey
C. Zhang, S. He, J. Qian, B. Li, L. Li, S. Qin, Y . Kang, M. Ma, Q. Lin, S. Rajmohan,et al., “Large language model-brained gui agents: A survey,”arXiv preprint arXiv:2411.18279, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Towards trustworthy gui agents: A survey,
Y . Shi, W. Yu, W. Yao, W. Chen, and N. Liu, “Towards trustworthy gui agents: A survey,”arXiv preprint arXiv:2503.23434, 2025
-
[30]
CowPilot: A framework for autonomous and human- agent collaborative web navigation,
F. Huq, Z. Z. Wang, F. F. Xu, T. Ou, S. Zhou, J. P. Bigham, and G. Neubig, “CowPilot: A framework for autonomous and human- agent collaborative web navigation,” inProceedings of the 2025 Con- ference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (System Demonstrations)(N. Dziri, S. X. ...
2025
-
[31]
Os-kairos: Adaptive interaction for mllm-powered gui agents,
P. Cheng, Z. Wu, Z. Wu, A. Zhang, Z. Zhang, and G. Liu, “Os-kairos: Adaptive interaction for mllm-powered gui agents,”arXiv preprint arXiv:2503.16465, 2025
-
[32]
VeriOS: Query-Driven Proactive Human-Agent-GUI Interaction for Trustworthy OS Agents
Z. Wu, H. Huang, X. Lou, X. Qu, P. Cheng, Z. Wu, W. Liu, W. Zhang, J. Wang, Z. Wang,et al., “Verios: Query-driven proactive human-agent-gui interaction for trustworthy os agents,”arXiv preprint arXiv:2509.07553, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Browseconf: Confidence-guided test-time scaling for web agents,
L. Ou, K. Li, H. Yin, L. Zhang, Z. Zhang, X. Wu, R. Ye, Z. Qiao, P. Xie, J. Zhou,et al., “Browseconf: Confidence-guided test-time scaling for web agents,”arXiv preprint arXiv:2510.23458, 2025
-
[34]
Mice for cats: Model-internal confidence estimation for calibrating agents with tools,
N. Subramani, J. Eisner, J. Svegliato, B. Van Durme, Y . Su, and S. Thomson, “Mice for cats: Model-internal confidence estimation for calibrating agents with tools,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Compu- tational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 12362–...
2025
-
[35]
Y . Lu, T. Ju, M. Zhao, X. Ma, Y . Guo, and Z. Zhang, “Eva: Red-teaming gui agents via evolving indirect prompt injection,”arXiv preprint arXiv:2505.14289, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
Y . Xu, Z. Wang, J. Wang, D. Lu, T. Xie, A. Saha, D. Sahoo, T. Yu, and C. Xiong, “Aguvis: Unified pure vision agents for autonomous gui interaction,”arXiv preprint arXiv:2412.04454, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Digirl: Training in-the-wild device-control agents with autonomous re- inforcement learning,
Y . Zhou, H. Bai, M. Cemri, J. Pan, A. Suhr, S. Levine, and A. Kumar, “Digirl: Training in-the-wild device-control agents with autonomous re- inforcement learning,” inAutomated Reinforcement Learning: Exploring Meta-Learning, AutoML, and LLMs, 2024
2024
-
[38]
Distrl: An asynchronous distributed reinforcement learning framework for on-device control agent,
T. Wang, Z. Wu, J. Liu, D. Yuen, H. Jianye, J. Wang, and K. Shao, “Distrl: An asynchronous distributed reinforcement learning framework for on-device control agent,” inNeurIPS 2024 Workshop on Fine-Tuning in Modern Machine Learning: Principles and Scalability, 2024
2024
-
[39]
UI-R1: Enhancing Efficient Action Prediction of GUI Agents by Reinforcement Learning
Z. Lu, Y . Chai, Y . Guo, X. Yin, L. Liu, H. Wang, H. Xiao, S. Ren, G. Xiong, and H. Li, “Ui-r1: Enhancing action prediction of gui agents by reinforcement learning,”arXiv preprint arXiv:2503.21620, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
R. Luo, L. Wang, W. He, L. Chen, J. Li, and X. Xia, “Gui-r1: A generalist r1-style vision-language action model for gui agents,”arXiv preprint arXiv:2504.10458, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
Y . Liu, P. Li, C. Xie, X. Hu, X. Han, S. Zhang, H. Yang, and F. Wu, “Infigui-r1: Advancing multimodal gui agents from reactive actors to deliberative reasoners,”arXiv preprint arXiv:2504.14239, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Ui-s1: Advancing gui automation via semi- online reinforcement learning,
Z. Lu, J. Ye, F. Tang, Y . Shen, H. Xu, Z. Zheng, W. Lu, M. Yan, F. Huang, J. Xiao,et al., “Ui-s1: Advancing gui automation via semi- online reinforcement learning,”arXiv preprint arXiv:2509.11543, 2025
-
[43]
Q. Ai, P. Bu, Y . Cao, Y . Wang, J. Gu, J. Xing, Z. Zhu, W. Jiang, Z. Zheng, J. Song,et al., “Inquiremobile: Teaching vlm-based mobile agent to request human assistance via reinforcement fine-tuning,”arXiv preprint arXiv:2508.19679, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in Neural Information Processing Systems, vol. 36, pp. 53728–53741, 2023
2023
-
[45]
Meta- gui: Towards multi-modal conversational agents on mobile gui,
L. Sun, X. Chen, L. Chen, T. Dai, Z. Zhu, and K. Yu, “Meta- gui: Towards multi-modal conversational agents on mobile gui,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 6699–6712, 2022
2022
-
[46]
On the effects of data scale on ui control agents, 2024
W. Li, W. Bishop, A. Li, C. Rawles, F. Campbell-Ajala, D. Tyama- gundlu, and O. Riva, “On the effects of data scale on computer control agents,”arXiv preprint arXiv:2406.03679, 2024
-
[47]
Android in the wild: a large-scale dataset for android device control,
C. Rawles, A. Li, D. Rodriguez, O. Riva, and T. Lillicrap, “Android in the wild: a large-scale dataset for android device control,” pp. 59708– 59728, 2023
2023
-
[48]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford,et al., “Gpt-4o system card,”arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
T. GLM, A. Zeng, B. Xu, B. Wang, C. Zhang, D. Yin, D. Zhang, D. Rojas, G. Feng, H. Zhao,et al., “Chatglm: A family of large language models from glm-130b to glm-4 all tools,”arXiv preprint arXiv:2406.12793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A frontier large vision-language model with versatile abilities,”arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016
2016
-
[52]
A convnet for the 2020s,
Z. Liu, H. Mao, C.-Y . Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11976–11986, 2022
2022
-
[53]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[54]
Mobile-agent: Autonomous multi-modal mobile device agent with visual perception,
J. Wang, H. Xu, J. Ye, M. Yan, W. Shen, J. Zhang, F. Huang, and J. Sang, “Mobile-agent: Autonomous multi-modal mobile device agent with visual perception,” inICLR 2024 Workshop on Large Language Model (LLM) Agents, 2024
2024
-
[55]
Attention-driven gui grounding: Leveraging pretrained multimodal large language models without fine-tuning,
H.-M. Xu, Q. Chen, L. Wang, and L. Liu, “Attention-driven gui grounding: Leveraging pretrained multimodal large language models without fine-tuning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, pp. 8851–8859, 2025. Zheng Wureceived his Bachelor’s degree in infor- mation security from Shanghai Jiao Tong University, Shanghai, C...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.