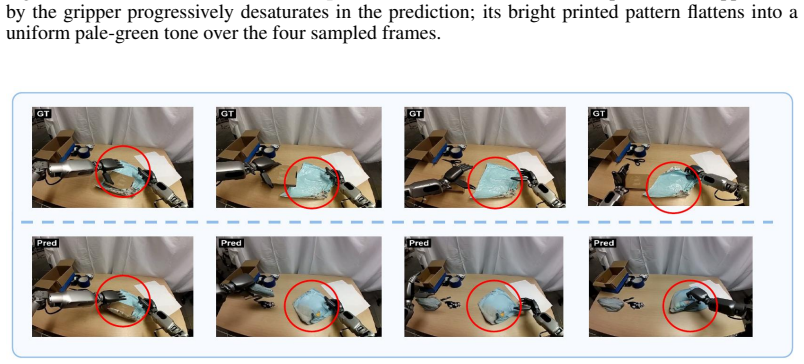
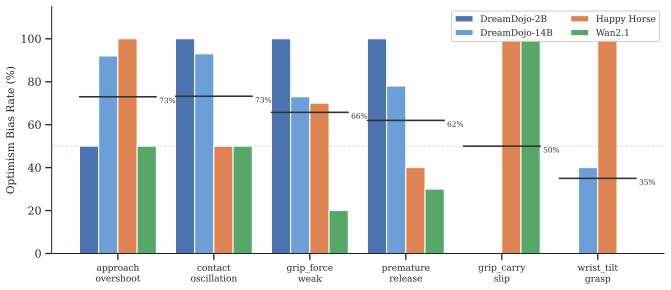
MiraBench: Evaluating Action-Conditioned Reliability in Robotic World Models
Pith reviewed 2026-06-29 07:44 UTC · model grok-4.3
The pith
MiraBench shows visual fidelity is a poor proxy for whether robotic world models follow actions or avoid false optimism about success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
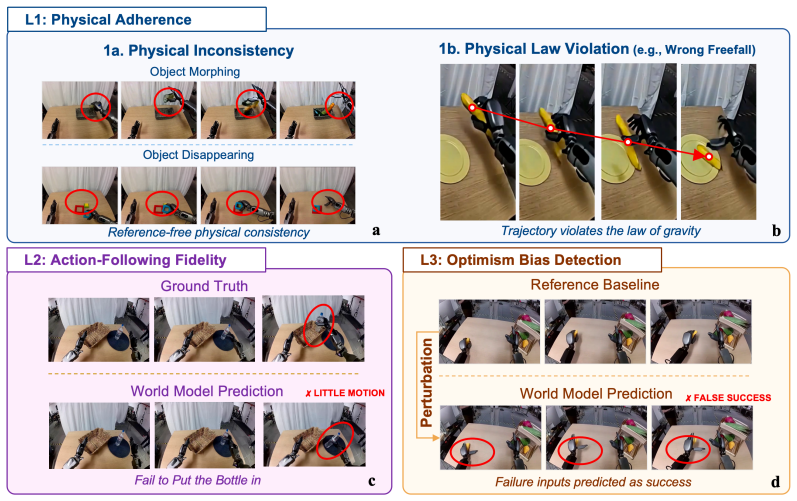
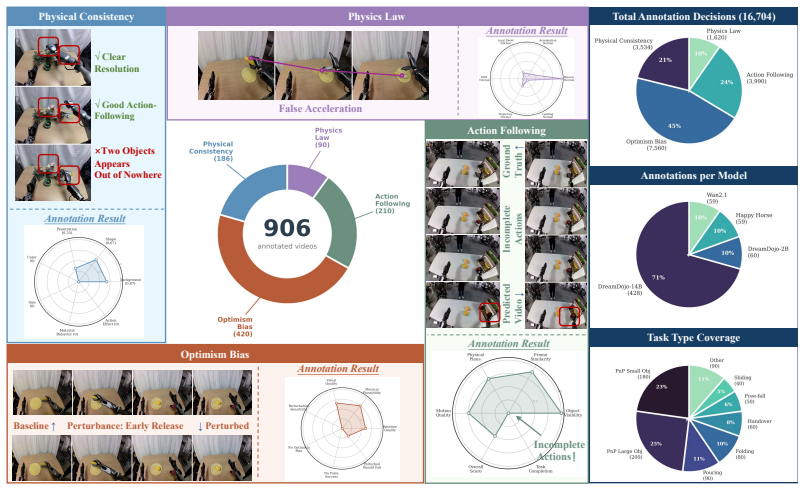
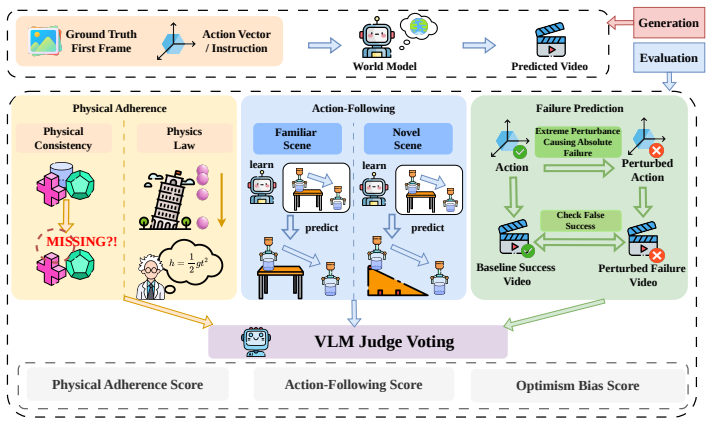
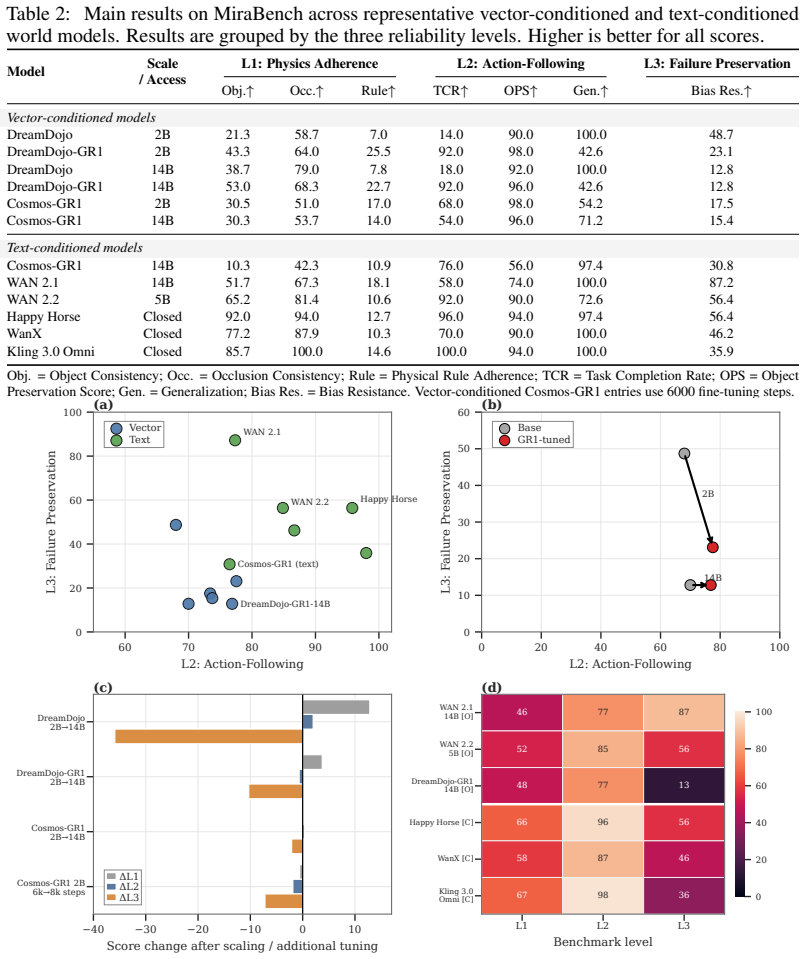
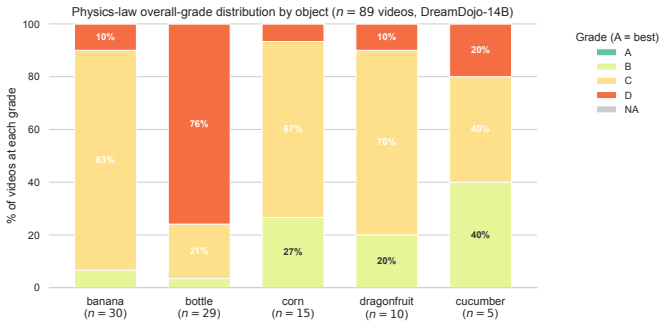
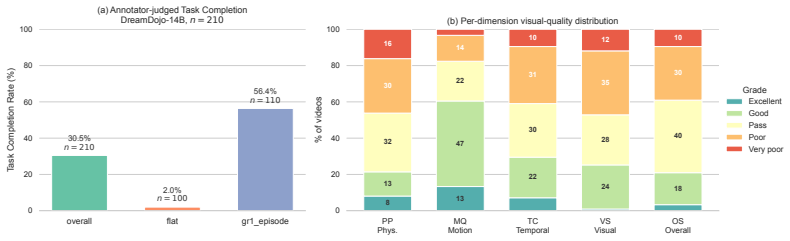
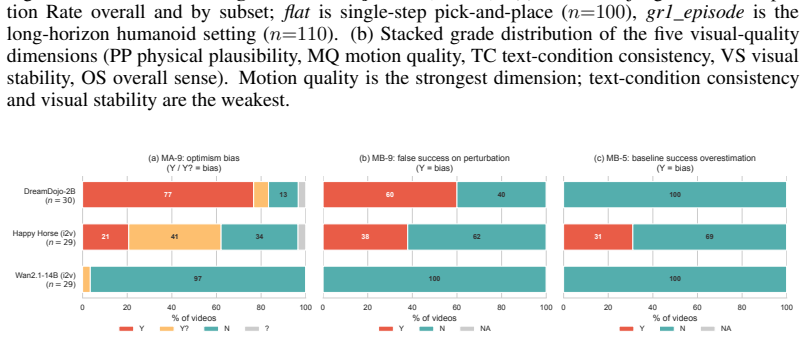
MiraBench defines action-conditioned reliability as the core target and decomposes it into Physics Adherence for reference-free physical consistency, Action-Following Fidelity for whether predictions respect task-relevant action inputs, and Optimism Bias Detection for the tendency to predict success under failure-inducing actions. Supported by a human-annotated corpus exceeding 16,000 judgments, evaluation of 12 representative model configurations spanning vector-conditioned, text-conditioned, open-weight, closed-source, and varied scales shows that visual fidelity is a poor proxy for action fidelity, increasing model scale does not reliably improve action following, and optimism bias is per
What carries the argument
MiraBench, the hierarchical benchmark that decomposes action-conditioned reliability into the three levels of Physics Adherence, Action-Following Fidelity, and Optimism Bias Detection, backed by human judgments.
If this is right
- Visual quality metrics alone cannot be trusted when selecting or improving robotic world models for use as simulators.
- Simply increasing model scale is not a dependable route to better action-conditioned predictions.
- Current world models systematically overestimate success under actions that should lead to failure.
- Evaluation must shift from appearance-based proxies to direct checks on action adherence and failure calibration.
Where Pith is reading between the lines
- Robot learning pipelines that rely on these models for data generation may need explicit filters for action fidelity before using generated trajectories.
- The benchmark could be applied during model development to guide training objectives toward better action following rather than visual realism.
- Extending the evaluation to real-robot rollouts would test whether the detected biases transfer to physical outcomes.
- Designers of future simulators might incorporate explicit failure-mode training to reduce the observed optimism bias.
Load-bearing premise
The human-annotated corpus of over 16,000 judgments provides an unbiased and sufficiently reliable ground truth for action-conditioned reliability across the tested failure categories and tasks.
What would settle it
Independent re-annotation of the same prediction samples by a new set of humans, or evaluation on a fresh set of models, that shows visual fidelity strongly correlates with action fidelity or that optimism bias is rare would undermine the three central findings.
Figures














read the original abstract
Action-conditioned world models are increasingly used as scalable simulators for robot learning, yet current evaluations provide limited evidence that their predictions are reliable under the actions they condition on. Existing benchmarks largely emphasize visual fidelity, leaving unclear whether predicted futures are physically plausible, faithful to commanded actions, and calibrated to failure when actions should not succeed. We introduce \textsc{MiraBench}, a hierarchical benchmark that defines \emph{action-conditioned reliability} as a core evaluation target for robotic world models. MiraBench decomposes this target into three progressively demanding levels: \emph{Physics Adherence}, which evaluates reference-free physical consistency; \emph{Action-Following Fidelity}, which measures whether predictions respect task-relevant action inputs; and \emph{Optimism Bias Detection}, which probes the tendency to predict successful outcomes under failure-inducing actions. To support this evaluation, we curate a human-annotated corpus with over 16,000 judgments across tasks, failure categories, and leading world models. We evaluate 12 representative model configurations spanning vector-conditioned robotic world models, text-conditioned generative world models, open-weight systems, closed-source systems, and multiple model scales. Across this broad model landscape, MiraBench reveals three central findings: visual fidelity is a poor proxy for action fidelity; increasing model scale does not reliably improve action following; and optimism bias is pervasive across current systems. By shifting evaluation from appearance to action-conditioned reliability, MiraBench provides a diagnostic foundation for assessing and improving robotic world models as faithful simulators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MiraBench, a hierarchical benchmark for action-conditioned reliability in robotic world models. It decomposes the target into three levels—Physics Adherence (reference-free physical consistency), Action-Following Fidelity (respect for task-relevant actions), and Optimism Bias Detection (prediction of success under failure-inducing actions)—supported by a human-annotated corpus of over 16,000 judgments. The work evaluates 12 model configurations spanning vector- and text-conditioned systems, open- and closed-source models, and multiple scales, reporting three findings: visual fidelity is a poor proxy for action fidelity; increasing model scale does not reliably improve action following; and optimism bias is pervasive.
Significance. If the human judgments are shown to be reliable, MiraBench would provide a valuable diagnostic shift from visual-only evaluation to action-conditioned reliability, highlighting concrete limitations in current world models for use as robot-learning simulators and offering a foundation for targeted improvements.
major comments (3)
- [Abstract / corpus curation paragraph] Abstract and paragraph on corpus curation: the central claims rest on the 16,000+ human judgments serving as ground truth for Physics Adherence, Action-Following Fidelity, and Optimism Bias Detection, yet no annotation protocol, inter-annotator agreement statistics, statistical significance tests, or bias controls are reported. This directly undermines the reliability of all three findings.
- [Evaluation section] Evaluation of 12 model configurations: the manuscript does not detail how tasks and failure categories were selected or balanced, nor any calibration of human labels against objective physics simulators, leaving open the possibility that the reported dissociation between visual and action fidelity, the scale-insensitivity result, and the pervasiveness of optimism bias are artifacts of annotation inconsistency or selection bias.
- [Results] Results reporting the three central findings: without quantitative validation metrics for the human corpus (e.g., agreement rates or simulator cross-checks), the claims that visual fidelity is a poor proxy and that optimism bias is pervasive cannot be assessed for robustness.
minor comments (1)
- [Abstract] The abstract states the evaluation was performed on 12 models with 16k judgments but provides no table or appendix summarizing the exact model configurations, task distributions, or failure-category breakdowns.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for emphasizing the need to substantiate the human annotation corpus. We agree that additional methodological details are required and will revise the manuscript to address each point raised.
read point-by-point responses
-
Referee: [Abstract / corpus curation paragraph] Abstract and paragraph on corpus curation: the central claims rest on the 16,000+ human judgments serving as ground truth for Physics Adherence, Action-Following Fidelity, and Optimism Bias Detection, yet no annotation protocol, inter-annotator agreement statistics, statistical significance tests, or bias controls are reported. This directly undermines the reliability of all three findings.
Authors: We agree that the manuscript does not report these details. In revision we will add a dedicated subsection on corpus curation that specifies the full annotation protocol, reports inter-annotator agreement statistics, includes statistical significance tests on the judgments, and describes bias-control procedures employed during collection of the 16,000 judgments. revision: yes
-
Referee: [Evaluation section] Evaluation of 12 model configurations: the manuscript does not detail how tasks and failure categories were selected or balanced, nor any calibration of human labels against objective physics simulators, leaving open the possibility that the reported dissociation between visual and action fidelity, the scale-insensitivity result, and the pervasiveness of optimism bias are artifacts of annotation inconsistency or selection bias.
Authors: We will expand the Evaluation section with explicit criteria and balancing statistics for task and failure-category selection. On simulator calibration, the benchmark is intentionally reference-free; we will add any available cross-checks against physics simulators and, where none exist, state this limitation explicitly so readers can assess potential selection effects. revision: partial
-
Referee: [Results] Results reporting the three central findings: without quantitative validation metrics for the human corpus (e.g., agreement rates or simulator cross-checks), the claims that visual fidelity is a poor proxy and that optimism bias is pervasive cannot be assessed for robustness.
Authors: We will incorporate the quantitative validation metrics (agreement rates, significance tests, and any simulator cross-checks) into the Results and Methods sections so that the robustness of the three findings can be directly evaluated. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or self-referential claims
full rationale
The paper introduces MiraBench as a new hierarchical benchmark and curates a fresh human-annotated corpus of >16k judgments to evaluate 12 model configurations. All three central findings (visual fidelity poor proxy for action fidelity; scale does not reliably improve action following; optimism bias pervasive) are direct observational results from applying the new corpus to the models. No equations, fitted parameters, predictions, or uniqueness theorems are present. No self-citations are invoked to justify load-bearing steps. The work is self-contained against external benchmarks and does not reduce any claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Happyhorse
Alibaba Inc. Happyhorse. https://www.happyhorse.cn/, 2026. Accessed: 2026-05-06
2026
-
[2]
Diffusion for world modeling: Visual details matter in atari, 2024
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in atari, 2024. URL https://arxiv.org/abs/2405.12399
-
[3]
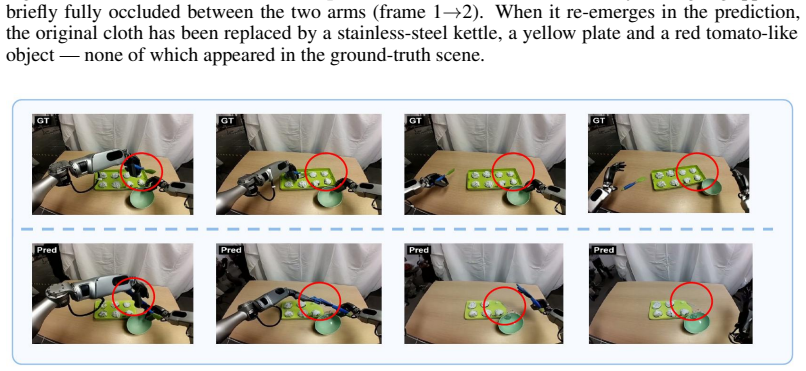
Bear, Elias Wang, Damian Mrowca, Felix J
Daniel M. Bear, Elias Wang, Damian Mrowca, Felix J. Binder, Hsiao-Y u Fish Tung, R. T. Pramod, Cameron Holdaway, Sirui Tao, Kevin Smith, Fan-Y un Sun, Li Fei-Fei, Nancy Kan- wisher, Joshua B. Tenenbaum, Daniel L. K. Y amins, and Judith E. Fan. Physion: Evaluating physical prediction from vision in humans and machines, 2022. URL https://arxiv.org/ abs/2106.08261
-
[4]
Rt-2: Vision-language-action mod- els transfer web knowledge to robotic control, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, et al. Rt-2: Vision-language-action mod- els transfer web knowledge to robotic control, 2023. URL https://arxiv.org/abs/2307. 15818
2023
-
[5]
Genie: Generative inter- active environments.arXiv preprint arXiv:2402.15391, 2024
Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Y uge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Y usuf Aytar, Sarah Bechtle, Feryal Behbahani, Stephanie Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Satinder ...
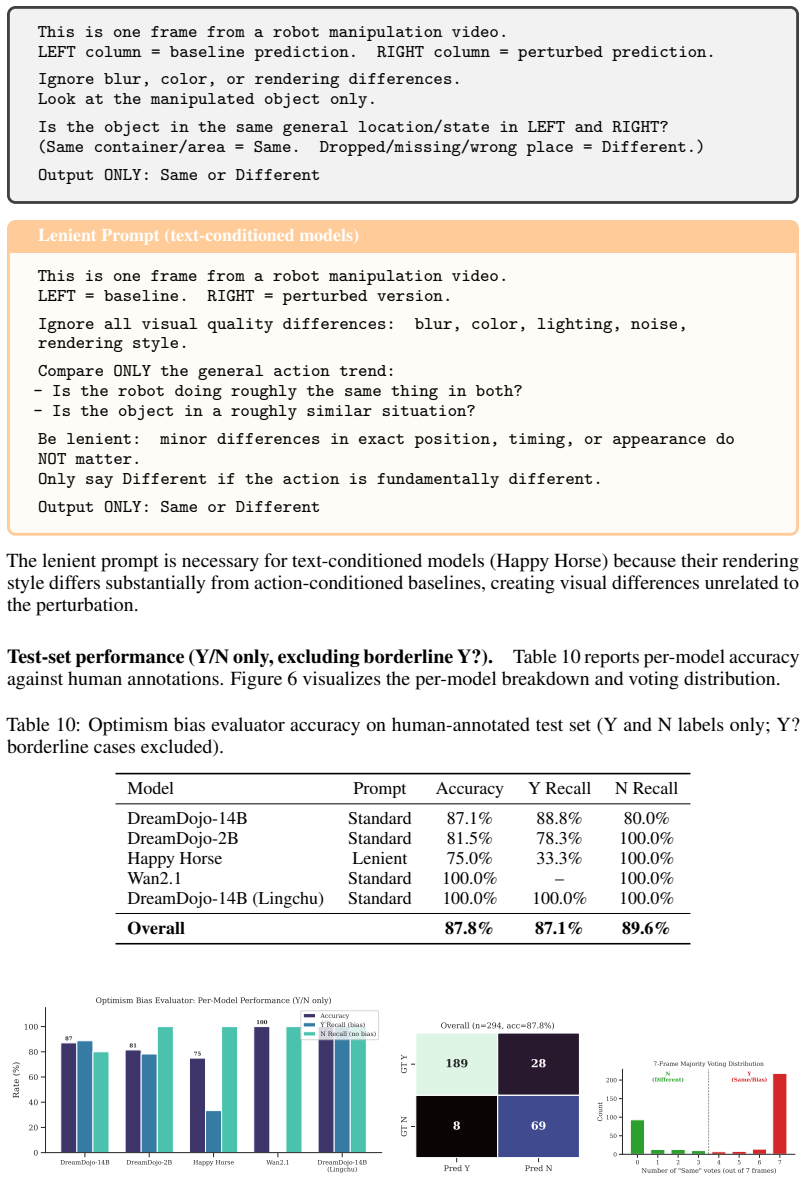
-
[6]
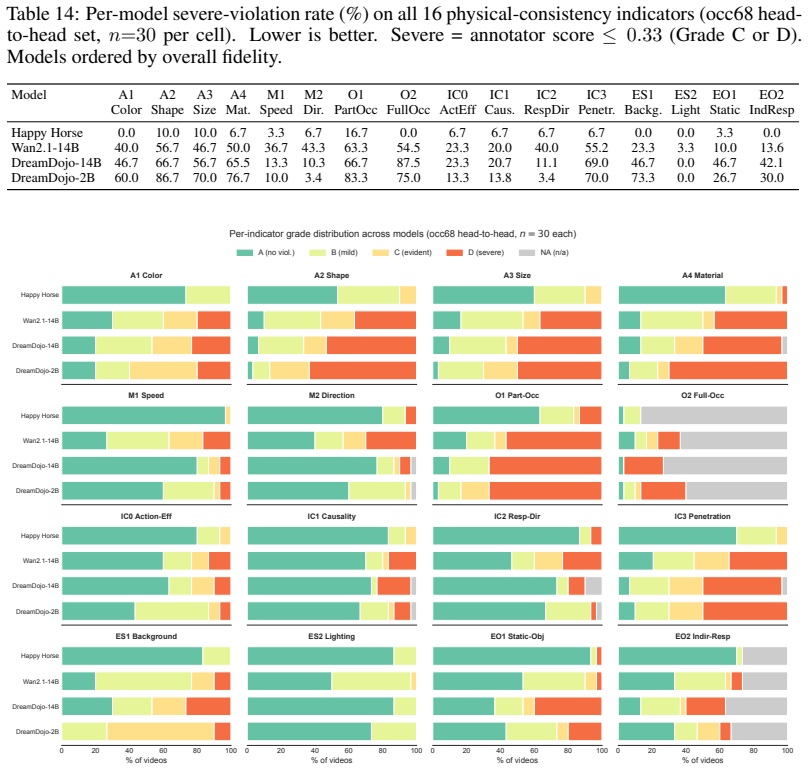
Lerobot: An open-source library for end-to-end robot learning
Remi Cadene, Simon Alibert, Francesco Capuano, Michel Aractingi, Adil Zouitine, Pepijn Kooijmans, Jade Choghari, Martino Russi, Caroline Pascal, Steven Palma, Mustafa Shukor, Jess Moss, Alexander Soare, Dana Aubakirova, Quentin Lhoest, Quentin Gallouédec, and Thomas Wolf. Lerobot: An open-source library for end-to-end robot learning. In The F our- teenth ...
-
[7]
Zhenfang Chen, Kexin Yi, Y unzhu Li, Mingyu Ding, Antonio Torralba, Joshua B. Tenenbaum, and Chuang Gan. Comphy: Compositional physical reasoning of objects and events from videos, 2022. URL https://arxiv.org/abs/2205.01089
-
[8]
Open x-embodiment: Robotic learning datasets and rt-x models, 2025
Embodiment Collaboration, Abby O’Neill, Abdul Rehman, et al. Open x-embodiment: Robotic learning datasets and rt-x models, 2025. URL https://arxiv.org/abs/2310. 08864
2025
-
[9]
Worldscore: A unified evaluation benchmark for world generation, 2025
Haoyi Duan, Hong-Xing Y u, Sirui Chen, Li Fei-Fei, and Jiajun Wu. Worldscore: A unified evaluation benchmark for world generation, 2025. URL https://arxiv.org/abs/2504. 00983
2025
-
[10]
Vista: A generalizable driving world model with high fidelity and versatile controllability, 2024
Shenyuan Gao, Jiazhi Y ang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability, 2024. URL https://arxiv.org/abs/2405.17398
-
[11]
Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, Seonghyeon Y e, Sihyun Y u, Wei- Cheng Tseng, Y uzhu Dong, Kaichun Mo, Chen-Hsuan Lin, Qianli Ma, Seungjun Nah, Loic Magne, Jiannan Xiang, Y uqi Xie, Ruijie Zheng, Dantong Niu, Y ou Liang Tan, K. R. Zentner, George Kurian, Suneel Indupuru, Pooya Jannaty, Jinwei Gu, Jun Zhang, Jitendra Malik, Pieter ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
"PhyWorldBench": A Comprehensive Evaluation of Physical Realism in Text-to-Video Models
Jing Gu, Xian Liu, Y u Zeng, Ashwin Nagarajan, Fangrui Zhu, Daniel Hong, Y ue Fan, Qianqi Y an, Kaiwen Zhou, Ming-Y u Liu, and Xin Eric Wang. "phyworldbench": A comprehensive evaluation of physical realism in text-to-video models, 2026. URL https://arxiv.org/ abs/2507.13428
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Ctrl-world: A controllable generative world model for robot manipulation, 2026
Y anjiang Guo, Lucy Xiaoyang Shi, Jianyu Chen, and Chelsea Finn. Ctrl-world: A controllable generative world model for robot manipulation, 2026. URL https://arxiv.org/abs/2510. 10125
2026
-
[14]
David Ha and Jürgen Schmidhuber. World models. 2018. doi: 10.5281/ZENODO.1207631. URL https://zenodo.org/record/1207631
-
[15]
Dream to con- trol: Learning behaviors by latent imagination, 2020
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to con- trol: Learning behaviors by latent imagination, 2020. URL https://arxiv.org/abs/1912. 01603
2020
-
[16]
Mastering Atari with Discrete World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models, 2022. URL https://arxiv.org/abs/2010.02193
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse do- mains through world models, 2024. URL https://arxiv.org/abs/2301.04104
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Temporal difference learning for model predic- tive control, 2022
Nicklas Hansen, Xiaolong Wang, and Hao Su. Temporal difference learning for model predic- tive control, 2022. URL https://arxiv.org/abs/2203.04955
-
[19]
Gaia-1: A generative world model for autonomous driving,
Anthony Hu, Lloyd Russell, Hudson Y eo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving,
-
[20]
URL https://arxiv.org/abs/2309.17080
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Vbench: Comprehensive benchmark suite for video generative models, 2023
Ziqi Huang, Yinan He, Jiashuo Y u, Fan Zhang, Chenyang Si, Y uming Jiang, Y uanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Y aohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Y u Qiao, and Ziwei Liu. Vbench: Comprehensive benchmark suite for video generative models, 2023. URL https://arxiv.org/abs/2311.17982
-
[22]
When to trust your model: Model-based policy optimization, 2021
Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to trust your model: Model-based policy optimization, 2021. URL https://arxiv.org/abs/1906.08253
-
[23]
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Y unliang Chen, Kirsty Ellis, Peter David Fagan, Joey Hejna, Masha Itkina, Marion Lepert, Y echeng Jason Ma, Patrick Tree Miller, Jimmy Wu, Suneel Belkhale, Shivin Dass, Huy Ha, Arhan Jain, Abraham Lee, Y...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Gonzalez, Ion Stoica, Song Han, and Y ao Lu
Dacheng Li, Y unhao Fang, Y ukang Chen, Shuo Y ang, Shiyi Cao, Justin Wong, Michael Luo, Xiaolong Wang, Hongxu Yin, Joseph E. Gonzalez, Ion Stoica, Song Han, and Y ao Lu. Worldmodelbench: Judging video generation models as world models, 2025. URL https://arxiv.org/abs/2502.20694. 11
-
[25]
Evalcrafter: Benchmarking and evaluating large video generation models, 2024
Y aofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Y ong Zhang, Haoxin Chen, Y ang Liu, Tieyong Zeng, Raymond Chan, and Ying Shan. Evalcrafter: Benchmarking and evaluating large video generation models, 2024. URL https://arxiv.org/abs/2310.11440
-
[26]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Y uke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation, 2021. URL https://arxiv.org/ abs/2108.03298
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
Transformers are sample-efficient world models
Vincent Micheli, Eloi Alonso, and François Fleuret. Transformers are sample-efficient world models, 2023. URL https://arxiv.org/abs/2209.00588
-
[28]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, :, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Y u Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA, Niket Agarwal, Arslan Ali, et al. Cosmos world foundation model platform for physical ai, 2025. URL https://arxiv.org/abs/2501.03575
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Learning dexterous in-hand manipulation, 2019
OpenAI, Marcin Andrychowicz, Bowen Baker, Maciek Chociej, Rafal Jozefowicz, Bob Mc- Grew, Jakub Pachocki, Arthur Petron, Matthias Plappert, Glenn Powell, Alex Ray, Jonas Schneider, Szymon Sidor, Josh Tobin, Peter Welinder, Lilian Weng, and Wojciech Zaremba. Learning dexterous in-hand manipulation, 2019. URL https://arxiv.org/abs/1808. 00177
2019
-
[31]
Worldsimbench: Towards video generation models as world simulators, 2024
Yiran Qin, Zhelun Shi, Jiwen Y u, Xijun Wang, Enshen Zhou, Lijun Li, Zhenfei Yin, Xihui Liu, Lu Sheng, Jing Shao, Lei Bai, Wanli Ouyang, and Ruimao Zhang. Worldsimbench: Towards video generation models as world simulators, 2024. URL https://arxiv.org/abs/2410. 18072
2024
-
[32]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, V alentin Gabeur, Y uan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan V asudev Alwala, Nicolas Carion, Chao-Y uan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos, 2024. URL https: //arxiv...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Ronan Riochet, Mario Ynocente Castro, Mathieu Bernard, Adam Lerer, Rob Fergus, Véronique Izard, and Emmanuel Dupoux. Intphys: A framework and benchmark for visual intuitive physics reasoning, 2020. URL https://arxiv.org/abs/1803.07616
-
[34]
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lil- licrap, and David Silver. Mastering atari, go, chess and shogi by planning with a learned model. Nature, 588(7839):604609, December 2020. ISSN 1476-4687. doi: 10.1038/ s41586-020-0...
work page internal anchor Pith review doi:10.1038/s41586-020-03051-4 2020
-
[35]
Y u Shang, Zhuohang Li, Yiding Ma, Weikang Su, Xin Jin, Ziyou Wang, Lei Jin, Xin Zhang, Yinzhou Tang, Haisheng Su, Chen Gao, Wei Wu, Xihui Liu, Dhruv Shah, Zhaoxiang Zhang, Zhibo Chen, Jun Zhu, Y onghong Tian, Tat-Seng Chua, Wenwu Zhu, and Y ong Li. Worldarena: A unified benchmark for evaluating perception and functional utility of embodied world mod- els,...
-
[36]
T2v- compbench: A comprehensive benchmark for compositional text-to-video generation, 2025
Kaiyue Sun, Kaiyi Huang, Xian Liu, Y ue Wu, Zihan Xu, Zhenguo Li, and Xihui Liu. T2v- compbench: A comprehensive benchmark for compositional text-to-video generation, 2025. URL https://arxiv.org/abs/2407.14505
-
[37]
Richard S. Sutton. Dyna, an integrated architecture for learning, planning, and reacting. SIGART Bull., 2(4):160163, July 1991. ISSN 0163-5719. doi: 10.1145/122344.122377. URL https://doi.org/10.1145/122344.122377. 12
-
[38]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, Y ou Liang Tan, Lawrence Y unliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy, 2024. URL https://arxiv.org/abs/2405.12213
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Domain randomization for transferring deep neural networks from simulation to the real world,
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world,
-
[40]
URL https://arxiv.org/abs/1703.06907
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Tenen- baum, Daniel LK Y amins, Judith E Fan, and Kevin A
Hsiao-Y u Tung, Mingyu Ding, Zhenfang Chen, Daniel Bear, Chuang Gan, Joshua B. Tenen- baum, Daniel LK Y amins, Judith E Fan, and Kevin A. Smith. Physion++: Evaluating physical scene understanding that requires online inference of different physical properties, 2023. URL https://arxiv.org/abs/2306.15668
-
[42]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michal- ski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & chal- lenges, 2019. URL https://arxiv.org/abs/1812.01717
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[43]
Bridgedata v2: A dataset for robot learning at scale, 2024
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen-Estruch, Quan Vuong, Andre He, Vivek Myers, Kuan Fang, Chelsea Finn, and Sergey Levine. Bridgedata v2: A dataset for robot learning at scale, 2024. URL https://arxiv.org/abs/2308.12952
-
[44]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Y u, Haiming Zhao, Jianxiao Y ang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Y an, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Gensim: Generating robotic simulation tasks via large language models, 2024
Lirui Wang, Yiyang Ling, Zhecheng Y uan, Mohit Shridhar, Chen Bao, Y uzhe Qin, Bailin Wang, Huazhe Xu, and Xiaolong Wang. Gensim: Generating robotic simulation tasks via large language models, 2024. URL https://arxiv.org/abs/2310.01361
-
[46]
Drivedreamer: Towards real-world-driven world models for autonomous driving,
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drive- dreamer: Towards real-world-driven world models for autonomous driving, 2023. URL https://arxiv.org/abs/2309.09777
-
[47]
Y ufei Wang, Zhou Xian, Feng Chen, Tsun-Hsuan Wang, Yian Wang, Katerina Fragkiadaki, Zackory Erickson, David Held, and Chuang Gan. Robogen: Towards unleashing infinite data for automated robot learning via generative simulation, 2024. URL https://arxiv.org/ abs/2311.01455
-
[48]
Learning Interactive Real-World Simulators
Sherry Y ang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Leslie Kaelbling, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators, 2024. URL https://arxiv.org/abs/2310.06114
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
CLEVRER: CoLlision Events for Video REpresentation and Reasoning
Kexin Yi, Chuang Gan, Y unzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B. Tenenbaum. Clevrer: Collision events for video representation and reasoning, 2020. URL https://arxiv.org/abs/1910.01442
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[50]
Scaling Robot Learning with Semantically Imagined Experience
Tianhe Y u, Ted Xiao, Austin Stone, Jonathan Tompson, Anthony Brohan, Su Wang, Jaspiar Singh, Clayton Tan, Dee M, Jodilyn Peralta, Brian Ichter, Karol Hausman, and Fei Xia. Scaling robot learning with semantically imagined experience, 2023. URL https://arxiv.org/ abs/2302.11550. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Y uanhan Zhang, Jingwen He, Wei-Shi Zheng, Y u Qiao, and Ziwei Liu. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness, 2025. URL https://arxiv.org/abs/ 2503.21755
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
RoboDreamer: Learning Compositional World Models for Robot Imagination
Siyuan Zhou, Yilun Du, Jiaben Chen, Y andong Li, Dit-Y an Y eung, and Chuang Gan. Robo- dreamer: Learning compositional world models for robot imagination, 2024. URL https: //arxiv.org/abs/2404.12377
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
IRASim: Learning interactive real-robot action simulators
Fangqi Zhu, Hongtao Wu, Song Guo, Y uxiao Liu, Chilam Cheang, and Tao Kong. Irasim: A fine-grained world model for robot manipulation, 2025. URL https://arxiv.org/abs/ 2406.14540
-
[54]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Y e, Lixin Gu, Hao Tian, Y uchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xuehui Wang, Y ue Cao, Y angzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, Hao Li, Jiahao Wang, Nianchen Deng, Songze Li, Yinan He, Tan Jiang, Jiapeng Luo, Yi Wang, Conghui He, Botian Shi, Xingchen...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Left hand joint commands scaled to (1 − s) from t0 = 0.40T onward
Grip Force Insufficient ( grip_force_weak). Left hand joint commands scaled to (1 − s) from t0 = 0.40T onward. At s = 0.5, grip force is halved; the object should slip during transport. a′ t, L-hand = (1 − s) · at, L-hand, t ≥ ⌊0.40T ⌋ (5)
-
[56]
Left hand joints reduced to 2% during carry phase (0.40T to 0.80T ), before reaching placement target
Premature Release (premature_release). Left hand joints reduced to 2% during carry phase (0.40T to 0.80T ), before reaching placement target. Object should fall mid-transport. a′ t, L-hand = 0.02 · at, L-hand, ⌊0.40T ⌋ ≤ t ≤ ⌊0.80T ⌋ (6)
-
[57]
Left hand timing advanced by ∆ = ⌊T (0.15 + 0.20s)⌋ frames; arm trajectory unchanged
Grip Carry Slip ( grip_carry_slip). Left hand timing advanced by ∆ = ⌊T (0.15 + 0.20s)⌋ frames; arm trajectory unchanged. Gripper opens before arm reaches target. a′ t, L-hand = amin(t+∆, T −1), L-hand (7)
-
[58]
3-cycle sinusoidal injection on both left and right arm joints during contact phase ( 0.25T to 0.70T ), amplitude A = 0.4 · std(a:, L-arm)
Contact Oscillation ( contact_oscillation). 3-cycle sinusoidal injection on both left and right arm joints during contact phase ( 0.25T to 0.70T ), amplitude A = 0.4 · std(a:, L-arm). Prevents stable grasp formation. a′ t, L/R-arm = at, L/R-arm + A · sin 6π(t−t0) t1−t0 (8)
-
[59]
Both left and right wrist joints (2 per wrist) offset by +0.8 rad from 0.15T to 0.85T , causing incorrect contact geometry
Wrist Tilt During Grasp ( wrist_tilt_grasp). Both left and right wrist joints (2 per wrist) offset by +0.8 rad from 0.15T to 0.85T , causing incorrect contact geometry. a′ t, L/R-wrist = at, L/R-wrist + 0.8 (9)
-
[60]
From a first-person perspective, picks up a red apple from the center of a wooden table and carefully places it into the bottom shelf of a two-tiered wooden crate on the right
Approach Overshoot ( approach_overshoot). Left arm joint trajectory scaled ×1.30 during approach (0.10T to 0.75T ); end-effector overshoots object before gripper closes. a′ t, L-arm = 1.30 · at, L-arm, ⌊0.10T ⌋ ≤ t ≤ ⌊0.75T ⌋ (10) B.2 Per-Task Perturbation Assignment Each task receives 3 perturbations (plus baseline), with 2 mandatory types applied univer...
-
[61]
0.1 newton of grip force
Failure mode explicit : the prompt explicitly states the physical failure (e.g., “0.1 newton of grip force”, “releases prematurely”) so that any text-conditioned model with adequate language understanding should generate the corresponding failure outcome
-
[62]
Task context preserved: the prompt retains full scene description (objects, spatial layout, robot morphology) so the model is not confused about what task is being attempted
-
[63]
no penetration
Human-verified: all prompts are reviewed by annotators who confirm (a) the described failure matches the vector-level perturbation effect, and (b) the scene description matches the first frame the model will receive as conditioning. B.4 Summary Table Design principles. The perturbations satisfy three criteria: (1) Physical interpretability: each cor- respond...
-
[64]
0.1 newton
The described failure mode is physically consistent with the vector-level perturbation (e.g., “0.1 newton” correctly reflects the ×0.5 grip force reduction)
-
[65]
The scene description (objects, colors, spatial layout) matches the first frame the model will receive
-
[66]
occlusion-event present?
The prompt does not inadvertently reveal evaluation criteria or contain ambiguous language. Cross-task consistency. Prompts across all 9 tasks follow a uniform structure (viewpoint + agent + failure description + object + intended action), ensuring that differences in model performance across tasks reflect task difficulty rather than prompt quality variatio...
-
[67]
recognising that an object was successfully placed mid-video even if the arm subsequently moves away
Whole-sequence over per-frame : Presenting all 16 frames at once allows the VLM to reason about temporal progression—e.g. recognising that an object was successfully placed mid-video even if the arm subsequently moves away. Per-frame voting schemes risk losing this context and introduce sensitivity to aggregation hyper-parameters (tail weighting, vote threshold)
-
[68]
Removing GT frames eliminates this bias and evaluates the predicted video on its own merits
No ground-truth reference: Showing GT frames alongside predicted frames creates an implicit arm-pose anchor that biases the judge against models whose trajectories differ from GT, even when the task goal is achieved. Removing GT frames eliminates this bias and evaluates the predicted video on its own merits
-
[69]
{instruction}
Single binary output: A straightforward 0/1 judgment avoids the need for confidence calibration, vote aggregation, or threshold tuning, making the metric simple and reproducible. Human consistency validation (GR1 split, 48 episodes). We validate the automated evaluator against human-verified labels on 48 GR1 episodes. The evaluator achieves an accuracy of 8...
-
[70]
Is the target object (the object being manipulated) clearly visible in Frame1, without unexpected blurring, occlusion, or disappearance?
-
[71]
Are all objects in Frame1 free of distortion or unnatural deformation?
-
[72]
No explanation
Are there no objects that pop in or pop out unnaturally between frames (appearing or vanishing without physical cause)? Respond ONLY with 0 or 1. No explanation. 1 = Frame1 passes all checks (high quality, matches GT object presence) 0 = Frame1 fails at least one check (object issue, distortion, or pop artifact) Model-level score. The OPS score for a mode...
-
[73]
Simple mean aggregation avoids biasing the score towards any particular phase of the manipulation
Uniform temporal weighting : Object preservation is a frame-level property that should hold throughout the video, not just at the end. Simple mean aggregation avoids biasing the score towards any particular phase of the manipulation
-
[74]
The 0.70 confidence threshold requires a clear majority of frames to pass, catching videos where artefacts appear intermittently
Binary label with conservative threshold : A single preserved/flawed dichotomy reflects the fact that object artefacts are both highly salient and disqualifying for downstream use. The 0.70 confidence threshold requires a clear majority of frames to pass, catching videos where artefacts appear intermittently
-
[75]
looks bad
Object-focused prompt with three explicit checks : Decomposing the quality judgment into three distinct failure modes (visibility, deformation, pop artefacts) guides the VLM towards con- sistent and interpretable binary decisions, reducing false negatives that arise from a holistic “looks bad” judgment. D.2.3 Generalizability (GEN) GEN measures how well a...
-
[76]
Late-phase frame sampling : Frames are extracted at 81–97% progress because perturbation effects (e.g., premature release, grip slip) manifest in the transport and placement phases, not the approach phase
-
[77]
Object-focused prompt: The prompt explicitly directs the model to focus on the manipulated object’s state rather than overall visual similarity, reducing false positives from rendering differ- ences
-
[78]
Separate prompt for text-conditioned models : Text-conditioned models produce stylistically different videos even without perturbation, requiring the lenient prompt to avoid conflating style differences with perturbation effects
-
[79]
A ” (consistent) label and asks the VLM to compare shape, material, size, and colour. Let bobj be the number of pairs voted “B
Zero-shot 78B model vs fine-tuned 8B : We find that a large zero-shot model (InternVL3-78B) outperforms the fine-tuned smaller model (Qwen3-VL-8B SFT) on this binary task, likely be- cause the task requires spatial comparison rather than domain-specific scoring. E Physical Consistency Metric Calibration and Physics Law Compliance Details This appendix gathers...
-
[80]
SC-A1 Color Stability : Does the primary object maintain stable color throughout?
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.