StressDream: Steering Video World Models for Robust Policy Evaluation and Improvement
Pith reviewed 2026-06-28 22:44 UTC · model grok-4.3
The pith
Optimizing initial noise in diffusion video models steers imaginations to high-impact events like task failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
StressDream optimizes the high-dimensional initial noise of diffusion-based video world models using a semantic objective from a vision-language model and a plausibility objective to produce imaginations that match text-specified high-impact events while remaining in-distribution, thereby enabling robust policy evaluation by identifying risky actions whose plausible futures include failures.
What carries the argument
The StressDream optimization procedure, which adjusts diffusion initial noise guided by VLM semantic scores and a plausibility regularizer to steer generated video sequences toward target outcomes.
If this is right
- Policy evaluation can identify actions that lead to undesirable outcomes in some plausible futures without drawing many samples.
- Policy improvement can prioritize actions that avoid futures containing specified failures.
- Video world models can be used for targeted stress-testing of autonomous systems in driving and manipulation domains.
- Steering happens at inference time without modifying the underlying world model.
Where Pith is reading between the lines
- Similar steering techniques might apply to other generative models beyond video, such as for text or audio generation in safety-critical applications.
- The approach could be extended to optimize for multiple conflicting objectives simultaneously in policy testing.
- Real-world validation would involve deploying the evaluated policies on physical robots to check if the identified risks correlate with actual failures.
Load-bearing premise
That gradients from the vision-language model can effectively guide high-dimensional noise optimization to produce nuanced scene-specific events without causing the generated videos to become implausible or out-of-distribution.
What would settle it
Generate steered videos for a specified failure event and check if independent human or VLM raters confirm that the event occurs in the video at rates significantly above unsteered samples, while also confirming visual plausibility.
Figures















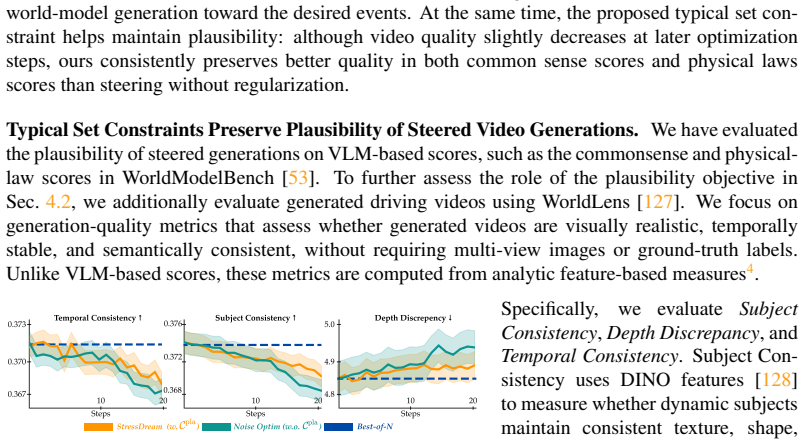

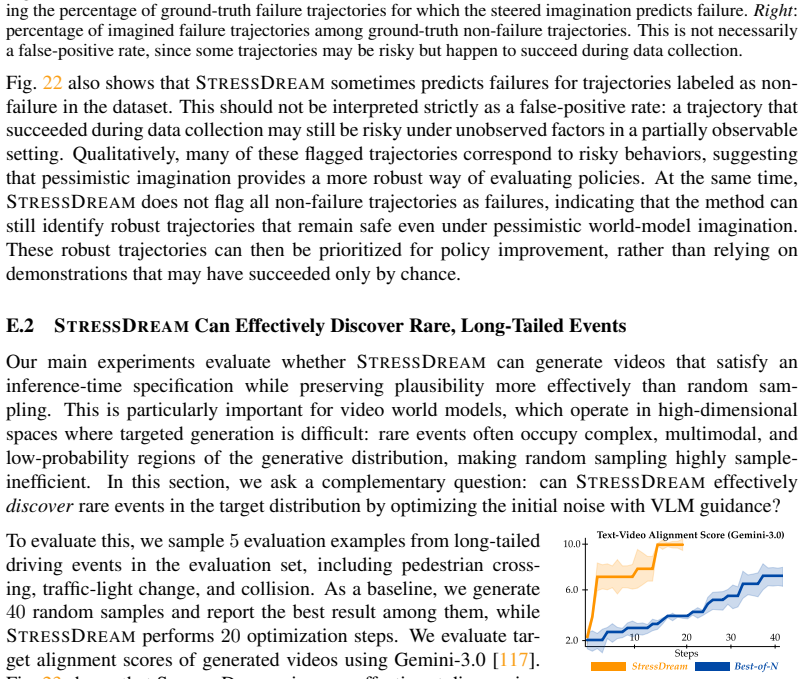


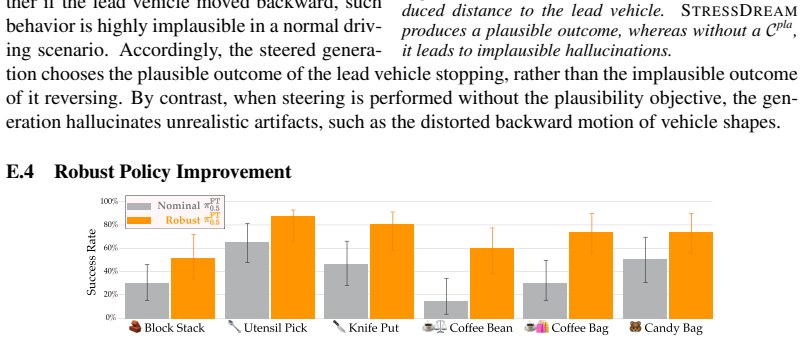
read the original abstract
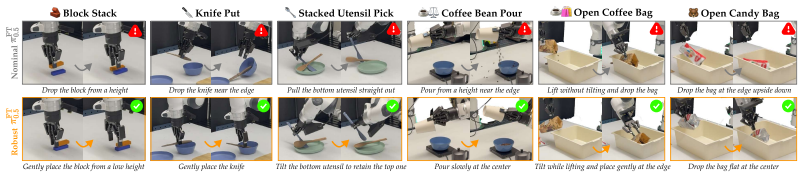
Video world models (WMs) have shown promise for policy evaluation and improvement by imagining realistic future observations conditioned on ego-robot actions. While WMs can model distributions over futures, policy evaluation and improvement typically rely on nominal imaginations, which can miss high-impact outcomes of robot actions unless prohibitively many samples are drawn. To enable robust policy evaluation and improvement over WM imaginations, we propose StressDream, which steers imaginations toward high-impact yet plausible outcomes specified at inference time by optimizing the initial noise of diffusion-based WMs. However, optimizing high-dimensional noise is challenging: the optimization must reason about nuanced, scene-dependent target events in generated videos while avoiding out-of-distribution (OOD) noise that yields implausible imaginations. We address this with two complementary objectives: a semantic objective with a Vision-Language Model that provides informative gradients by reasoning about the generated video, and a plausibility objective that prevents the optimized noise from drifting OOD. With state-of-the-art video world models for autonomous driving and robotic manipulation, we show that StressDream effectively steers imaginations toward high-impact yet plausible outcomes specified by text at inference time, such as task failures, enabling robust policy evaluation and improvement by identifying actions whose plausible futures include undesirable outcomes. Video results are available at https://junwon.me/StressDream/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes StressDream, a technique for steering diffusion-based video world models at inference time by optimizing the initial noise vector. It combines a VLM-driven semantic objective (to target high-impact events such as task failures specified by text) with a plausibility objective (to keep the optimized noise in-distribution). Experiments on state-of-the-art WMs for autonomous driving and robotic manipulation are claimed to show that the steered imaginations enable more robust policy evaluation and improvement by surfacing undesirable yet plausible futures.
Significance. If the optimization reliably produces in-distribution samples that realize the specified high-impact events, the approach would meaningfully extend the utility of video WMs beyond nominal rollouts, allowing text-specified stress testing without exhaustive sampling. The combination of VLM semantic guidance and a plausibility regularizer is a reasonable design choice, but the absence of certified manifold proximity or strong empirical controls on OOD leakage limits the strength of the policy-evaluation guarantee.
major comments (2)
- [Section 3.2, Eq. (4)] Section 3.2, Eq. (4): the joint semantic + plausibility objective is presented as sufficient to keep optimized noise inside the WM training distribution, yet the plausibility term is only a soft reconstruction/feature-matching penalty with no Lipschitz bound, distance-to-manifold certificate, or rejection sampling step. Gradient descent in the high-dimensional noise space can therefore satisfy the VLM captioning objective via spurious correlations while producing OOD z, directly undermining the claim that the resulting futures are valid WM samples for policy evaluation.
- The central policy-evaluation claim (identifying actions whose plausible futures include undesirable outcomes) rests on the steered videos being both high-impact and in-distribution. No quantitative results, ablation tables, or distribution-distance metrics (e.g., FID, reconstruction error histograms, or classifier-based OOD scores) are referenced that would demonstrate the plausibility term actually prevents exploitation of VLM gradients; without such evidence the load-bearing assumption remains unverified.
minor comments (2)
- The abstract states that video results are available at an external link; the main text should include at least one quantitative table summarizing success rates or failure-detection metrics across the driving and manipulation domains.
- Notation for the two loss terms and the noise variable z should be introduced once in Section 3 and used consistently thereafter to improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the optimization guarantees and empirical validation of the plausibility term. We address each major comment below, providing clarifications from the manuscript while agreeing to strengthen the presentation where evidence is indirect.
read point-by-point responses
-
Referee: [Section 3.2, Eq. (4)] Section 3.2, Eq. (4): the joint semantic + plausibility objective is presented as sufficient to keep optimized noise inside the WM training distribution, yet the plausibility term is only a soft reconstruction/feature-matching penalty with no Lipschitz bound, distance-to-manifold certificate, or rejection sampling step. Gradient descent in the high-dimensional noise space can therefore satisfy the VLM captioning objective via spurious correlations while producing OOD z, directly undermining the claim that the resulting futures are valid WM samples for policy evaluation.
Authors: We agree that Eq. (4) relies on a soft plausibility penalty without formal certificates such as Lipschitz continuity or manifold distance bounds. The design choice was motivated by the need for a differentiable regularizer compatible with gradient-based optimization of z; stronger constraints like rejection sampling would break differentiability. Section 3.2 explicitly frames the term as a practical regularizer rather than a certified guarantee. We will revise the text to more clearly state this limitation and avoid implying formal in-distribution guarantees. revision: yes
-
Referee: [—] The central policy-evaluation claim (identifying actions whose plausible futures include undesirable outcomes) rests on the steered videos being both high-impact and in-distribution. No quantitative results, ablation tables, or distribution-distance metrics (e.g., FID, reconstruction error histograms, or classifier-based OOD scores) are referenced that would demonstrate the plausibility term actually prevents exploitation of VLM gradients; without such evidence the load-bearing assumption remains unverified.
Authors: The manuscript presents qualitative comparisons and ablations in Section 4 showing that removing the plausibility term leads to visibly implausible generations while the combined objective produces coherent high-impact events. However, we acknowledge the absence of explicit quantitative distribution metrics such as FID or OOD classifier scores in the current version. We will add these metrics (computed on held-out validation sets) and corresponding ablation tables in the revised manuscript to directly quantify the effect of the plausibility term on OOD leakage. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces StressDream as an inference-time optimization technique over diffusion noise using a VLM semantic loss and a plausibility regularizer. No equations, derivations, or predictions are shown that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The method description relies on external pretrained components (diffusion WMs, VLMs) without renaming known results or importing uniqueness theorems from the authors' prior work. The central contribution is an empirical steering procedure whose validity is assessed via downstream policy evaluation experiments rather than any self-referential mathematical reduction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
NoiseTilt: Noise-Tilted Reverse Kernels for Diffusion Reward Alignment
NTRK uses a whitening operator to tilt the noise term in diffusion reverse kernels for reward guidance, outperforming baselines with 20x fewer steps on aesthetic tasks.
Reference graph
Works this paper leans on
-
[1]
N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y . Chen, Y . Cui, Y . Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[2]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[3]
Z. Mei, T. Yin, O. Shorinwa, A. Badithela, Z. Zheng, J. Bruno, M. Bland, L. Zha, A. Hancock, J. F. Fisac, et al. Video generation models in robotics-applications, research challenges, future directions.arXiv preprint arXiv:2601.07823, 2026
arXiv 2026
-
[4]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems (NeurIPS), 33:6840–6851, 2020
2020
-
[5]
Karras, M
T. Karras, M. Aittala, T. Aila, and S. Laine. Elucidating the design space of diffusion- based generative models.Advances in Neural Information Processing Systems (NeurIPS), 35:26565–26577, 2022
2022
-
[6]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023. URL https://openreview.net/forum?id=PqvMRDCJT9t
2023
-
[7]
Alonso, A
E. Alonso, A. Jelley, V . Micheli, A. Kanervisto, A. Storkey, T. Pearce, and F. Fleuret. Dif- fusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Systems (NeurIPS), 37:58757–58791, 2024
2024
-
[8]
B. Chen, D. Mart ´ı Mons´o, Y . Du, M. Simchowitz, R. Tedrake, and V . Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Informa- tion Processing Systems (NeurIPS), 37:24081–24125, 2024
2024
-
[9]
S. Gao, S. Zhou, Y . Du, J. Zhang, and C. Gan. Adaworld: Learning adaptable world models with latent actions. InInternational Conference on Machine Learning (ICML), pages 18744– 18771, 2025
2025
-
[10]
T. Kerssies, G. Berton, J. He, Q. Yu, W. Ma, D. de Geus, G. Dubbelman, and L.-C. Chen. A frame is worth one token: Efficient generative world modeling with delta tokens.arXiv preprint arXiv:2604.04913, 2026
Pith/arXiv arXiv 2026
-
[11]
S. Gao, J. Yang, L. Chen, K. Chitta, Y . Qiu, A. Geiger, J. Zhang, and H. Li. Vista: A generalizable driving world model with high fidelity and versatile controllability.Advances in Neural Information Processing Systems (NeurIPS), 37:91560–91596, 2024
2024
-
[12]
Y . Guo, L. X. Shi, J. Chen, and C. Finn. Ctrl-world: A controllable generative world model for robot manipulation. InInternational Conference on Learning Representations (ICLR),
-
[13]
URLhttps://openreview.net/forum?id=748bHL2BAv. 9
-
[14]
Y . Guo, T. Lee, L. X. Shi, J. Chen, P. Liang, and C. Finn. Vlaw: Iterative co-improvement of vision-language-action policy and world model.arXiv preprint arXiv:2602.12063, 2026
arXiv 2026
-
[15]
Zhang, Z
K. Zhang, Z. Tang, X. Hu, X. Pan, X. Guo, Y . Liu, J. Huang, L. Yuan, Q. Zhang, X.-X. Long, et al. Epona: Autoregressive diffusion world model for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 27220–27230, 2025
2025
-
[16]
J. Quevedo, A. K. Sharma, Y . Sun, V . Suryavanshi, P. Liang, and S. Yang. Worldgym: World model as an environment for policy evaluation.arXiv preprint arXiv:2506.00613, 2025
arXiv 2025
-
[17]
G. R. Team, K. Choromanski, C. Devin, Y . Du, D. Dwibedi, R. Gao, A. Jindal, T. Kipf, S. Kirmani, I. Leal, et al. Evaluating gemini robotics policies in a veo world simulator.arXiv preprint arXiv:2512.10675, 2025
arXiv 2025
-
[18]
A. K. Sharma, Y . Sun, N. Lu, Y . Zhang, J. Liu, and S. Yang. World-gymnast: Training robots with reinforcement learning in a world model.arXiv preprint arXiv:2602.02454, 2026
arXiv 2026
-
[19]
Samuel, R
D. Samuel, R. Ben-Ari, N. Darshan, H. Maron, and G. Chechik. Norm-guided latent space exploration for text-to-image generation.Advances in Neural Information Processing Systems (NeurIPS), 36:57863–57875, 2023
2023
-
[20]
Z. Tang, J. Peng, J. Tang, M. Hong, F. Wang, and T.-H. Chang. Inference-time alignment of diffusion models with direct noise optimization. InInternational Conference on Machine Learning (ICML), 2025. URLhttps://openreview.net/forum?id=JpbqiD7n9r
2025
-
[21]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: A vision-language-action model with open-world generaliza- tion.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[22]
Y . Li, Y . Zhu, J. Wen, C. Shen, and Y . Xu. Worldeval: World model as real-world robot policies evaluator.arXiv preprint arXiv:2505.19017, 2025
arXiv 2025
-
[23]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, and J. Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning. InInternational Conference on Learning Representations (ICLR), 2026. URLhttps:// openreview.net/forum?id=wPEIStHxYH
2026
-
[24]
T. Yin, Z. Mei, Z. Zheng, M. Yamane, D. Wang, J. Sceats, S. M. Bateman, L. Zha, A. Ba- dithela, O. Shorinwa, et al. Playworld: Learning robot world models from autonomous play. arXiv preprint arXiv:2603.09030, 2026
Pith/arXiv arXiv 2026
-
[25]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Representations (ICLR), 2021. URLhttps://openreview.net/ forum?id=St1giarCHLP
2021
-
[26]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations (ICLR), 2021. URLhttps://openreview.net/forum?id= PxTIG12RRHS
2021
-
[27]
G. Zhou, H. Pan, Y . LeCun, and L. Pinto. DINO-WM: World models on pre-trained vi- sual features enable zero-shot planning. InInternational Conference on Machine Learning (ICML), 2025. URLhttps://openreview.net/forum?id=D5RNACOZEI
2025
-
[28]
Hansen, H
N. Hansen, H. Su, and X. Wang. Td-mpc2: Scalable, robust world models for continuous control. InInternational Conference on Learning Representations (ICLR), 2024. 10
2024
-
[29]
J. Moos, K. Hansel, H. Abdulsamad, S. Stark, D. Clever, and J. Peters. Robust reinforcement learning: A review of foundations and recent advances.Machine Learning and Knowledge Extraction, 4(1):276–315, 2022
2022
-
[30]
Akella, A
P. Akella, A. Dixit, M. Ahmadi, L. Lindemann, M. P. Chapman, G. J. Pappas, A. D. Ames, and J. W. Burdick. Risk-aware robotics: Tail risk measures in planning, control, and verification [focus on education].IEEE Control Systems, 45(4):46–78, 2025
2025
-
[31]
Karunratanakul, K
K. Karunratanakul, K. Preechakul, E. Aksan, T. Beeler, S. Suwajanakorn, and S. Tang. Opti- mizing diffusion noise can serve as universal motion priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1334–1345, 2024
2024
-
[32]
Eyring, S
L. Eyring, S. Karthik, K. Roth, A. Dosovitskiy, and Z. Akata. Reno: Enhancing one-step text- to-image models through reward-based noise optimization.Advances in Neural Information Processing Systems (NeurIPS), 37:125487–125519, 2024
2024
-
[33]
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 2023
Pith/arXiv arXiv 2023
-
[34]
T. M. Cover.Elements of information theory. John Wiley & Sons, 1999
1999
-
[35]
M. Betancourt. A conceptual introduction to hamiltonian monte carlo.arXiv preprint arXiv:1701.02434, 2017
Pith/arXiv arXiv 2017
-
[36]
E. Nalisnick, A. Matsukawa, Y . W. Teh, and B. Lakshminarayanan. Detecting out-of-distribution inputs to deep generative models using typicality.arXiv preprint arXiv:1906.02994, 2019
arXiv 1906
-
[37]
Samuel, R
D. Samuel, R. Ben-Ari, S. Raviv, N. Darshan, and G. Chechik. Generating images of rare concepts using pre-trained diffusion models. InProceedings of the AAAI Conference on Artificial Intelligence, 2024
2024
-
[38]
Harrington, A
A. Harrington, A. S. Koepke, S. Karthik, T. Darrell, and A. A. Efros. It’s never too late: Noise optimization for collapse recovery in trained diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[39]
Durall, M
R. Durall, M. Keuper, and J. Keuper. Watch your up-convolution: Cnn based generative deep neural networks are failing to reproduce spectral distributions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7890– 7899, 2020
2020
-
[40]
Stoica, R
P. Stoica, R. L. Moses, et al.Spectral analysis of signals, volume 452. Pearson Prentice Hall Upper Saddle River, NJ, 2005
2005
-
[41]
S. V . Vaseghi.Advanced digital signal processing and noise reduction. John Wiley & Sons, 2008
2008
-
[42]
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y . Levi, Z. En- glish, V . V oleti, A. Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
Pith/arXiv arXiv 2023
-
[43]
Eyring, S
L. Eyring, S. Karthik, A. Dosovitskiy, N. Ruiz, and Z. Akata. Noise hypernetworks: Amor- tizing test-time compute in diffusion models. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[44]
D. Ahn, J. Kang, S. Lee, J. Min, M. Kim, W. Jang, H. Cho, S. Paul, S. Kim, E. Cha, et al. A noise is worth diffusion guidance. InInternational Conference on Learning Representations (ICLR), 2026. URLhttps://openreview.net/forum?id=xEWooSOgaz. 11
2026
-
[45]
Dhariwal and A
P. Dhariwal and A. Nichol. Diffusion models beat gans on image synthesis.Advances in Neural Information Processing Systems (NeurIPS), 34:8780–8794, 2021
2021
-
[46]
W. Li, X. Xu, X. Xiao, J. Liu, H. Yang, G. Li, Z. Wang, Z. Feng, Q. She, Y . Lyu, et al. Upaint- ing: Unified text-to-image diffusion generation with cross-modal guidance.arXiv preprint arXiv:2210.16031, 2022
arXiv 2022
-
[47]
PhysicalAI-Autonomous-Vehicles.https://huggingface.co/ datasets/nvidia/PhysicalAI-Autonomous-Vehicles, 2025
NVIDIA Corporation. PhysicalAI-Autonomous-Vehicles.https://huggingface.co/ datasets/nvidia/PhysicalAI-Autonomous-Vehicles, 2025
2025
-
[48]
Moura, S
D. Moura, S. Zhu, and O. Zvitia. Nexar dashcam collision prediction dataset and challenge. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2583–2591, 2025
2025
-
[49]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[50]
B. Li, L. Zhu, R. Tian, S. Tan, Y . Chen, Y . Lu, Y . Cui, S. Veer, M. Ehrlich, J. Philion, X. Weng, F. Xue, L. Fan, Y . Zhu, J. Kautz, A. Tao, M.-Y . Liu, S. Fidler, B. Ivanovic, T. Darrell, J. Malik, S. Han, and M. Pavone. Wolf: Dense video captioning with a world summarization framework.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. U...
2025
-
[51]
Y . Ma, G. Xu, X. Sun, M. Yan, J. Zhang, and R. Ji. X-clip: End-to-end multi-grained con- trastive learning for video-text retrieval. InProceedings of the 30th ACM international con- ference on multimedia, pages 638–647, 2022
2022
-
[52]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[53]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
Pith/arXiv arXiv 2025
-
[54]
D. Li, Y . Fang, Y . Chen, S. Yang, S. Cao, J. Wong, M. Luo, X. Wang, H. Yin, J. Gonzalez, et al. Worldmodelbench: Judging video generation models as world models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 38, 2025
2025
-
[55]
Y . Hong, K.-C. Kao, H. Zhou, and C.-J. Hsieh. Understanding reward hacking in text-to- image reinforcement learning.arXiv preprint arXiv:2601.03468, 2026
arXiv 2026
-
[56]
H. Tan, S. Chen, Y . Xu, Z. Wang, Y . Ji, C. Chi, Y . Lyu, Z. Zhao, X. Chen, P. Co, et al. Robo- dopamine: General process reward modeling for high-precision robotic manipulation.arXiv preprint arXiv:2512.23703, 2025
arXiv 2025
-
[57]
Liang, Y
A. Liang, Y . Korkmaz, J. Zhang, M. Hwang, A. Anwar, S. Kaushik, A. Shah, A. S. Huang, L. Zettlemoyer, D. Fox, Y . Xiang, A. Li, A. Bobu, A. Gupta, S. Tu, E. Biyik, and J. Zhang. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons. In Robotics: Science and Systems (RSS), 2026
2026
-
[58]
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever. Consistency models. InInternational Conference on Machine Learning (ICML), pages 32211–32252, 2023. 12
2023
-
[59]
Kim, C.-H
D. Kim, C.-H. Lai, W. Liao, N. Murata, Y . Takida, T. Uesaka, Y . He, Y . Mitsufuji, and S. Er- mon. Consistency trajectory models: Learning probability flow ode trajectory of diffusion. In International Conference on Learning Representations (ICLR), volume 2024, pages 44493– 44525, 2024
2024
-
[60]
Esser, S
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, D. Podell, T. Dockhorn, Z. English, and R. Rombach. Scaling rectified flow trans- formers for high-resolution image synthesis. InInternational Conference on Machine Learn- ing (ICML), 2024. URLhttps://openreview.net/forum?id=FPnUhsQJ5B
2024
-
[61]
Finn and S
C. Finn and S. Levine. Deep visual foresight for planning robot motion. InIEEE International Conference on Robotics and Automation (ICRA), pages 2786–2793, 2017
2017
-
[62]
F. Ebert, C. Finn, S. Dasari, A. Xie, A. Lee, and S. Levine. Visual foresight: Model- based deep reinforcement learning for vision-based robotic control.arXiv preprint arXiv:1812.00568, 2018
Pith/arXiv arXiv 2018
-
[63]
Hafner, T
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson. Learning latent dynamics for planning from pixels. InInternational Conference on Machine Learning (ICML), 2019
2019
-
[64]
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg. Daydreamer: World models for physical robot learning. InConference on Robot Learning (CoRL), pages 2226–2240, 2023
2023
-
[65]
Micheli, E
V . Micheli, E. Alonso, and F. Fleuret. Transformers are sample-efficient world models. In International Conference on Learning Representations (ICLR), 2023
2023
-
[66]
Bruce, M
J. Bruce, M. D. Dennis, A. Edwards, J. Parker-Holder, Y . Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, et al. Genie: Generative interactive environments. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[67]
L. Maes, Q. L. Lidec, D. Scieur, Y . LeCun, and R. Balestriero. Leworldmodel: Stable end-to- end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026
Pith/arXiv arXiv 2026
-
[68]
Hafner, T
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination. InInternational Conference on Learning Representations (ICLR), 2020
2020
-
[69]
Hafner, T
D. Hafner, T. P. Lillicrap, M. Norouzi, and J. Ba. Mastering atari with discrete world models. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[70]
Hafner, J
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse control tasks through world models.Nature, 640(8059):647–653, Apr. 2025. ISSN 1476-4687
2025
-
[71]
D. Hafner, W. Yan, and T. Lillicrap. Training agents inside of scalable world models.arXiv preprint arXiv:2509.24527, 2025
Pith/arXiv arXiv 2025
-
[72]
Nakamura, L
K. Nakamura, L. Peters, and A. Bajcsy. Generalizing safety beyond collision-avoidance via latent-space reachability analysis. InRobotics: Science and Systems (RSS), 2025
2025
-
[73]
Agrawal, J
S. Agrawal, J. Seo, K. Nakamura, R. Tian, and A. Bajcsy. Anysafe: Adapting latent safety filters at runtime via safety constraint parameterization in the latent space. InIEEE Interna- tional Conference on Robotics and Automation (ICRA), 2026
2026
- [74]
-
[75]
Hassan, S
M. Hassan, S. Stapf, A. Rahimi, P. Rezende, Y . Haghighi, D. Br ¨uggemann, I. Katircioglu, L. Zhang, X. Chen, S. Saha, et al. Gem: A generalizable ego-vision multimodal world model for fine-grained ego-motion, object dynamics, and scene composition control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2...
2025
-
[76]
Walker, C
J. Walker, C. Doersch, A. Gupta, and M. Hebert. An uncertain future: Forecasting from static images using variational autoencoders. InEuropean Conference on Computer Vision (ECCV), pages 835–851. Springer, 2016
2016
-
[77]
Zhang, G
W. Zhang, G. Wang, J. Sun, Y . Yuan, and G. Huang. Storm: Efficient stochastic transformer based world models for reinforcement learning.Advances in Neural Information Processing Systems (NeurIPS), 36:27147–27166, 2023
2023
-
[78]
L. Russell, A. Hu, L. Bertoni, G. Fedoseev, J. Shotton, E. Arani, and G. Corrado. Gaia-2: A controllable multi-view generative world model for autonomous driving.arXiv preprint arXiv:2503.20523, 2025
Pith/arXiv arXiv 2025
-
[79]
F. Bartoccioni, E. Ramzi, V . Besnier, S. Venkataramanan, T.-H. Vu, Y . Xu, L. Chambon, S. Gidaris, S. Odabas, D. Hurych, et al. Vavim and vavam: Autonomous driving through video generative modeling.arXiv preprint arXiv:2502.15672, 2025
arXiv 2025
-
[80]
J. Seo, K. Nakamura, and A. Bajcsy. Uncertainty-aware latent safety filters for avoiding out-of-distribution failures. InConference on Robot Learning (CoRL), 2025. URLhttps: //openreview.net/forum?id=CQKxhmLobo
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.