Seeing Isn't Knowing: Do VLMs Know When Not to Answer Spatial Questions (and Why)?
Pith reviewed 2026-06-29 07:46 UTC · model grok-4.3
The pith
VLMs overconfidently answer spatial questions even when views are occluded or misleading.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
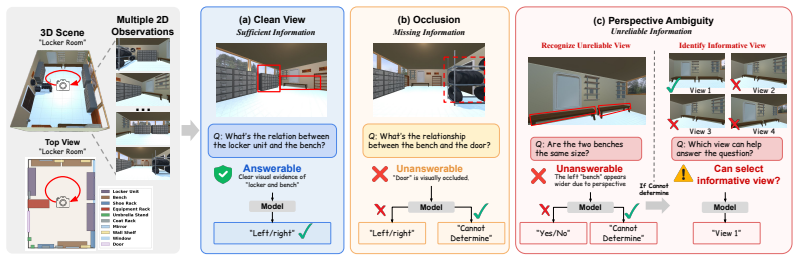
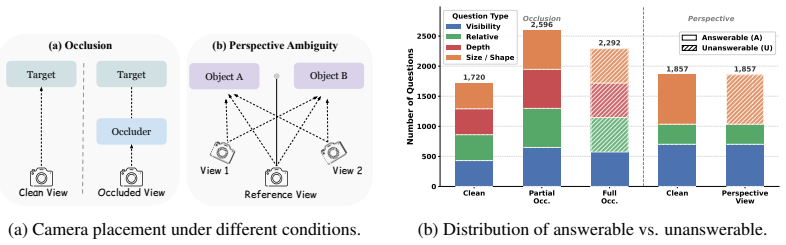
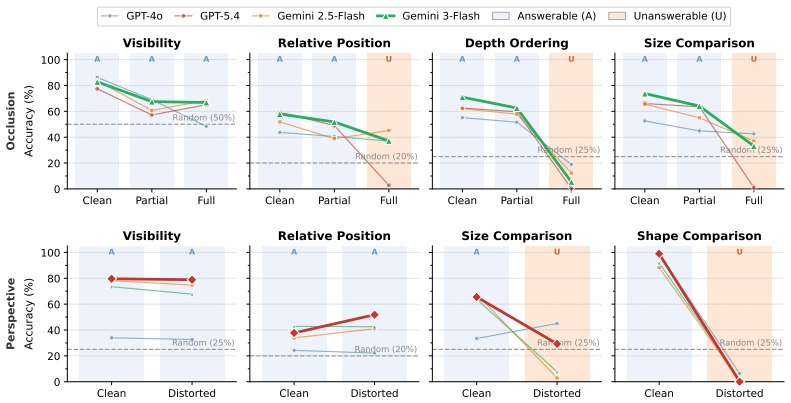
The paper establishes that frontier open- and closed-source VLMs exhibit consistent overconfident answering on spatial reasoning tasks under occlusion and perspective ambiguity challenges, producing average accuracies around 30 percent and below 10 percent respectively, while many models select additional resolving views at rates near random chance.
What carries the argument
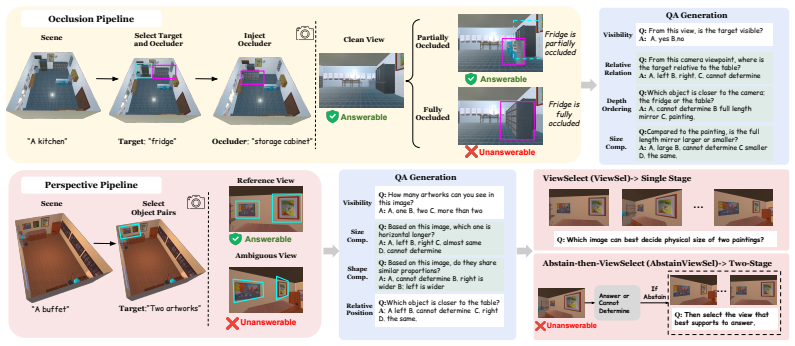
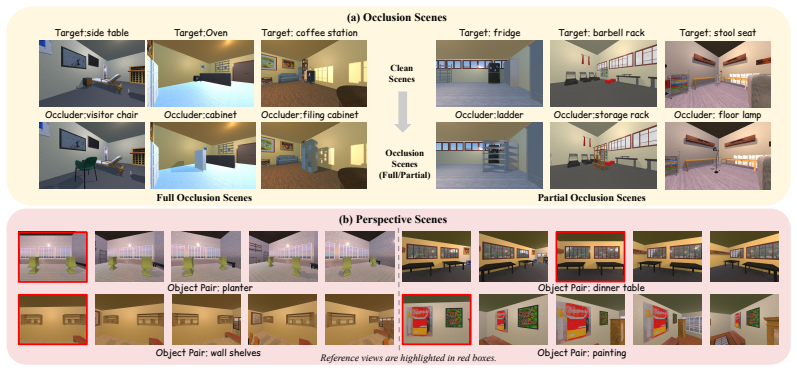
SpatialUncertain, a controlled evaluation framework that pairs answerable spatial questions with introduced occlusion and perspective ambiguity conditions to require abstention or view selection.
If this is right
- Spatial reasoning benchmarks must test for recognition of insufficient evidence in addition to answer correctness.
- Models need explicit mechanisms to detect incomplete or misleading observations and choose to abstain.
- Evaluation protocols should measure the ability to identify which additional viewpoints would resolve ambiguity.
- Real-world deployment of VLMs for spatial tasks requires handling observation uncertainty rather than assuming reliable inputs.
Where Pith is reading between the lines
- Robotics and navigation systems using these models may produce errors when relying on partial or angled camera feeds.
- Training approaches could incorporate explicit rewards for abstention on ambiguous spatial inputs.
- The results point toward integrating active perception, where models request new observations when current ones are insufficient.
Load-bearing premise
The constructed spatial questions become genuinely unanswerable from the challenged views, so that abstention is the required behavior.
What would settle it
A model that abstains at high rates on the occlusion and ambiguity cases or selects resolving views well above chance while maintaining high accuracy on clean cases would contradict the reported failure modes.
Figures

read the original abstract
Spatial reasoning is a fundamental capability for vision-language models (VLMs) deployed in real-world environments. However, visual observations are inherently limited representations of a 3D world: occlusion can render objects invisible, and perspective can make geometric properties misleading. Despite this, existing spatial reasoning benchmarks typically assume that observations are sufficient and reliable, focusing on whether models produce correct answers rather than whether they recognize when a question cannot be answered and what additional observations would be needed. In this work, we challenge this assumption by constructing a controlled evaluation framework, SpatialUncertain, and introducing two types of observation challenges: (1) occlusion, which hides target information, and (2) perspective ambiguity, which produces misleading visual cues. For each configuration, we design spatial questions that are answerable under clean observations but require abstention under the introduced challenges. We further evaluate whether models can identify which additional viewpoints would resolve perspective ambiguity. Our results across a diverse set of frontier open- and closed-source VLMs reveal two consistent failure modes. First, models are prone to overconfident answering, attempting to solve spatial reasoning tasks even when visual evidence is incomplete or misleading, with average accuracy around 30\% under occlusion and below 10\% under perspective ambiguity. Second, even when additional views are available, some models perform near random chance in identifying which would provide reliable evidence. Together, our findings call for moving beyond answer correctness toward evaluating whether models know when to abstain and how to seek reliable evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpatialUncertain, a controlled evaluation framework for VLMs on spatial reasoning questions under two observation challenges: occlusion (hiding target information) and perspective ambiguity (misleading geometric cues). It claims that questions are answerable from clean views but require abstention under challenges, and reports that frontier VLMs exhibit overconfident answering (average accuracy ~30% under occlusion, <10% under perspective ambiguity) and often fail to identify helpful additional viewpoints even when available.
Significance. If the central claims hold after validation, the work is significant for highlighting a gap between answer correctness and uncertainty awareness in VLMs, which is critical for real-world deployment. The empirical evaluation across open- and closed-source models provides concrete failure mode data that could motivate new benchmarks focused on abstention and evidence-seeking behavior.
major comments (2)
- [Abstract / SpatialUncertain description] Abstract and SpatialUncertain construction: the claim that designed questions 'are answerable under clean observations but require abstention under the introduced challenges' is load-bearing for interpreting low accuracies as overconfident failure to abstain rather than task hardness, yet the manuscript provides no human performance baselines on the challenged images, no formal geometric argument for unanswerability, and no independent verification that correct answers are impossible from the given views.
- [Abstract] Abstract: the specific accuracy figures (~30% occlusion, below 10% perspective) are presented without any description of question construction details, prompting strategy, number of trials, or statistical controls, preventing verification of the 'systematic failure modes' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas for strengthening the validation of our claims. We address each major comment below and will incorporate revisions to provide additional evidence and details.
read point-by-point responses
-
Referee: [Abstract / SpatialUncertain description] Abstract and SpatialUncertain construction: the claim that designed questions 'are answerable under clean observations but require abstention under the introduced challenges' is load-bearing for interpreting low accuracies as overconfident failure to abstain rather than task hardness, yet the manuscript provides no human performance baselines on the challenged images, no formal geometric argument for unanswerability, and no independent verification that correct answers are impossible from the given views.
Authors: We agree these elements would strengthen the central claim. The manuscript describes the question design process in Section 3, where configurations were selected such that target information is inaccessible or misleading under the challenges while solvable from clean views. However, we acknowledge the absence of human baselines, formal geometric arguments, and documented independent verification. In revision, we will add: (1) human performance results on a subset of clean and challenged views demonstrating appropriate abstention; (2) a geometric analysis subsection with diagrams showing why answers cannot be determined; and (3) details on multi-annotator verification of unanswerability during construction. revision: yes
-
Referee: [Abstract] Abstract: the specific accuracy figures (~30% occlusion, below 10% perspective) are presented without any description of question construction details, prompting strategy, number of trials, or statistical controls, preventing verification of the 'systematic failure modes' claim.
Authors: The abstract prioritizes brevity, while the full manuscript provides these details in Sections 3 (construction of occlusion and perspective ambiguity cases) and 4 (evaluation protocol, including prompting variants and trial counts with variance). To improve verifiability, we will revise the abstract to include a brief reference to the evaluation scale and direct readers to the methods for construction, prompting, and statistical details. revision: yes
Circularity Check
Empirical evaluation on new benchmark; no derivations or fitted predictions
full rationale
The paper introduces SpatialUncertain by constructing questions asserted to be answerable under clean observations but requiring abstention under occlusion/perspective challenges. It then reports empirical accuracies of existing VLMs on this test set (e.g., ~30% under occlusion). No equations, parameters, or predictions are fitted within the paper and then renamed as results. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are present. The evaluation is externally falsifiable via human baselines or further testing on the released set. This is a standard empirical benchmark paper with no internal circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visual observations can be insufficient or misleading for spatial questions due to occlusion and perspective.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.Ar...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Spatialrgpt: Grounded spatial reasoning in vision language model.ArXiv, abs/2406.01584,
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision language model.ArXiv, abs/2406.01584,
-
[3]
Deepmind. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.https://arxiv.org/abs/2507.06261, 2025a. Deepmind. Gemini 3 flash: Frontier intelligence built for speed. https://blog.google/produc ts/gemini/gemini-3-flash/, 2025b. Jiafei Duan, Samson Yu, Hui Li Tan, Hongyuan Zhu, an...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Selectively answering visual questions
Julian Eisenschlos, Hernán Maina, Guido Ivetta, and Luciana Benotti. Selectively answering visual questions. InFindings of the Association for Computational Linguistics: ACL 2024, pages 4219–4229,
2024
-
[5]
Xingwei He, Qianru Zhang, A Jin, Yuan Yuan, Siu-Ming Yiu, et al. Tubench: Benchmarking large vision-language models on trustworthiness with unanswerable questions.arXiv preprint arXiv:2410.04107,
-
[6]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks.arXiv preprint arXiv:1610.02136,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
LoRA: Low-Rank Adaptation of Large Language Models
10 J. Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.ArXiv, abs/2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi
URL https://api.semanticscholar.org/CorpusID:235458009. Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models.arXiv preprint arXiv:2506.03135,
-
[9]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
What’s “up” with vision-language models? investigating their struggle with spatial reasoning
Amita Kamath, Jack Hessel, and Kai-Wei Chang. What’s “up” with vision-language models? investigating their struggle with spatial reasoning. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9161–9175,
2023
-
[11]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305,
2023
-
[13]
Sqa3d: Situated question answering in 3d scenes.arXiv preprint arXiv:2210.07474,
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. Sqa3d: Situated question answering in 3d scenes.arXiv preprint arXiv:2210.07474,
-
[14]
Selfcheckgpt: Zero-resource black-box hallucina- tion detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. Selfcheckgpt: Zero-resource black-box hallucina- tion detection for generative large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 9004–9017,
2023
-
[15]
Navid Rajabi and Jana Kosecka. Gsr-bench: A benchmark for grounded spatial reasoning evaluation via multimodal llms.ArXiv, abs/2406.13246,
-
[16]
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko
URL https://api.semanticscholar.or g/CorpusID:270619607. Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045,
2018
-
[17]
11 Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Ilias Stogiannidis, Steven McDonagh, and Sotirios A Tsaftaris. Mind the gap: Benchmarking spatial reasoning in vision-language models.arXiv preprint arXiv:2503.19707,
-
[19]
Aligning large multimodal models with factually augmented rlhf
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liangyan Gui, Yu-Xiong Wang, Yiming Yang, et al. Aligning large multimodal models with factually augmented rlhf. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13088–13110,
2024
-
[20]
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages ...
2023
-
[21]
SpatialBench: Benchmarking Multimodal Large Language Models for Spatial Cognition
URL https: //openreview.net/forum?id=gjeQKFxFpZ. Peiran Xu, Sudong Wang, Yao Zhu, Jianing Li, Gege Qi, and Yunjian Zhang. Spatialbench: Bench- marking multimodal large language models for spatial cognition.arXiv preprint arXiv:2511.21471,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025a. Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis L Brown II, Zihao Yang, Yue Yu, Shengb...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Do large language models know what they don’t know? InFindings of the association for Computational Linguistics: ACL 2023, pages 8653–8665,
12 Zhangyue Yin, Qiushi Sun, Qipeng Guo, Jiawen Wu, Xipeng Qiu, and Xuan-Jing Huang. Do large language models know what they don’t know? InFindings of the association for Computational Linguistics: ACL 2023, pages 8653–8665,
2023
-
[24]
Shoubin Yu, Yue Zhang, Zun Wang, Jaehong Yoon, Huaxiu Yao, Mingyu Ding, and Mohit Bansal. When and how much to imagine: Adaptive test-time scaling with world models for visual spatial reasoning.ArXiv, abs/2602.08236, 2026a. URL https://api.semanticscholar.org/Corp usID:285452504. Shoubin Yu, Yue Zhang, Zun Wang, Jaehong Yoon, Huaxiu Yao, Mingyu Ding, and ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
URL https: //api.semanticscholar.org/CorpusID:257038436. Yue Zhang, Ziqiao Ma, Jialu Li, Yanyuan Qiao, Zun Wang, Joyce Chai, Qi Wu, Mohit Bansal, and Parisa Kordjamshidi. Vision-and-language navigation today and tomorrow: A survey in the era of foundation models.arXiv preprint arXiv:2407.07035, 2024a. Yue Zhang, Zhiyang Xu, Ying Shen, Parisa Kordjamshidi,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.