Opir: Efficient Multi-Task Safety Classification for Toxicity, Jailbreaks, Hate Speech, and Harmful Content
Pith reviewed 2026-06-29 09:09 UTC · model grok-4.3
The pith
Opir encoder models match or exceed open-weight guardrails on safety benchmarks with far fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
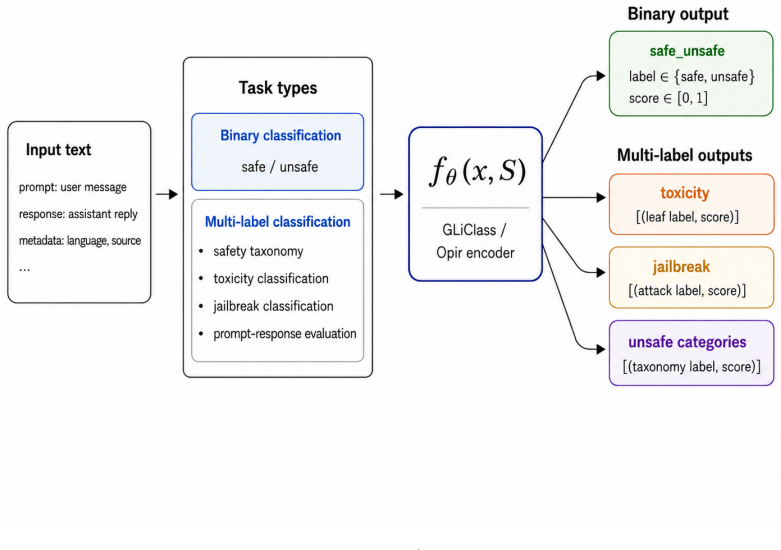
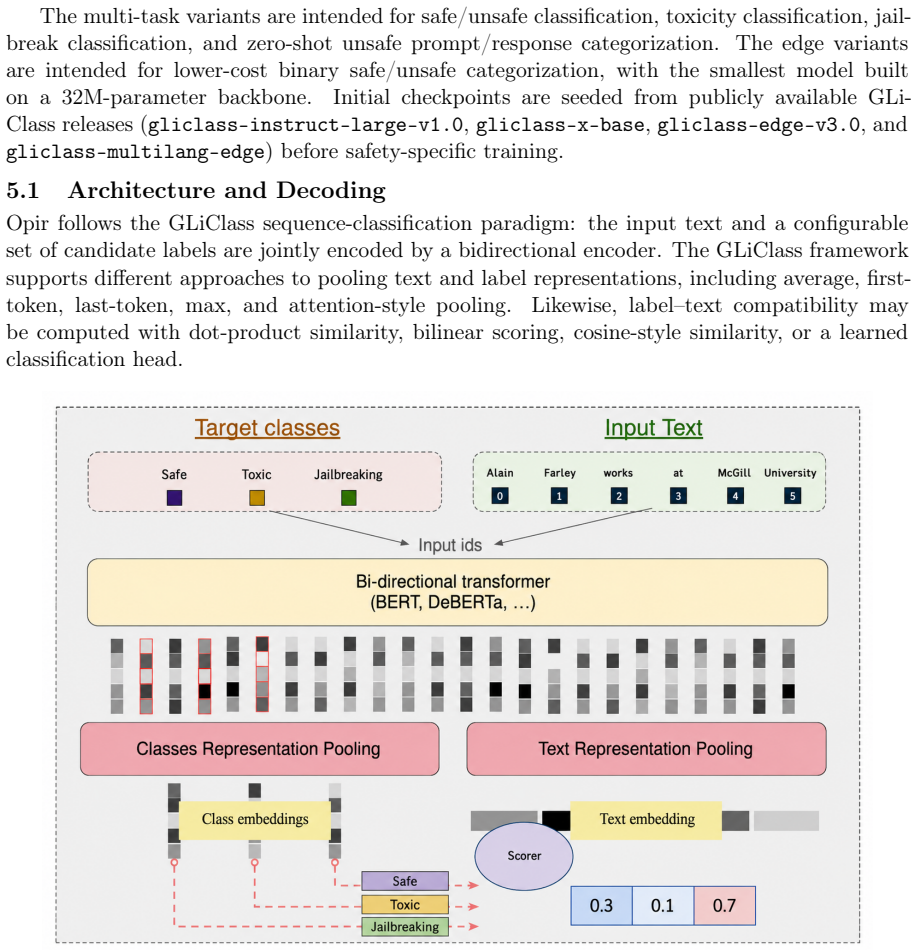
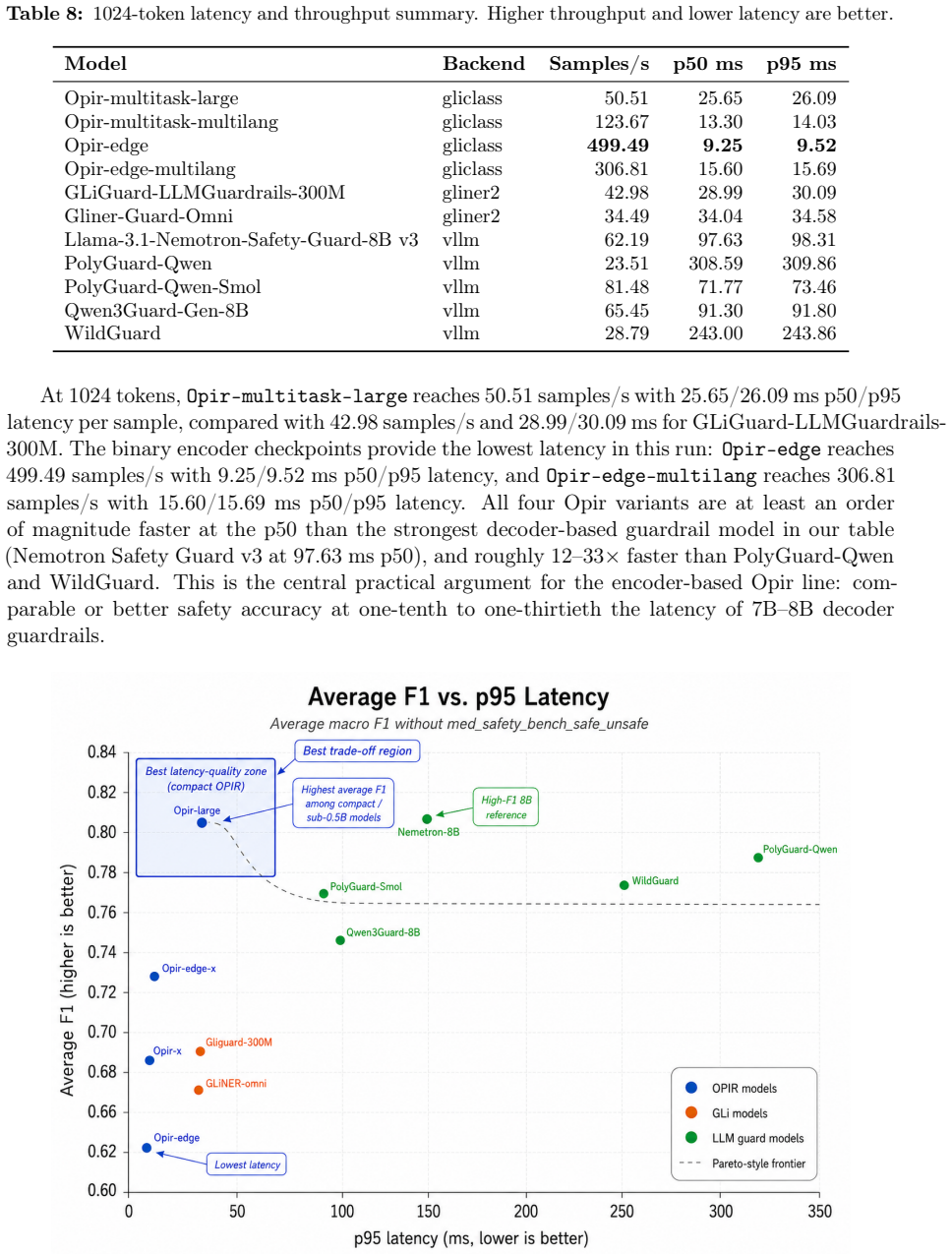
Opir is a family of GLiClass architecture encoder-based guardrail models trained on a three-level taxonomy of 996 categories. The training data includes taxonomy-grounded unsafe prompts, adversarially mined hard negatives, benign safety-preserving examples, generated response examples, multilingual translations, and portions of the Aegis2 and WildGuard training subsets. Variants handle binary safe/unsafe classification, multi-label toxicity classification, jailbreak classification, and zero-shot unsafe prompt and response categorization, with edge variants under 100M parameters. Across 12 safety-classification tasks and 17 category tasks against eight contemporary guardrail systems, Opir var
What carries the argument
GLiClass architecture encoder models trained on a three-level taxonomy with 996 categories using taxonomy-grounded data combined with adversarially mined hard negatives for multi-task safety classification.
If this is right
- Real-time safety filtering for LLM applications becomes possible without the inference cost of large guardrail models.
- Multi-task handling allows simultaneous binary classification, toxicity labeling, jailbreak detection, and zero-shot subcategory assignment.
- Edge variants under 100M parameters enable deployment in resource-limited environments for binary safe/unsafe decisions.
- The open evaluation harness supports consistent testing of GLiClass, GLiNER2, and decoder-based models on prompt and response safety.
- Distinction between benign sensitive text and covert harmful content improves across multilingual and response-level tasks.
Where Pith is reading between the lines
- Compact size could allow direct embedding of safety checks inside LLM serving stacks rather than separate API calls.
- The adversarial mining technique might transfer to training classifiers for other high-stakes detection domains.
- Zero-shot capability on the leaf labels could reduce the need for retraining when new harmful categories emerge.
- Smaller footprint lowers the barrier for independent developers to run custom safety layers on consumer hardware.
Load-bearing premise
The specific mix of taxonomy-grounded data, adversarially mined negatives, and benchmark subsets produces models that generalize beyond the 12 safety and 17 category tasks evaluated.
What would settle it
A new test set of jailbreak attempts or harmful categories outside the 996-category taxonomy where Opir variants show large performance drops compared to the reported baselines.
Figures

read the original abstract
Real-time safety filtering for large language model (LLM) applications requires classifiers that can detect unsafe prompts, toxic language, jailbreak attempts, and unsafe responses without the cost profile of large guardrail models, and that can distinguish benign sensitive text from genuinely covert harmful content. In this paper, we introduce Opir, a family of encoder-based guardrail models built on the GLiClass architecture. Opir includes multi-task models for binary safe/unsafe classification, multi-label toxicity classification, jailbreak classification, and zero-shot unsafe prompt and response categorization. We also release edge variants with fewer than 100M parameters dedicated to binary safe/unsafe categorization. The models are trained on a three-level taxonomy containing 996 categories across 16 top-level labels, 126 mid-level labels, and 854 leaf labels. Opir's training data combines taxonomy-grounded unsafe prompts, adversarially mined hard negatives, benign safety-preserving examples, generated response examples, multilingual translations, and portions of the Aegis2 and WildGuard training subsets. We also open-sourced an evaluation harness that supports GLiClass and GLiNER2 backends as well as decoder-based models, and covers binary safety classification, multi-label categorization, toxicity, jailbreak detection, prompt safety, response safety, response refusal, and prompt subcategory views across public benchmark families. Across an expanded comparison spanning 12 safety-classification tasks and 17 category tasks against eight contemporary guardrail systems -- including both GLiNER2-based and generative guardrail models -- Opir variants are competitive on or ahead of the strongest open-weight baselines on the majority of benchmark datasets while operating with a substantially smaller deployment footprint.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Opir, a family of encoder-based guardrail models built on the GLiClass architecture for multi-task safety classification. This includes binary safe/unsafe detection, multi-label toxicity classification, jailbreak classification, and zero-shot unsafe prompt/response categorization into a three-level taxonomy (996 categories). Models are trained on taxonomy-grounded unsafe prompts, adversarially mined hard negatives, benign examples, generated responses, multilingual data, and subsets from Aegis2 and WildGuard. Edge variants (<100M parameters) target binary classification. The authors also release an open evaluation harness supporting GLiClass/GLiNER2 and decoder models across binary safety, multi-label, toxicity, jailbreak, prompt/response safety, and subcategory tasks. The central claim is that Opir variants are competitive with or ahead of the strongest open-weight baselines on the majority of 12 safety-classification tasks and 17 category tasks while using a substantially smaller deployment footprint.
Significance. If the reported results hold, the work is significant for enabling efficient, real-time safety filtering in LLM applications at lower computational cost than large guardrail models. The multi-task and zero-shot design, combined with the detailed taxonomy, supports practical deployment. The open-sourced evaluation harness is a clear strength for reproducibility and standardized benchmarking in the field.
minor comments (3)
- [Abstract] Abstract: The abstract asserts competitive performance across tasks but does not report any quantitative metrics (e.g., F1, accuracy) or specific baseline comparisons; adding 1-2 key headline numbers would make the central claim immediately verifiable.
- The manuscript would benefit from a dedicated limitations or error-analysis subsection (e.g., failure modes on particular taxonomy leaves or multilingual cases) to complement the benchmark results.
- Ensure the released evaluation harness repository link and exact version/commit are stated explicitly in the main text and reproducibility statement.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the work's significance for efficient safety filtering, and recommendation of minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The manuscript describes an empirical ML contribution: encoder-based guardrail models trained on an explicitly enumerated data mixture (taxonomy-grounded prompts, adversarial negatives, Aegis2/WildGuard subsets, etc.) and evaluated on 12 safety-classification plus 17 category tasks against eight external baselines. No derivation chain, equations, fitted-parameter predictions, or self-citation load-bearing steps appear. All performance claims are scoped to the stated open evaluation harness and rest on direct comparisons to public benchmarks and prior systems, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
free parameters (2)
- Edge variant parameter count =
<100M
- Taxonomy granularity =
16 top-level, 126 mid-level, 854 leaf
axioms (2)
- domain assumption GLiClass encoder architecture supports effective multi-task adaptation for safety classification
- domain assumption The described data sources produce generalizable safety classifiers
Reference graph
Works this paper leans on
-
[1]
Are you still on track!? catching LLM task drift with activations.arXiv preprint arXiv:2406.00799,
Sahar Abdelnabi, Aideen Fay, Giovanni Cherubin, Ahmed Salem, Mario Fritz, and Andrew Paverd. Are you still on track!? catching LLM task drift with activations.arXiv preprint arXiv:2406.00799,
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Sergei Bogdanov, Alexandre Constantin, Timothée Bernard, Benoit Crabbé, and Etienne Bernard. NuNER: Entity recognition encoder pre-training via LLM-annotated data.arXiv preprint arXiv:2402.15343,
-
[4]
Jack Boylan et al. GLiREL: Generalist lightweight model for zero-shot relation extraction.arXiv preprint arXiv:2501.03172,
-
[5]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong. JailbreakBench: An open robustness benchmark for jailbreaking large language models.arXiv preprint arXiv:2404.01318, 2024a. Patrick Chao, Alexander Ro...
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[6]
URL:https://arxiv.org/abs/2405.20947, doi:10.48550/arXiv.2405.20947, arXiv:2405.20947
Justin Cui, Wei-Lin Chiang, Ion Stoica, and Cho-Jui Hsieh. OR-Bench: An over-refusal bench- mark for large language models.arXiv preprint arXiv:2405.20947,
-
[7]
RTP- LX: Can LLMs evaluate toxicity in multilingual scenarios?arXiv preprint arXiv:2404.14397,
Adrian de Wynter, Ishaan Watts, Tua Altintoprak, Chiao-Wen Wang, Lena Stevens, et al. RTP- LX: Can LLMs evaluate toxicity in multilingual scenarios?arXiv preprint arXiv:2404.14397,
-
[8]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. AgentDojo: A dynamic environment to evaluate attacks and defenses for LLM agents.arXiv preprint arXiv:2406.13352,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Multilingual jailbreak challenges in large language models.arXiv preprint arXiv:2310.06474,
Yue Deng, Wenxuan Zhang, Sinno Jialin Pan, and Lidong Bing. Multilingual jailbreak challenges in large language models.arXiv preprint arXiv:2310.06474,
-
[10]
garak: A framework for security probing large language models.arXiv preprint arXiv:2406.11036,
Leon Derczynski, Erick Galinkin, Jeffrey Martin, Subho Majumdar, and Nanna Inie. garak: A framework for security probing large language models.arXiv preprint arXiv:2406.11036,
-
[11]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Shaona Ghosh, Prasoon Varshney, Erick Galinkin, and Christopher Parisien. AEGIS: On- line adaptive AI content safety moderation with ensemble of LLM experts.arXiv preprint arXiv:2404.05993,
-
[13]
Shaona Ghosh, Prasoon Varshney, Makesh Narsimhan Sreedhar, Aishwarya Padmakumar, Tra- ian Rebedea, Jibin Rajan Varghese, and Christopher Parisien. Aegis2.0: A diverse AI safety dataset and risks taxonomy for alignment of LLM guardrails.arXiv preprint arXiv:2501.09004,
-
[14]
Model card.https://huggingface.co/google/shieldgemma-2-4b-it. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. WildGuard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLMs.arXiv preprint arXiv:2406.18495,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. DeBERTa: Decoding-enhanced BERT with disentangled attention.arXiv preprint arXiv:2006.03654,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[17]
Pengcheng He, Jianfeng Gao, and Weizhu Chen. DeBERTaV3: Improving DeBERTa using ELECTRA-style pre-training with gradient-disentangled embedding sharing.arXiv preprint arXiv:2111.09543,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
IBM Granite Team. Granite 3.0 language models, 2024.https://www.ibm.com/granite. Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama guard: LLM-based input-output safeguard for human-AI conversations.arXiv preprint arXiv:2312.06674,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
PAN 2012: Sexual predator identification task,
Giacomo Inches and Fabio Crestani. PAN 2012: Sexual predator identification task,
2012
-
[20]
Devansh Jain, Priyanshu Kumar, Samuel Gehman, Xuhui Zhou, Thomas Hartvigsen, and Maarten Sap
Working Notes Papers of the CLEF 2012 Evaluation Labs. Devansh Jain, Priyanshu Kumar, Samuel Gehman, Xuhui Zhou, Thomas Hartvigsen, and Maarten Sap. PolyglotToxicityPrompts: Multilingual evaluation of neural toxic degeneration in large language models.arXiv preprint arXiv:2405.09373,
-
[21]
Ettin: A compact encoder family for edge deployment, 2025a
JHU-CLSP. Ettin: A compact encoder family for edge deployment, 2025a. Model card.https: //huggingface.co/jhu-clsp/ettin-encoder-32m. JHU-CLSP. mmBERT: Multilingual compact encoders for edge deployment, 2025b. Model card. https://huggingface.co/jhu-clsp/mmBERT-small. Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Ruiyang Sun, Yizhou Wa...
-
[22]
Jiaming Ji, Donghai Hong, Borong Zhang, Boyuan Chen, Josef Dai, Boren Zheng, Tianyi Qiu, Boxun Li, and Yaodong Yang. PKU-SafeRLHF: Towards multi-level safety alignment for LLMs with human preference.arXiv preprint arXiv:2406.15513,
-
[23]
PolyGuard: A multilingual safety moderation tool for 17 languages.arXiv preprint arXiv:2504.04377,
Priyanshu Kumar, Devansh Jain, Akhila Yerukola, Liwei Jiang, Himanshu Beniwal, Thomas Hartvigsen, and Maarten Sap. PolyGuard: A multilingual safety moderation tool for 17 languages.arXiv preprint arXiv:2504.04377,
-
[24]
Lijun Li, Bowen Dong, Ruohui Wang, Xuhao Hu, Wangmeng Zuo, Dahua Lin, Yu Qiao, and Jing Shao. SALAD-Bench: A hierarchical and comprehensive safety benchmark for large language models.arXiv preprint arXiv:2402.05044,
-
[25]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. AutoDAN: Generating stealthy jail- break prompts on aligned large language models.arXiv preprint arXiv:2310.04451,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Tree of attacks: Jailbreaking black-box LLMs automatically.arXiv preprint arXiv:2312.02119,
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black-box LLMs automatically.arXiv preprint arXiv:2312.02119,
-
[28]
URLhttps://arxiv.org/abs/2605.05277. NVIDIA. Nemotron-content-safety-reasoning-4b,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Model card.https://huggingface.co/ nvidia/Nemotron-Content-Safety-Reasoning-4B. OWASP Foundation. OWASP top 10 for LLM applications 2025, 2025.https://owasp.org/ www-project-top-10-for-large-language-model-applications/. InkitPadhi, ManishNagireddy, GiandomenicoCornacchia, SubhajitChaudhury, TejaswiniPeda- pati, Pierre Dognin, Keerthiram Murugesan, Erik M...
-
[30]
Red Teaming Language Models with Language Models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models.arXiv preprint arXiv:2202.03286,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
arXiv preprint arXiv:2512.20293. Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. “do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models.arXiv preprint arXiv:2308.03825,
-
[32]
Ihor Stepanov and Mykhailo Shtopko. GLiNER multi-task: Generalist lightweight model for various information extraction tasks.arXiv preprint arXiv:2406.12925,
-
[33]
Ihor Stepanov, Mykhailo Shtopko, Dmytro Vodianytskyi, Oleksandr Lukashov, Alexander Ya- vorskyi, and Mykyta Yaroshenko. GLiClass: Generalist lightweight model for sequence classi- fication tasks.arXiv preprint arXiv:2508.07662,
-
[34]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Efficientfew-shotlearningwithoutprompts.arXiv preprint arXiv:2209.11055,
Lewis Tunstall, Nils Reimers, Unso Eun Seo Jo, Luke Bates, Daniel Korat, Moshe Wasserblat, andOrenPereg. Efficientfew-shotlearningwithoutprompts.arXiv preprint arXiv:2209.11055,
-
[36]
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating LLM generations with a panel of diverse models.arXiv preprint arXiv:2404.18796,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Bertie Vidgen, Nino Scherrer, Hannah Rose Kirk, Rebecca Qian, Anand Kannappan, Scott A. Hale, and Paul Röttger. SimpleSafetyTests: a test suite for identifying critical safety risks in large language models.arXiv preprint arXiv:2311.08370,
-
[38]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training LLMs to prioritize privileged instructions.arXiv preprint arXiv:2404.13208,
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Tinghao Wang, Shasha Xie, Jingyi Mu, Vishal Asnani, et al. Sorry-Bench: Systematically evaluating large language model safety refusal behaviors.arXiv preprint arXiv:2406.14598, 2024a. Wenxuan Wang, Zhaopeng Tu, Chang Chen, Youliang Yuan, Jen-tse Huang, Wenxiang Jiao, and Michael R. Lyu. All languages matter: On the multilingual safety of large language mo...
-
[40]
WizardLM: Empowering large pre-trained language models to follow complex instructions
Blog post. https://simonwillison.net/2022/Sep/12/prompt-injection/. 19 Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. WizardLM: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
An Yang, Baosong Yang, et al. Qwen 3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Urchade Zaratiana, Nadi Tomeh, Pierre Holat, and Thierry Charnois. GLiNER: General- ist model for named entity recognition using bidirectional transformer.arXiv preprint arXiv:2311.08526,
-
[43]
GLiGuard: Schema-Conditioned Classification for LLM Safeguard
URLhttps://arxiv.org/abs/2605.07982. Wenjun Zeng, Yuchi Liu, Ryan Mullins, Ludovic Peran, Joe Fernandez, Hamza Harvey, Karthik Chitre, Jeremy Brunner, Steven Dean, and Andrew Wang. ShieldGemma: Generative AI content moderation based on Gemma.arXiv preprint arXiv:2407.21772,
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena.arXiv preprint arXiv:2306.05685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adver- sarial attacks on aligned language models.arXiv preprint arXiv:2307.15043,
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Leaves” column are the number of Level 3 labels in the subcat- egory; the “Representative leaves
20 A Taxonomy Detail This appendix lists the Level 2 subcategories and representative Level 3 leaf labels under each Level 1 category. Counts in the “Leaves” column are the number of Level 3 labels in the subcat- egory; the “Representative leaves” column shows a non-exhaustive sample. toxicity Subcategory Leaves Representative leaves harassment_and_abuse ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.