How LoRA Remembers? A Parametric Memory Law for LLM Finetuning
Pith reviewed 2026-06-29 07:21 UTC · model grok-4.3
The pith
LoRA fine-tuning follows a power law where loss reduction depends on effective parameters and sequence length, with verbatim recall guaranteed once token prediction exceeds 0.5 probability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
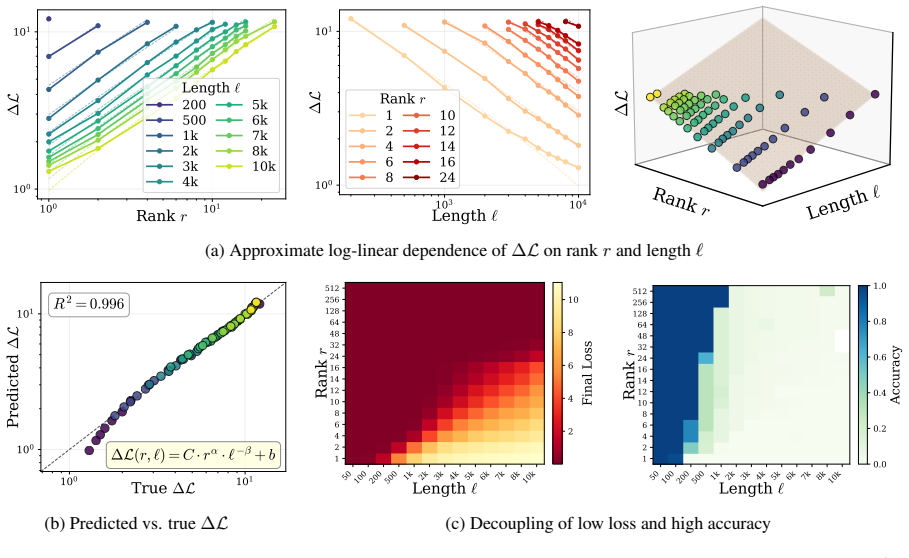
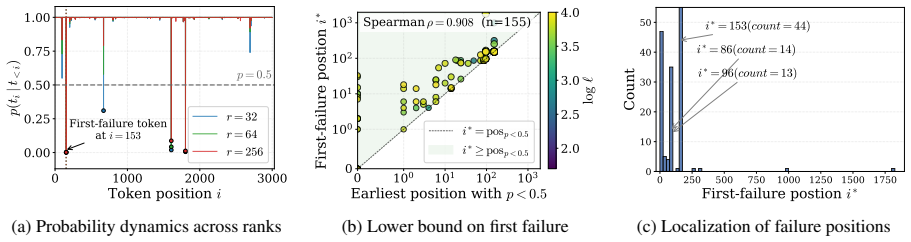
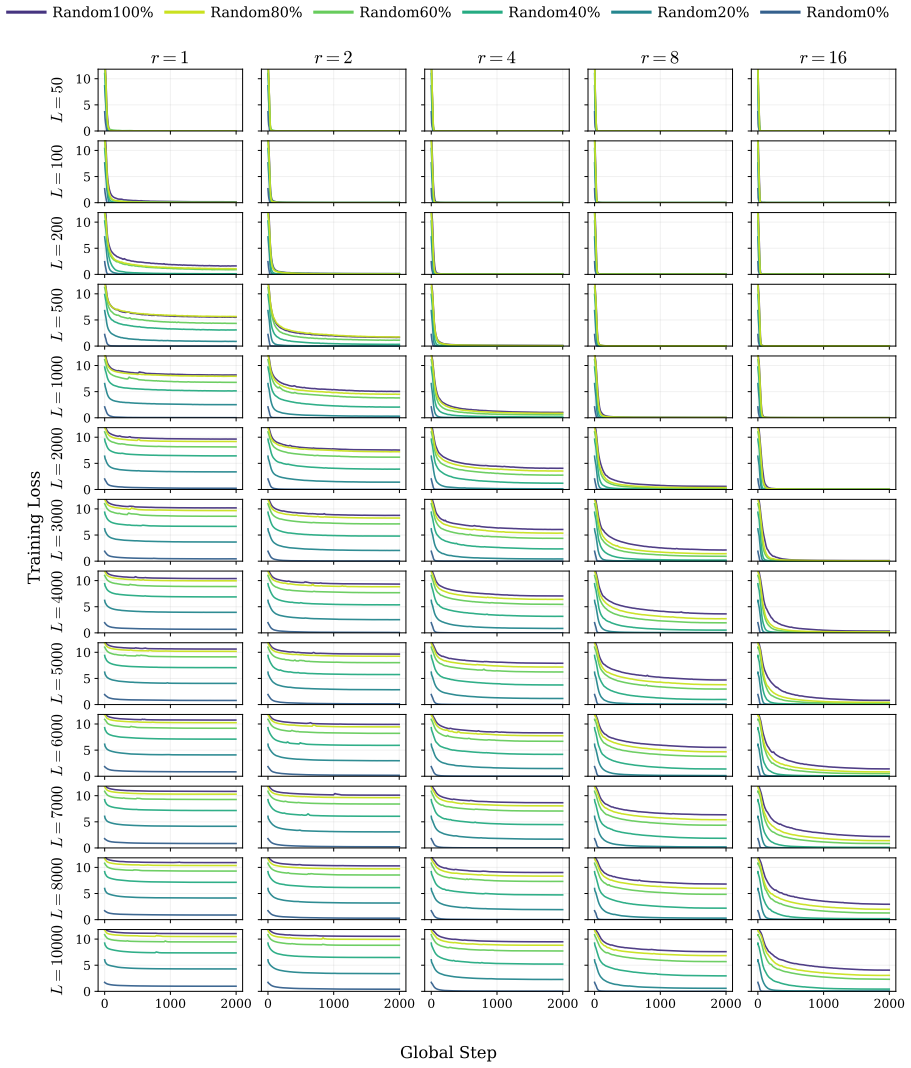
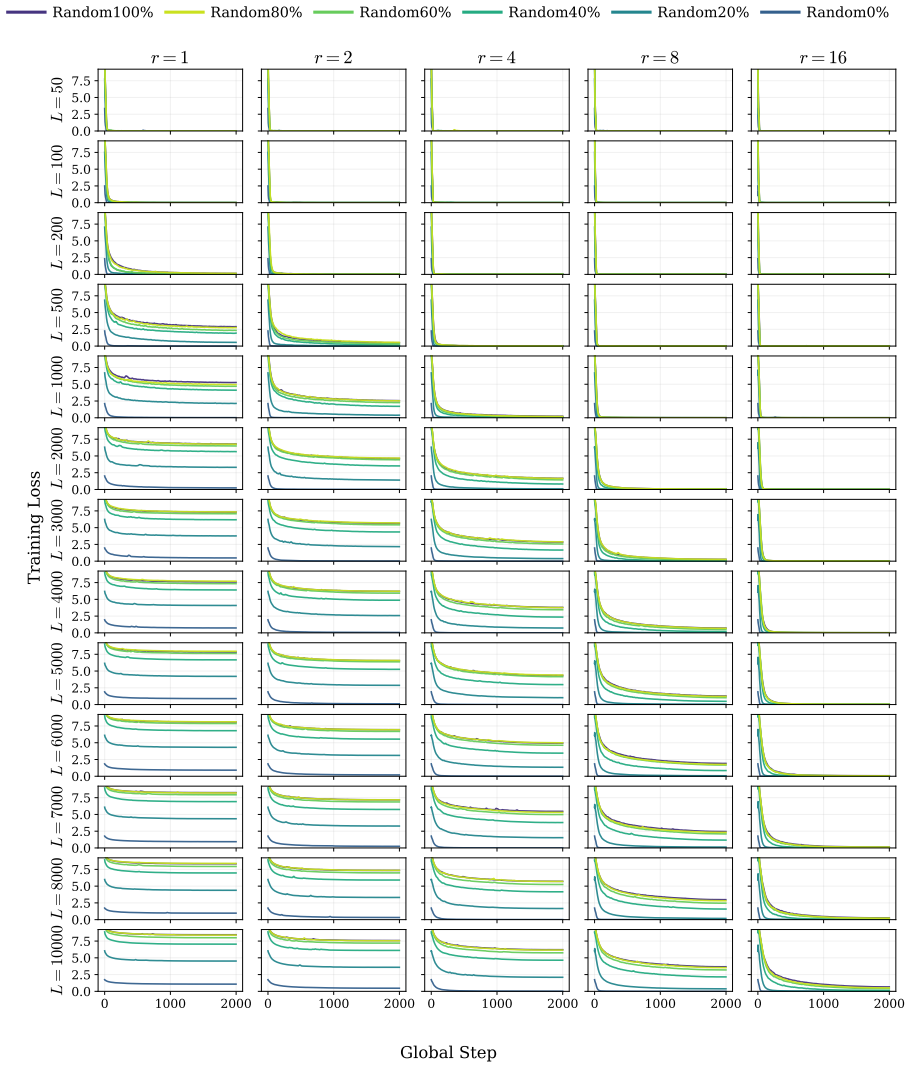
The authors demonstrate that the reduction in loss ΔL during LoRA fine-tuning follows a robust power law determined by the number of effective parameters and the sequence length. Fine-grained token analysis shows a deterministic phase transition at p > 0.5, which is sufficient for verbatim recall under greedy decoding. This insight enables a new optimization strategy called MemFT that redistributes training budget to sub-threshold tokens.
What carries the argument
The Parametric Memory Law, a power-law relationship between loss reduction ΔL, effective parameters, and sequence length.
Load-bearing premise
The observed power law and the p > 0.5 phase transition will continue to hold for models, datasets, and LoRA configurations outside the specific controlled experiments performed.
What would settle it
Repeat the latent-space probe experiments on a different model family or dataset and verify whether the fitted power-law exponent stays consistent and whether every token with probability above 0.5 is still recalled exactly under greedy decoding.
Figures

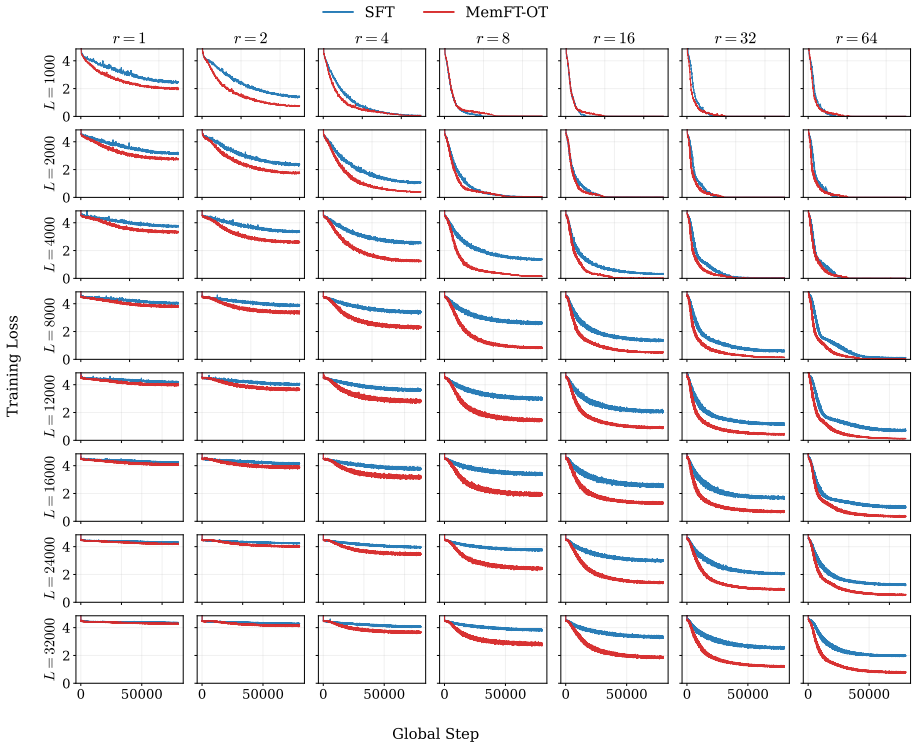
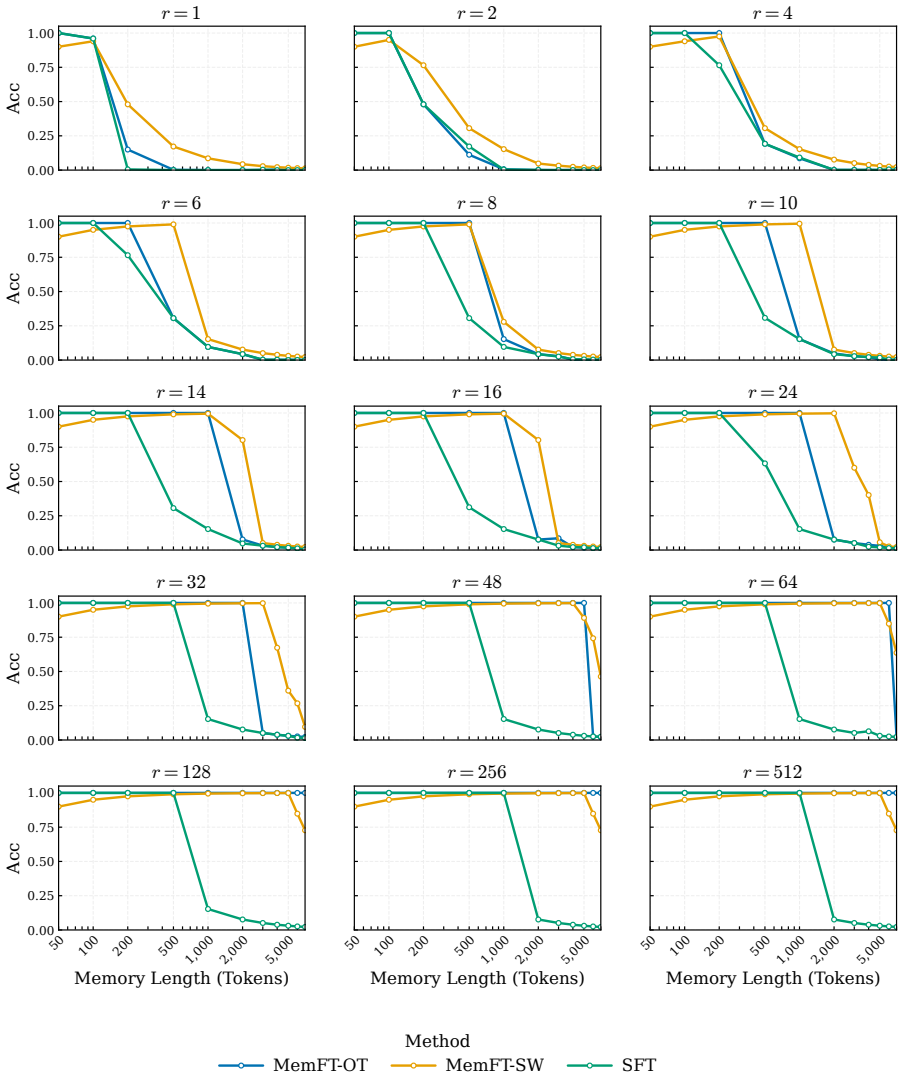
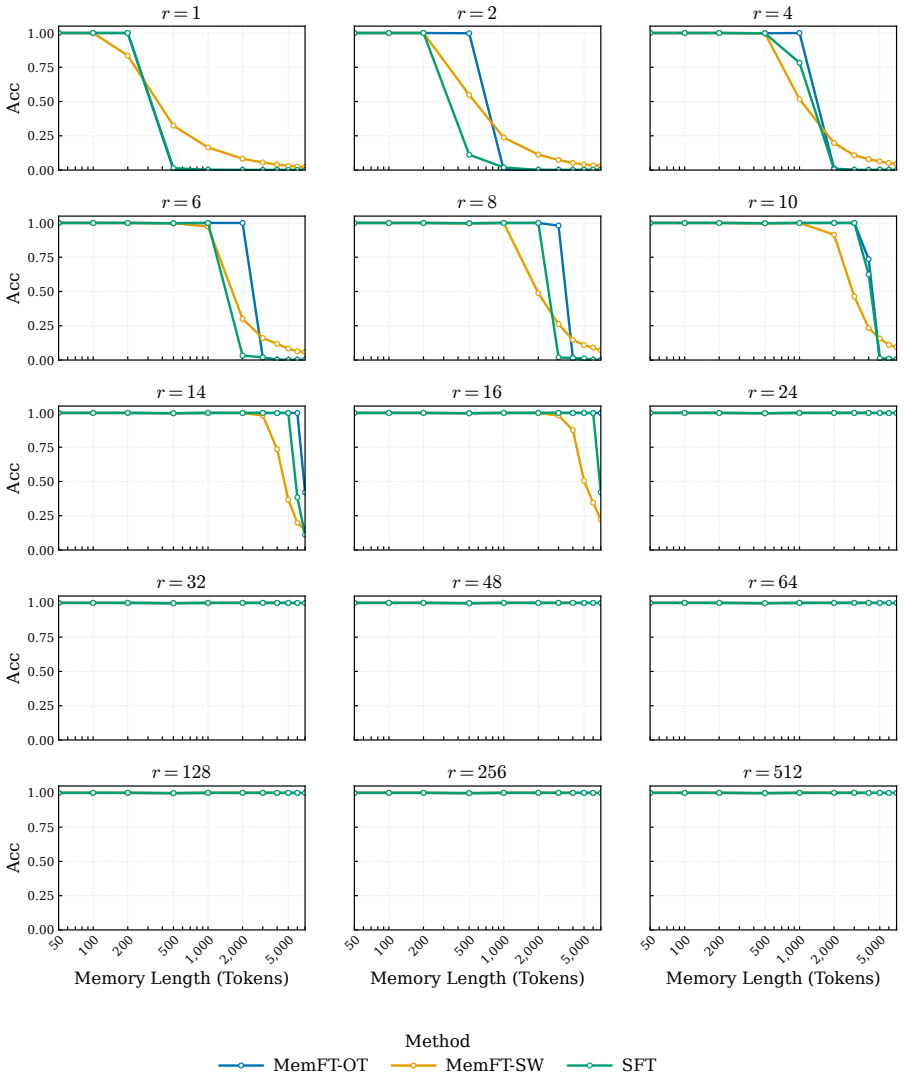
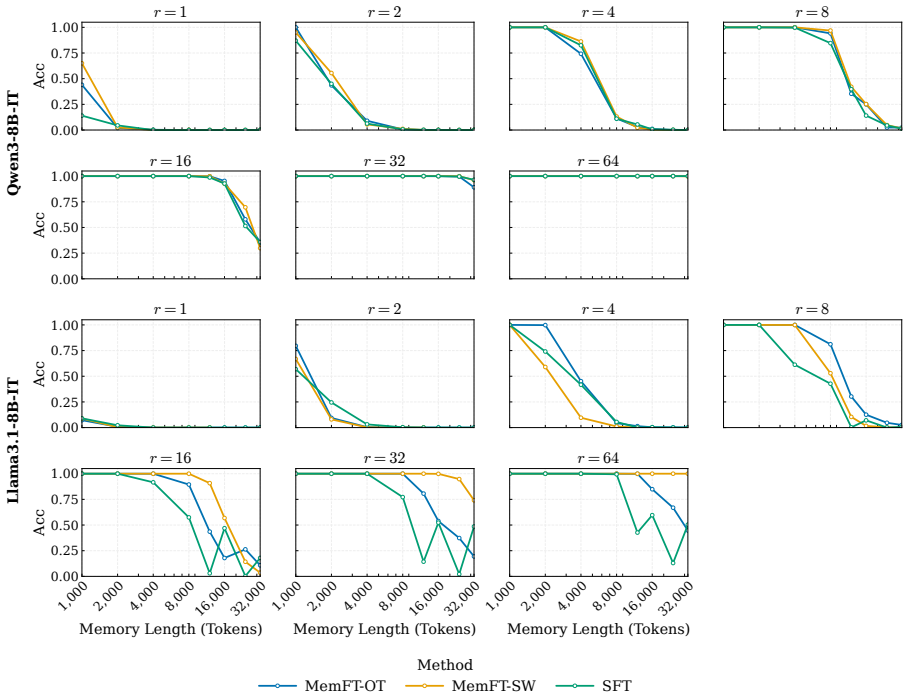
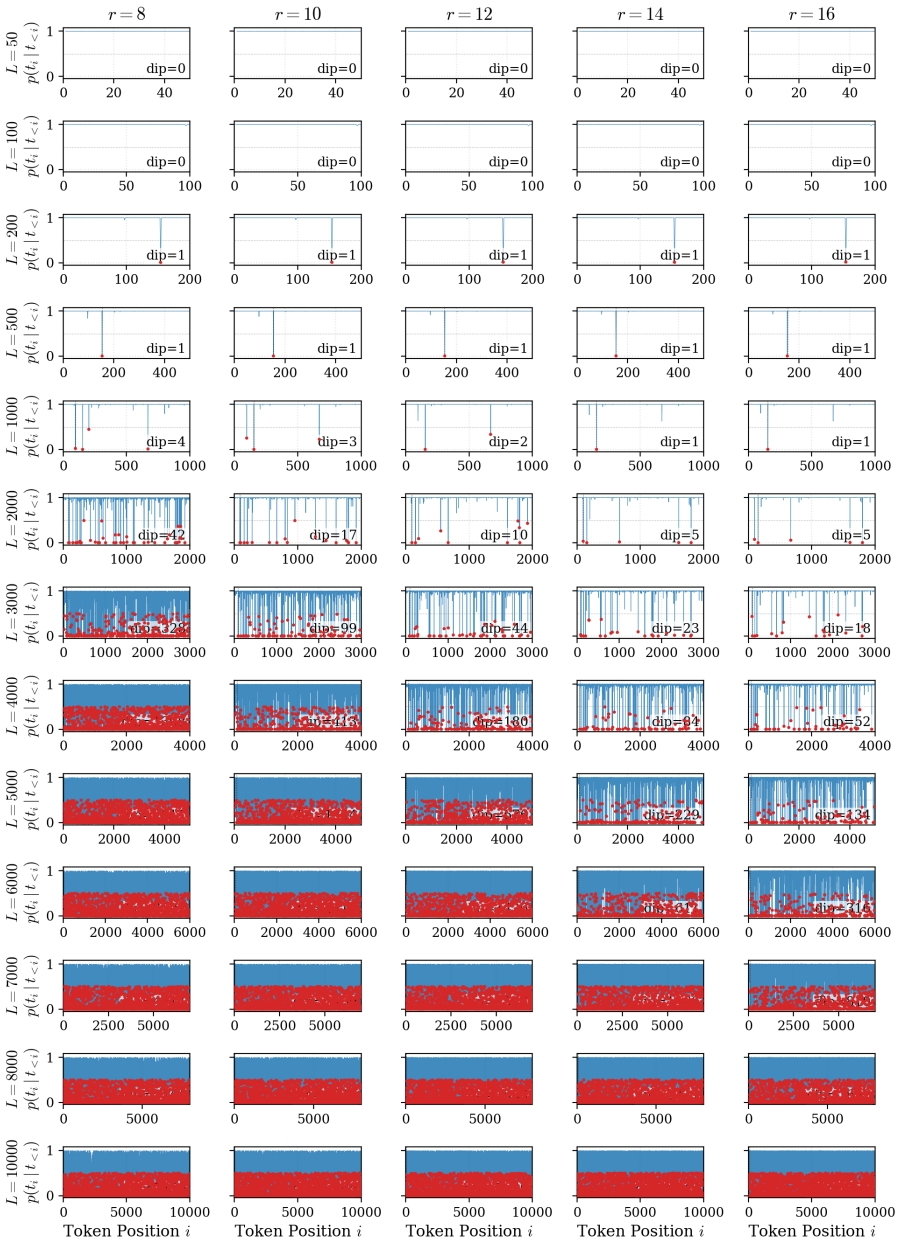

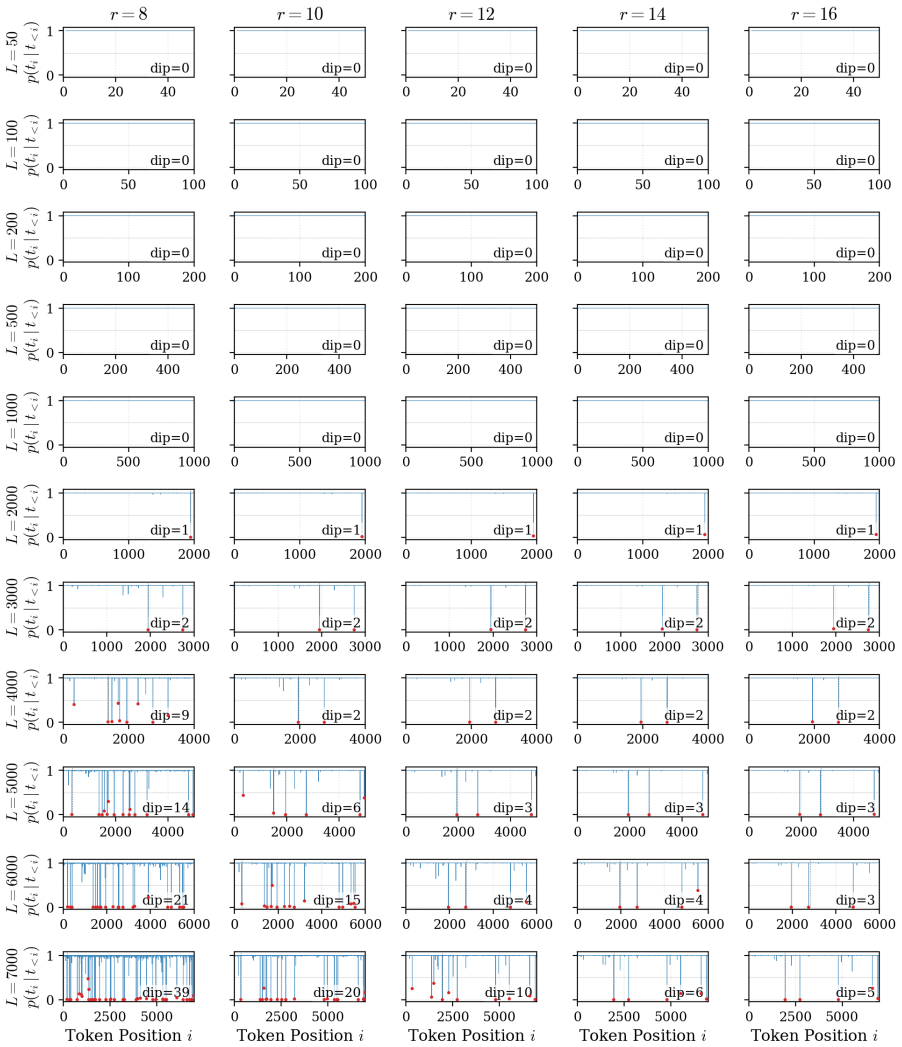
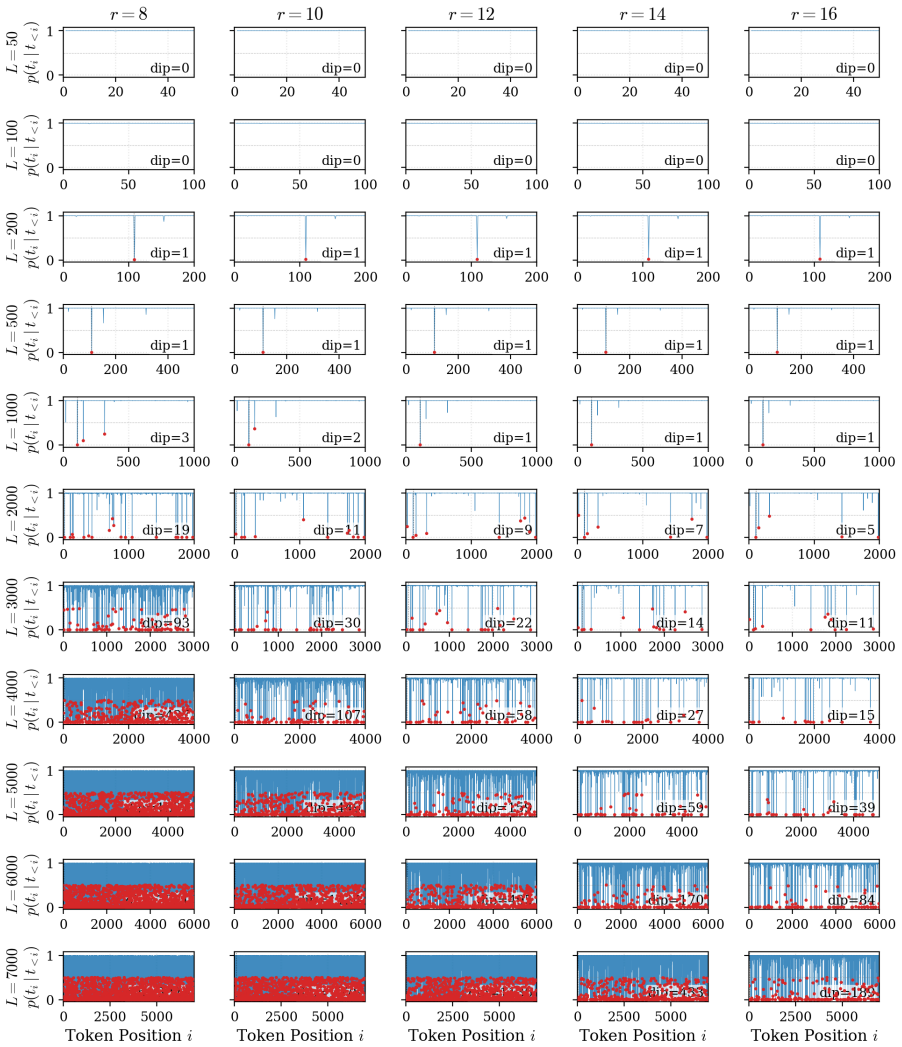
read the original abstract
Large Language Models (LLMs) must continuously learn and update knowledge to remain effective in dynamic real-world environments. While Low-Rank Adaptation (LoRA) is widely used for such memory updates, existing studies mainly rely on qualitative downstream evaluations, leaving the quantitative capacity limits and underlying dynamics of exact parametric memory largely unexplored. To bridge this gap, we employ LoRA as a controlled memory capacity probe within the latent space to systematically quantify exact parametric memory. We introduce the Parametric Memory Law, a robust power law linking loss reduction Delta L to effective parameters and sequence length. At the token level, fine-grained analysis reveals a deterministic phase transition, demonstrating that a prediction probability of p > 0.5 constitutes a sufficient condition for verbatim recall under greedy decoding. Driven by these insights, we introduce MemFT, a threshold-guided optimization strategy that dynamically redistributes the training budget toward sub-threshold tokens. Empirical evaluations demonstrate that MemFT can enhance memory fidelity and efficiency. Code will be released at https://github.com/zjunlp/ParametricMemoryLaw.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper employs LoRA as a latent-space probe to quantify exact parametric memory in LLMs. It introduces the Parametric Memory Law as a power law relating loss reduction ΔL to effective parameters and sequence length. At the token level, it identifies a deterministic phase transition where p > 0.5 suffices for verbatim recall under greedy decoding, and proposes the MemFT threshold-guided optimization to improve fidelity and efficiency.
Significance. If the power law generalizes and the phase transition provides non-trivial insight, the work could supply a quantitative basis for memory capacity in fine-tuning and motivate more efficient adaptation methods. The empirical nature of the law and the triviality of the p > 0.5 condition, however, limit its current significance absent broader validation.
major comments (3)
- [Abstract] Abstract: the sufficiency of p > 0.5 for verbatim recall under greedy decoding follows directly from the definition of argmax and adds no new information beyond the decoding rule itself; this undermines the claim of a 'deterministic phase transition' as a substantive finding.
- [Abstract] Abstract: the Parametric Memory Law is asserted as a 'robust power law' without derivation from loss-landscape or capacity arguments and without reported out-of-distribution or cross-model tests; the robustness claim therefore rests entirely on fits within the narrow LoRA probe regime described.
- [Abstract] Abstract: MemFT is motivated by the phase-transition insight, yet because that insight reduces to the standard greedy rule, the strategy's claimed improvements require independent verification that is not shown to hold outside the specific models, ranks, and datasets used in the controlled probes.
minor comments (1)
- [Abstract] The abstract states that code will be released but provides no details on how the power-law parameters or phase-transition thresholds were obtained, hindering immediate reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications and indicate proposed revisions to better align the abstract with the empirical scope of our findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: the sufficiency of p > 0.5 for verbatim recall under greedy decoding follows directly from the definition of argmax and adds no new information beyond the decoding rule itself; this undermines the claim of a 'deterministic phase transition' as a substantive finding.
Authors: We agree that p > 0.5 follows directly from the argmax operation in greedy decoding. The contribution in our work is the empirical demonstration, via fine-grained token-level analysis during LoRA-based memory insertion, that the per-token prediction probability crosses this threshold at the point of verbatim memorization. We will revise the abstract to frame this as an observed transition in the learning trajectory rather than a novel theoretical phase transition. revision: partial
-
Referee: [Abstract] Abstract: the Parametric Memory Law is asserted as a 'robust power law' without derivation from loss-landscape or capacity arguments and without reported out-of-distribution or cross-model tests; the robustness claim therefore rests entirely on fits within the narrow LoRA probe regime described.
Authors: The Parametric Memory Law is presented as an empirical power-law relationship observed consistently across controlled LoRA probing experiments varying effective parameters and sequence lengths. We do not claim a first-principles derivation. We will revise the abstract to qualify the robustness claim as holding within the reported experimental regime and add a limitations discussion noting the need for further validation. revision: partial
-
Referee: [Abstract] Abstract: MemFT is motivated by the phase-transition insight, yet because that insight reduces to the standard greedy rule, the strategy's claimed improvements require independent verification that is not shown to hold outside the specific models, ranks, and datasets used in the controlled probes.
Authors: MemFT is a threshold-guided training strategy whose performance gains are shown through direct empirical comparisons in our evaluations. We will revise the abstract to decouple the description of MemFT from the phase-transition phrasing and to highlight that its benefits are demonstrated empirically within the evaluated settings. revision: partial
- Absence of a theoretical derivation of the Parametric Memory Law from loss-landscape or capacity arguments.
- Lack of out-of-distribution or additional cross-model validation beyond the LoRA probe experiments reported.
Circularity Check
p>0.5 'phase transition' reduces to argmax definition; power law presented as introduced without shown first-principles derivation
specific steps
-
other
[Abstract]
"At the token level, fine-grained analysis reveals a deterministic phase transition, demonstrating that a prediction probability of p > 0.5 constitutes a sufficient condition for verbatim recall under greedy decoding."
The sufficiency of p > 0.5 for selection under greedy decoding is a direct logical consequence of the argmax operation (the token with probability >0.5 must be the maximum), so the claimed 'deterministic phase transition' and 'demonstrating' add no new information beyond restating the decoding rule itself.
full rationale
The abstract presents the Parametric Memory Law as introduced from empirical observation and the p>0.5 condition as a revealed deterministic transition. No equations or derivation chain appear in the provided text that would allow reduction to fitted inputs or self-citations. The p>0.5 sufficiency follows directly from the definition of greedy decoding rather than from any model-specific analysis, but this is a single logical observation rather than a load-bearing derivation chain that collapses the central result. No self-citation, ansatz smuggling, or uniqueness theorem is invoked. The paper remains self-contained as an empirical report with the noted tautology on one sub-claim.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Memory Depth, Not Memory Access: Selective Parametric Consolidation for Long-Running Language Agents
EVAF, a surprise- and valence-gated LoRA mechanism, provides memory depth for goal persistence in language agents via the loop-drift protocol, complementary to retrieval.
-
Yuvion LLM: An Adversarially-Aware Large Language Model for Content And AI Safety
Yuvion LLM applies adversarially aware training and introduces the YLRE benchmark set, claiming superior safety robustness over larger models on multiple tasks.
Reference graph
Works this paper leans on
-
[1]
M. H. I. Abdalla, Zhipin Wang, Christian Frey, Steffen Eger, and Josif Grabocka. 2025. https://doi.org/10.48550/ARXIV.2510.19733 Zhyper: Factorized hypernetworks for conditioned LLM fine-tuning . CoRR, abs/2510.19733
-
[2]
Seungju Back, Dongwoo Lee, Naun Kang, Taehee Lee, S. K. Hong, Youngjune Gwon, and Sungjin Ahn. 2026. https://doi.org/10.48550/ARXIV.2603.01097 Understanding lora as knowledge memory: An empirical analysis . CoRR, abs/2603.01097
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.01097 2026
-
[3]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. https://doi.org/10.18653/V1/2024.ACL-LONG.172 Longbench: A bilingual, multitask benchmark for long context understanding . In Proceedings of the 62nd Annual Meeting of the Association for Com...
-
[4]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert - Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litw...
2020
-
[5]
Rujikorn Charakorn, Edoardo Cetin, Yujin Tang, and Robert Tjarko Lange. 2025. https://proceedings.mlr.press/v267/charakorn25a.html Text-to-lora: Instant transformer adaption . In Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 , Proceedings of Machine Learning Research. PMLR / OpenReview.net
2025
-
[6]
Rujikorn Charakorn, Edoardo Cetin, Shinnosuke Uesaka, and Robert Tjarko Lange. 2026. https://doi.org/10.48550/ARXIV.2602.15902 Doc-to-lora: Learning to instantly internalize contexts . CoRR, abs/2602.15902
-
[7]
Tong Chen, Hao Fang, Patrick Xia, Xiaodong Liu, Benjamin Van Durme, Luke Zettlemoyer, Jianfeng Gao, and Hao Cheng. 2025. https://openreview.net/forum?id=bc3sUsS6ck Generative adapter: Contextualizing language models in parameters with A single forward pass . In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, Apri...
2025
-
[8]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. https://doi.org/10.3233/FAIA251160 Mem0: Building production-ready AI agents with scalable long-term memory . In ECAI 2025 - 28th European Conference on Artificial Intelligence, 25-30 October 2025, Bologna, Italy - Including 14th Conference on Prestigious Applications of I...
-
[9]
Gr \' e goire Del \' e tang, Anian Ruoss, Paul - Ambroise Duquenne, Elliot Catt, Tim Genewein, Christopher Mattern, Jordi Grau - Moya, Li Kevin Wenliang, Matthew Aitchison, Laurent Orseau, Marcus Hutter, and Joel Veness. 2024. https://openreview.net/forum?id=jznbgiynus Language modeling is compression . In The Twelfth International Conference on Learning ...
2024
-
[10]
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. 2024. https://doi.org/10.18653/V1/2024.EMNLP-MAIN.64 A survey on in-context learning . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, Nov...
-
[11]
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Huajun Chen, and Ningyu Zhang. 2025. https://doi.org/10.48550/ARXIV.2510.18866 Lightmem: Lightweight and efficient memory-augmented generation . CoRR, abs/2510.18866
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.18866 2025
-
[12]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. 2023. https://doi.org/10.48550/ARXIV.2312.10997 Retrieval-augmented generation for large language models: A survey . CoRR, abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.10997 2023
-
[13]
Human-inspired perspectives: A survey on ai long-term memory,
Zihong He, Weizhe Lin, Hao Zheng, Fan Zhang, Matt W. Jones, Laurence Aitchison, Xuhai Xu, Miao Liu, Per Ola Kristensson, and Junxiao Shen. 2024. https://doi.org/10.48550/ARXIV.2411.00489 Human-inspired perspectives: A survey on AI long-term memory . CoRR, abs/2411.00489
-
[14]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen - Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen - Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lora: Low-rank adaptation of large language models . In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net
2022
-
[15]
Kakade, and Eran Malach
Samy Jelassi, David Brandfonbrener, Sham M. Kakade, and Eran Malach. 2024. https://proceedings.mlr.press/v235/jelassi24a.html Repeat after me: Transformers are better than state space models at copying . In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 , Proceedings of Machine Learning Research, pag...
2024
-
[16]
Josip Jukic, Martin Tutek, and Jan Snajder. 2025. https://doi.org/10.48550/ARXIV.2509.22158 Context parametrization with compositional adapters . CoRR, abs/2509.22158
-
[17]
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. 2025. https://doi.org/10.18653/V1/2025.EMNLP-MAIN.1318 Memory OS of AI agent . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025 , pages 25961--25970. Association for Computational Linguistics
-
[18]
Sorokin, and Mikhail Burtsev
Yuri Kuratov, Aydar Bulatov, Petr Anokhin, Ivan Rodkin, Dmitry Sorokin, Artyom Y. Sorokin, and Mikhail Burtsev. 2024. http://papers.nips.cc/paper\_files/paper/2024/hash/c0d62e70dbc659cc9bd44cbcf1cb652f-Abstract-Datasets\_and\_Benchmarks\_Track.html Babilong: Testing the limits of llms with long context reasoning-in-a-haystack . In Advances in Neural Infor...
2024
-
[19]
Jingdi Lei, Di Zhang, Junxian Li, Weida Wang, Kaixuan Fan, Xiang Liu, Qihan Liu, Xiaoteng Ma, Baian Chen, and Soujanya Poria. 2026. https://api.semanticscholar.org/CorpusID:288259118 -mem: Efficient online memory for large language models
2026
-
[20]
u ttler, Mike Lewis, Wen - tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \" u ttler, Mike Lewis, Wen - tau Yih, Tim Rockt \" a schel, Sebastian Riedel, and Douwe Kiela. 2020. https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html Retrieval-augmented generation for knowledge-intensive ...
2020
-
[21]
Jiakai Li, Rongzheng Wang, Yizhuo Ma, Shuang Liang, Guangchun Luo, and Ke Qin. 2026. Dsas: A universal plug-and-play framework for attention optimization in multi-document question answering. Advances in Neural Information Processing Systems, 38:174538--174564
2026
-
[22]
Zhiyu Li, Shichao Song, Hanyu Wang, Simin Niu, Ding Chen, Jiawei Yang, Chenyang Xi, Huayi Lai, Jihao Zhao, Yezhaohui Wang, Junpeng Ren, Zehao Lin, Jiahao Huo, Tianyi Chen, Kai Chen, Kehang Li, Zhiqiang Yin, Qingchen Yu, Bo Tang, Hongkang Yang, Zhi - Qin John Xu, and Feiyu Xiong. 2025. https://doi.org/10.48550/ARXIV.2505.22101 Memos: An operating system fo...
-
[23]
Bronstein, Yang You, Zhangyang Wang, and Kai Wang
Zhiyuan Liang, Dongwen Tang, Yuhao Zhou, Xuanlei Zhao, Mingjia Shi, Wangbo Zhao, Zekai Li, Peihao Wang, Konstantin Sch \" u rholt, Damian Borth, Michael M. Bronstein, Yang You, Zhangyang Wang, and Kai Wang. 2025. https://doi.org/10.48550/ARXIV.2506.16406 Drag-and-drop llms: Zero-shot prompt-to-weights . CoRR, abs/2506.16406
-
[24]
Lei Liu, Xiaoyan Yang, Yue Shen, Binbin Hu, Zhiqiang Zhang, Jinjie Gu, and Guannan Zhang. 2023. https://doi.org/10.48550/ARXIV.2311.08719 Think-in-memory: Recalling and post-thinking enable llms with long-term memory . CoRR, abs/2311.08719
-
[25]
Lost in the middle: How language models use long contexts
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. https://doi.org/10.1162/TACL\_A\_00638 Lost in the middle: How language models use long contexts . Trans. Assoc. Comput. Linguistics, 12:157--173
work page internal anchor Pith review doi:10.1162/tacl 2024
-
[26]
Adyasha Maharana, Dong - Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. https://doi.org/10.18653/V1/2024.ACL-LONG.747 Evaluating very long-term conversational memory of LLM agents . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thaila...
-
[27]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. http://papers.nips.cc/paper\_files/paper/2022/hash/6f1d43d5a82a37e89b0665b33bf3a182-Abstract-Conference.html Locating and editing factual associations in GPT . In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2...
2022
-
[28]
Ponti, Laurent Charlin, Nicolas Le Roux, Lucas Caccia, and Alessandro Sordoni
Oleksiy Ostapenko, Zhan Su, Edoardo M. Ponti, Laurent Charlin, Nicolas Le Roux, Lucas Caccia, and Alessandro Sordoni. 2024. https://proceedings.mlr.press/v235/ostapenko24a.html Towards modular llms by building and reusing a library of loras . In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 , Procee...
2024
-
[29]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. 2023. https://doi.org/10.48550/ARXIV.2310.08560 Memgpt: Towards llms as operating systems . CoRR, abs/2310.08560
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08560 2023
-
[30]
Sergey Pletenev, Maria Marina, Daniil Moskovskiy, Vasily Konovalov, Pavel Braslavski, Alexander Panchenko, and Mikhail Salnikov. 2025. https://doi.org/10.18653/V1/2025.FINDINGS-NAACL.243 How much knowledge can you pack into a lora adapter without harming llm? In Findings of the Association for Computational Linguistics: NAACL 2025, Albuquerque, New Mexico...
-
[31]
V.F. Reyna and C.J. Brainerd. 1995. https://doi.org/10.1016/1041-6080(95)90031-4 Fuzzy-trace theory: An interim synthesis . Learning and Individual Differences, 7(1):1--75. Special Issue: Fuzzy-Trace Theory
-
[32]
Weihang Su, Yichen Tang, Qingyao Ai, Junxi Yan, Changyue Wang, Hongning Wang, Ziyi Ye, Yujia Zhou, and Yiqun Liu. 2025. https://doi.org/10.1145/3726302.3729957 Parametric retrieval augmented generation . In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2025, Padua, Italy, July 13-18,...
-
[33]
Yuqiao Tan, Shizhu He, Huanxuan Liao, Jun Zhao, and Kang Liu. 2025 a . https://doi.org/10.48550/ARXIV.2503.23895 Better wit than wealth: Dynamic parametric retrieval augmented generation for test-time knowledge enhancement . CoRR, abs/2503.23895
-
[34]
Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, Anand Rajan Iyer, Tianlong Chen, Huan Liu, Chen - Yu Lee, and Tomas Pfister
Zhen Tan, Jun Yan, I - Hung Hsu, Rujun Han, Zifeng Wang, Long T. Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, Anand Rajan Iyer, Tianlong Chen, Huan Liu, Chen - Yu Lee, and Tomas Pfister. 2025 b . https://aclanthology.org/2025.acl-long.413/ In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents . In P...
2025
-
[35]
Llama Team. 2024. https://doi.org/10.48550/ARXIV.2407.21783 The llama 3 herd of models . CoRR, abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[36]
Qwen Team. 2025. https://doi.org/10.48550/ARXIV.2505.09388 Qwen3 technical report . CoRR, abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[37]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai - Wei Chang, and Dong Yu. 2025. https://openreview.net/forum?id=pZiyCaVuti Longmemeval: Benchmarking chat assistants on long-term interactive memory . In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net
2025
-
[38]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. https://openreview.net/forum?id=NG7sS51zVF Efficient streaming language models with attention sinks . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
-
[39]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. 2025. https://doi.org/10.48550/ARXIV.2502.12110 A-MEM: agentic memory for LLM agents . CoRR, abs/2502.12110
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.12110 2025
-
[40]
Ziwen Xu, Chenyan Wu, Hengyu Sun, Haiwen Hong, Mengru Wang, Yunzhi Yao, Longtao Huang, Hui Xue, Shumin Deng, Zhixuan Chu, Huajun Chen, and Ningyu Zhang. 2026. https://doi.org/10.48550/ARXIV.2602.02343 Why steering works: Toward a unified view of language model parameter dynamics . CoRR, abs/2602.02343
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.02343 2026
-
[41]
Hongkang Yang, Zehao Lin, Wenjin Wang, Hao Wu, Zhiyu Li, Bo Tang, Wenqiang Wei, Jinbo Wang, Zeyun Tang, Shichao Song, Chenyang Xi, Yu Yu, Kai Chen, Feiyu Xiong, Linpeng Tang, and Weinan E. 2024. https://doi.org/10.48550/ARXIV.2407.01178 Memory\( ^ 3 \): Language modeling with explicit memory . CoRR, abs/2407.01178
-
[42]
Yunzhi Yao, Peng Wang, Bozhong Tian, Siyuan Cheng, Zhoubo Li, Shumin Deng, Huajun Chen, and Ningyu Zhang. 2023. https://doi.org/10.18653/V1/2023.EMNLP-MAIN.632 Editing large language models: Problems, methods, and opportunities . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10...
-
[43]
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. 2023. https://openreview.net/forum?id=lq62uWRJjiY Adaptive budget allocation for parameter-efficient fine-tuning . In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net
2023
-
[44]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models. arXiv preprint arXiv:2303.18223, 1(2)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. https://doi.org/10.1609/AAAI.V38I17.29946 Memorybank: Enhancing large language models with long-term memory . In Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Sympo...
-
[46]
Tongyao Zhu, Qian Liu, Liang Pang, Zhengbao Jiang, Min - Yen Kan, and Min Lin. 2024. https://doi.org/10.18653/V1/2024.ACL-LONG.185 Beyond memorization: The challenge of random memory access in language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, A...
-
[47]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[48]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.