VolFill: Single-View Amodal 3D Scene Reconstruction with Volumetric Flow Matching
Pith reviewed 2026-06-28 23:08 UTC · model grok-4.3
The pith
VolFill generates complete 3D scene geometry from one RGB image by denoising volumetric latents conditioned on foundation-model priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
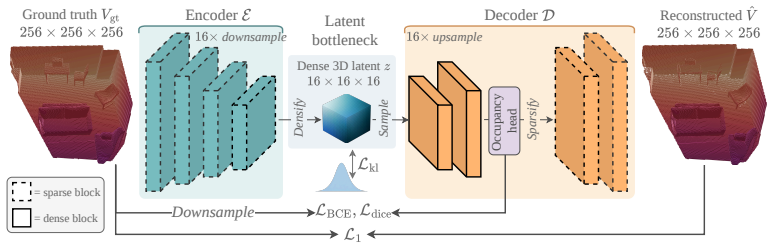
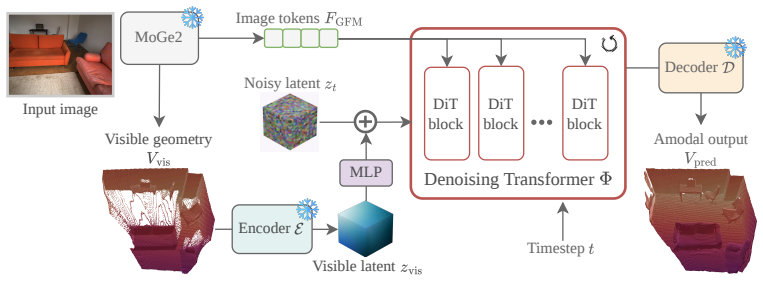
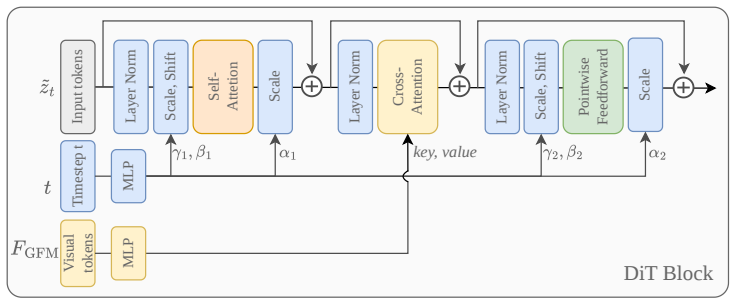
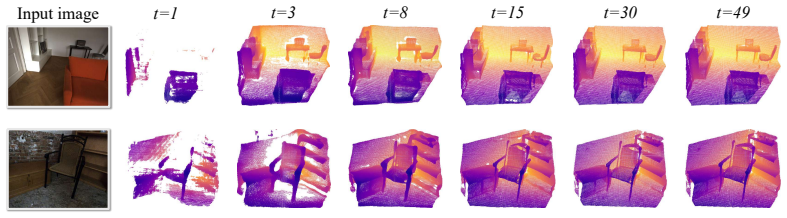
VolFill predicts the 3D structure of the complete scene from a single RGB image by first compressing truncated unsigned distance function grids into a latent space with a hybrid 3D VAE and then denoising that latent with a Diffusion Transformer conditioned on geometry foundation models, yielding a structured volumetric output that supports surface extraction and occupancy queries.
What carries the argument
Hybrid 3D VAE plus latent Diffusion Transformer that compresses and denoises truncated unsigned distance function grids while conditioned on geometry foundation models.
If this is right
- The output supports direct surface extraction and occupancy queries without additional per-ray or point-cloud processing.
- The method scales to full scenes rather than being limited to object-centric reconstruction.
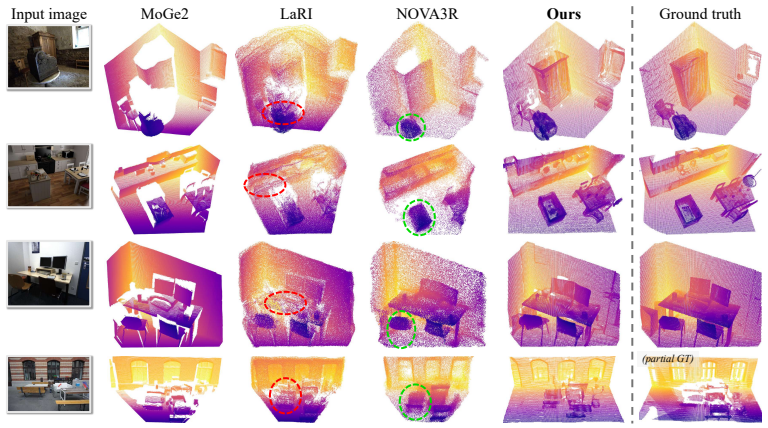
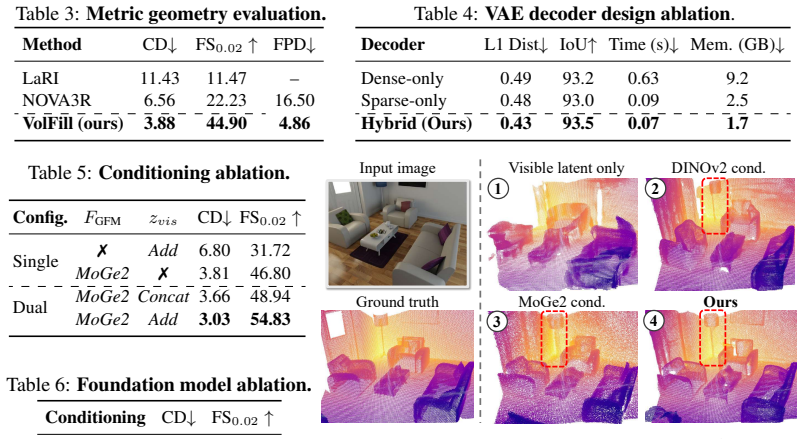
- Performance gains on SCRREAM and NRGB-D indicate better handling of amodal completion than regression-based baselines.
- The latent representation can be queried at arbitrary resolution after generation.
Where Pith is reading between the lines
- The same latent space could be conditioned on additional inputs such as depth or text descriptions without retraining the VAE.
- Real-time variants might be obtained by replacing the iterative denoising with a single forward pass through a distilled model.
- The approach could be tested on outdoor driving scenes where foundation-model priors are weaker than in indoor datasets.
Load-bearing premise
Geometry foundation models already contain sufficiently accurate spatial priors to let the model correctly infer hidden structures even when the input image supplies no visual evidence for them.
What would settle it
A test set of single-view scenes whose hidden geometry is known from ground-truth scans but whose layout contradicts the priors of current geometry foundation models; if VolFill still reconstructs the true hidden parts, the conditioning assumption holds, otherwise it fails.
Figures





read the original abstract
Reconstructing the complete geometry of a scene from a single RGB image remains challenging - especially when inferring hidden structures where visual evidence is incomplete. We introduce VolFill, a generative framework that predicts the 3D structure of the complete scene rather than relying on traditional pixel-aligned regression. Our method utilizes a hybrid 3D VAE to compress sparse truncated unsigned distance function grids into a compact latent space, paired with a latent Diffusion Transformer that denoises this representation to recover the complete scene. We condition the generation on geometry foundation models, leveraging rich spatial priors for robust reasoning. Unlike existing methods limited by per-ray constraints or unstructured point-cloud queries, VolFill provides a structured representation that supports direct surface extraction and occupancy queries at scale. Extensive experiments on the SCRREAM and NRGB-D datasets demonstrate that our approach significantly outperforms current baselines, providing a robust foundation for holistic spatial understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VolFill, a generative framework for single-view amodal 3D scene reconstruction. It employs a hybrid 3D VAE to compress sparse truncated unsigned distance function grids into a compact latent space, paired with a latent Diffusion Transformer that denoises this representation to recover the complete scene, conditioned on geometry foundation models. The method claims to provide a structured representation supporting direct surface extraction and occupancy queries, with extensive experiments on the SCRREAM and NRGB-D datasets demonstrating significant outperformance over current baselines.
Significance. If the outperformance claims hold with rigorous quantitative support, the work could advance amodal reconstruction by moving beyond per-ray or point-cloud limitations to a volumetric generative approach that leverages external geometry priors for hidden structure inference.
major comments (1)
- [Abstract] Abstract: the central claim that the method 'significantly outperforms current baselines' on SCRREAM and NRGB-D is asserted without any quantitative metrics, error analysis, baseline details, or experimental protocol, rendering the empirical contribution impossible to evaluate from the provided text.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'significantly outperforms current baselines' on SCRREAM and NRGB-D is asserted without any quantitative metrics, error analysis, baseline details, or experimental protocol, rendering the empirical contribution impossible to evaluate from the provided text.
Authors: We agree the abstract would be clearer with concrete numbers. In the revision we will add the key quantitative results (e.g., the reported improvements in surface and occupancy metrics on both datasets), name the primary baselines, and briefly note the evaluation protocol. Full tables, error analysis, and protocol details remain in the Experiments section. revision: yes
Circularity Check
No significant circularity detected; derivation is self-contained
full rationale
The abstract and available description present VolFill as a generative model using a hybrid 3D VAE for latent compression of truncated unsigned distance functions, a latent Diffusion Transformer for denoising, and conditioning on external geometry foundation models. Performance claims rest on empirical outperformance versus baselines on the independent public datasets SCRREAM and NRGB-D. No equations, fitted-parameter predictions, self-citations, or uniqueness theorems are supplied that would reduce any central result to its own inputs by construction. The approach is therefore evaluated against external benchmarks rather than internally forced.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Building normalizing flows with stochastic interpolants
Michael Samuel Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[2]
Neural rgb-d surface reconstruction
Dejan Azinovi´c, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, and Justus Thies. Neural rgb-d surface reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6290–6301, 2022
2022
-
[3]
Adabins: Depth estimation using adaptive bins
Shariq Farooq Bhat, Ibraheem Alhashim, and Peter Wonka. Adabins: Depth estimation using adaptive bins. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4009–4018, 2021
2021
-
[4]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias Muller. Zoedepth: Zero-shot transfer by combining relative and metric depth.ArXiv, abs/2302.12288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Aleksei Bochkovskii, AmaÃcGl Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second.arXiv preprint arXiv:2410.02073, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Monoscene: Monocular 3d semantic scene completion
Anh-Quan Cao and Raoul de Charette. Monoscene: Monocular 3d semantic scene completion. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3981–3991, 2021
2022
-
[7]
Occany: Generalized unconstrained urban 3d occupancy
Anh-Quan Cao and Tuan-Hung Vu. Occany: Generalized unconstrained urban 3d occupancy. InCVPR, 2026
2026
-
[8]
Jiahao Chang, Chongjie Ye, Yushuang Wu, Yuantao Chen, Yidan Zhang, Zhongjin Luo, Chenghong Li, Yihao Zhi, and Xiaoguang Han. Reconviagen: Towards accurate multi-view 3d object reconstruction via generation.arXiv preprint arXiv:2510.23306, 2025
-
[9]
Single-stage diffusion nerf: A unified approach to 3d generation and reconstruction.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 2416–2425, 2023
Hansheng Chen, Jiatao Gu, Anpei Chen, Wei Tian, Zhuowen Tu, Lingjie Liu, and Haoran Su. Single-stage diffusion nerf: A unified approach to 3d generation and reconstruction.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 2416–2425, 2023
2023
-
[10]
Reconstruct, inpaint, test-time finetune: Dynamic novel-view synthesis from monocular videos
Kaihua Chen, Tarasha Khurana, and Deva Ramanan. Reconstruct, inpaint, test-time finetune: Dynamic novel-view synthesis from monocular videos. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[11]
Nova3r: Non-pixel-aligned visual transformer for amodal 3d reconstruction
Weirong Chen, Chuanxia Zheng, Ganlin Zhang, Andrea Vedaldi, and Daniel Cremers. Nova3r: Non-pixel-aligned visual transformer for amodal 3d reconstruction. InThe F ourteenth Interna- tional Conference on Learning Representations, 2026
2026
-
[12]
Tulyakov, Alexander G
Yen-Chi Cheng, Hsin-Ying Lee, S. Tulyakov, Alexander G. Schwing, and Liangyan Gui. Sdfusion: Multimodal 3d shape completion, reconstruction, and generation.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4456–4465, 2022
2023
-
[13]
4d spatio-temporal convnets: Minkowski convolutional neural networks
Christopher Choy, JunYoung Gwak, and Silvio Savarese. 4d spatio-temporal convnets: Minkowski convolutional neural networks. InProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition, pages 3075–3084, 2019
2019
-
[14]
Spconv: Spatially sparse convolution library
Spconv Contributors. Spconv: Spatially sparse convolution library. https://github.com/ traveller59/spconv, 2022
2022
-
[15]
Depth map prediction from a single image using a multi-scale deep network.Advances in neural information processing systems, 27, 2014
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network.Advances in neural information processing systems, 27, 2014
2014
-
[16]
Dens3r: A foundation model for 3d geometry prediction.arXiv preprint arXiv:2507.16290,
Xianze Fang, Jingnan Gao, Zhe Wang, Zhuo Chen, Xingyu Ren, Jiangjing Lyu, Qiaomu Ren, Zhonglei Yang, Xiaokang Yang, Yichao Yan, and Chengfei Lyu. Dens3r: A foundation model for 3d geometry prediction.ArXiv, abs/2507.16290, 2025. 11
-
[17]
3d-front: 3d furnished rooms with layouts and semantics.2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 10913–10922, 2020
Huan Fu, Bowen Cai, Lin Gao, Ling-Xiao Zhang, Cao Li, Zengqi Xun, Chengyue Sun, Yiyun Fei, Yu qiong Zheng, Ying Li, Yi Liu, Peng Liu, Lin Ma, Le Weng, Xiaohang Hu, Xin Ma, Qian Qian, Rongfei Jia, Binqiang Zhao, and Hao Helen Zhang. 3d-front: 3d furnished rooms with layouts and semantics.2021 IEEE/CVF International Conference on Computer Vision (ICCV), pag...
2021
-
[18]
Deep ordinal regression network for monocular depth estimation
Huan Fu, Mingming Gong, Chaohui Wang, Kayhan Batmanghelich, and Dacheng Tao. Deep ordinal regression network for monocular depth estimation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2002–2011, 2018
2002
-
[19]
Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image
Xiao Fu, Wei Yin, Mu Hu, Kaixuan Wang, Yuexin Ma, Ping Tan, Shaojie Shen, Dahua Lin, and Xiaoxiao Long. Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image. InEuropean Conference on Computer Vision, pages 241–258. Springer, 2024
2024
-
[20]
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul P. Srinivasan, Jonathan T. Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models.ArXiv, abs/2405.10314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Fine-tuning image-conditional diffusion models is easier than you think
Gonzalo Martin Garcia, Karim Abou Zeid, Christian Schmidt, Daan De Geus, Alexander Hermans, and Bastian Leibe. Fine-tuning image-conditional diffusion models is easier than you think. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 753–762. IEEE, 2025
2025
-
[22]
Submanifold Sparse Convolutional Networks
Benjamin Graham and Laurens van der Maaten. Submanifold sparse convolutional networks. ArXiv, abs/1706.01307, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Benoît Guillard, Federico Stella, and P. Fua. Meshudf: Fast and differentiable meshing of unsigned distance field networks. InEuropean Conference on Computer Vision, 2021
2021
-
[24]
Towards zero-shot scale-aware monocular depth estimation.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9199–9209, 2023
Vitor Campanholo Guizilini, Igor Vasiljevic, Di Chen, Rares Ambrus, and Adrien Gaidon. Towards zero-shot scale-aware monocular depth estimation.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9199–9209, 2023
2023
-
[25]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.ArXiv, abs/2404.02101, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Jing He, Haodong Li, Wei Yin, Yixun Liang, Leheng Li, Kaiqiang Zhou, Hongbo Zhang, Bingbing Liu, and Ying-Cong Chen. Lotus: Diffusion-based visual foundation model for high-quality dense prediction.arXiv preprint arXiv:2409.18124, 2024
-
[27]
Gaussian error linear units (gelus).arXiv: Learning, 2016
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv: Learning, 2016
2016
-
[28]
Query-key normalization for transformers
Alex Henry, Prudhvi Raj Dachapally, Shubham Vivek Pawar, and Yuxuan Chen. Query-key normalization for transformers. InFindings, 2020
2020
-
[29]
Recovering surface layout from an image
Derek Hoiem, Alexei A Efros, and Martial Hebert. Recovering surface layout from an image. International Journal of Computer Vision, 75(1):151–172, 2007
2007
-
[30]
LRM: Large Reconstruction Model for Single Image to 3D
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. Lrm: Large reconstruction model for single image to 3d. ArXiv, abs/2311.04400, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10579–10596, 2024
2024
-
[32]
Repurposing geometric foundation models for multi-view diffusion
Wooseok Jang, Seonghu Jeon, Jisang Han, Jinhyeok Choi, Minkyung Kwon, Seungryong Kim, Saining Xie, and Sainan Liu. Repurposing geometric foundation models for multi-view diffusion. 2026. 12
2026
-
[33]
Hyunjun Jung, Weihang Li, Shun cheng Wu, William Bittner, Nikolas Brasch, Jifei Song, Eduardo P’erez-Pellitero, Zhensong Zhang, Arthur Moreau, Nassir Navab, and Benjamin Busam. Scrream : Scan, register, render and map:a framework for annotating accurate and dense 3d indoor scenes with a benchmark.ArXiv, abs/2410.22715, 2024
-
[34]
Depth Transfer: Depth Extraction from Video Us- ing Non-Parametric Sampling .IEEE Transactions on Pattern Analysis & Machine Intelligence, 36(11):2144–2158, November 2014
Kevin Karsch, Ce Liu, and Sing Bing Kang. Depth Transfer: Depth Extraction from Video Us- ing Non-Parametric Sampling .IEEE Transactions on Pattern Analysis & Machine Intelligence, 36(11):2144–2158, November 2014
2014
-
[35]
Kazhdan, Matthew Bolitho, and Hugues Hoppe
Michael M. Kazhdan, Matthew Bolitho, and Hugues Hoppe. Poisson surface reconstruction. InEurographics Symposium on Geometry Processing, 2006
2006
-
[36]
Repurposing diffusion-based image generators for monocular depth estima- tion
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Konrad Schindler. Repurposing diffusion-based image generators for monocular depth estima- tion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9492–9502, 2024
2024
-
[37]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, Jonathon Luiten, Manuel López-Antequera, Samuel Rota Bulò, Christian Richardt, Deva Ramanan, Sebastian Scherer, and Peter Kontschieder. Mapanything: Universal feed-forward metric 3d reconstruc- tion.Ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023
2023
-
[39]
Jin Han Lee, Myung-Kyu Han, Dong Wook Ko, and Il Hong Suh. From big to small: Multi- scale local planar guidance for monocular depth estimation.arXiv preprint arXiv:1907.10326, 2019
-
[40]
Jiahao Li, Hao Tan, Kai Zhang, Zexiang Xu, Fujun Luan, Yinghao Xu, Yicong Hong, Kalyan Sunkavalli, Greg Shakhnarovich, and Sai Bi. Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model.ArXiv, abs/2311.06214, 2023
-
[41]
LaRI: Layered Ray Intersections for Single-view 3D Geometric Reasoning
Rui Li, Biao Zhang, Zhenyu Li, Federico Tombari, and Peter Wonka. Lari: Layered ray intersections for single-view 3d geometric reasoning.ArXiv, abs/2504.18424, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models.IEEE transactions on pattern analysis and machine intelligence, PP, 2025
Yangguang Li, Zi-Xin Zou, Zexiang Liu, Dehui Wang, Yuanzhi Liang, Zhipeng Yu, Xingchao Liu, Yuanchen Guo, Ding Liang, Wanli Ouyang, and Yan-Pei Cao. Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models.IEEE transactions on pattern analysis and machine intelligence, PP, 2025
2025
-
[43]
V oxformer: Sparse voxel transformer for camera-based 3d semantic scene completion.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9087–9098, 2023
Yiming Li, Zhiding Yu, Christopher Bongsoo Choy, Chaowei Xiao, José Manuel Álvarez, Sanja Fidler, Chen Feng, and Anima Anandkumar. V oxformer: Sparse voxel transformer for camera-based 3d semantic scene completion.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9087–9098, 2023
2023
-
[44]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.ArXiv, abs/2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.ArXiv, abs/2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[46]
Zero-1-to-3: Zero-shot one image to 3d object.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9264–9275, 2023
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9264–9275, 2023
2023
-
[47]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.ArXiv, abs/2209.03003, 2022. 13
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
SyncDreamer: Generating Multiview-consistent Images from a Single-view Image
Yuan Liu, Chu-Hsing Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. Syncdreamer: Generating multiview-consistent images from a single-view image.ArXiv, abs/2309.03453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Neural volumes: Learning dynamic renderable volumes from images.ACM Trans
Stephen Lombardi, Tomas Simon, Jason Saragih, Gabriel Schwartz, Andreas Lehrmann, and Yaser Sheikh. Neural volumes: Learning dynamic renderable volumes from images.ACM Trans. Graph., 38(4):65:1–65:14, July 2019
2019
-
[50]
Wonder3d: Single image to 3d using cross-domain diffusion.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9970–9980, 2023
Xiaoxiao Long, Yuanchen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, and Wenping Wang. Wonder3d: Single image to 3d using cross-domain diffusion.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9970–9980, 2023
2024
-
[51]
Seen2scene: Completing realistic 3d scenes with visibility-guided flow, 2026
Quan Meng, Yujin Chen, Lei Li, Matthias Nießner, and Angela Dai. Seen2scene: Completing realistic 3d scenes with visibility-guided flow, 2026
2026
-
[52]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
2021
-
[53]
Diffrf: Rendering-guided 3d radiance field diffusion.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4328–4338, 2022
Norman Muller, Yawar Siddiqui, Lorenzo Porzi, Samuel Rota Bulò, Peter Kontschieder, and Matthias Nießner. Diffrf: Rendering-guided 3d radiance field diffusion.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4328–4338, 2022
2023
-
[54]
Dage: Dual-stream architecture for efficient and fine-grained geometry estimation
Tuan Duc Ngo, Jiahui Huang, Seoung Wug Oh, Kevin Blackburn-Matzen, Evangelos Kaloger- akis, Chuang Gan, and Joon-Young Lee. Dage: Dual-stream architecture for efficient and fine-grained geometry estimation. InCVPR, 2026
2026
-
[55]
Point-E: A System for Generating 3D Point Clouds from Complex Prompts
Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, and Mark Chen. Point-e: A system for generating 3d point clouds from complex prompts.ArXiv, abs/2212.08751, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[56]
Mescheder, Michael Oechsle, and Andreas Geiger
Michael Niemeyer, Lars M. Mescheder, Michael Oechsle, and Andreas Geiger. Differentiable volumetric rendering: Learning implicit 3d representations without 3d supervision.2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3501– 3512, 2019
2020
-
[57]
Peebles and Saining Xie
William S. Peebles and Saining Xie. Scalable diffusion models with transformers.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 4172–4182, 2022
2023
-
[58]
Sharpdepth: Sharpening metric depth predictions using diffusion distillation
Duc-Hai Pham, Tung Do, Phong Nguyen, Binh-Son Hua, Khoi Nguyen, and Rang Nguyen. Sharpdepth: Sharpening metric depth predictions using diffusion distillation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17060–17069, 2025
2025
-
[59]
Unidepth: Universal monocular metric depth estimation.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10106–10116, 2024
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc van Gool, and Fisher Yu. Unidepth: Universal monocular metric depth estimation.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10106–10116, 2024
2024
-
[60]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020
2020
-
[62]
Xcube: Large-scale 3d generative modeling using sparse voxel hierarchies.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4209–4219, 2023
Xuanchi Ren, Jiahui Huang, Xiaohui Zeng, Ken Museth, Sanja Fidler, and Francis Williams. Xcube: Large-scale 3d generative modeling using sparse voxel hierarchies.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4209–4219, 2023
2024
-
[63]
Gen3c: 3d-informed world- consistent video generation with precise camera control.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6121–6132, 2025
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Muller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world- consistent video generation with precise camera control.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6121–6132, 2025. 14
2025
-
[64]
Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer
Robin Rombach, A. Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10674–10685, 2021
2022
-
[65]
High-resolution image synthesis with latent diffusion models, 2021
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models, 2021
2021
-
[66]
Learning depth from single monocular images.Advances in neural information processing systems, 18, 2005
Ashutosh Saxena, Sung Chung, and Andrew Ng. Learning depth from single monocular images.Advances in neural information processing systems, 18, 2005
2005
-
[67]
Make3d: Learning 3d scene structure from a single still image.IEEE transactions on pattern analysis and machine intelligence, 31(5):824– 840, 2008
Ashutosh Saxena, Min Sun, and Andrew Y Ng. Make3d: Learning 3d scene structure from a single still image.IEEE transactions on pattern analysis and machine intelligence, 31(5):824– 840, 2008
2008
-
[68]
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and X. Yang. Mvdream: Multi-view diffusion for 3d generation.ArXiv, abs/2308.16512, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[69]
Implicit neural representations with periodic activation functions.Advances in neural informa- tion processing systems, 33:7462–7473, 2020
Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions.Advances in neural informa- tion processing systems, 33:7462–7473, 2020
2020
-
[70]
Chang, Manolis Savva, and Thomas A
Shuran Song, Fisher Yu, Andy Zeng, Angel X. Chang, Manolis Savva, and Thomas A. Funkhouser. Semantic scene completion from a single depth image.2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 190–198, 2016
2017
-
[71]
TorchSparse: Efficient Point Cloud Inference Engine
Haotian Tang, Zhijian Liu, Xiuyu Li, Yujun Lin, and Song Han. TorchSparse: Efficient Point Cloud Inference Engine. InConference on Machine Learning and Systems (MLSys), 2022
2022
-
[72]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view gaussian model for high-resolution 3d content creation. InEuropean Conference on Computer Vision, 2024
2024
-
[73]
Hunyuan3d 1.0: A unified framework for text-to-3d and image-to- 3d generation, 2024
Tencent Hunyuan3D Team. Hunyuan3d 1.0: A unified framework for text-to-3d and image-to- 3d generation, 2024
2024
-
[74]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeural Information Processing Systems, 2017
2017
-
[75]
Learning depth from monocular videos using direct methods
Chaoyang Wang, José Miguel Buenaposada, Rui Zhu, and Simon Lucey. Learning depth from monocular videos using direct methods. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2022–2030, 2018
2022
-
[76]
4real- video: Learning generalizable photo-realistic 4d video diffusion.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17723–17732, 2024
Chaoyang Wang, Peiye Zhuang, Tuan Duc Ngo, Willi Menapace, Aliaksandr Siarohin, Michael Vasilkovsky, Ivan Skorokhodov, Sergey Tulyakov, Peter Wonka, and Hsin-Ying Lee. 4real- video: Learning generalizable photo-realistic 4d video diffusion.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17723–17732, 2024
2025
-
[77]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[78]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5261–5271, 2025
2025
-
[79]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details.arXiv preprint arXiv:2507.02546, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20697–20709, 2024. 15
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.