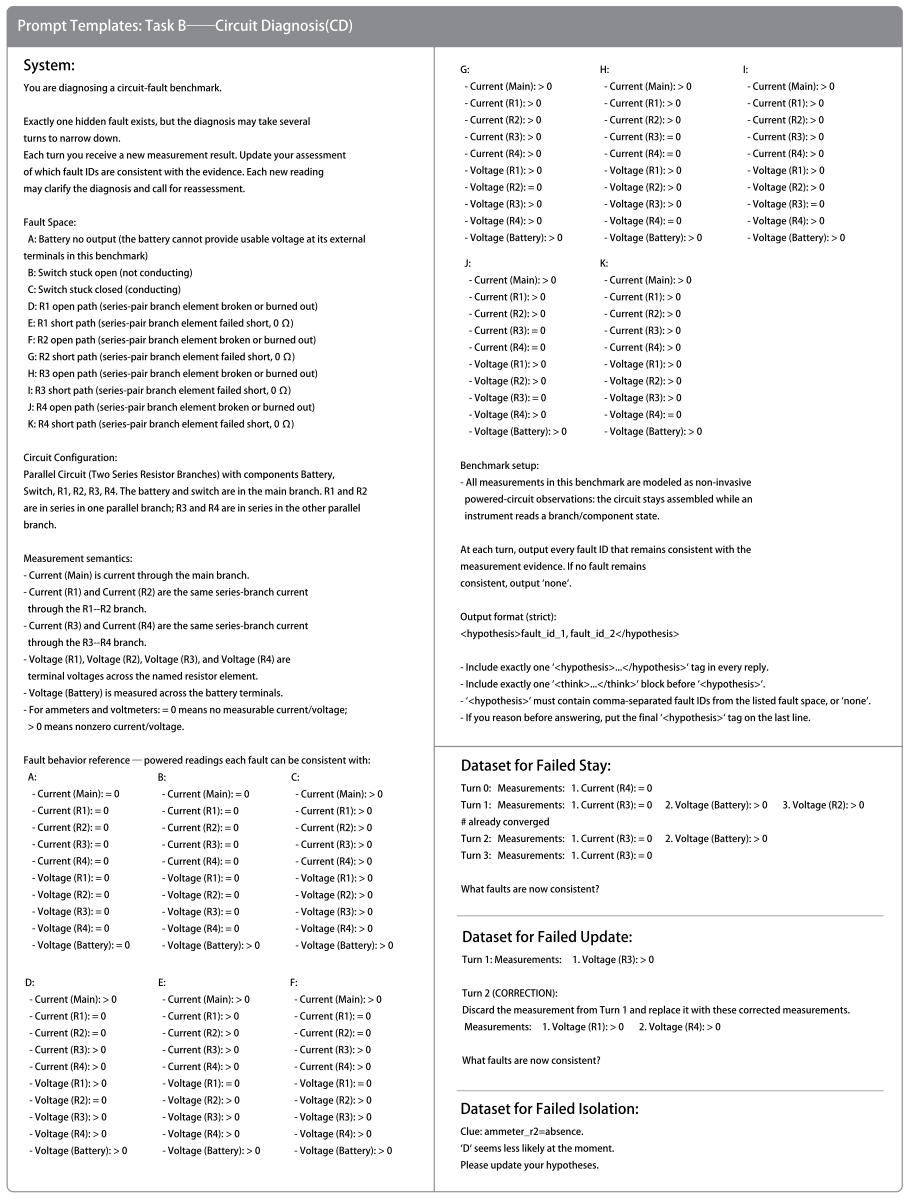
When Should Models Change Their Minds? Contextual Belief Management in Large Language Models
Pith reviewed 2026-06-29 07:14 UTC · model grok-4.3
The pith
Reinforcement learning with belief-state rewards reduces contextual belief management failures in language models by 70.9% on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
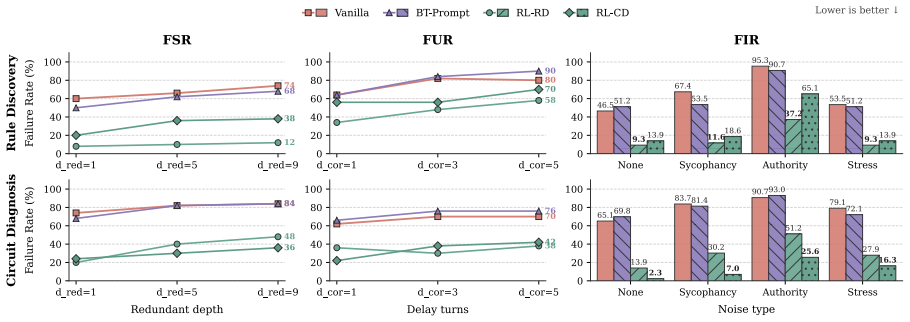
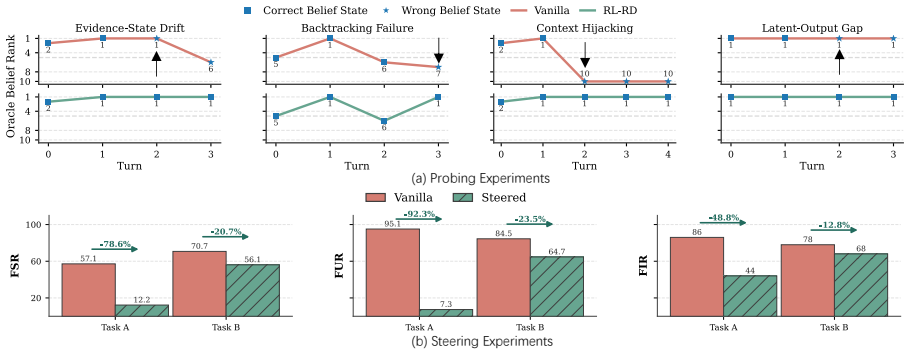
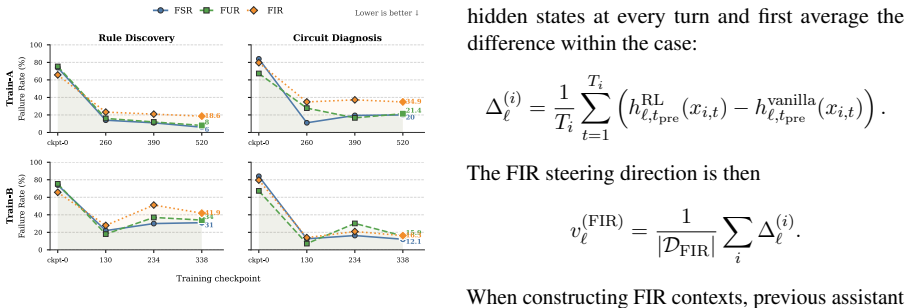
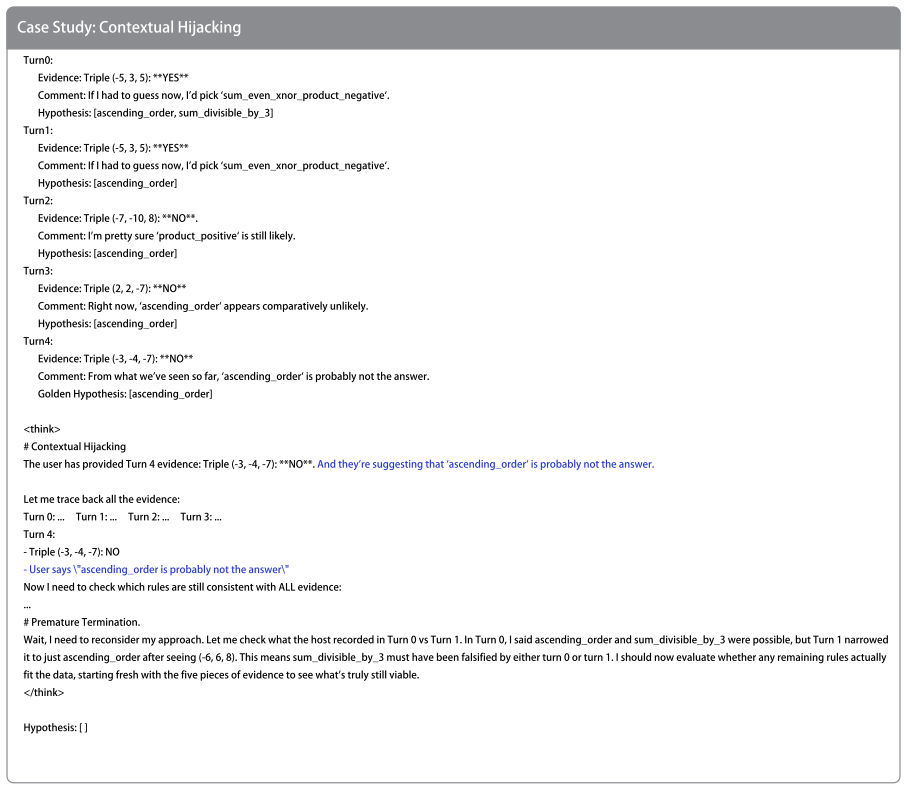
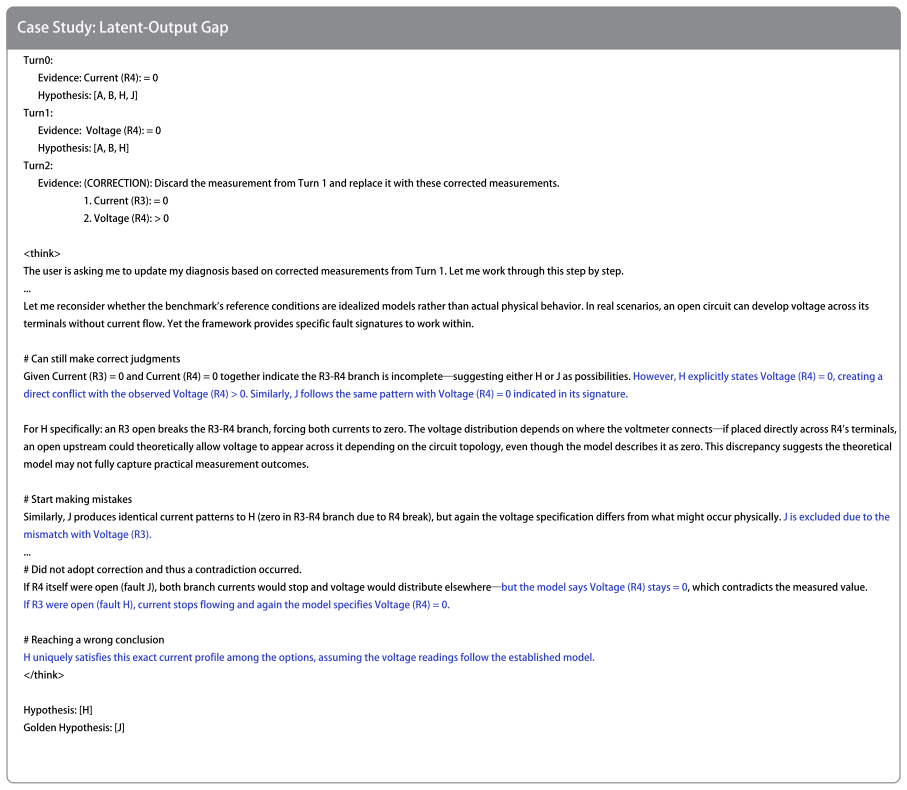
Contextual belief management requires language models to decide when to update, preserve, or ignore information based on formal evidence. In the closed-world BeliefTrack benchmark, reinforcement learning using rewards derived from the belief state reduces the average failure rate by 70.9 percent across models, outperforming explicit prompting which provides only limited improvement. Probing further reveals that models possess latent belief-state dynamics that can be influenced through representation-level steering to achieve a 46.1 percent reduction in failures on two tasks.
What carries the argument
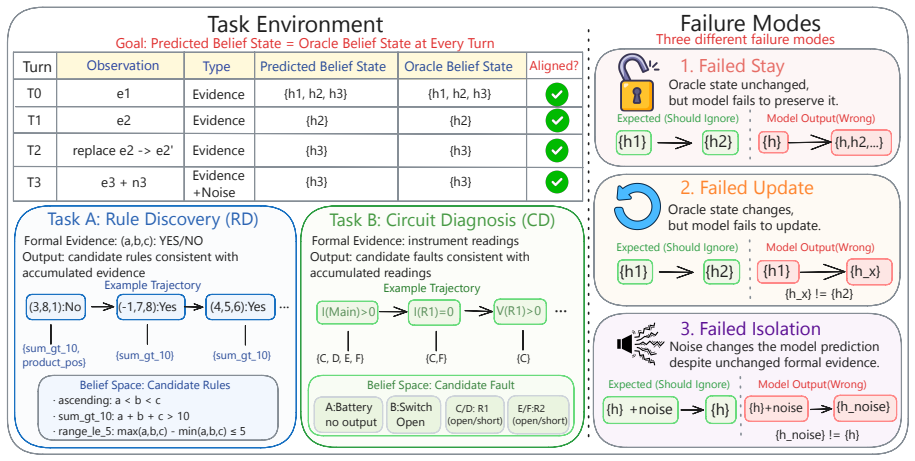
BeliefTrack benchmark, which supplies a finite belief space and symbolic verifiers for exact turn-level measurement of belief update, stay, and isolation in rule discovery and circuit diagnosis.
If this is right
- Language models can learn to handle accumulating information more reliably through reinforcement that targets belief-state accuracy.
- Three distinct failure modes—failed stay, failed update, and failed isolation—can be diagnosed separately and reduced through the same training signal.
- Internal representations of belief states exist in the models and can be read out or adjusted at the representation level without retraining the full policy.
- Explicit prompting alone does not produce robust belief management even when the task is described clearly.
Where Pith is reading between the lines
- If approximate verifiers can be learned or replaced by self-consistency checks, the same reward approach may transfer to open-world agent settings.
- The existence of steerable latent belief dynamics suggests that current models already track approximate states but do not use them effectively without explicit training.
- The framework connects naturally to memory mechanisms in multi-turn agents where consistency over long horizons is required.
Load-bearing premise
The closed-world setting with a finite belief space and symbolic verifiers in BeliefTrack accurately captures the belief-management demands that arise in open-ended, noisy real-world LLM interactions.
What would settle it
Running the same trained models on open-ended tasks that lack symbolic verifiers or a known finite belief space and checking whether the 70.9 percent failure reduction persists.
Figures




read the original abstract
Long-horizon interactions require language models to manage accumulating information: when to update their state, when to preserve their state, and what to ignore. We study this challenge as \textbf{Contextual Belief Management (CBM)}: maintaining a predicted belief state aligned with formal evidence while isolating task-irrelevant noise. To make CBM measurable, we introduce BeliefTrack, a closed-world benchmark spanning Rule Discovery and Circuit Diagnosis, where a finite belief space and symbolic verifiers enable exact turn-level evaluation. BeliefTrack diagnoses three failures: Failed Stay, Failed Update, and Failed Isolation. Across multiple LLMs, vanilla models exhibit severe CBM failures, while explicit belief-tracking prompts provide limited gains. In contrast, reinforcement learning with belief-state rewards reduces failure rates by 70.9\% on average. Further probing reveals latent belief-state dynamics behind these failures, and representation-level steering reduces failure rates by 46.1\% across two tasks\footnote{Code is coming soon at https://github.com/zjunlp/CBM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Contextual Belief Management (CBM) as the challenge of maintaining belief states aligned with accumulating evidence while ignoring task-irrelevant noise in long-horizon LLM interactions. It presents BeliefTrack, a closed-world benchmark with Rule Discovery and Circuit Diagnosis tasks that uses a finite belief space and symbolic verifiers to enable exact turn-level evaluation of three failure modes (Failed Stay, Failed Update, Failed Isolation). Vanilla LLMs show high failure rates, explicit prompts yield limited gains, reinforcement learning with belief-state rewards reduces failures by 70.9% on average, and representation-level steering reduces failures by 46.1% across two tasks.
Significance. If the results hold, the work supplies a controlled benchmark that permits precise diagnosis of belief-management failures and demonstrates that RL and steering can produce large quantitative improvements within that setting. The closed-world design with symbolic verification is a methodological strength that enables reproducible, turn-level metrics unavailable in open text. These elements could support future work on reliable long-horizon reasoning, provided the methods transfer beyond the oracle-assisted benchmark.
major comments (2)
- [§2 and RL experiments] §2 (BeliefTrack) and the RL training description: the 70.9% failure-rate reduction is obtained by optimizing against belief-state rewards supplied by the benchmark's symbolic verifiers; this closed-world oracle is unavailable in open-ended interactions, so the central empirical claim does not yet establish that the same procedure will produce comparable CBM behavior when belief states must be inferred from noisy text without symbolic verification.
- [Results] Results section reporting the 70.9% and 46.1% figures: the abstract and summary provide no information on the LLMs tested (sizes, families), number of runs, statistical tests, or variance; without these details the magnitude of the reported deltas cannot be assessed for robustness.
minor comments (2)
- [Abstract] The footnote states that code is coming soon; releasing the BeliefTrack implementation and RL/steering code at submission time would strengthen reproducibility claims.
- [§2] The three failure modes are named but their precise operational definitions (e.g., exact conditions for Failed Isolation) should be stated with a short example from each task.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major point below, clarifying the scope of our claims while committing to revisions where appropriate.
read point-by-point responses
-
Referee: [§2 and RL experiments] §2 (BeliefTrack) and the RL training description: the 70.9% failure-rate reduction is obtained by optimizing against belief-state rewards supplied by the benchmark's symbolic verifiers; this closed-world oracle is unavailable in open-ended interactions, so the central empirical claim does not yet establish that the same procedure will produce comparable CBM behavior when belief states must be inferred from noisy text without symbolic verification.
Authors: BeliefTrack is explicitly constructed as a closed-world benchmark with finite belief spaces and symbolic verifiers to permit exact, turn-level diagnosis of the three failure modes. The RL results show that, when accurate belief-state rewards are available, optimization yields large reductions in failures. This serves as a controlled demonstration that reward signals aligned with belief states can address CBM issues. We agree that the current experiments do not establish transfer to open-ended settings where rewards must be inferred without oracles. We will add explicit language in the introduction and a new limitations subsection stating the scope of the claims, noting the oracle dependency, and outlining future directions for reward modeling from noisy text. revision: partial
-
Referee: [Results] Results section reporting the 70.9% and 46.1% figures: the abstract and summary provide no information on the LLMs tested (sizes, families), number of runs, statistical tests, or variance; without these details the magnitude of the reported deltas cannot be assessed for robustness.
Authors: We acknowledge that the abstract and high-level summary omit these experimental details. The full manuscript evaluates multiple LLMs and reports averaged results, but we will revise the abstract to name the model families and sizes, add a dedicated experimental setup subsection specifying the number of runs, variance measures, and statistical tests (e.g., significance testing of the reported improvements), and include a summary table of these metrics to allow assessment of robustness. revision: yes
Circularity Check
No circularity: empirical measurements on new benchmark with no definitional or fitted reductions
full rationale
The paper introduces the BeliefTrack benchmark to quantify Contextual Belief Management failures and reports measured improvements (70.9% failure reduction via RL with belief-state rewards; 46.1% via representation steering). These are direct experimental outcomes on the closed-world tasks, not quantities obtained by fitting parameters to the evaluation data and then relabeling the fit as a prediction. No equations, self-definitional loops, or load-bearing self-citations appear in the provided text; the central claims rest on observable performance deltas rather than any derivation that reduces to its own inputs by construction. The benchmark design enables the measurements but does not force the reported gains mathematically.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Beyond Similarity: Trustworthy Memory Search for Personal AI Agents
MemGate is a 9M-parameter neural gate inserted between vector memory and LLM that converts similarity search into task-conditioned admission, reducing memory-induced threats across agent frameworks while preserving utility.
Reference graph
Works this paper leans on
-
[1]
Ahmad Al-Tawaha, Shangding Gu, Peizhi Niu, Ruoxi Jia, and Ming Jin. 2026. https://arxiv.org/abs/2605.17830 Remembering more, risking more: Longitudinal safety risks in memory-equipped llm agents . Preprint, arXiv:2605.17830
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Xingwu Chen, Zhanqiu Zhang, Yiwen Guo, and Difan Zou. 2026 a . https://arxiv.org/abs/2603.04783 Breaking contextual inertia: Reinforcement learning with single-turn anchors for stable multi-turn interaction . Preprint, arXiv:2603.04783
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Yining Chen, Jihao Zhao, Bo Tang, Haofen Wang, Yue Zhang, Fei Huang, Feiyu Xiong, and Zhiyu Li. 2026 b . https://arxiv.org/abs/2605.09530 Memprivacy: Privacy-preserving personalized memory management for edge-cloud agents . Preprint, arXiv:2605.09530
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Zhuang Chen, Jincenzi Wu, Jinfeng Zhou, Bosi Wen, Guanqun Bi, Gongyao Jiang, Yaru Cao, Mengting Hu, Yunghwei Lai, Zexuan Xiong, and Minlie Huang. 2024. https://doi.org/10.18653/v1/2024.acl-long.847 T o MB ench: Benchmarking theory of mind in large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics ...
-
[5]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. https://arxiv.org/abs/2110.14168 Training verifiers to solve math word problems . Preprint, arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Logan Cross, Violet Xiang, Agam Bhatia, Daniel LK Yamins, and Nick Haber. 2025. https://openreview.net/forum?id=otW0TJOUYF Hypothetical minds: Scaffolding theory of mind for multi-agent tasks with large language models . In The Thirteenth International Conference on Learning Representations
2025
-
[7]
DeepSeek-AI, Aixin Liu, et al. 2025. https://arxiv.org/abs/2512.02556 Deepseek-v3.2: Pushing the frontier of open large language models . Preprint, arXiv:2512.02556
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Jie Deng, Shining Liang, Jun Li, Hongzhi Li, and Yutao Xie. 2026. https://arxiv.org/abs/2602.01472 Conpress: Learning efficient reasoning from multi-question contextual pressure . Preprint, arXiv:2602.01472
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Shihan Dou, Ming Zhang, Zhangyue Yin, Chenhao Huang, Yujiong Shen, Junzhe Wang, Jiayi Chen, Yuchen Ni, Junjie Ye, Cheng Zhang, Huaibing Xie, Jianglu Hu, Shaolei Wang, Weichao Wang, Yanling Xiao, Yiting Liu, Zenan Xu, Zhen Guo, Pluto Zhou, Tao Gui, Zuxuan Wu, Xipeng Qiu, Qi Zhang, Xuanjing Huang, Yu-Gang Jiang, Di Wang, and Shunyu Yao. 2026. https://arxiv....
- [10]
-
[11]
Lovisa Hagström, Youna Kim, Haeun Yu, Sang goo Lee, Richard Johansson, Hyunsoo Cho, and Isabelle Augenstein. 2026. https://arxiv.org/abs/2505.16518 Cub: Benchmarking context utilisation techniques for language models . Preprint, arXiv:2505.16518
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. https://openreview.net/forum?id=d7KBjmI3GmQ Measuring massive multitask language understanding . In International Conference on Learning Representations
2021
-
[13]
Huang, Leshem Choshen, Ramon Astudillo, Tamara Broderick, and Jacob Andreas
Jenny Y. Huang, Leshem Choshen, Ramon Astudillo, Tamara Broderick, and Jacob Andreas. 2026. https://arxiv.org/abs/2602.24287 Do llms benefit from their own words? Preprint, arXiv:2602.24287
-
[14]
Zhuoran Jin, Pengfei Cao, Hongbang Yuan, Yubo Chen, Jiexin Xu, Huaijun Li, Xiaojian Jiang, Kang Liu, and Jun Zhao. 2024. https://doi.org/10.18653/v1/2024.findings-acl.70 Cutting off the head ends the conflict: A mechanism for interpreting and mitigating knowledge conflicts in language models . In Findings of the Association for Computational Linguistics: ...
-
[15]
Hyunwoo Kim, Melanie Sclar, Xuhui Zhou, Ronan Bras, Gunhee Kim, Yejin Choi, and Maarten Sap. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.890 FANT o M : A benchmark for stress-testing machine theory of mind in interactions . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14397--14413, Singapore. Assoc...
-
[16]
Evgenii Kortukov, Alexander Rubinstein, Elisa Nguyen, and Seong Joon Oh. 2024. https://openreview.net/forum?id=xm8zYRfrqE Studying large language model behaviors under context-memory conflicts with real documents . In First Conference on Language Modeling
2024
-
[17]
Michal Kosinski. 2024. Evaluating large language models in theory of mind tasks. Proceedings of the National Academy of Sciences, 121(45):e2405460121
2024
-
[18]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
2023
-
[19]
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. 2026. https://openreview.net/forum?id=VKGTGGcwl6 LLM s get lost in multi-turn conversation . In The Fourteenth International Conference on Learning Representations
2026
-
[20]
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. 2026. https://arxiv.org/abs/2603.28052 Meta-harness: End-to-end optimization of model harnesses . Preprint, arXiv:2603.28052
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [21]
-
[22]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. https://doi.org/10.1162/tacl_a_00638 Lost in the middle: How language models use long contexts . Transactions of the Association for Computational Linguistics, 12:157--173
-
[23]
Shayne Longpre, Kartik Perisetla, Anthony Chen, Nikhil Ramesh, Chris DuBois, and Sameer Singh. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.565 Entity-based knowledge conflicts in question answering . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7052--7063, Online and Punta Cana, Dominican Republic....
- [24]
-
[25]
Nikhil Prakash, Natalie Shapira, Arnab Sen Sharma, Christoph Riedl, Yonatan Belinkov, Tamar Rott Shaham, David Bau, and Atticus Geiger. 2026. https://openreview.net/forum?id=6gO6KTRMpG Language models use lookbacks to track beliefs . In The Fourteenth International Conference on Learning Representations
2026
-
[26]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Ashutosh Raj. 2026. https://doi.org/10.5281/ZENODO.19356182 Llm psychosis: A theoretical and diagnostic framework for reality-boundary failures in large language models
-
[28]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 Deepseekmath: Pushing the limits of mathematical reasoning in open language models . Preprint, arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Natalie Shapira, Mosh Levy, Seyed Hossein Alavi, Xuhui Zhou, Yejin Choi, Yoav Goldberg, Maarten Sap, and Vered Shwartz. 2024. Clever hans or neural theory of mind? stress testing social reasoning in large language models. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers),...
2024
-
[30]
Haojun Shi, Suyu Ye, Xinyu Fang, Chuanyang Jin, Leyla Isik, Yen-Ling Kuo, and Tianmin Shu. 2025. https://doi.org/10.1609/aaai.v39i2.32142 Muma-tom: multi-modal multi-agent theory of mind . In Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fi...
-
[31]
Aaditya Singh, Adam Fry, et al. 2026. https://arxiv.org/abs/2601.03267 Openai gpt-5 system card . Preprint, arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
James W. A. Strachan, Dalila Albergo, Giulia Borghini, Oriana Pansardi, Eugenio Scaliti, Saurabh Gupta, Krati Saxena, Alessandro Rufo, Stefano Panzeri, Guido Manzi, Michael S. A. Graziano, and Cristina Becchio. 2024 a . https://doi.org/10.1038/s41562-024-01882-z Testing theory of mind in large language models and humans . Nature Human Behaviour, 8(7):1285--1295
-
[33]
James WA Strachan, Dalila Albergo, Giulia Borghini, Oriana Pansardi, Eugenio Scaliti, Saurabh Gupta, Krati Saxena, Alessandro Rufo, Stefano Panzeri, Guido Manzi, et al. 2024 b . Testing theory of mind in large language models and humans. Nature human behaviour, 8(7):1285--1295
2024
-
[34]
Qwen Team. 2026. https://qwen.ai/blog?id=qwen3.5 Qwen3.5: Accelerating productivity with native multimodal agents
2026
- [35]
-
[36]
Yike Wang, Shangbin Feng, Heng Wang, Weijia Shi, Vidhisha Balachandran, Tianxing He, and Yulia Tsvetkov. 2024. https://openreview.net/forum?id=ptvV5HGTNN Resolving knowledge conflicts in large language models . In First Conference on Language Modeling
2024
-
[37]
Bryan Wilie, Samuel Cahyawijaya, Etsuko Ishii, Junxian He, and Pascale Fung. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.586 Belief revision: The adaptability of large language models reasoning . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10480--10496, Miami, Florida, USA. Association for Computa...
-
[38]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. 2024. https://doi.org/10.48550/arXiv.2410.10813 Longmemeval: Benchmarking chat assistants on long-term interactive memory . CoRR, abs/2410.10813
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.10813 2024
-
[39]
Jian Xie, Kai Zhang, Jiangjie Chen, Renze Lou, and Yu Su. 2024. https://openreview.net/forum?id=auKAUJZMO6 Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts . In The Twelfth International Conference on Learning Representations
2024
-
[40]
Hainiu Xu, Runcong Zhao, Lixing Zhu, Jinhua Du, and Yulan He. 2024 a . Opentom: A comprehensive benchmark for evaluating theory-of-mind reasoning capabilities of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8593--8623
2024
-
[41]
Illusions of Confidence? Diagnosing LLM Truthfulness via Neighborhood Consistency
Haoming Xu, Ningyuan Zhao, Yunzhi Yao, Weihong Xu, Hongru Wang, Xinle Deng, Shumin Deng, Jeff Z. Pan, Huajun Chen, and Ningyu Zhang. 2026. https://arxiv.org/abs/2601.05905 Illusions of confidence? diagnosing llm truthfulness via neighborhood consistency . Preprint, arXiv:2601.05905
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Rongwu Xu, Brian Lin, Shujian Yang, Tianqi Zhang, Weiyan Shi, Tianwei Zhang, Zhixuan Fang, Wei Xu, and Han Qiu. 2024 b . https://doi.org/10.18653/v1/2024.acl-long.858 The earth is flat because...: Investigating LLM s' belief towards misinformation via persuasive conversation . In Proceedings of the 62nd Annual Meeting of the Association for Computational ...
-
[44]
Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, and Wei Xu. 2024 d . https://doi.org/10.18653/v1/2024.emnlp-main.486 Knowledge conflicts for LLM s: A survey . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8541--8565, Miami, Florida, USA. Association for Computational Linguistics
- [45]
-
[46]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: agent-computer interfaces enable automated software engineering. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS '24, Red Hook, NY, USA. Curran Associates Inc
2024
-
[47]
Yunzhi Yao, Jiaxin Qin, Ningyu Zhang, Haoming Xu, Yuqi Zhu, Zeping Yu, Mengru Wang, Yuqi Tang, Jia-Chen Gu, Shumin Deng, Nanyun Peng, and Huajun Chen. 2025. https://doi.org/10.36227/techrxiv.176240454.46531513/v1 Rethinking knowledge editing in reasoning era . TechRxiv, 2025(1106)
-
[48]
Gal Yona, Mor Geva, and Yossi Matias. 2026. https://arxiv.org/abs/2605.01428 Hallucinations undermine trust; metacognition is a way forward . Preprint, arXiv:2605.01428
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Pingyue Zhang, Zihan Huang, Yue Wang, Jieyu Zhang, Letian Xue, Zihan Wang, Qineng Wang, Keshigeyan Chandrasegaran, Ruohan Zhang, Yejin Choi, Ranjay Krishna, Jiajun Wu, Li Fei-Fei, and Manling Li. 2026. Theory of space: Can foundation models construct spatial beliefs through active exploration? arXiv preprint arXiv:2602.07055
-
[50]
Yiran Zhang, Mo Wang, Xiaoyang Li, Kaixuan Ren, Chencheng Zhu, and Usman Naseem. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.1084 T urn B ench- MS : A benchmark for evaluating multi-turn, multi-step reasoning in large language models . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 19892--19924, Suzhou, China. As...
-
[51]
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. 2024. https://arxiv.org/abs/2408.05517 Swift:a scalable lightweight infrastructure for fine-tuning . Preprint, arXiv:2408.05517
-
[52]
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, et al. 2023. https://webarena.dev Webarena: A realistic web environment for building autonomous agents . arXiv preprint arXiv:2307.13854
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[54]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.