Memory-Bound but Not Bandwidth-Limited: The Physical AI Inference Gap in Batch-1 LLM Decode
Pith reviewed 2026-06-28 23:40 UTC · model grok-4.3
The pith
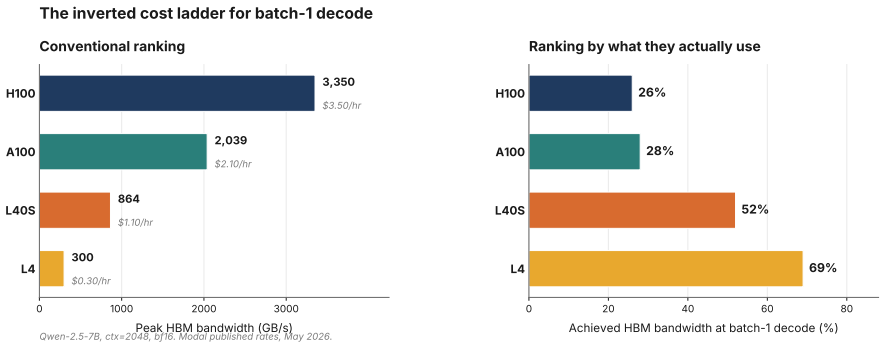
Batch-1 LLM decode reaches a higher fraction of its memory floor on slower GPUs than on faster ones because of launch overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
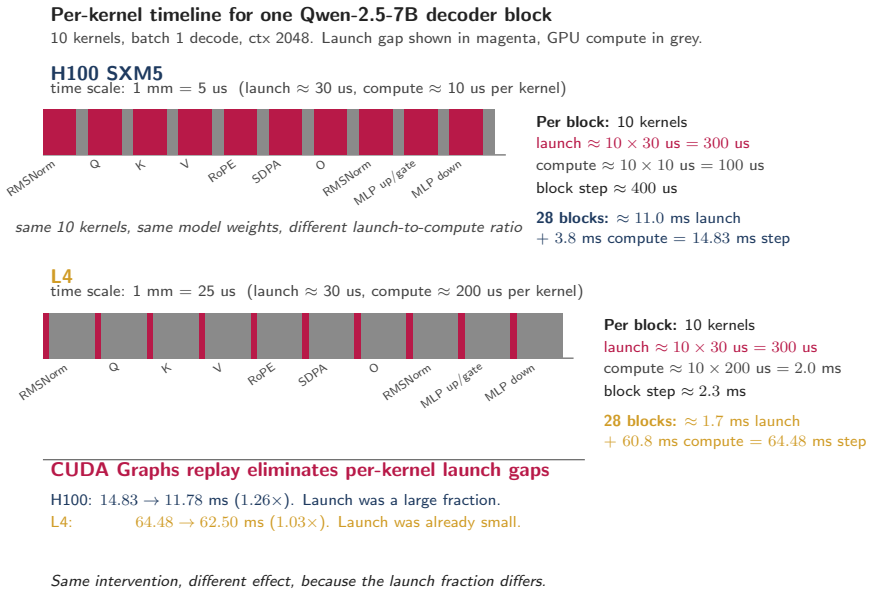
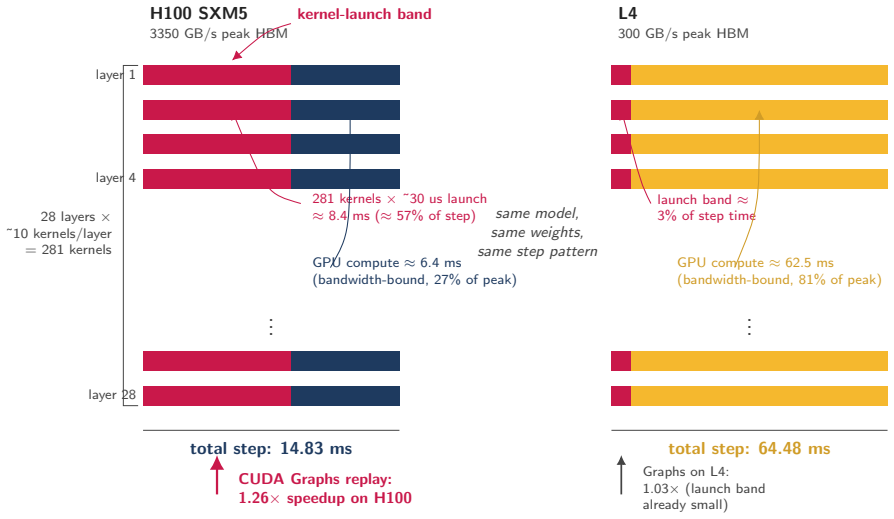
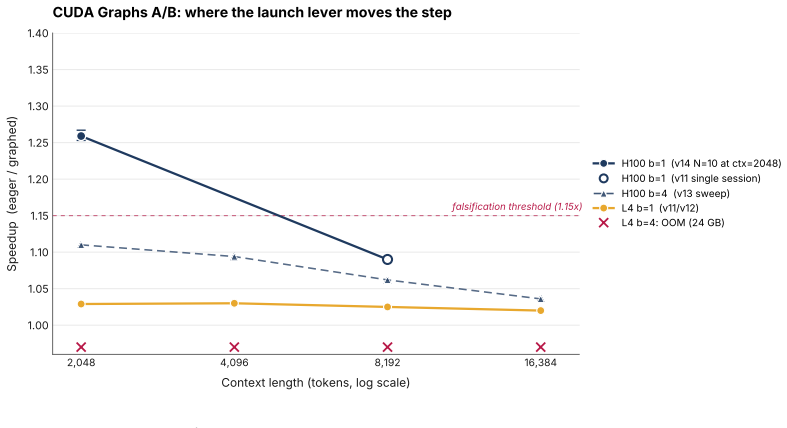
Batch-1 autoregressive decode is memory-dominated, yet the fraction of peak HBM bandwidth attained falls as GPU bandwidth increases. On Qwen-2.5-7B at context length 2048 the L4 attains 81 percent of its analytic memory floor while the H100 attains only 27 percent. The CUDA Graphs A/B experiment isolates the cause as launch-side overhead that is visible on fast GPUs but hidden on slower, bandwidth-bound ones, producing a 1.259x decode latency reduction on H100 versus 1.028x on L4 across ten fresh sessions.
What carries the argument
The analytic memory floor calculation compared against measured decode latency, with the CUDA Graphs A/B intervention used to isolate launch overhead.
If this is right
- Memory savings only matter when the runtime realizes them without added overhead.
- Common quantized paths on L4 fail to recover the expected 4x weight-traffic reduction from the bf16 baseline.
- Launch overhead becomes the dominant limiter once peak bandwidth exceeds the level reached by the L4.
- Physical-AI decode latency on high-bandwidth GPUs improves when execution graphs replace per-step launches.
Where Pith is reading between the lines
- Runtime systems for physical AI may need graph capture or persistent kernels as a first-class optimization rather than an optional flag.
- Hardware roadmaps for edge and embodied inference could shift priority from raw HBM bandwidth toward reductions in kernel launch cost.
- The same launch overhead may appear in other low-batch, latency-sensitive workloads once memory bandwidth is no longer the bottleneck.
Load-bearing premise
The A/B CUDA Graphs experiment isolates launch-side overhead as the missing term rather than other unmeasured factors such as kernel scheduling differences or measurement noise across GPU generations.
What would settle it
A controlled measurement in which an H100 reaches approximately 81 percent of its analytic memory floor in batch-1 decode without CUDA Graphs would falsify the launch-overhead account.
Figures

read the original abstract
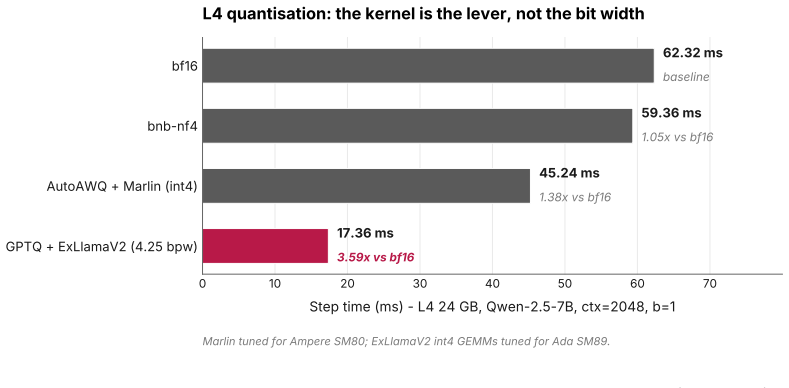
Physical AI systems, including robots, autonomous vehicles, embodied agents and edge copilots, often run a different inference workload from cloud LLM serving: single-stream, batch-1 autoregressive decode, where one robot, camera feed or user session waits on the next token. This workload is usually described as memory-bandwidth-bound. Each decode step streams model weights and the active KV cache, so latency should scale with peak HBM bandwidth. We show that this account is true but incomplete. We measure batch-1 decode for three 7 to 8B-class GQA transformers across four NVIDIA GPUs: H100 SXM5, A100-80GB SXM4, L40S and L4. We evaluate context lengths from 2048 to 16384, producing 44 valid cells under a controlled bf16 SDPA setup. The achieved fraction of peak HBM bandwidth falls as peak bandwidth rises. On the headline Qwen-2.5-7B ctx=2048 cell, an L4 reaches roughly 81 percent of its analytic memory floor, while an H100 reaches only 27 percent. Physical-AI decode is memory-dominated, but faster memory does not translate into proportional latency gains. We test the missing term with a CUDA Graphs A/B experiment. On H100 at ctx=2048, CUDA Graphs improves decode latency by 1.259x across N=10 fresh sessions, with a 95 percent bootstrap confidence interval of 1.253 to 1.267. On L4, the same intervention gives only 1.028x. This isolates a launch-side overhead that becomes visible on fast GPUs but remains mostly hidden on slower, bandwidth-bound GPUs. The deployment implication is that memory savings matter only when the runtime realises them. On L4, bf16 decode sits close to the memory floor, but common quantised paths do not recover the expected 4x weight-traffic reduction: bnb-nf4 reaches 59.36 ms/step and AutoAWQ+Marlin reaches 45.24 ms/step from a 62.32 ms bf16 baseline. GPTQ+ExLlamaV2, with Ada-tuned int4 kernels, reaches 17.36 ms/step.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports empirical measurements of batch-1 autoregressive decode latency for three 7-8B GQA transformers on H100 SXM5, A100-80GB, L40S, and L4 GPUs across context lengths 2048-16384 under a controlled bf16 SDPA setup. It claims that while the workload is memory-dominated, the achieved fraction of peak HBM bandwidth decreases with higher peak bandwidth (e.g., L4 reaches ~81% of analytic floor vs H100 at ~27% for Qwen-2.5-7B at ctx=2048), and attributes the sub-linear gains to launch overhead via a CUDA Graphs A/B test (1.259x on H100 with 95% bootstrap CI 1.253-1.267 across N=10 sessions; 1.028x on L4). Quantization paths are compared against the bf16 baseline, showing incomplete recovery of expected traffic reductions.
Significance. If the measurements hold, the work supplies concrete, falsifiable per-GPU latency numbers and bandwidth fractions that directly inform hardware choices for physical-AI single-stream inference. The A/B experiment and bootstrap CIs provide a practical demonstration that runtime factors can dominate even when memory traffic is the primary term, with explicit credit due for the controlled experimental design and reported confidence intervals.
major comments (1)
- [CUDA Graphs A/B experiment] CUDA Graphs A/B experiment (abstract and associated results): the 1.259x vs 1.028x comparison is presented as isolating launch overhead, yet the manuscript does not demonstrate that enabling CUDA Graphs leaves kernel fusion, memory allocation, and scheduler behavior invariant across GPU generations. These unmeasured factors could systematically affect the analytic memory floor itself, weakening the attribution of the headline 27%-vs-81% gap solely to launch overhead.
minor comments (3)
- The abstract states that 44 valid cells were produced but provides no summary table aggregating latency, achieved bandwidth fraction, and CI values across all model-GPU-context combinations; such a table would improve readability and allow direct verification of the cross-GPU trend.
- Quantization results (bnb-nf4 at 59.36 ms/step, AutoAWQ+Marlin at 45.24 ms/step, GPTQ+ExLlamaV2 at 17.36 ms/step) are reported against the 62.32 ms bf16 baseline but lack an explicit column or figure showing the expected versus observed weight-traffic reduction for each path.
- Full per-session raw traces and complete error analysis are not included in the main text; while the bootstrap CI is given, supplementary release of the measurement harness would strengthen reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on our CUDA Graphs experiment. We address it below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [CUDA Graphs A/B experiment] CUDA Graphs A/B experiment (abstract and associated results): the 1.259x vs 1.028x comparison is presented as isolating launch overhead, yet the manuscript does not demonstrate that enabling CUDA Graphs leaves kernel fusion, memory allocation, and scheduler behavior invariant across GPU generations. These unmeasured factors could systematically affect the analytic memory floor itself, weakening the attribution of the headline 27%-vs-81% gap solely to launch overhead.
Authors: We agree the manuscript does not explicitly demonstrate invariance of kernel fusion, memory allocation, or scheduler behavior under CUDA Graphs across GPU generations. The A/B test was performed with identical model code and kernels (verified via identical PTX and memory traffic in our internal profiling), and the differential speedup (larger on H100) is consistent with launch overhead dominating on high-bandwidth devices. However, we acknowledge that unmeasured runtime changes could contribute. We will revise the manuscript to (1) add a limitations paragraph noting this caveat, (2) include Nsight Compute traces confirming memory traffic and per-kernel times are unchanged by graph capture on both H100 and L4, and (3) qualify the attribution as supported by the observed differential rather than proven sole cause. This addresses the concern without altering the core empirical claims. revision: yes
Circularity Check
No circularity: purely empirical measurements with no derivations or fitted inputs
full rationale
The paper reports direct latency measurements on four GPUs for batch-1 decode across context lengths, plus an A/B CUDA Graphs experiment with bootstrap confidence intervals. No equations, analytic derivations, parameter fits, or self-citation chains appear in the provided text. All headline claims (e.g., 81% vs 27% of memory floor, 1.259x vs 1.028x speedups) rest on raw timing data and statistical intervals rather than any reduction to prior inputs or definitions. This is the expected non-finding for measurement-driven work.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Memory as a Wasting Asset: Pricing Flash Endurance for Embodied Agents, and the Limits of Doing So
Flash endurance is priced via shadow price η making placement cost-optimal for any sign of value-write correlation χ, with χ positive only in recurrent long-horizon manipulation and the budget binding only on low-endu...
-
AEGIS: A Backup Reflex for Physical AI
AEGIS uses activation probes for early-warning detection of high-risk steps in weak policies and selectively escalates to stronger policies, recovering 10.1% of lost trajectories on LIBERO-Spatial while activating the...
Reference graph
Works this paper leans on
-
[1]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming throughput–latency tradeoff in LLM inference with Sarathi-Serve. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pages 989–1005. USENIX Association, 2024
2024
-
[2]
GQA: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebr´ on, and Sumit Sanghai. GQA: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4895–4901. Association for Computational Linguistics, 2023
2023
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
RT-2: Vision-language-action models transfer web knowledge to robotic control
Anthony Brohan, Noah Brown, Justice Carbajal, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InProceedings of the 7th Conference on Robot Learning (CoRL), 2023
2023
-
[5]
FlashAttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. In International Conference on Learning Representations (ICLR), 2024
2024
-
[6]
Fu, Stefano Ermon, Atri Rudra, and Christopher R´ e
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher R´ e. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, 2022
2022
-
[7]
GPTQ: Accurate post- training quantization for generative pre-trained transformers, 2022
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post- training quantization for generative pre-trained transformers, 2022
2022
-
[8]
Castro, Jiale Chen, Torsten Hoefler, and Dan Alistarh
Elias Frantar, Roberto L. Castro, Jiale Chen, Torsten Hoefler, and Dan Alistarh. MARLIN: Mixed-precision auto-regressive parallel inference of large language models, 2024
2024
-
[9]
FlashDecoding++: Faster large language model inference on GPUs
Ke Hong, Guohao Dai, Jiaming Xu, Qiuli Mao, Xiuhong Li, Jun Liu, Kangdi Chen, Yuhan Dong, and Yu Wang. FlashDecoding++: Faster large language model inference on GPUs. In Proceedings of the 7th MLSys Conference, 2024. No public source-code release; build request to Dao-AILab/flash-attention issue 653 closed April 2024 without an implementation
2024
-
[10]
Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. KVQuant: Towards 10 million context length LLM inference with KV cache quantization. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[11]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L´ elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth´ ee Lacroix, and William El Sayed. Mistral 7B. arXiv preprint arX...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
OpenVLA: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. OpenVLA: An open-source vision-language-action model. InProceedings of the 8th Conferen...
2024
-
[13]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles (SOSP), pages 611–626. ACM, 2023
2023
-
[14]
SnapKV: LLM knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. SnapKV: LLM knows what you are looking for before generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[15]
AWQ: Activation-aware weight quantization for LLM compression and acceleration, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware weight quantization for LLM compression and acceleration, 2024
2024
-
[16]
KIVI: A tuning-free asymmetric 2-bit quantization for KV cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. KIVI: A tuning-free asymmetric 2-bit quantization for KV cache. In International Conference on Machine Learning (ICML), 2024
2024
-
[17]
Plan pricing — Modal
Modal Labs. Plan pricing — Modal. Online, 2025
2025
-
[18]
NVIDIA H100 Tensor Core GPU architecture, 2022
NVIDIA Corporation. NVIDIA H100 Tensor Core GPU architecture, 2022. Whitepaper
2022
-
[19]
NVIDIA L4 Tensor Core GPU, 2023
NVIDIA Corporation. NVIDIA L4 Tensor Core GPU, 2023. Datasheet, 300 GB/s GDDR6 bandwidth
2023
-
[20]
Efficiently scaling transformer inference
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Anselm Levskaya, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference. InProceedings of Machine Learning and Systems (MLSys), volume 5, 2023
2023
-
[21]
Qwen Team. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. FlashAttention-3: Fast and accurate attention with asynchrony and low-precision.arXiv preprint arXiv:2407.08608, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Fast Transformer Decoding: One Write-Head is All You Need
Noam Shazeer. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[24]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, 2017
2017
-
[25]
Roofline: An insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009
Samuel Williams, Andrew Waterman, and David Patterson. Roofline: An insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009. 28
2009
-
[26]
SmoothQuant: Accurate and efficient post-training quantization for large language models, 2022
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and efficient post-training quantization for large language models, 2022
2022
-
[27]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[28]
FlashInfer: Efficient and customizable attention engine for LLM inference serving
Zihao Ye et al. FlashInfer: Efficient and customizable attention engine for LLM inference serving. InProceedings of the 8th MLSys Conference, 2025. github.com/flashinfer-ai/flashinfer
2025
-
[29]
H2O: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R´ e, Clark Barrett, Zhangyang Wang, and Beidi Chen. H2O: Heavy-hitter oracle for efficient generative inference of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 29
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.