CoCoVideo: The High-Quality Commercial-Model-Based Contrastive Benchmark for AI-Generated Video Detection
Pith reviewed 2026-06-29 18:22 UTC · model grok-4.3
The pith
A dataset of 26K watermark-free commercial AI video pairs enables a hybrid detector that outperforms prior methods on realistic forgeries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
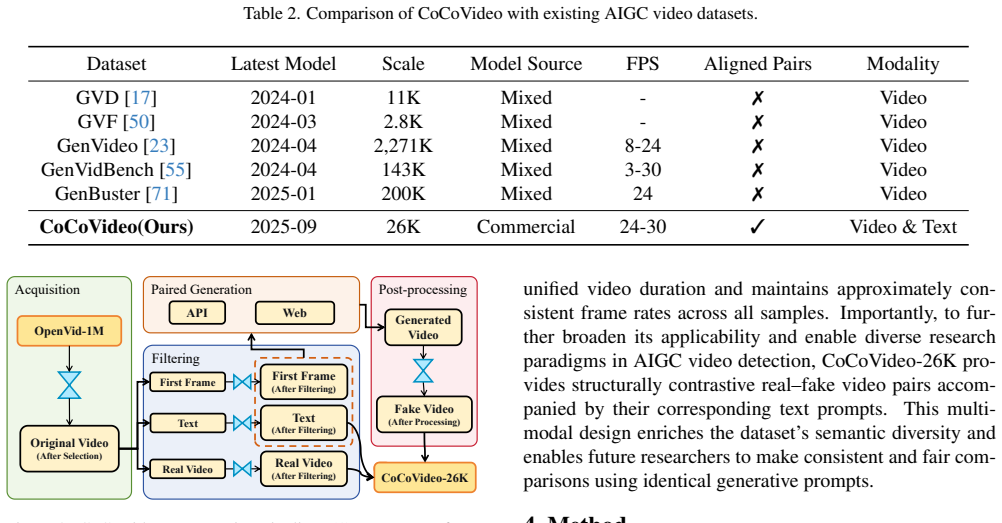
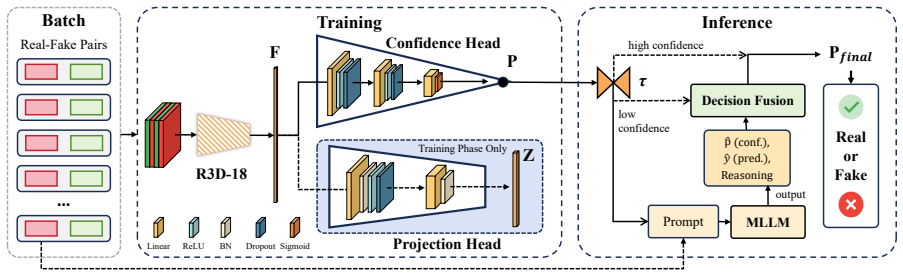
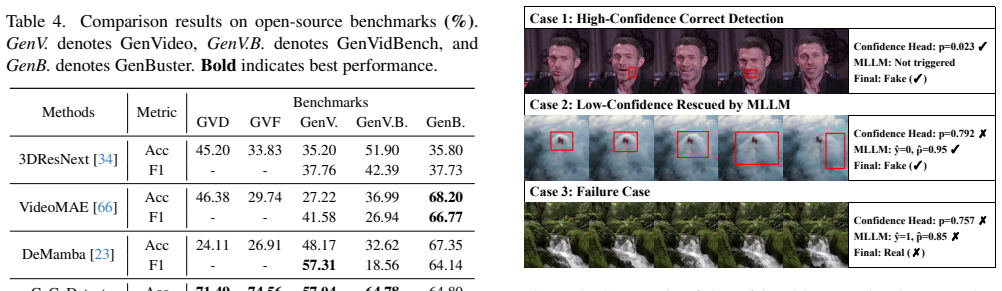
The paper establishes CoCoVideo-26K as a contrastive benchmark of high-quality commercial AIGC videos paired with real footage across 13 generators, and introduces CoCoDetect, which combines contrastive learning on an R3D-18 backbone with confidence-gated MLLM inference to achieve superior detection of high-fidelity video forgeries.
What carries the argument
The confidence gate that routes uncertain R3D-18 predictions to multimodal large language model reasoning on physical plausibility and scene consistency.
If this is right
- Detection systems can generalize more reliably to current commercial AIGC outputs.
- Future video forgery benchmarks will need to prioritize commercial generators to stay relevant.
- The hybrid CNN-plus-MLLM routing strategy can extend to detection tasks in other media types.
- Improved performance on realistic pairs raises the practical threshold for public video trust.
Where Pith is reading between the lines
- The dataset may expose generator-specific artifacts absent from open-source models.
- MLLM reasoning could help flag forgeries from future generators not seen during training.
- Similar contrastive pairing methods could be applied to create benchmarks for image or audio generation.
Load-bearing premise
Commercial video samples without watermarks represent the authentic high-fidelity forgeries that detection systems must handle in practice.
What would settle it
A controlled test in which models trained on CoCoVideo-26K show no accuracy gain over prior-dataset baselines when evaluated on new, unseen videos from the same commercial generators.
Figures





read the original abstract
With the rapid advancement of artificial intelligence generated content (AIGC) technologies, video forgery has become increasingly prevalent, posing new challenges to public discourse and societal security. Despite remarkable progress in existing deepfake detection methods, AIGC forgery detection remains challenging, as existing datasets mainly rely on open-source video generation models with quality far below that of commercial AIGC systems. Even datasets containing a few commercial samples often retain visible watermarks, compromising authenticity and hindering model generalization to high-fidelity AIGC videos. To address these issues, we introduce CoCoVideo-26K, a contrastive, commercial-model-based AIGC video dataset covering 13 mainstream commercial generators and providing semantically aligned real-fake video pairs. This dataset enables deeper exploration of the differences between authentic and high-quality synthetic videos and establishes a new benchmark for highly realistic video forgery detection. Building on this dataset, we propose CoCoDetect, a detection framework integrating contrastive learning with confidence-gated multimodal large language model (MLLM) inference. An R3D-18 backbone extracts spatio-temporal representations, while a confidence gate routes uncertain cases to an MLLM for reasoning about physical plausibility and scene consistency. Extensive experiments on CoCoVideo-26K and public benchmarks demonstrate state-of-the-art performance, validating the framework's robustness and generalizability. Our code and dataset are available at https://github.com/DonoToT/CoCoVideo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoCoVideo-26K, a contrastive dataset of 26K semantically aligned real-fake video pairs from 13 commercial AIGC generators without visible watermarks, to overcome limitations of prior datasets based on lower-quality open-source models. It proposes CoCoDetect, which combines contrastive learning via an R3D-18 backbone with a confidence-gated MLLM for physical-plausibility reasoning on uncertain cases, and reports state-of-the-art detection performance on CoCoVideo-26K and public benchmarks.
Significance. If the central claims hold, the work supplies a higher-fidelity benchmark that could improve generalization of AIGC video detectors to commercial systems and demonstrates a hybrid contrastive-MLLM architecture that may handle edge cases more reliably than purely visual models.
major comments (2)
- [Introduction and §3] Introduction and §3 (Dataset Construction): the claim that commercial-model samples without watermarks supply materially higher-fidelity examples than open-source generators is load-bearing for both the benchmark value and the reported generalization gains, yet the manuscript supplies neither an acquisition protocol, a watermark-removal procedure, nor quantitative fidelity comparisons (e.g., perceptual metrics, artifact histograms, or cross-generator FID scores) to substantiate the superiority.
- [§4 and §5] §4 (CoCoDetect) and §5 (Experiments): the abstract and experimental claims of SOTA performance and robustness rest on the premise that CoCoVideo-26K pairs are unbiased; without the missing fidelity validation, any reported gains on CoCoVideo-26K cannot be confidently attributed to the framework rather than dataset-specific cues.
minor comments (2)
- [Abstract] The abstract states that code and dataset are available at a GitHub link, but the manuscript does not include a data-card or license statement detailing commercial-video usage rights.
- [§4] Notation for the confidence gate and MLLM routing threshold is introduced without an explicit equation or pseudocode block, making the inference procedure harder to reproduce from the text alone.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which highlight important aspects for strengthening the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Introduction and §3] Introduction and §3 (Dataset Construction): the claim that commercial-model samples without watermarks supply materially higher-fidelity examples than open-source generators is load-bearing for both the benchmark value and the reported generalization gains, yet the manuscript supplies neither an acquisition protocol, a watermark-removal procedure, nor quantitative fidelity comparisons (e.g., perceptual metrics, artifact histograms, or cross-generator FID scores) to substantiate the superiority.
Authors: We agree that the manuscript would be strengthened by including these details. In the revision, we will expand §3 to provide the acquisition protocol for sourcing videos from the 13 commercial AIGC generators, including steps taken to ensure no visible watermarks are present. We will also incorporate quantitative fidelity comparisons using perceptual metrics, artifact analysis, and cross-generator FID scores to support the claim of higher fidelity. revision: yes
-
Referee: [§4 and §5] §4 (CoCoDetect) and §5 (Experiments): the abstract and experimental claims of SOTA performance and robustness rest on the premise that CoCoVideo-26K pairs are unbiased; without the missing fidelity validation, any reported gains on CoCoVideo-26K cannot be confidently attributed to the framework rather than dataset-specific cues.
Authors: We acknowledge this point. While the SOTA results on public benchmarks provide independent validation of the framework, we agree that additional fidelity validation for CoCoVideo-26K is necessary to confidently attribute gains on this dataset. The revisions to §3 will include the requested comparisons, which will be referenced in §5 to demonstrate that performance improvements stem from the contrastive-MLLM approach rather than dataset biases. We will also add discussion on the unbiased nature of the pairs. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces a new dataset (CoCoVideo-26K) based on commercial generators and a detection framework (CoCoDetect) using standard R3D-18 contrastive learning plus gated MLLM inference. No equations, fitted parameters, or derivations appear in the provided text. Claims about commercial-model superiority are presented as motivating assumptions rather than derived results, with no self-citation chains, self-definitional loops, or renamed known results that reduce the central claims to inputs by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Commercial AIGC systems produce videos of substantially higher quality than open-source generators, and watermark-free commercial samples represent authentic high-fidelity forgeries.
Reference graph
Works this paper leans on
-
[1]
Ai model & api providers analysis.https : / / artificialanalysis.ai/. 3
-
[2]
Hailuo ai.https://hailuoai.video/. 2, 3
-
[3]
Jimeng ai.https://jimeng.jianying.com/. 3
-
[4]
Kling ai.https://app.klingai.com/. 3
-
[5]
Luma ai.https://lumalabs.ai/. 3
-
[6]
Midjourney.https://www.midjourney.com/. 3
-
[7]
Pika.https://pika.art/. 3
-
[8]
Pixverse.https://app.pixverse.ai/. 3
-
[9]
Runway.https://app.runwayml.com/. 3
-
[10]
Seedance 1.0 official api.https://www.byteplus. com/. 3
-
[11]
Sora.https://sora.chatgpt.com/. 3
-
[12]
Veo 3.https://aistudio.google.com/models/ veo-3. 3
-
[13]
Vidu ai.https://www.vidu.com/. 3
-
[14]
Vivago ai.https://vivago.ai/. 2, 3
-
[15]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Ai-generated video detection via spatial-temporal anomaly learning
Jianfa Bai, Man Lin, Gang Cao, and Zijie Lou. Ai-generated video detection via spatial-temporal anomaly learning. In Proceedings of the Chinese Conference on Pattern Recogni- tion and Computer Vision, pages 460–470. Springer, 2024. 2, 4, 7
2024
-
[18]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
A deep learning approach to universal image manipulation detection using a new convolutional layer
Belhassen Bayar and Matthew C Stamm. A deep learning approach to universal image manipulation detection using a new convolutional layer. InProceedings of the 4th ACM workshop on information hiding and multimedia security, pages 5–10, 2016. 1
2016
-
[20]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luh- man, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024. 2
2024
-
[22]
Deepfake: Creation, purpose, risks
Angela Busacca and Melchiorre Alberto Monaca. Deepfake: Creation, purpose, risks. InInnovations and economic and social changes due to artificial intelligence: the state of the art, pages 55–68. Springer, 2023. 1
2023
-
[23]
Haoxing Chen, Yan Hong, Zizheng Huang, Zhuoer Xu, Zhangxuan Gu, Yaohui Li, Jun Lan, Huijia Zhu, Jianfu Zhang, Weiqiang Wang, et al. Demamba: Ai-generated video detection on million-scale genvideo benchmark.arXiv preprint arXiv:2405.19707, 2024. 2, 3, 4, 6, 7, 8
-
[24]
How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.Science China Information Sciences, 67(12):220101,
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhang- wei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.Science China Information Sciences, 67(12):220101,
-
[25]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024. 3
2024
-
[26]
Xception: Deep learning with depthwise separable convolutions
Franc ¸ois Chollet. Xception: Deep learning with depthwise separable convolutions. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 1251–1258, 2017. 3
2017
-
[27]
Faceswapdevs, 2019.https://github
Deepfakes. Faceswapdevs, 2019.https://github. com/deepfakes/faceswap. 1, 2
2019
-
[28]
The deepfake detection challenge (dfdc) dataset, 2020
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, and Cristian Canton Ferrer. The deepfake detection challenge (dfdc) dataset, 2020. 2
2020
-
[29]
Fake-gpt: Detecting fake image via large language model
Yuming Fan, Dongming Yang, Jiguang Zhang, Bang Yang, and Yuexian Zou. Fake-gpt: Detecting fake image via large language model. InChinese Conference on Pattern Recogni- tion and Computer Vision (PRCV), pages 122–136. Springer,
-
[30]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014. 1
2014
-
[31]
Face forgery video detection via temporal forgery cue unraveling
Zonghui Guo, Yingjie Liu, Jie Zhang, Haiyong Zheng, and Shiguang Shan. Face forgery video detection via temporal forgery cue unraveling. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 7396–7405,
-
[32]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Learn- ing spatio-temporal features with 3d residual networks for action recognition
Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. Learn- ing spatio-temporal features with 3d residual networks for action recognition. InProceedings of the IEEE international conference on computer vision workshops, pages 3154– 3160, 2017. 4
2017
-
[34]
Can spatiotemporal 3d cnns retrace the history of 2d cnns and im- agenet? InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 6546–6555, 2018
Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. Can spatiotemporal 3d cnns retrace the history of 2d cnns and im- agenet? InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 6546–6555, 2018. 6, 7, 8
2018
-
[35]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 2, 4
2016
-
[36]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 2
2020
-
[37]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Sida: Social media image deepfake detection, localization and explanation with large multimodal model
Zhenglin Huang, Jinwei Hu, Xiangtai Li, Yiwei He, Xingyu Zhao, Bei Peng, Baoyuan Wu, Xiaowei Huang, and Guan- gliang Cheng. Sida: Social media image deepfake detection, localization and explanation with large multimodal model. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 28831–28841, 2025. 3
2025
-
[39]
Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Freqdebias: Towards generalizable deepfake de- tection via consistency-driven frequency debiasing
Hossein Kashiani, Niloufar Alipour Talemi, and Fatemeh Afghah. Freqdebias: Towards generalizable deepfake de- tection via consistency-driven frequency debiasing. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8775–8785. IEEE, 2025. 1, 2
2025
-
[41]
Text2video-zero: Text- to-image diffusion models are zero-shot video generators
Levon Khachatryan, Andranik Movsisyan, Vahram Tade- vosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text- to-image diffusion models are zero-shot video generators. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15954–15964, 2023. 2
2023
-
[42]
Beyond spatial frequency: Pixel-wise temporal frequency- based deepfake video detection
Taehoon Kim, Jongwook Choi, Yonghyun Jeong, Haeun Noh, Jaejun Yoo, Seungryul Baek, and Jongwon Choi. Beyond spatial frequency: Pixel-wise temporal frequency- based deepfake video detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11198–11207, 2025. 1, 2
2025
-
[43]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Towards a universal synthetic video detector: From face or background manip- ulations to fully ai-generated content
Rohit Kundu, Hao Xiong, Vishal Mohanty, Athula Balachan- dran, and Amit K Roy-Chowdhury. Towards a universal synthetic video detector: From face or background manip- ulations to fully ai-generated content. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28050–28060, 2025. 3
2025
-
[45]
Gradient-based learning applied to document recog- nition.Proceedings of the IEEE, 86(11):2278–2324, 2002
Yann LeCun, L ´eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recog- nition.Proceedings of the IEEE, 86(11):2278–2324, 2002. 1
2002
-
[46]
Celeb-df: A large-scale challenging dataset for deep- fake forensics
Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. Celeb-df: A large-scale challenging dataset for deep- fake forensics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3207– 3216, 2020. 2
2020
-
[47]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 3
2023
-
[48]
Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024. 6
2024
-
[49]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision- language understanding.arXiv preprint arXiv:2403.05525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Decof: Generated video de- tection via frame consistency.arXiv preprint arXiv, 2402,
Long Ma, Jiajia Zhang, Hongping Deng, Ningyu Zhang, Yong Liao, and Haiyang Yu. Decof: Generated video de- tection via frame consistency.arXiv preprint arXiv, 2402,
-
[51]
Faceswap, 2018.https://github
MarekKowalski. Faceswap, 2018.https://github. com/MarekKowalski/FaceSwap. 1, 2
2018
-
[52]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhen- heng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to- video generation.arXiv preprint arXiv:2407.02371, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Laa-net: Localized artifact attention network for quality-agnostic and generalizable deepfake de- tection
Dat Nguyen, Nesryne Mejri, Inder Pal Singh, Polina Kuleshova, Marcella Astrid, Anis Kacem, Enjie Ghorbel, and Djamila Aouada. Laa-net: Localized artifact attention network for quality-agnostic and generalizable deepfake de- tection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17395– 17405, 2024. 1, 2
2024
-
[54]
Vulnerability-aware spatio-temporal learning for generalizable deepfake video detection
Dat Nguyen, Marcella Astrid, Anis Kacem, Enjie Ghorbel, and Djamila Aouada. Vulnerability-aware spatio-temporal learning for generalizable deepfake video detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10786–10796, 2025. 1, 2
2025
-
[55]
Zhenliang Ni, Qiangyu Yan, Mouxiao Huang, Tianning Yuan, Yehui Tang, Hailin Hu, Xinghao Chen, and Yunhe Wang. Genvidbench: A challenging benchmark for detecting ai-generated video.arXiv preprint arXiv:2501.11340, 2025. 2, 4, 7
-
[56]
Fsgan: Subject agnostic face swapping and reenactment
Yuval Nirkin, Yosi Keller, and Tal Hassner. Fsgan: Subject agnostic face swapping and reenactment. InProceedings of the IEEE/CVF international conference on computer vision, pages 7184–7193, 2019. 1
2019
-
[57]
Faceforen- sics++: Learning to detect manipulated facial images
Andreas R ¨ossler, Davide Cozzolino, Luisa Verdoliva, Chris- tian Riess, Justus Thies, and Matthias Nießner. Faceforen- sics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF international conference on computer vision, pages 1–11, 2019. 1, 2
2019
-
[58]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational confer- ence on machine learning, pages 2256–2265. pmlr, 2015. 2
2015
-
[59]
On learn- ing multi-modal forgery representation for diffusion gener- ated video detection.Advances in Neural Information Pro- cessing Systems, 37:122054–122077, 2024
Xiufeng Song, Xiao Guo, Jiache Zhang, Qirui Li, Lei Bai, Xiaoming Liu, Guangtao Zhai, and Xiaohong Liu. On learn- ing multi-modal forgery representation for diffusion gener- ated video detection.Advances in Neural Information Pro- cessing Systems, 37:122054–122077, 2024. 3
2024
-
[60]
Frequency-aware deepfake de- tection: Improving generalizability through frequency space domain learning
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. Frequency-aware deepfake de- tection: Improving generalizability through frequency space domain learning. InProceedings of the AAAI Conference on Artificial Intelligence, pages 5052–5060, 2024. 1, 2
2024
-
[61]
Rethinking the up-sampling op- erations in cnn-based generative network for generalizable deepfake detection
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. Rethinking the up-sampling op- erations in cnn-based generative network for generalizable deepfake detection. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 28130–28139, 2024. 2
2024
-
[62]
Efficientnet: Rethinking model scaling for convolutional neural networks
Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. InInternational conference on machine learning, pages 6105–6114. PMLR,
-
[63]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
Face2face: Real-time face capture and reenactment of rgb videos
Justus Thies, Michael Zollhofer, Marc Stamminger, Chris- tian Theobalt, and Matthias Nießner. Face2face: Real-time face capture and reenactment of rgb videos. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 2387–2395, 2016. 1, 2
2016
-
[65]
De- ferred neural rendering: Image synthesis using neural tex- tures.Acm Transactions on Graphics (TOG), 38(4):1–12,
Justus Thies, Michael Zollh ¨ofer, and Matthias Nießner. De- ferred neural rendering: Image synthesis using neural tex- tures.Acm Transactions on Graphics (TOG), 38(4):1–12,
-
[66]
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35:10078–10093, 2022
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35:10078–10093, 2022. 6, 7, 8
2022
-
[67]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
A closer look at spatiotemporal convolutions for action recognition
Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. InProceedings of the IEEE conference on Computer Vision and Pattern Recogni- tion, pages 6450–6459, 2018. 4
2018
-
[69]
Do deepfake videos undermine our epistemic trust? a thematic analysis of tweets that discuss deepfakes in the russian invasion of ukraine.Plos one, 18(10):e0291668, 2023
John Twomey, Didier Ching, Matthew Peter Aylett, Michael Quayle, Conor Linehan, and Gillian Murphy. Do deepfake videos undermine our epistemic trust? a thematic analysis of tweets that discuss deepfakes in the russian invasion of ukraine.Plos one, 18(10):e0291668, 2023. 1
2023
-
[70]
Dynamic graph learning with content-guided spatial- frequency relation reasoning for deepfake detection
Yuan Wang, Kun Yu, Chen Chen, Xiyuan Hu, and Silong Peng. Dynamic graph learning with content-guided spatial- frequency relation reasoning for deepfake detection. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7278–7287, 2023. 1, 2
2023
-
[71]
BusterX: MLLM-Powered AI-Generated Video Forgery Detection and Explanation
Haiquan Wen, Yiwei He, Zhenglin Huang, Tianxiao Li, Zi- han Yu, Xingru Huang, Lu Qi, Baoyuan Wu, Xiangtai Li, and Guangliang Cheng. Busterx: Mllm-powered ai-generated video forgery detection and explanation.arXiv preprint arXiv:2505.12620, 2025. 2, 3, 4, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Tall: Thumbnail layout for deepfake video detection
Yuting Xu, Jian Liang, Gengyun Jia, Ziming Yang, Yanhao Zhang, and Ran He. Tall: Thumbnail layout for deepfake video detection. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 22658–22668,
-
[73]
Zhipei Xu, Xuanyu Zhang, Runyi Li, Zecheng Tang, Qing Huang, and Jian Zhang. Fakeshield: Explainable image forgery detection and localization via multi-modal large lan- guage models.arXiv preprint arXiv:2410.02761, 2024. 3
-
[74]
Yi: Open Foundation Models by 01.AI
Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Guoyin Wang, Heng Li, Jiangcheng Zhu, Jianqun Chen, et al. Yi: Open foundation models by 01. ai. arXiv preprint arXiv:2403.04652, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[75]
Zhengqing Yuan, Yixin Liu, Yihan Cao, Weixiang Sun, Hao- long Jia, Ruoxi Chen, Zhaoxu Li, Bin Lin, Li Yuan, Lifang He, et al. Mora: Enabling generalist video generation via a multi-agent framework.arXiv preprint arXiv:2403.13248,
-
[76]
Learning natural consistency represen- tation for face forgery video detection
Daichi Zhang, Zihao Xiao, Shikun Li, Fanzhao Lin, Jianmin Li, and Shiming Ge. Learning natural consistency represen- tation for face forgery video detection. InEuropean Confer- ence on Computer Vision, pages 407–424. Springer, 2024. 1, 2
2024
-
[77]
Multi-attentional deep- fake detection
Hanqing Zhao, Wenbo Zhou, Dongdong Chen, Tianyi Wei, Weiming Zhang, and Nenghai Yu. Multi-attentional deep- fake detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2185– 2194, 2021. 1, 2
2021
-
[78]
D3: Training-free ai-generated video detection using second-order features
Chende Zheng, Ruiqi Suo, Chenhao Lin, Zhengyu Zhao, Le Yang, Shuai Liu, Minghui Yang, Cong Wang, and Chao Shen. D3: Training-free ai-generated video detection using second-order features. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 12852– 12862, 2025. 6, 7
2025
-
[79]
Exploring temporal coherence for more gen- eral video face forgery detection
Yinglin Zheng, Jianmin Bao, Dong Chen, Ming Zeng, and Fang Wen. Exploring temporal coherence for more gen- eral video face forgery detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15044–15054, 2021. 2
2021
-
[80]
Wilddeepfake: A challenging real-world dataset for deepfake detection
Bojia Zi, Minghao Chang, Jingjing Chen, Xingjun Ma, and Yu-Gang Jiang. Wilddeepfake: A challenging real-world dataset for deepfake detection. InProceedings of the 28th ACM international conference on multimedia, pages 2382– 2390, 2020. 2 CoCoVideo: The High-Quality Commercial-Model-Based Contrastive Benchmark for AI-Generated Video Detection Supplementary...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.