VLA-Pro: Cross-Task Procedural Memory Transfer for Vision-Language-Action Models
Pith reviewed 2026-06-29 07:02 UTC · model grok-4.3
The pith
VLA-Pro stores task-specific LoRA adapters as procedural memories and retrieves plus fuses them at inference to improve cross-task generalization in vision-language-action models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
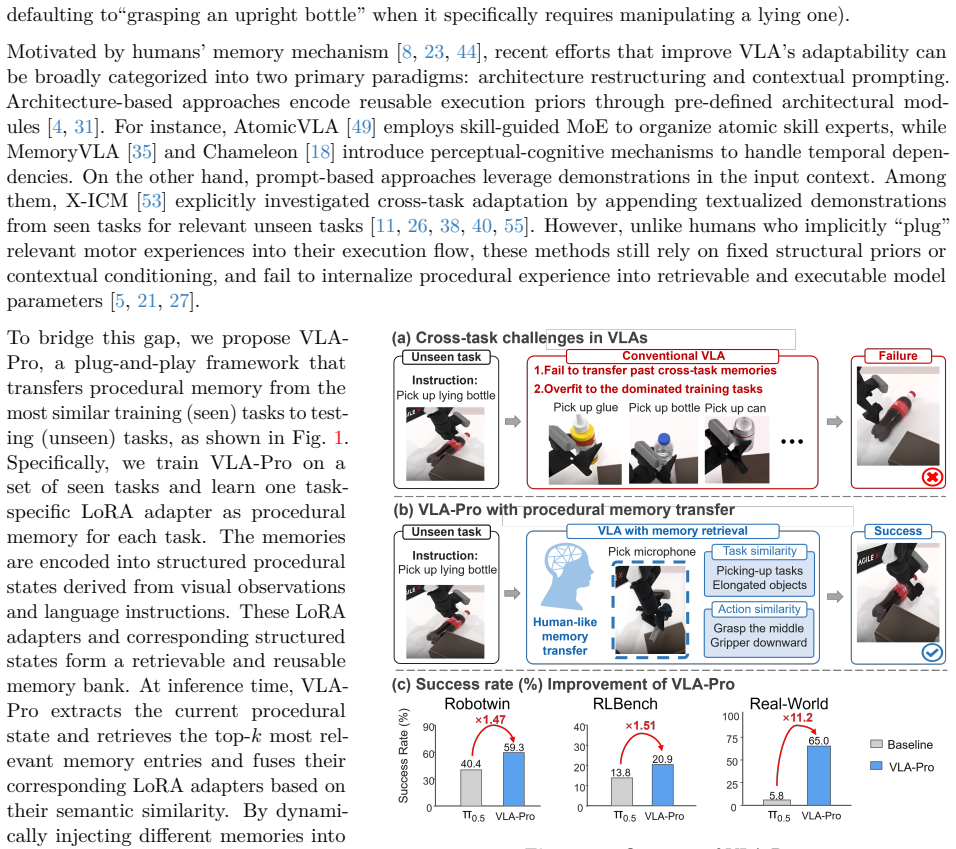
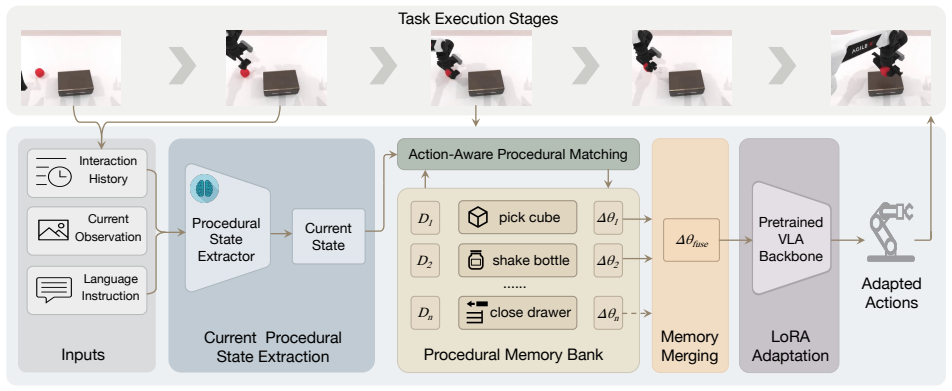
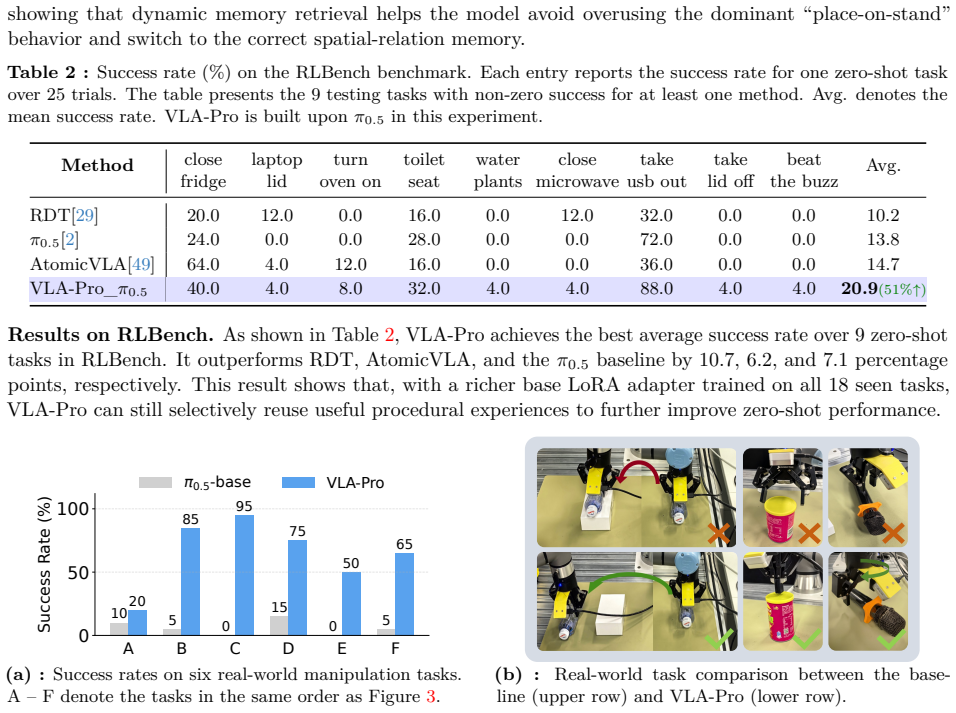
VLA-Pro stores task-specific LoRA adapters as parameterized procedural memories during training. At inference time it retrieves relevant procedural memories based on the current multi-modal context and dynamically fuses these memories for generating the current action chunk. Experiments across RoboTwin, RLBench, and real-world tasks show consistent gains in cross-task generalization on multiple backbones.
What carries the argument
Retrieval of relevant task-specific LoRA adapters followed by dynamic fusion into the current action generation step.
If this is right
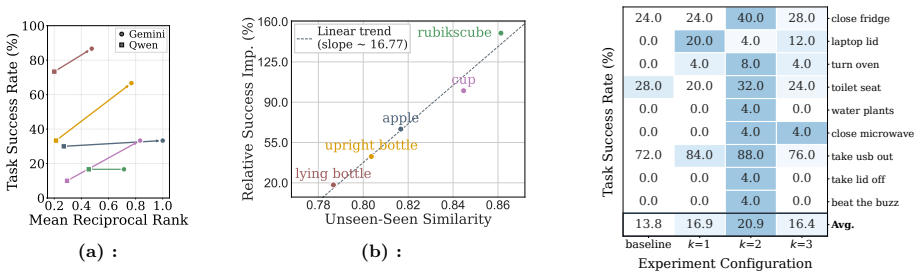
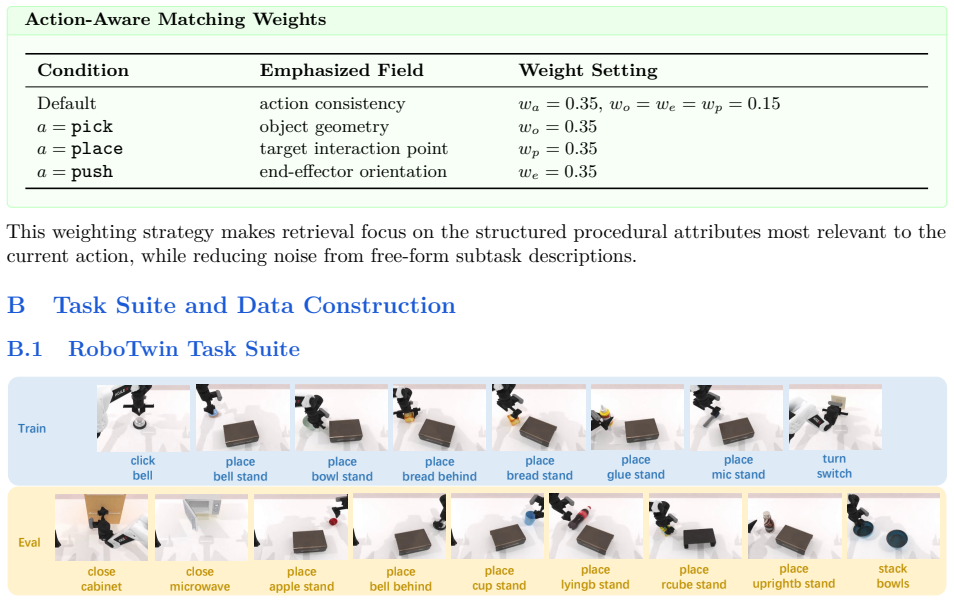
- Cross-task success improves up to 207 percent relative in simulation benchmarks.
- Real-world manipulation success rises from 5.8 percent to 65.0 percent on the tested tasks.
- The same gains appear across different VLA backbones while keeping the original model weights unchanged.
- Procedural memory transfer supplies a route for moving manipulation experience to novel tasks without retraining the full model.
Where Pith is reading between the lines
- A growing library of stored adapters could let a single robot improve over its lifetime by adding new tasks without overwriting old ones.
- The same retrieval-plus-fusion pattern might extend to other sequential decision domains such as navigation or tool use where context cues signal which past skills apply.
- If retrieval accuracy proves the main limit, future work could test whether richer context encoders or learned retrieval policies raise the ceiling further.
Load-bearing premise
Retrieval from multi-modal context will select useful memories and their fusion will add value without causing negative transfer or unstable actions.
What would settle it
A controlled test on held-out tasks where the base VLA model without retrieval matches or exceeds VLA-Pro performance, or where fusion produces visibly unstable robot trajectories.
Figures


read the original abstract
Vision-Language-Action~(VLA) models have shown strong potential for general-purpose robotic manipulation, yet they still struggle to generalize to unseen tasks that necessitate transferring relevant experience across objects, scenes, and action patterns. This paper proposes VLA-Pro, a plug-and-play framework designed to enhance cross-task generalization by storing task-relevant procedural memories at training time and transferring these memories during inference. Specifically, VLA-Pro stores task-specific LoRA adapters as parameterized procedural memories during training. At inference time, VLA-Pro retrieves relevant procedural memories based on the current multi-modal context and dynamically fuses these memories for generating the current action chunk. Experiments on RoboTwin, RLBench, and real-world manipulation tasks show that VLA-Pro consistently improves cross-task generalization across multiple backbones, achieving up to a 207% relative improvement in simulation and increasing real-world success rate from 5.8% to 65.0%. These results suggest that procedural memory retrieval and adaptation provide an effective mechanism for transferring manipulation experience to novel tasks while preserving modularity and execution stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VLA-Pro, a plug-and-play framework for Vision-Language-Action (VLA) models that stores task-specific LoRA adapters as procedural memories during training and, at inference, retrieves relevant memories via multi-modal context similarity and dynamically fuses them to generate action chunks. This is claimed to improve cross-task generalization on RoboTwin, RLBench, and real-world manipulation tasks, with reported gains of up to 207% relative improvement in simulation and real-world success rates rising from 5.8% to 65.0% across multiple backbones.
Significance. If the empirical results hold after addressing the retrieval and fusion assumptions, the work would be significant for offering a modular, parameter-efficient mechanism to transfer manipulation experience across tasks without full retraining, preserving execution stability. The scale of the reported gains suggests potential for practical impact in general-purpose robotics, though the absence of detailed baseline comparisons and negative-transfer controls limits immediate assessment of novelty relative to existing adapter or memory-based methods.
major comments (2)
- [Abstract] Abstract: The central empirical claim (207% relative improvement; 5.8%→65.0% real-world success) is load-bearing, yet no information is supplied on the exact baselines, number of evaluation episodes, data splits, or statistical significance testing; without these, it is impossible to determine whether the gains arise from the retrieval-fusion mechanism or from unaccounted confounds.
- [Method] Method description (inference-time retrieval and fusion): The claim that multi-modal-context retrieval followed by dynamic fusion reliably transfers useful procedural memories without negative transfer rests on the untested assumption that visual-language similarity selects action-compatible LoRA adapters; the manuscript must provide an ablation or failure-case analysis on tasks with similar objects/scenes but divergent action sequences, as mismatch would directly undermine the cross-task generalization results.
minor comments (2)
- [Abstract] Abstract: The phrase 'preserving modularity and execution stability' is asserted without reference to any stability metric or comparison against unfused baselines.
- The manuscript should include a table or figure explicitly listing the backbones tested and the precise retrieval similarity function (e.g., cosine on which embeddings).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the empirical claims and methodological assumptions. We address each major comment point-by-point below, clarifying where details appear in the manuscript and indicating revisions made to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim (207% relative improvement; 5.8%→65.0% real-world success) is load-bearing, yet no information is supplied on the exact baselines, number of evaluation episodes, data splits, or statistical significance testing; without these, it is impossible to determine whether the gains arise from the retrieval-fusion mechanism or from unaccounted confounds.
Authors: The full experimental protocol—including exact baselines (e.g., vanilla VLA, LoRA fine-tuning per task), evaluation episodes (100 per task across 3 random seeds), data splits (train/test task partitions detailed in Section 4.1), and statistical reporting (mean ± std with significance tests)—is provided in Section 4 and Appendix B. The abstract summarizes headline results for brevity. To address the concern, we have revised the abstract to include a one-sentence reference to the evaluation setup and added a compact experimental summary table (Table 1) in the main text. revision: partial
-
Referee: [Method] Method description (inference-time retrieval and fusion): The claim that multi-modal-context retrieval followed by dynamic fusion reliably transfers useful procedural memories without negative transfer rests on the untested assumption that visual-language similarity selects action-compatible LoRA adapters; the manuscript must provide an ablation or failure-case analysis on tasks with similar objects/scenes but divergent action sequences, as mismatch would directly undermine the cross-task generalization results.
Authors: We agree that explicit validation of the retrieval assumption is valuable. We have added a targeted ablation (new Section 4.4) comparing multi-modal retrieval against vision-only and language-only variants on a curated set of tasks with high visual/scene similarity but divergent action sequences (e.g., “pick red block” vs. “push red block” on identical tables). Results show reduced negative transfer with the full multi-modal similarity metric, supported by quantitative success rates and qualitative failure-case analysis. These additions directly test and support the cross-task transfer claims. revision: yes
Circularity Check
No circularity: empirical framework validated on external benchmarks
full rationale
The paper introduces VLA-Pro as a plug-and-play retrieval-and-fusion framework for LoRA adapters in VLA models. No equations, derivations, or first-principles predictions appear in the provided text; the central claims rest on experimental outcomes across RoboTwin, RLBench, and real-world tasks rather than any self-referential fitting or self-citation chain that reduces the result to its inputs by construction. Retrieval and fusion are described as design choices whose effectiveness is measured externally, with no load-bearing step that renames a fit as a prediction or imports uniqueness from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
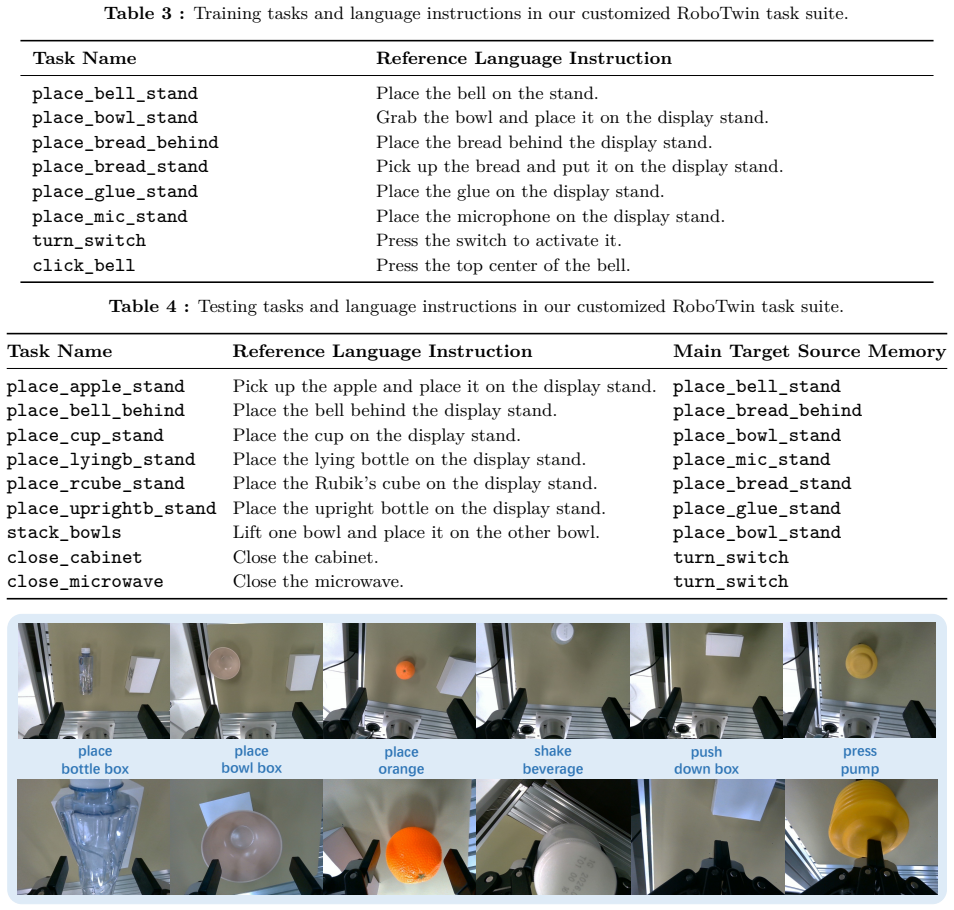
In9th Annual Conference on Robot Learning, 2025
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y Galliker, et al.π0.5: A vision-language-action model with open-world generalization. In9th Annual Conference on Robot Learning, 2025
2025
-
[3]
Rt-1: Robotics transformer for real-world control at scale.Robotics: Science and Systems XIX, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.Robotics: Science and Systems XIX, 2023
2023
-
[4]
RynnVLA-002: A Unified Vision-Language-Action and World Model
Jun Cen, Siteng Huang, Yuqian Yuan, Kehan Li, Hangjie Yuan, Chaohui Yu, Yuming Jiang, Jiayan Guo, Xin Li, Hao Luo, et al. Rynnvla-002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Wei-Chia Chang and Yan-Ann Chen. Zero-shot vehicle model recognition via text-based retrieval-augmented generation.arXiv preprint arXiv:2510.18502, 2025
-
[6]
Queryadapter: Rapid adaptation of vision-language models in response to natural language queries
Nicolas Harvey Chapman, Feras Dayoub, Will Browne, and Christopher Lehnert. Queryadapter: Rapid adaptation of vision-language models in response to natural language queries. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9606–9613. IEEE, 2025
2025
-
[7]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
From Local Corrections to Generalized Skills: Improving Neuro-Symbolic Policies with MEMO
Benjamin A Christie, Yinlong Dai, Mohammad Bararjanianbahnamiri, Simon Stepputtis, and Dylan P Losey. From local corrections to generalized skills: Improving neuro-symbolic policies with memo.arXiv preprint arXiv:2603.04560, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
RoboMME: Benchmarking and Understanding Memory for Robotic Generalist Policies
Yinpei Dai, Hongze Fu, Jayjun Lee, Yuejiang Liu, Haoran Zhang, Jianing Yang, Chelsea Finn, Nima Fazeli, and Joyce Chai. Robomme: Benchmarking and understanding memory for robotic generalist policies.arXiv preprint arXiv:2603.04639, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Palm-e: an embodied multimodal language model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: an embodied multimodal language model. In Proceedings of the 40th International Conference on Machine Learning, pages 8469–8488, 2023
2023
-
[11]
Test-time retrieval-augmented adaptation for vision-language models
Xinqi Fan, Xueli Chen, Luoxiao Yang, Chuin Hong Yap, Rizwan Qureshi, Qi Dou, Moi Hoon Yap, and Mubarak Shah. Test-time retrieval-augmented adaptation for vision-language models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8810–8819, 2025
2025
-
[12]
Long-vla: Unleashing long-horizon capability of vision language action model for robot manipulation
Yiguo Fan, Shuanghao Bai, Xinyang Tong, Pengxiang Ding, Yuyang Zhu, Hongchao Lu, Fengqi Dai, Wei Zhao, Yang Liu, Siteng Huang, et al. Long-vla: Unleashing long-horizon capability of vision language action model for robot manipulation. In9th Annual Conference on Robot Learning, 2025
2025
-
[13]
Kalm: Keypoint abstraction using large models for object-relative imitation learning
Xiaolin Fang, Bo-Ruei Huang, Jiayuan Mao, Jasmine Shone, Joshua B Tenenbaum, Tomás Lozano-Pérez, and Leslie Pack Kaelbling. Kalm: Keypoint abstraction using large models for object-relative imitation learning. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8307–8314. IEEE, 2025
2025
-
[14]
Yuxia Fu, Zhizhen Zhang, Yuqi Zhang, Zijian Wang, Zi Huang, and Yadan Luo. Mergevla: Cross-skill model merging toward a generalist vision-language-action agent.arXiv preprint arXiv:2511.18810, 2025
-
[15]
Rvt-2: Learning precise manipulation from few demonstrations
Ankit Goyal, Valts Blukis, Jie Xu, Yijie Guo, Yu-Wei Chao, and Dieter Fox. Rvt-2: Learning precise manipulation from few demonstrations. InRSS 2024 Workshop: Data Generation for Robotics, 2024
2024
-
[16]
Metaxas, and Ruixiang Tang
Minghao Guo, Qingyue Jiao, Zeru Shi, Yihao Quan, Boxuan Zhang, Danrui Li, Liwei Che, Wujiang Xu, Shilong Liu, Zirui Liu, Mubbasir Kapadia, Vladimir Pavlovic, Jiang Liu, Mengdi Wang, Yiyu Shi, Dimitris N. Metaxas, and Ruixiang Tang. Memeye: A visual-centric evaluation framework for multimodal agent memory, 2026. 11
2026
-
[17]
Deepsieve: Information sieving via llm-as-a-knowledge-router
Minghao Guo, Qingcheng Zeng, Xujiang Zhao, Yanchi Liu, Wenchao Yu, Mengnan Du, Haifeng Chen, and Wei Cheng. Deepsieve: Information sieving via llm-as-a-knowledge-router. InFindings of the Association for Computational Linguistics: EACL 2026, pages 3054–3077, 2026
2026
-
[18]
Chameleon: Control-Indexed Prospective Memory for Visuomotor Manipulation
Xinying Guo, Chenxi Jiang, Hyun Bin Kim, Ying Sun, Yang Xiao, Yuhang Han, and Jianfei Yang. Chameleon: Episodic memory for long-horizon robotic manipulation.arXiv preprint arXiv:2603.24576, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
2020
-
[20]
Robo-abc: Affordance generalization beyond categories via semantic correspondence for robot manipulation
Yuanchen Ju, Kaizhe Hu, Guowei Zhang, Gu Zhang, Mingrun Jiang, and Huazhe Xu. Robo-abc: Affordance generalization beyond categories via semantic correspondence for robot manipulation. InEuropean Conference on Computer Vision, pages 222–239. Springer, 2024
2024
-
[21]
Donghoon Kim, Minji Bae, Unghui Nam, Gyeonghun Kim, Suyun Lee, Kyuhong Shim, and Byonghyo Shim. Adaptive capacity allocation for vision language action fine-tuning.arXiv preprint arXiv:2603.07404, 2026
-
[22]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language-action model. In8th Annual Conference on Robot Learning, 2024
2024
-
[23]
Ram: Retrieval-based affordance transfer for generalizable zero-shot robotic manipulation
Yuxuan Kuang, Junjie Ye, Haoran Geng, Jiageng Mao, Congyue Deng, Leonidas Guibas, He Wang, and Yue Wang. Ram: Retrieval-based affordance transfer for generalizable zero-shot robotic manipulation. In8th Annual Conference on Robot Learning, 2024
2024
-
[24]
Collage: Adaptive fusion-based retrieval for augmented policy learning
Sateesh Kumar, Shivin Dass, Georgios Pavlakos, and Roberto Martín-Martín. Collage: Adaptive fusion-based retrieval for augmented policy learning. InConference on Robot Learning, pages 4607–4624. PMLR, 2025
2025
-
[25]
Multi-agent behavior retrieval: Retrieval-augmented policy training for cooperative push manipulation by mobile robots
So Kuroki, Mai Nishimura, and Tadashi Kozuno. Multi-agent behavior retrieval: Retrieval-augmented policy training for cooperative push manipulation by mobile robots. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 12671–12678. IEEE, 2024
2024
-
[26]
Ra-tta: Retrieval- augmented test-time adaptation for vision-language models
Youngjun Lee, Doyoung Kim, Junhyeok Kang, Jihwan Bang, Hwanjun Song, and Jae-Gil Lee. Ra-tta: Retrieval- augmented test-time adaptation for vision-language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[27]
Zhuoran Li, Zhiyang Li, Kaijun Zhou, and Jinyu Gu. Soma: Strategic orchestration and memory-augmented system for vision-language-action model robustness via in-context adaptation.arXiv preprint arXiv:2603.24060, 2026
-
[28]
Adaptive Action Chunking at Inference-time for Vision-Language-Action Models
Yuanchang Liang, Xiaobo Wang, Kai Wang, Shuo Wang, Xiaojiang Peng, Haoyu Chen, David Kim Huat Chua, and Prahlad Vadakkepat. Adaptive action chunking at inference-time for vision-language-action models.arXiv preprint arXiv:2604.04161, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Coral: Scalable multi-task robot learning via lora experts.arXiv preprint arXiv:2603.09298, 2026
Yuankai Luo, Woping Chen, Tong Liang, and Zhenguo Li. Coral: Scalable multi-task robot learning via lora experts.arXiv preprint arXiv:2603.09298, 2026
-
[31]
Omnirouter: Budget and performance controllable multi-llm routing.ACM SIGKDD Explorations Newsletter, 27(2):107–116, 2025
Kai Mei, Wujiang Xu, Minghao Guo, Shuhang Lin, and Yongfeng Zhang. Omnirouter: Budget and performance controllable multi-llm routing.ACM SIGKDD Explorations Newsletter, 27(2):107–116, 2025
2025
-
[32]
Attributes as operators: factorizing unseen attribute-object compositions
Tushar Nagarajan and Kristen Grauman. Attributes as operators: factorizing unseen attribute-object compositions. InProceedings of the European Conference on Computer Vision (ECCV), pages 169–185, 2018
2018
-
[33]
Jingyuan Qi, Zhiyang Xu, Rulin Shao, Yang Chen, Jin Di, Yu Cheng, Qifan Wang, and Lifu Huang. Rora-vlm: Robust retrieval augmentation for vision language models.arXiv preprint arXiv:2410.08876, 2024
-
[34]
Flower: Democratizing generalist robot policies with efficient vision-language-flow models
Moritz Reuss, Hongyi Zhou, Marcel Rühle, Ömer Erdinç Yağmurlu, Fabian Otto, and Rudolf Lioutikov. Flower: Democratizing generalist robot policies with efficient vision-language-flow models. InConference on Robot Learning, pages 3736–3761. PMLR, 2025. 12
2025
-
[35]
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, and Gao Huang. Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation.arXiv preprint arXiv:2508.19236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
3D-Anchored Lookahead Planning for Persistent Robotic Scene Memory via World-Model-Based MCTS
Bronislav Sidik and Dror Mizrahi. 3d-anchored lookahead planning for persistent robotic scene memory via world-model-based mcts.arXiv preprint arXiv:2604.11302, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Reconvla: Reconstructive vision-language-action model as effective robot perceiver
Wenxuan Song, Ziyang Zhou, Han Zhao, Jiayi Chen, Pengxiang Ding, Haodong Yan, Yuxin Huang, Feilong Tang, Donglin Wang, and Haoang Li. Reconvla: Reconstructive vision-language-action model as effective robot perceiver. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18549–18557, 2026
2026
-
[38]
Ricl: Adding in-context adaptability to pre-trained vision-language-action models
Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, and Insup Lee. Ricl: Adding in-context adaptability to pre-trained vision-language-action models. In9th Annual Conference on Robot Learning, 2025
2025
-
[39]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Sheng Wang. Roboflamingo-plus: Fusion of depth and rgb perception with vision-language models for enhanced robotic manipulation.arXiv preprint arXiv:2503.19510, 2025
-
[41]
Kinematic-aware prompting for generalizable articulated object manipulation with llms
Wenke Xia, Dong Wang, Xincheng Pang, Zhigang Wang, Bin Zhao, Di Hu, and Xuelong Li. Kinematic-aware prompting for generalizable articulated object manipulation with llms. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 2073–2080. IEEE, 2024
2073
-
[42]
Haozhe Xie, Beichen Wen, Jiarui Zheng, Zhaoxi Chen, Fangzhou Hong, Haiwen Diao, and Ziwei Liu. Dynamicvla: A vision-language-action model for dynamic object manipulation.arXiv preprint arXiv:2601.22153, 2026
-
[43]
Yiweng Xie, Bo He, Junke Wang, Xiangyu Zheng, Ziyi Ye, and Zuxuan Wu. Fluxmem: Adaptive hierarchical memory for streaming video understanding.arXiv preprint arXiv:2603.02096, 2026
-
[44]
Zero-shot robotic manipulation via 3d gaussian splatting-enhanced multimodal retrieval-augmented generation
Zilong Xie, Jingyu Gong, Xin Tan, Zhizhong Zhang, and Yuan Xie. Zero-shot robotic manipulation via 3d gaussian splatting-enhanced multimodal retrieval-augmented generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18683–18691, 2026
2026
-
[45]
Vision-language-action instruction tuning: From understanding to manipulation
Shuai Yang, Hao Li, Bin Wang, Yilun Chen, Yang Tian, Tai Wang, Hanqing Wang, Feng Zhao, Yiyi Liao, and Jiangmiao Pang. Vision-language-action instruction tuning: From understanding to manipulation. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[46]
Jinhui Ye, Fangjing Wang, Ning Gao, Junqiu Yu, Yangkun Zhu, Bin Wang, Jinyu Zhang, Weiyang Jin, Yanwei Fu, Feng Zheng, et al. St4vla: Spatially guided training for vision-language-action models.arXiv preprint arXiv:2602.10109, 2026
-
[47]
Learning llm-as-a-judge for preference alignment
Ziyi Ye, Xiangsheng Li, Qiuchi Li, Qingyao Ai, Yujia Zhou, Wei Shen, Dong Yan, and Yiqun Liu. Learning llm-as-a-judge for preference alignment. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[48]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. InICRA 2024 Workshop on 3D Visual Representations for Robot Manipulation, 2024
2024
-
[49]
Likui Zhang, Tao Tang, Zhihao Zhan, Xiuwei Chen, Zisheng Chen, Jianhua Han, Jiangtong Zhu, Pei Xu, Hang Xu, Hefeng Wu, et al. Atomicvla: Unlocking the potential of atomic skill learning in robots.arXiv preprint arXiv:2603.07648, 2026
-
[50]
Align-then-steer: Adapting the vision-language action models through unified latent guidance
Yang Zhang, Chenwei Wang, Ouyang Lu, Yuan Zhao, Yunfei Ge, Zhenglong Sun, Xiu Li, Chi Zhang, Chenjia Bai, and Xuelong Li. Align-then-steer: Adapting the vision-language action models through unified latent guidance. arXiv preprint arXiv:2509.02055, 2025
-
[51]
Yuelin Zhang, Sijie Cheng, Chen Li, Zongzhao Li, Yuxin Huang, Yang Liu, and Wenbing Huang. Recurrent reasoning with vision-language models for estimating long-horizon embodied task progress.arXiv preprint arXiv:2603.17312, 2026. 13
-
[52]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Exploring the limits of vision-language-action manipulation in cross-task generalization
Jiaming Zhou, Ke Ye, Teli Ma, Zifan Wang, Ronghe Qiu, Kun-Yu Lin, Zhilin Zhao, Junwei Liang, et al. Exploring the limits of vision-language-action manipulation in cross-task generalization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[54]
Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning
Zewei Zhou, Tianhui Cai, Seth Z Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[55]
Retrieval-augmented embodied agents
Yichen Zhu, Zhicai Ou, Xiaofeng Mou, and Jian Tang. Retrieval-augmented embodied agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17985–17995, 2024
2024
-
[56]
subtask":
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In7th Annual Conference on Robot Learning, 2023. 14 A Procedural Memory Storage and Retrieval A.1 Prompt for Procedural State Extraction We use the...
2023
-
[57]
No markdown, no comments, no trailing commas
Output JSON only. No markdown, no comments, no trailing commas
-
[58]
Keep exactly the keys shown above
Do not add/remove keys. Keep exactly the keys shown above
-
[59]
place-on-stand
Use ONLY one of the allowed enum values. A.2 Procedural State Schema and Matching Weights This section summarizes the procedural state schema for RoboTwin tasks and the matching weights used in Action-Aware Procedural Matching. The free-formsubtask field is only used for readability and debugging, and is excluded from similarity computation to avoid seman...
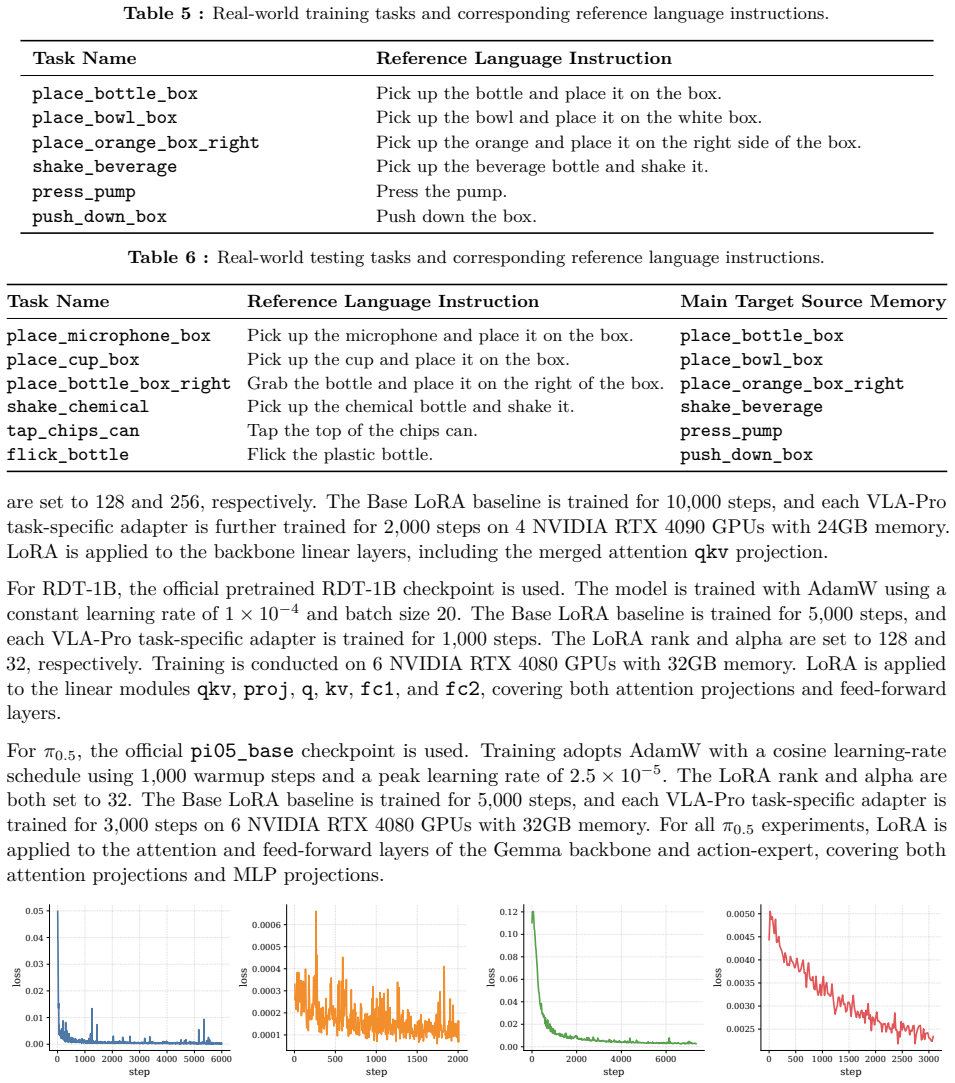
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.