Why Specialist Models Still Matter: A Heterogeneous Multi-Agent Paradigm for Medical Artificial Intelligence
Pith reviewed 2026-06-29 07:41 UTC · model grok-4.3
The pith
Specialist models remain essential because their collaboration with generalist LLMs outperforms either type alone on clinical tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
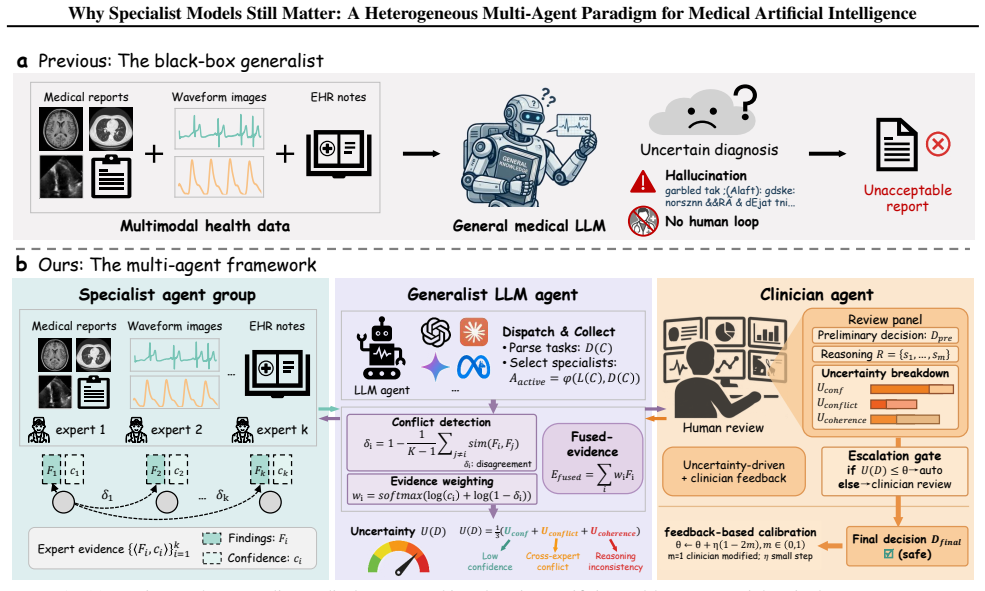
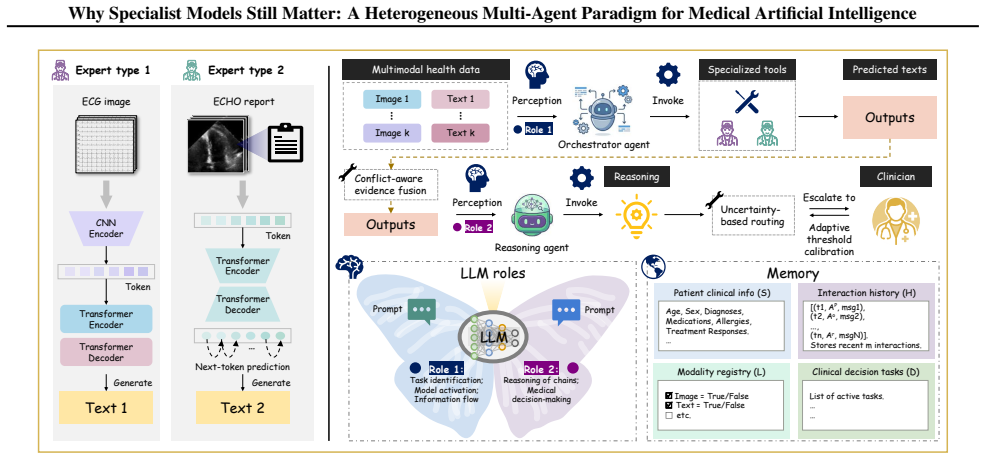
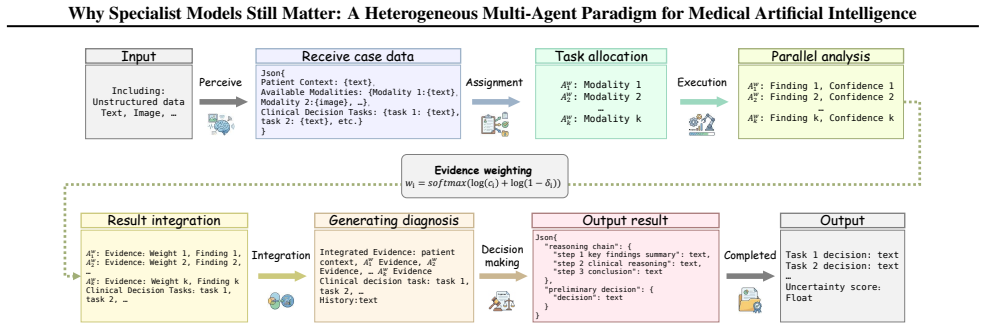
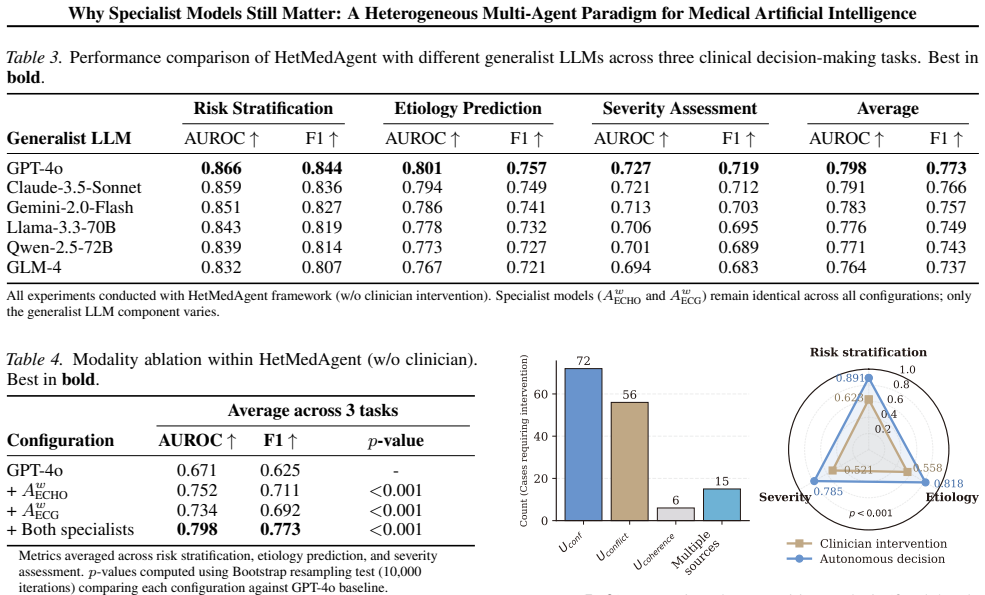
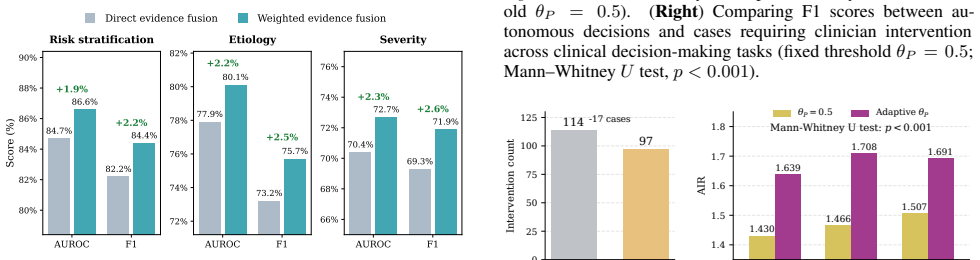
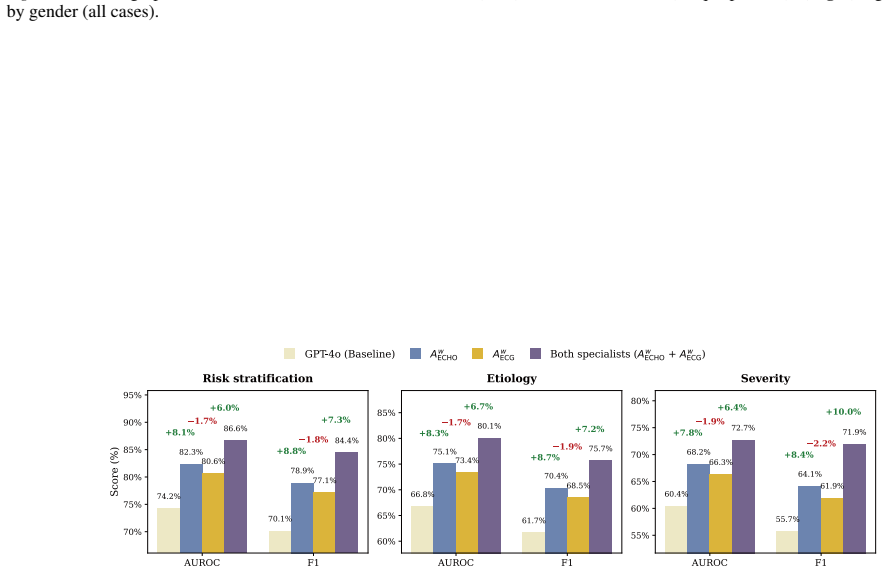
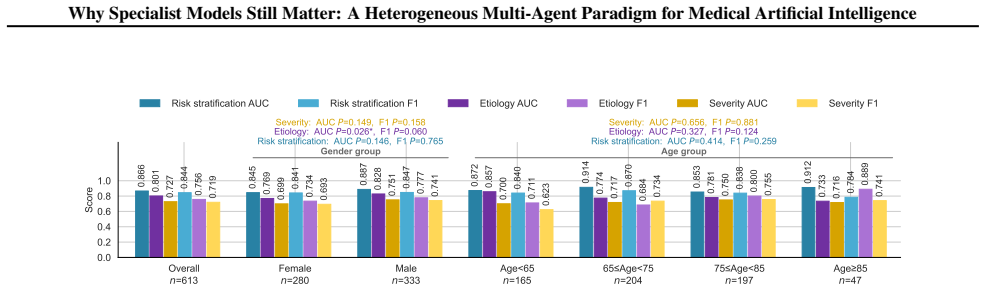
The central claim is that a heterogeneous multi-agent framework called HetMedAgent, which coordinates generalist LLMs with domain-specific specialist models and clinicians through conflict-aware evidence fusion, uncertainty-triggered intervention, and adaptive calibration, produces significantly higher performance on three real-world clinical decision-making tasks than using generalist LLMs or specialist models in isolation.
What carries the argument
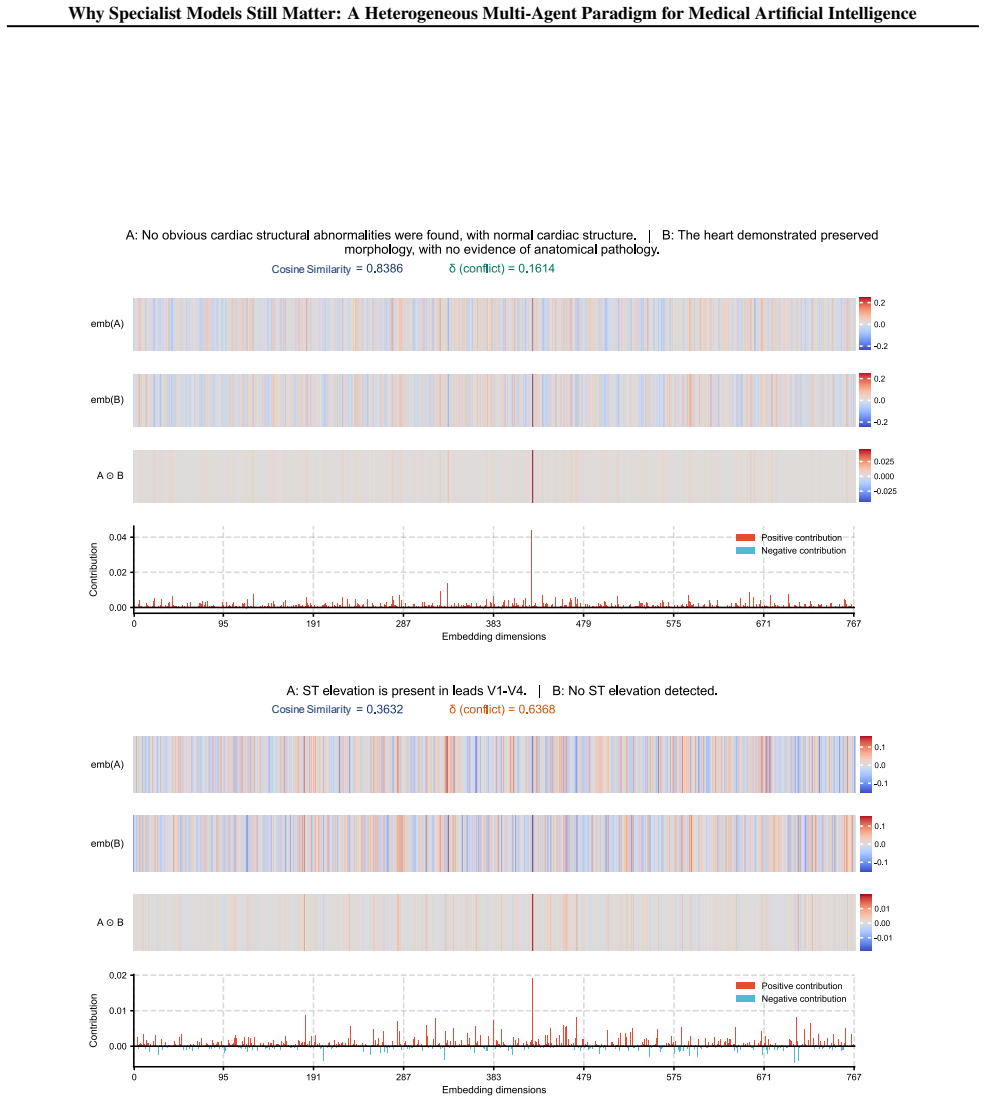
HetMedAgent, a heterogeneous medical multi-agent framework that enables conflict-aware evidence fusion, uncertainty-based clinician intervention triggering, and adaptive threshold calibration.
If this is right
- Specialist models hold irreplaceable value for modality-specific medical analysis.
- Medical AI development should move from monolithic foundation models toward multi-agent collaboration.
- The approach balances broad reasoning from generalist models with the precision of specialists.
- Clinician intervention can be triggered selectively based on model uncertainty.
Where Pith is reading between the lines
- Medical AI systems may benefit from explicit interfaces that let different model types exchange evidence rather than competing as replacements.
- The same collaboration pattern could be tested in other high-stakes domains where general and specialized tools coexist.
- Future work could examine whether the performance edge persists when specialist models are updated independently of the generalist LLM.
Load-bearing premise
The three chosen real-world clinical tasks and the selected specialist models are representative enough for performance gains to be credited to the collaboration rather than to task-specific details or implementation choices.
What would settle it
Running the same framework on a fourth independent clinical task where the combined system shows no advantage over the stronger of the two model types used alone.
Figures




read the original abstract
The impressive performance of generalist large language models (LLMs) such as GPT and Claude in healthcare raises a critical question: will domain-specific medical specialist models become obsolete? We argue that the future of medical artificial intelligence (AI) lies not in building monolithic medical foundation models, nor in replacing human expertise, but in orchestrating collaboration among generalist LLMs, domain-specific specialist models, and clinicians. We propose HetMedAgent, a heterogeneous medical multi-agent framework that enables conflict-aware evidence fusion, uncertainty-based clinician intervention triggering, and adaptive threshold calibration. Experiments on three real-world clinical decision-making tasks demonstrate that the synergy between generalist LLMs and domain-specific specialist models significantly outperforms using either type of model alone, validating the irreplaceable value of specialist models in modality-specific analysis. HetMedAgent represents a shift from building medical LLMs or foundation models to multi-agent collaboration, achieving a balance between general reasoning capabilities and domain-specific precision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that specialist models remain essential in medical AI and proposes HetMedAgent, a heterogeneous multi-agent framework that orchestrates generalist LLMs, domain-specific specialist models, and clinicians via conflict-aware evidence fusion, uncertainty-based intervention triggering, and adaptive threshold calibration. It claims that experiments on three real-world clinical decision-making tasks demonstrate that this synergy significantly outperforms using either model type alone, validating the irreplaceable role of specialists in modality-specific analysis.
Significance. If the reported performance gains are robustly demonstrated with proper controls, the work could support a shift from monolithic medical foundation models toward multi-agent collaboration paradigms that combine general reasoning with domain precision. The proposed mechanisms (conflict-aware fusion and uncertainty triggering) provide a concrete integration strategy worth further exploration in clinical settings.
major comments (1)
- [Abstract] Abstract: The central claim that 'the synergy ... significantly outperforms using either type of model alone' on three tasks supplies no task definitions, specialist model choices, baselines (generalist-only, specialist-only, or simple ensembles), metrics, statistical tests, or ablation controls. This absence makes it impossible to attribute gains to the proposed conflict-aware fusion or uncertainty triggering rather than task artifacts or implementation details, rendering the validation of specialist models' value untestable.
minor comments (1)
- [Abstract] The abstract introduces the term 'HetMedAgent' and its components without a high-level architectural diagram or pseudocode that would clarify the interaction flow among agents.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater specificity in the abstract. We address this point below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the synergy ... significantly outperforms using either type of model alone' on three tasks supplies no task definitions, specialist model choices, baselines (generalist-only, specialist-only, or simple ensembles), metrics, statistical tests, or ablation controls. This absence makes it impossible to attribute gains to the proposed conflict-aware fusion or uncertainty triggering rather than task artifacts or implementation details, rendering the validation of specialist models' value untestable.
Authors: We agree the abstract is high-level and omits these specifics due to length constraints. The full manuscript defines the three clinical tasks, specifies the specialist models used for each modality, details the baselines (generalist-only, specialist-only, and simple ensembles), reports metrics with statistical tests, and includes ablations on the fusion and triggering components. We will revise the abstract to include concise references to tasks, key metrics, and controls to make the claim more testable from the abstract alone. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes HetMedAgent as a multi-agent framework and supports its value via experimental results on three clinical tasks. No equations, fitted parameters, self-referential derivations, or load-bearing self-citations appear in the provided text. The central claim rests on empirical outperformance rather than any mathematical reduction to inputs by construction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- adaptive threshold calibration parameters
axioms (1)
- domain assumption Specialist models supply modality-specific analysis that generalist LLMs cannot replicate at equivalent precision.
invented entities (1)
-
HetMedAgent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
The claude 3 model family: Opus, sonnet, haiku
Anthropic AI . The claude 3 model family: Opus, sonnet, haiku. Claude-3 Model Card, 1 0 (1): 0 4, 2024
2024
-
[3]
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
Chen, Z., Cano, A. H., Romanou, A., Bonnet, A., Matoba, K., Salvi, F., Pagliardini, M., Fan, S., K \"o pf, A., Mohtashami, A., et al. Meditron-70b: Scaling medical pretraining for large language models. arXiv preprint arXiv:2311.16079, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Cohen, I. G. and Mello, M. M. Hipaa and protecting health information in the 21st century. JAMA, 320 0 (3): 0 231--232, 2018
2018
-
[5]
S., and Jurdak, R
Dorri, A., Kanhere, S. S., and Jurdak, R. Multi-agent systems: A survey. IEEE Access, 6: 0 28573--28593, 2018
2018
-
[6]
A., Ko, J., Swetter, S
Esteva, A., Kuprel, B., Novoa, R. A., Ko, J., Swetter, S. M., Blau, H. M., and Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature, 542 0 (7639): 0 115--118, 2017
2017
-
[7]
Ethical and legal challenges of artificial intelligence-driven healthcare
Gerke, S., Minssen, T., and Cohen, G. Ethical and legal challenges of artificial intelligence-driven healthcare. In Artificial intelligence in healthcare, pp.\ 295--336. Elsevier, 2020
2020
-
[8]
Ghassemi, M., Oakden-Rayner, L., and Beam, A. L. The false hope of current approaches to explainable artificial intelligence in health care. The Lancet Digital Health, 3 0 (11): 0 e745--e750, 2021
2021
-
[9]
Domain-specific language model pretraining for biomedical natural language processing
Gu, Y., Tinn, R., Cheng, H., Lucas, M., Usuyama, N., Liu, X., Naumann, T., Gao, J., and Poon, H. Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare (HEALTH), 3 0 (1): 0 1--23, 2021
2021
-
[10]
C., Wu, D., Narayanaswamy, A., Venugopalan, S., Widner, K., Madams, T., Cuadros, J., et al
Gulshan, V., Peng, L., Coram, M., Stumpe, M. C., Wu, D., Narayanaswamy, A., Venugopalan, S., Widner, K., Madams, T., Cuadros, J., et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA, 316 0 (22): 0 2402--2410, 2016
2016
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Y., Rajpurkar, P., Haghpanahi, M., Tison, G
Hannun, A. Y., Rajpurkar, P., Haghpanahi, M., Tison, G. H., Bourn, C., Turakhia, M. P., and Ng, A. Y. Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network. Nature Medicine, 25 0 (1): 0 65--69, 2019
2019
-
[13]
Multimodal integration in health care: development with applications in disease management
Hao, Y., Cheng, C., Li, J., Li, H., Di, X., Zeng, X., Jin, S., Han, X., Liu, C., Wang, Q., et al. Multimodal integration in health care: development with applications in disease management. Journal of medical Internet research, 27: 0 e76557, 2025
2025
-
[14]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 770--778, 2016
2016
-
[15]
Metagpt: Meta programming for a multi-agent collaborative framework
Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y., Wang, J., Zhang, C., Yau, S., Lin, Z., et al. Metagpt: Meta programming for a multi-agent collaborative framework. In International Conference on Learning Representations, volume 2024, pp.\ 23247--23275, 2024
2024
-
[16]
Transparent artificial intelligence-enabled interpretable and interactive sleep apnea assessment across flexible monitoring scenarios
Hu, S., Liu, J., Wang, Y., Fu, C., Zhu, J., Yu, H., and Yang, C. Transparent artificial intelligence-enabled interpretable and interactive sleep apnea assessment across flexible monitoring scenarios. Nature Communications, 16 0 (1): 0 7548, 2025
2025
-
[17]
H., and Quinn, G
Inkpen, K., Chappidi, S., Mallari, K., Nushi, B., Ramesh, D., Michelucci, P., Mandava, V., Vep r ek, L. H., and Quinn, G. Advancing human-ai complementarity: The impact of user expertise and algorithmic tuning on joint decision making. ACM Transactions on Computer-Human Interaction, 30 0 (5): 0 1--29, 2023
2023
-
[18]
S., Kazerooni, E
Jabbour, S., Fouhey, D., Shepard, S., Valley, T. S., Kazerooni, E. A., Banovic, N., Wiens, J., and Sjoding, M. W. Measuring the impact of ai in the diagnosis of hospitalized patients: a randomized clinical vignette survey study. JAMA, 330 0 (23): 0 2275--2284, 2023
2023
-
[19]
F., McCoy Jr, T
Jacobs, M., Pradier, M. F., McCoy Jr, T. H., Perlis, R. H., Doshi-Velez, F., and Gajos, K. Z. How machine-learning recommendations influence clinician treatment selections: the example of antidepressant selection. Translational Psychiatry, 11 0 (1): 0 108, 2021
2021
-
[20]
Jiang, A. Q., Sablayrolles, A., Mensch, A., et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Biomistral: A collection of open-source pretrained large language models for medical domains
Labrak, Y., Bazoge, A., Morin, E., Gourraud, P.-A., Rouvier, M., and Dufour, R. Biomistral: A collection of open-source pretrained large language models for medical domains. arXiv preprint arXiv:2402.10373, 2024
-
[22]
W., Brown, K
Lamb, B. W., Brown, K. F., Nagpal, K., Vincent, C., Green, J. S., and Sevdalis, N. Quality of care management decisions by multidisciplinary cancer teams: a systematic review. Annals of surgical oncology, 18 0 (8): 0 2116--2125, 2011
2011
-
[23]
H., and Kang, J
Lee, J., Yoon, W., Kim, S., Kim, D., Kim, S., So, C. H., and Kang, J. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36 0 (4): 0 1234--1240, 2020
2020
-
[24]
Benefits, limits, and risks of gpt-4 as an ai chatbot for medicine
Lee, P., Bubeck, S., and Petro, J. Benefits, limits, and risks of gpt-4 as an ai chatbot for medicine. New England Journal of Medicine, 388 0 (13): 0 1233--1239, 2023
2023
-
[25]
E., Motzfeldt, A
Li \'e vin, V., Hother, C. E., Motzfeldt, A. G., and Winther, O. Can large language models reason about medical questions? Patterns, 5 0 (3), 2024
2024
-
[26]
Decision making strategies and team efficacy in human-ai teams
Munyaka, I., Ashktorab, Z., Dugan, C., Johnson, J., and Pan, Q. Decision making strategies and team efficacy in human-ai teams. Proceedings of the ACM on Human-Computer Interaction, 7 0 (CSCW1): 0 1--24, 2023
2023
-
[27]
Capabilities of GPT-4 on Medical Challenge Problems
Nori, H., King, N., McKinney, S. M., Carignan, D., and Horvitz, E. Capabilities of gpt-4 on medical challenge problems. arXiv preprint arXiv:2303.13375, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Rajpurkar, P., Chen, E., Banerjee, O., and Topol, E. J. Ai in health and medicine. Nature Medicine, 28 0 (1): 0 31--38, 2022
2022
-
[29]
Evaluation framework to guide implementation of ai systems into healthcare settings
Reddy, S., Rogers, W., Makinen, V.-P., Coiera, E., Brown, P., Wenzel, M., Weicken, E., Ansari, S., Mathur, P., Casey, A., et al. Evaluation framework to guide implementation of ai systems into healthcare settings. BMJ Health & Care Informatics, 28 0 (1): 0 e100444, 2021
2021
-
[30]
Capabilities of Gemini Models in Medicine
Saab, K., Tu, T., Weng, W.-H., Tanno, R., Stutz, D., Wulczyn, E., Zhang, F., Strother, T., Park, C., Vedadi, E., et al. Capabilities of gemini models in medicine. arXiv preprint arXiv:2404.18416, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Llama-3-meditron: An open-weight suite of medical llms based on llama-3.1
Sallinen, A., Solergibert, A.-J., Zhang, M., Boy \'e , G., Dupont-Roc, M., Theimer-Lienhard, X., Boisson, E., Bernath, B., Hadhri, H., Tran, A., et al. Llama-3-meditron: An open-weight suite of medical llms based on llama-3.1. In Workshop on Large Language Models and Generative AI for Health at AAAI 2025, 2025
2025
-
[32]
AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
Schmidgall, S., Ziaei, R., Harris, C., Reis, E., Jopling, J., and Moor, M. Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical environments. arXiv preprint arXiv:2405.07960, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
R., Vassef, S., Goyal, A., Kumar, N., and Saha, K
Shimgekar, S. R., Vassef, S., Goyal, A., Kumar, N., and Saha, K. Agentic ai framework for end-to-end medical data inference. arXiv preprint arXiv:2507.18115, 2025
-
[34]
Large language models encode clinical knowledge
Singhal, K., Azizi, S., Tu, T., et al. Large language models encode clinical knowledge. Nature, 620 0 (7972): 0 172--180, 2023
2023
-
[35]
Quo vadis, ai-empowered doctor? JMIR medical education, 11 0 (1): 0 e70079, 2025
Takahashi, G., von Liechti, L., and Tarshizi, E. Quo vadis, ai-empowered doctor? JMIR medical education, 11 0 (1): 0 e70079, 2025
2025
-
[36]
L., Tatekawa, H., Saito, K., Tsujimoto, Y., Miki, Y., and Ueda, D
Takita, H., Kabata, D., Walston, S. L., Tatekawa, H., Saito, K., Tsujimoto, Y., Miki, Y., and Ueda, D. A systematic review and meta-analysis of diagnostic performance comparison between generative ai and physicians. npj Digital Medicine, 8 0 (1): 0 175, 2025
2025
-
[37]
and Le, Q
Tan, M. and Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, pp.\ 6105--6114. PMLR, 2019
2019
-
[38]
Medagents: Large language models as collaborators for zero-shot medical reasoning
Tang, X., Zou, A., Zhang, Z., Li, Z., Zhao, Y., Zhang, X., Cohan, A., and Gerstein, M. Medagents: Large language models as collaborators for zero-shot medical reasoning. In Findings of the Association for Computational Linguistics: ACL 2024, pp.\ 599--621, 2024
2024
-
[39]
J., Ting, D
Thirunavukarasu, A. J., Ting, D. S. J., Elangovan, K., Gutierrez, L., Tan, T. F., and Ting, D. S. W. Large language models in medicine. Nature Medicine, 29 0 (8): 0 1930--1940, 2023
1930
-
[40]
D., and Goldenberg, A
Tonekaboni, S., Joshi, S., McCradden, M. D., and Goldenberg, A. What clinicians want: contextualizing explainable machine learning for clinical end use. In Machine Learning for Healthcare Conference, pp.\ 359--380. PMLR, 2019
2019
-
[41]
Deep medicine: how artificial intelligence can make healthcare human again
Topol, E. Deep medicine: how artificial intelligence can make healthcare human again. Hachette UK, 2019
2019
-
[42]
G., Schalekamp, S., Rutten, M
van Leeuwen, K. G., Schalekamp, S., Rutten, M. J., van Ginneken, B., and de Rooij, M. Artificial intelligence in radiology: 100 commercially available products and their scientific evidence. European Radiology, 31 0 (6): 0 3797--3804, 2021
2021
-
[43]
and Von dem Bussche, A
Voigt, P. and Von dem Bussche, A. The eu general data protection regulation (gdpr). A practical guide, 1st ed., Cham: Springer International Publishing, 10 0 (3152676): 0 10--5555, 2017
2017
-
[44]
V., Zhou, D., et al
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V., Zhou, D., et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35: 0 24824--24837, 2022
2022
-
[45]
Pmc-llama: toward building open-source language models for medicine
Wu, C., Lin, W., Zhang, X., Zhang, Y., Xie, W., and Wang, Y. Pmc-llama: toward building open-source language models for medicine. Journal of the American Medical Informatics Association, 31 0 (9): 0 1833--1843, 2024
2024
-
[46]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Wu, Q., Bansal, G., Zhang, J., Wu, Y., Zhang, S., Zhu, E., Li, B., Jiang, L., Zhang, X., and Wang, C. Autogen: Enabling next-gen llm applications via multi-agent conversation framework. arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Doctorglm: Fine-tuning your chinese doctor is not a herculean task
Xiong, H., Wang, S., Zhu, Y., Zhao, Z., Liu, Y., Huang, L., Wang, Q., and Shen, D. Doctorglm: Fine-tuning your chinese doctor is not a herculean task. arXiv preprint arXiv:2304.01097, 2023
-
[48]
C., Smith, K
Yang, X., Chen, A., PourNejatian, N., Shin, H. C., Smith, K. E., Parisien, C., Compas, C., Martin, C., Costa, A. B., Flores, M. G., et al. A large language model for electronic health records. NPJ Digital Medicine, 5 0 (1): 0 194, 2022
2022
-
[49]
Tree of thoughts: Deliberate problem solving with large language models
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T., Cao, Y., and Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems, 36: 0 11809--11822, 2023
2023
-
[50]
Zhang, S., Xu, Y., Usuyama, N., Bagga, J., Tinn, R., Preston, S., Rao, R., Wei, M., Valluri, N., Wong, C., et al. Large-scale domain-specific pretraining for biomedical vision-language processing. arXiv preprint arXiv:2303.00915, 2 0 (3): 0 6, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.