ExpGraph: Model-Agnostic Experience Learning with Graph-Structured Memory for LLM Agents
Pith reviewed 2026-06-28 22:59 UTC · model grok-4.3
The pith
ExpGraph lets frozen LLM executors reuse experiences from a self-evolving graph without any parameter updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
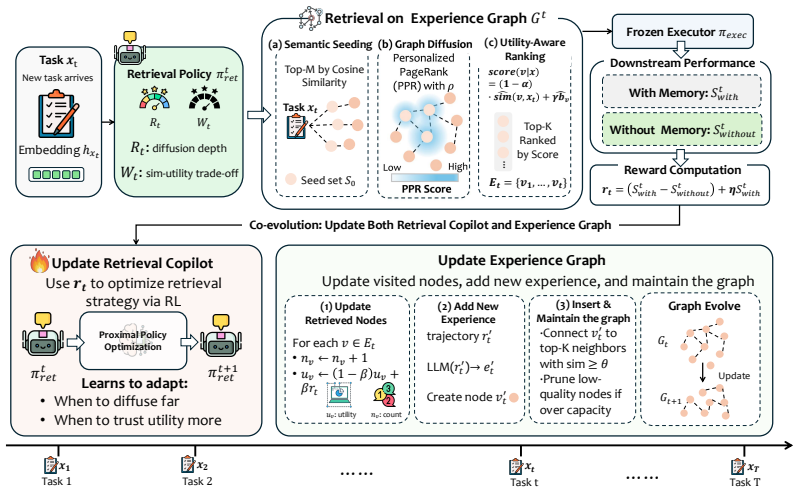
ExpGraph summarizes historical trajectories into reusable skills and failure lessons, organizes them as nodes in a self-evolving experience graph, and retrieves useful experiences through graph diffusion and utility-aware ranking. A lightweight retrieval copilot is trained with reinforcement learning using feedback that compares executor performance with and without retrieved experiences, while the graph is updated online from downstream task outcomes. This enables frozen and replaceable LLM executors to improve through external experience reuse without parameter updates.
What carries the argument
The self-evolving experience graph that stores summarized trajectories as nodes, retrieved via graph diffusion and utility-aware ranking under control of an RL-trained retrieval copilot.
If this is right
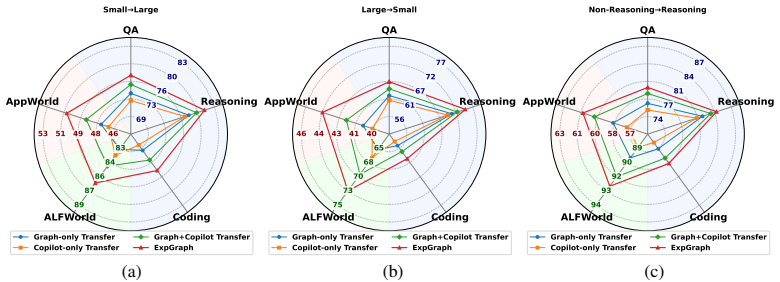
- Executors of different sizes can all benefit from the same external graph without retraining.
- Average interaction steps drop because retrieved lessons steer the agent away from repeated mistakes.
- The framework applies equally to static reasoning tasks and multi-step agentic environments.
- Swapping in a stronger executor later requires no re-processing of past experience data.
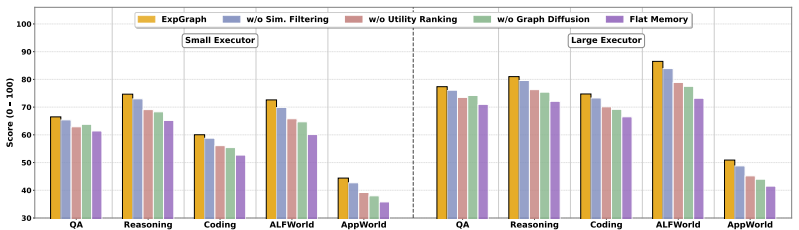
- Graph structure, utility ranking, and the adaptive copilot each contribute measurable value according to ablations.
Where Pith is reading between the lines
- The same graph could serve multiple agents operating in parallel by sharing nodes across instances.
- Adding explicit conflict detection between opposing lessons would be a natural next extension when experiences contradict.
- Measuring how quickly the graph grows and stabilizes on long-running agent deployments would test scalability outside the reported benchmarks.
Load-bearing premise
The performance difference observed when the executor runs with versus without retrieved experiences supplies a clean enough signal to train the copilot to select only helpful items across tasks and model sizes.
What would settle it
A controlled test in which the copilot's top-ranked experiences produce no gain or a consistent drop in executor success rate on held-out tasks would show the retrieval mechanism does not work as claimed.
Figures
read the original abstract
Large language model (LLM) agents have shown strong capabilities in reasoning, tool use, and multi-step interaction, but they often solve tasks from scratch and fail to reuse successful strategies or failure lessons from prior experience. Fine-tuning on collected experience can improve reuse, but it is inflexible when stronger or more suitable executors emerge. We propose ExpGraph, a model-agnostic experience learning framework that enables frozen and replaceable LLM executors to improve through external experience reuse without parameter updates. ExpGraph summarizes historical trajectories into reusable skills and failure lessons, organizes them as nodes in a self-evolving experience graph, and retrieves useful experiences through graph diffusion and utility-aware ranking. A lightweight retrieval copilot is trained with reinforcement learning using feedback that compares executor performance with and without retrieved experiences, while the graph is updated online from downstream task outcomes. We evaluate ExpGraph on ExpSuite, covering question answering, mathematical reasoning, code generation, and multi-step agentic environments including ALFWorld and AppWorld. ExpGraph improves over the strongest baseline by 12.2% and 4.7% on static tasks with smaller and larger executors, and by 21.4% and 12.7% in agentic environments, while reducing average interaction steps by 12.7% and 21.6%. Ablations show that graph-structured experience, utility-aware ranking, and adaptive retrieval jointly enable effective experience reuse across diverse tasks and executor models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ExpGraph, a model-agnostic framework for LLM agents that summarizes historical trajectories into reusable skills and failure lessons stored as nodes in a self-evolving experience graph. Experiences are retrieved via graph diffusion and utility-aware ranking; a lightweight retrieval copilot is trained with RL whose reward is the performance delta between executor runs with versus without retrieved experiences. The graph is updated online from task outcomes. On the ExpSuite benchmark (QA, math reasoning, code generation, ALFWorld, AppWorld), ExpGraph reports gains of 12.2%/4.7% over the strongest baseline on static tasks (smaller/larger executors) and 21.4%/12.7% on agentic tasks, plus reductions in interaction steps of 12.7%/21.6%. Ablations attribute gains to the graph structure, ranking, and adaptive retrieval.
Significance. If the quantitative claims hold under rigorous evaluation, the model-agnostic external-memory design would be a useful practical advance, allowing frozen or replaceable executors to benefit from accumulated experience without parameter updates. The combination of graph diffusion for retrieval and online graph evolution from downstream outcomes is a concrete strength that supports continuous adaptation across executor sizes and task types.
major comments (2)
- [Evaluation section] Evaluation section: the abstract states specific percentage improvements (12.2%, 4.7%, 21.4%, 12.7%) and step reductions but supplies no information on the number of runs per condition, standard deviations, statistical significance tests, or exact baseline implementations and data-exclusion rules. These omissions are load-bearing for the central performance claims.
- [Method section (retrieval copilot training)] Method section (retrieval copilot training): the RL reward is defined as the scalar performance difference between executor runs with and without retrieved graph experiences, yet the manuscript provides no description of variance-reduction steps (paired trials, multiple rollouts per experience, or baseline subtraction) or bias controls when the executor itself changes size or sampling behavior. This directly affects whether the reported gains can be attributed to the copilot rather than task stochasticity.
minor comments (1)
- [Abstract] The abstract refers to 'ExpSuite' and 'strongest baseline' without a citation or short description of task composition and baseline details; adding these would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on evaluation transparency and RL training details. We will revise the manuscript to address both points by adding the requested statistical and methodological information.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: the abstract states specific percentage improvements (12.2%, 4.7%, 21.4%, 12.7%) and step reductions but supplies no information on the number of runs per condition, standard deviations, statistical significance tests, or exact baseline implementations and data-exclusion rules. These omissions are load-bearing for the central performance claims.
Authors: We agree these reporting details are necessary to substantiate the performance claims. In the revised manuscript we will expand the Evaluation section (and appendix) to specify the number of runs per condition, include standard deviations, report statistical significance tests, provide precise baseline implementation details, and clarify any data-exclusion rules. revision: yes
-
Referee: [Method section (retrieval copilot training)] Method section (retrieval copilot training): the RL reward is defined as the scalar performance difference between executor runs with and without retrieved graph experiences, yet the manuscript provides no description of variance-reduction steps (paired trials, multiple rollouts per experience, or baseline subtraction) or bias controls when the executor itself changes size or sampling behavior. This directly affects whether the reported gains can be attributed to the copilot rather than task stochasticity.
Authors: We appreciate the referee noting this gap in the description. The revised Method section will explicitly describe our variance-reduction approach, which uses paired trials on identical task instances to compute the performance delta, multiple rollouts per condition, and baseline subtraction; it will also detail the normalization procedure applied when executor size or sampling behavior changes to mitigate bias. revision: yes
Circularity Check
No significant circularity; empirical gains measured on external benchmarks
full rationale
The paper's derivation chain consists of an external RL reward signal (performance delta between executor runs with/without retrieved experiences) and empirical evaluation on independent task suites (ExpSuite, ALFWorld, AppWorld). No equations or steps reduce a claimed prediction or result to a quantity defined inside the method itself. The reported improvements (12.2%/4.7% static, 21.4%/12.7% agentic) are obtained by direct comparison to external baselines rather than by construction from fitted parameters or self-citations. The framework therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
System card: Claude Opus 4 & Claude Sonnet 4
Anthropic. System card: Claude Opus 4 & Claude Sonnet 4. Technical report, Anthropic, May 2025
2025
-
[2]
Evaluating Large Language Models Trained on Code
Mark Chen. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models.arXiv preprint arXiv:2401.01335, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv:1803.05457v1, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Training verifiers to solve math word problems.CoRR, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.CoRR, 2021
2021
-
[7]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Gemini 3.1 Flash-Lite model card
Google DeepMind. Gemini 3.1 Flash-Lite model card. Technical report, Google DeepMind, March 2026
2026
-
[9]
LightMem: Lightweight and Efficient Memory-Augmented Generation
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, et al. Lightmem: Lightweight and efficient memory- augmented generation.arXiv preprint arXiv:2510.18866, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Michael Alvarez
Pengrui Han, Rafal Kocielnik, Peiyang Song, Ramit Debnath, Dean Mobbs, Anima Anandkumar, and R. Michael Alvarez. The personality illusion: Revealing dissociation between self-reports & behavior in llms, 2025
2025
-
[13]
Pengrui Han, Xueqiang Xu, Keyang Xuan, Peiyang Song, Siru Ouyang, Runchu Tian, Yuqing Jiang, Cheng Qian, Pengcheng Jiang, Jiashuo Sun, et al. Steer2adapt: Dynamically composing steering vectors elicits efficient adaptation of llms.arXiv preprint arXiv:2602.07276, 2026
-
[14]
Webvoyager: Building an end-to-end web agent with large multimodal models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6864–6890, 2024
2024
-
[15]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021, 2021. 10
2021
-
[16]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021
2021
-
[17]
Discoveryworld: A virtual environment for developing and evaluating automated scientific discovery agents.Advances in Neural Information Processing Systems, 37:10088–10116, 2024
Peter Jansen, Marc-Alexandre Côté, Tushar Khot, Erin Bransom, Bhavana Dalvi Mishra, Bodhisattwa Prasad Majumder, Oyvind Tafjord, and Peter Clark. Discoveryworld: A virtual environment for developing and evaluating automated scientific discovery agents.Advances in Neural Information Processing Systems, 37:10088–10116, 2024
2024
-
[18]
Adaptation of agentic ai.arXiv preprint arXiv:2512.16301, 2025
Pengcheng Jiang, Jiacheng Lin, Zhiyi Shi, Zifeng Wang, Luxi He, Yichen Wu, Ming Zhong, Peiyang Song, Qizheng Zhang, Heng Wang, et al. Adaptation of agentic ai.arXiv preprint arXiv:2512.16301, 2025
-
[19]
s3: You don’t need that much data to train a search agent via rl
Pengcheng Jiang, Xueqiang Xu, Jiacheng Lin, Jinfeng Xiao, Zifeng Wang, Jimeng Sun, and Jiawei Han. s3: You don’t need that much data to train a search agent via rl. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 21610–21628, 2025
2025
-
[20]
Process reward models that think.arXiv preprint arXiv:2504.16828,
Muhammad Khalifa, Rishabh Agarwal, Lajanugen Logeswaran, Jaekyeom Kim, Hao Peng, Moontae Lee, Honglak Lee, and Lu Wang. Process reward models that think.arXiv preprint arXiv:2504.16828, 2025
-
[21]
Training Language Models to Self-Correct via Reinforcement Learning
Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, et al. Training language models to self-correct via reinforcement learning.arXiv preprint arXiv:2409.12917, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[23]
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models.arXiv preprint arXiv:2501.05366, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[25]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Advances in neural information processing systems, 36:21558–21572, 2023
2023
-
[27]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
On-policy distillation.Thinking Machines Lab: Connec- tionism, 2025
Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Connec- tionism, 2025. https://thinkingmachines.ai/blog/on-policy-distillation
2025
-
[30]
Qianli Ma, Haotian Zhou, Tingkai Liu, Jianbo Yuan, Pengfei Liu, Yang You, and Hongxia Yang. Let’s reward step by step: Step-level reward model as the navigators for reasoning.arXiv preprint arXiv:2310.10080, 2023
-
[31]
Can a suit of armor conduct electricity? A new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? A new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, pages 2381–2391. Association for Computational Linguistics, 2018. 11
2018
-
[32]
Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025, 2025
2025
-
[33]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[34]
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
Siru Ouyang, Jun Yan, I Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T Le, Samira Daruki, Xiangru Tang, et al. Reasoningbank: Scaling agent self-evolving with reasoning memory.arXiv preprint arXiv:2509.25140, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
WebCanvas: Benchmarking Web Agents in Online Environments
Yichen Pan, Dehan Kong, Sida Zhou, Cheng Cui, Yifei Leng, Bing Jiang, Hangyu Liu, Yanyi Shang, Shuyan Zhou, Tongshuang Wu, et al. Webcanvas: Benchmarking web agents in online environments.arXiv preprint arXiv:2406.12373, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Choice- mates: Supporting unfamiliar online decision-making with multi-agent conversational interac- tions
Jeongeon Park, Bryan Min, Kihoon Son, Jean Y Song, Xiaojuan Ma, and Juho Kim. Choice- mates: Supporting unfamiliar online decision-making with multi-agent conversational interac- tions. InProceedings of the 31st International Conference on Intelligent User Interfaces, pages 1526–1550, 2026
2026
-
[37]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[38]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
2024
-
[39]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
2023
-
[42]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[43]
Commonsenseqa: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (...
2019
-
[44]
Xiangru Tang, Tianyu Hu, Muyang Ye, Yanjun Shao, Xunjian Yin, Siru Ouyang, Wangchunshu Zhou, Pan Lu, Zhuosheng Zhang, Yilun Zhao, et al. Chemagent: Self-updating library in large language models improves chemical reasoning.arXiv preprint arXiv:2501.06590, 2025
-
[45]
Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 10014–10037, 2023. 12
2023
-
[46]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. Appworld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
2024
-
[47]
Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
2023
-
[48]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. arXiv preprint arXiv:2409.07429, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Browsecomp: A simple yet challenging benchmark for browsing agents, 2025
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents, 2025
2025
-
[50]
Zero-shot open-schema entity structure discovery
Xueqiang Xu, Jinfeng Xiao, James Barry, Mohab El-karef, Jiaru Zou, Pengcheng Jiang, Yunyi Zhang, Maxwell J Giammona, Geeth Mel, and Jiawei Han. Zero-shot open-schema entity structure discovery. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7547–7561, 2026
2026
-
[51]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
On-policy context distillation for language models, 2026
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models, 2026
2026
-
[54]
TextGrad: Automatic "Differentiation" via Text
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. Textgrad: Automatic" differentiation" via text.arXiv preprint arXiv:2406.07496, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory
Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, Zhuo Li, Yujie Zheng, Weinan Zhang, Ying Wen, Zhiyu Li, et al. Memrl: Self-evolving agents via runtime reinforcement learning on episodic memory.arXiv preprint arXiv:2601.03192, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Expel: Llm agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642, 2024
2024
-
[57]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. 13 Contents of Appendix A Limitations, Future Work, and Broader Impact 14 B Implementation Details 15 C Training Procedure ofExpGraph16 D Dataset Descriptions 1...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
go to {recep}
controls graph exploration scope and W (0-100) controls the trade-off between semantic similarity and historical utility. The search returns lessons learned from similar questions solved before (both successful strategies and common mistakes). You can search multiple times. When ready, provide ONLY the answer letter inside<answer>and</answer>. For example...
-
[60]
The general task category ( pick_and_place, heat_then_place, clean_then_place, cool_then_place,examine_in_light,pick_two)
-
[61]
The concrete step-by-step strategy that worked
-
[62]
soapbar is usually on countertop, bathtubbasin, or shelf
Common locations where target objects are found (e.g. “soapbar is usually on countertop, bathtubbasin, or shelf”) Be specific. Use actual object/location types (countertop,sinkbasin,microwave). Output format:SKILL: [your skill text] <|im_end|> Table 34:Prompt for ExpGraph extracting a memory item from a failed ALFWorld trajectory. <|im_start|> system You ...
-
[63]
The general task category
-
[64]
What specific mistake was made
-
[65]
transactions
What the agent should have done differently Output format:SKILL: [your lesson text] <|im_end|> 32 Table 35:Prompt for ExpGraph extracting a memory item from an AppWorld episode. {STA- TUS}is replaced bySUCCESSFUL,FAILED, orPARTIAL. <|im_start|> user Analyze this{STATUS}AppWorld code generation episode. Task:{task} Trajectory:{trajectory} Extract ONE conci...
-
[66]
Identify factual information that is relevant to the Current Search Query
Carefully review the content of each searched memory. Identify factual information that is relevant to the Current Search Query
-
[67]
quote” or “funny
Select the information that directly contributes to advancing the Previous Reasoning Steps. Ensure that the extracted information is accurate and relevant. Output Format: - If the memories provide helpful information: present the information beginning with **Final Information** **Final Information** [Helpful information] - If the memories do not provide h...
2026
-
[68]
Handle factor 2: whilenis even, divide by 2; track last factor
-
[69]
whilei 2 ≤n, divide out all copies ofi
Handle odd factors: fori= 3,5, . . .whilei 2 ≤n, divide out all copies ofi
-
[70]
open fridge 1→cool {X} with fridge 1
Ifn >1after the loop,nitself is the largest prime factor. Trace onlargest_prime_factor(15):15/3 = 5;5>1⇒return 5✓ Trace onlargest_prime_factor(27):27/3 = 9,9/3 = 3,3/3 = 1; last factor = 3✓ The cleanest implementation uses a running variableistarting at 2 and repeatedly dividesn. “‘python def largest_prime_factor(n: int) -> int: i = 2 while i * i <= n: if...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.