DREAM-S: Speculative Decoding with Searchable Drafting and Target-Aware Refinement for Multimodal Generation
Pith reviewed 2026-06-28 18:54 UTC · model grok-4.3
The pith
DREAM-S uses neural architecture search to automatically optimize draft models and their interactions with target models for faster speculative decoding in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
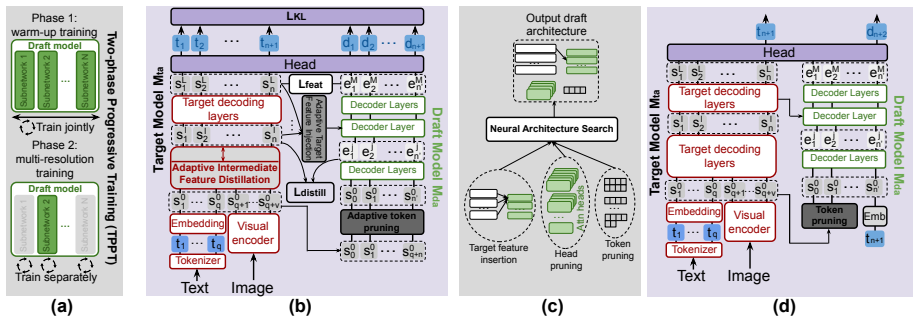
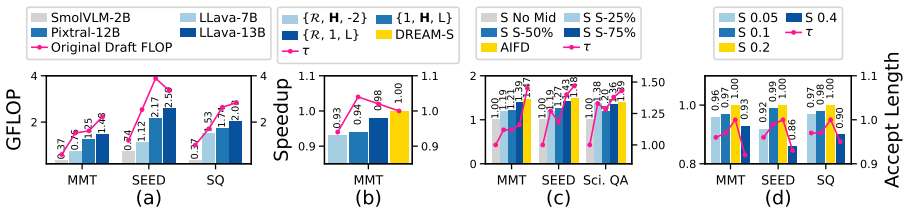
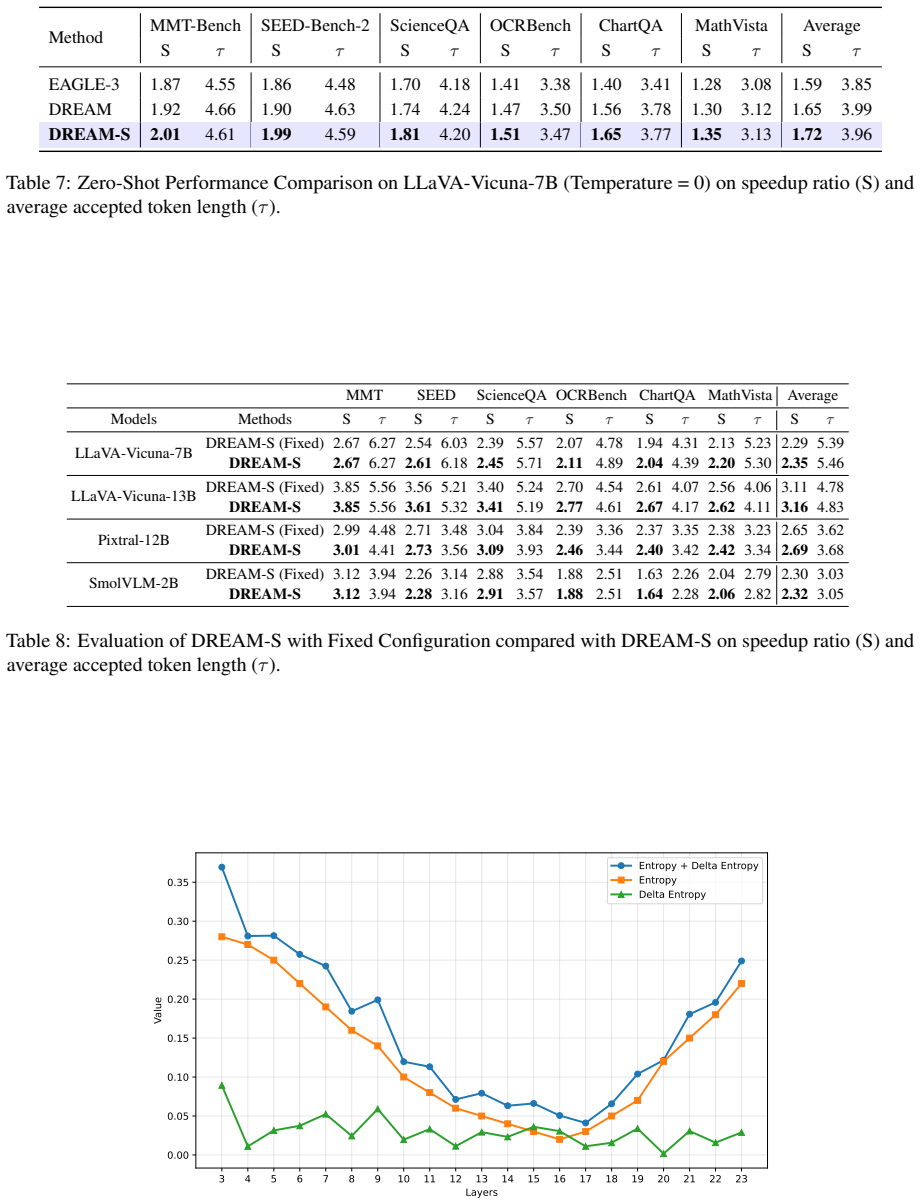
DREAM-S is a speculative decoding framework for VLMs that employs a NAS framework with target-aware supernet training to automatically determine optimal interaction strategies between draft and target models and suitable draft architectures, along with adaptive intermediate feature distillation guided by attention entropy, leading to up to 3.85x speedup compared to standard decoding and better performance than existing SD baselines.
What carries the argument
The neural architecture search framework with target-aware supernet training that identifies optimal draft-target interaction strategies and draft architectures for given hardware.
If this is right
- Speculative decoding becomes practical for VLMs without manual design of draft models or interaction rules.
- Draft models can be trained more efficiently through attention-entropy-guided distillation from the target.
- The same search process adapts the method to different hardware platforms automatically.
- Generation latency drops while output quality remains comparable to the original target model.
- Existing VLM inference pipelines can incorporate the framework with measurable speed gains over prior SD techniques.
Where Pith is reading between the lines
- The search-based approach could be applied to other autoregressive multimodal tasks such as video or audio generation.
- Hardware-specific drafts found this way might also reduce memory footprint during inference.
- Combining the method with quantization or other compression steps could produce further cumulative speedups.
- If the search cost stays low, the framework might support on-device adaptation when new VLMs are deployed.
Load-bearing premise
The neural architecture search process can reliably locate the single best interaction strategy and draft architecture for any target model and hardware platform.
What would settle it
Running the full search and then measuring generation time on a VLM and hardware pair not included in the original search, and finding that the resulting draft produces no speedup or lower quality than standard decoding.
Figures
read the original abstract
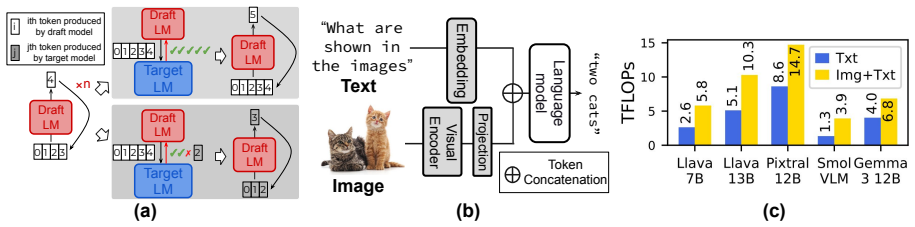
Speculative decoding (SD) has proven to be an effective technique for accelerating autoregressive generation in large language models (LLMs) however, its application to vision-language models (VLMs) remains relatively unexplored. We propose~\textit{DREAM-S}, a novel SD framework designed specifically for fast and efficient decoding in VLMs. DREAM-S leverages a neural architecture search (NAS) framework with target-aware supernet training to automatically identify both the optimal interaction strategy between the draft and target models, and the most suitable draft model architecture for the underlying hardware implementation platform. DREAM-S additionally incorporates adaptive intermediate feature distillation, guided by attention entropy, to enable efficient draft training. Experiments on a range of well-established VLMs show that DREAM-S achieves up to a $3.85\times$ speedup compared to standard decoding approaches and significantly outperforms existing SD baselines. The code is publicly available at: https://github.com/SAI-Lab-NYU/DREAM-S .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DREAM-S, a speculative decoding framework for vision-language models (VLMs) that uses a neural architecture search (NAS) approach with target-aware supernet training to automatically discover optimal draft-model architectures and draft-target interaction strategies. It further incorporates adaptive intermediate feature distillation guided by attention entropy. Experiments on established VLMs report up to 3.85× speedup versus standard autoregressive decoding and consistent outperformance over prior speculative-decoding baselines, with code released publicly.
Significance. If the NAS component is shown to reliably identify superior drafts and interaction patterns beyond what fixed or hand-crafted designs achieve under comparable training budgets, the work would provide a practical, hardware-aware method for accelerating multimodal generation. The public code release is a clear strength that supports reproducibility.
major comments (2)
- [Experiments section (results and ablations)] The headline claims of speedup and outperformance rest on the NAS framework with target-aware supernet training discovering better draft architectures and interaction strategies than existing SD baselines. No ablation is described that isolates the searchable-drafting component (e.g., searched vs. hand-crafted or random drafts) while holding the attention-entropy distillation and training budget fixed. Without such a comparison, gains cannot be confidently attributed to the NAS rather than the distillation alone.
- [Method section (target-aware supernet training)] The target-aware supernet is asserted to serve as a faithful proxy for the full target VLM across both vision and language tokens. The manuscript should report quantitative validation of this proxy (e.g., correlation between supernet-predicted and target-model acceptance rates or token-level fidelity metrics) to substantiate that the search space exploration is meaningful for multimodal inputs.
minor comments (2)
- [Abstract / Experiments] The abstract states results on “a range of well-established VLMs” but does not name the specific models, datasets, or hardware platforms used; these details should appear in the first paragraph of the experimental section for immediate clarity.
- [Method section] Notation for draft-target interaction strategies (e.g., how many tokens are drafted per step or how verification is performed) should be introduced with a compact table or diagram early in the method section to aid readers unfamiliar with VLM-specific SD variants.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the contributions of the NAS component and the validity of the supernet proxy. We address each major comment below and will revise the manuscript accordingly to strengthen the experimental evidence and validation.
read point-by-point responses
-
Referee: [Experiments section (results and ablations)] The headline claims of speedup and outperformance rest on the NAS framework with target-aware supernet training discovering better draft architectures and interaction strategies than existing SD baselines. No ablation is described that isolates the searchable-drafting component (e.g., searched vs. hand-crafted or random drafts) while holding the attention-entropy distillation and training budget fixed. Without such a comparison, gains cannot be confidently attributed to the NAS rather than the distillation alone.
Authors: We agree that an explicit ablation isolating the searchable-drafting component—while holding the attention-entropy-guided distillation and training budget fixed—would strengthen attribution of gains to the NAS framework. In the revised manuscript we will add experiments comparing searched draft architectures and interaction strategies against both hand-crafted baselines and randomly sampled drafts under identical distillation settings and compute budgets. These results will be reported alongside the existing comparisons to prior SD methods. revision: yes
-
Referee: [Method section (target-aware supernet training)] The target-aware supernet is asserted to serve as a faithful proxy for the full target VLM across both vision and language tokens. The manuscript should report quantitative validation of this proxy (e.g., correlation between supernet-predicted and target-model acceptance rates or token-level fidelity metrics) to substantiate that the search space exploration is meaningful for multimodal inputs.
Authors: We concur that quantitative validation of the supernet as a proxy would better substantiate the search process for multimodal inputs. In the revision we will include additional metrics, such as Pearson correlation between supernet-predicted and target-model acceptance rates as well as token-level fidelity measures (e.g., feature similarity on vision and language tokens), to demonstrate the proxy's reliability. revision: yes
Circularity Check
No circularity: empirical claims rest on experiments, not self-referential definitions or fits
full rationale
The paper presents DREAM-S as a new NAS-based speculative decoding framework for VLMs, with claims of speedup supported by experiments on established models. No equations, fitted parameters, or self-citations appear in the abstract or described text that would reduce the performance claims to inputs by construction. The NAS component and distillation are presented as methodological contributions whose value is evaluated externally via benchmarks, keeping the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[9]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[10]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[11]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Visualgpt: Data-efficient adaptation of pretrained language models for image captioning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[12]
Layer by Layer: Uncovering Hidden Representations in Language Models
Layer by layer: Uncovering hidden representations in language models , author=. arXiv preprint arXiv:2502.02013 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
VLRM: Vision-Language Models act as Reward Models for Image Captioning , author=. arXiv preprint arXiv:2404.01911 , year=
-
[14]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Scaling up vision-language pre-training for image captioning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[15]
Svdqunat: Absorbing outliers by low-rank components for 4-bit diffusion models , author=. arXiv preprint arXiv:2411.05007 , year=
-
[16]
Dobi-SVD: Differentiable SVD for LLM Compression and Some New Perspectives , author=. arXiv preprint arXiv:2502.02723 , year=
-
[17]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Quarot: Outlier-free 4-bit inference in rotated llms , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[18]
Palu: KV-Cache Compression with Low-Rank Projection , author=
-
[19]
Proceedings of the Conference on Artificial Intelligence (AAAI) , year=
Unified vision-language pre-training for image captioning and vqa , author=. Proceedings of the Conference on Artificial Intelligence (AAAI) , year=
-
[20]
int8 (): 8-bit matrix multiplication for transformers at scale , author=
Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[21]
Bioengineering , year=
Vision--language model for visual question answering in medical imagery , author=. Bioengineering , year=
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Prompt-RSVQA: Prompting visual context to a language model for remote sensing visual question answering , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[23]
Surgical-lvlm: Learning to adapt large vision-language model for grounded visual question answering in robotic surgery , author=. arXiv preprint arXiv:2405.10948 , year=
-
[24]
Proceedings of the Conference on Artificial Intelligence (AAAI) , year=
Leveraging large vision-language model as user intent-aware encoder for composed image retrieval , author=. Proceedings of the Conference on Artificial Intelligence (AAAI) , year=
-
[25]
SearchLVLMs: A Plug-and-Play Framework for Augmenting Large Vision-Language Models by Searching Up-to-Date Internet Knowledge , author=. arXiv preprint arXiv:2405.14554 , year=
-
[26]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Gqa: Training generalized multi-query transformer models from multi-head checkpoints , author=. arXiv preprint arXiv:2305.13245 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Fast Transformer Decoding: One Write-Head is All You Need
Fast transformer decoding: One write-head is all you need , author=. arXiv preprint arXiv:1911.02150 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[29]
arXiv preprint arXiv:2310.17956 , year=
Qilin-med-vl: Towards chinese large vision-language model for general healthcare , author=. arXiv preprint arXiv:2310.17956 , year=
-
[30]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Vision-language models for vision tasks: A survey , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[31]
arXiv preprint arXiv:2503.16365 , year=
JARVIS-VLA: Post-Training Large-Scale Vision Language Models to Play Visual Games with Keyboards and Mouse , author=. arXiv preprint arXiv:2503.16365 , year=
-
[32]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , year=
Videogamebunny: Towards vision assistants for video games , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , year=
-
[33]
JMIR Formative Research , year=
Vision-language model for generating textual descriptions from clinical images: Model development and validation study , author=. JMIR Formative Research , year=
-
[34]
Proceedings of the International Conference on Machine Learning (ICML) , year=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. Proceedings of the International Conference on Machine Learning (ICML) , year=
-
[35]
Proceedings of the International Conference on Machine Learning (ICML) , year=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. Proceedings of the International Conference on Machine Learning (ICML) , year=
-
[36]
SmolVLM: Redefining small and efficient multimodal models
SmolVLM: Redefining small and efficient multimodal models , author=. arXiv preprint arXiv:2504.05299 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Tinyllava: A framework of small-scale large multimodal models,
Tinyllava: A framework of small-scale large multimodal models , author=. arXiv preprint arXiv:2402.14289 , year=
-
[38]
Tinygpt-v: Efficient multimodal large language model via small backbones , author=. arXiv preprint arXiv:2312.16862 , year=
-
[39]
A Survey on Hallucination in Large Vision-Language Models
A survey on hallucination in large vision-language models , author=. arXiv preprint arXiv:2402.00253 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Visual instruction tuning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[41]
CoRR , year=
PaliGemma: A versatile 3B VLM for transfer , author=. CoRR , year=
-
[42]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
SpinQuant: LLM quantization with learned rotations
Spinquant: Llm quantization with learned rotations , author=. arXiv preprint arXiv:2405.16406 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Duquant: Distributing outliers via dual transformation makes stronger quantized llms , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[46]
Proceedings of the International Conference on Machine Learning (ICML) , year=
Smoothquant: Accurate and efficient post-training quantization for large language models , author=. Proceedings of the International Conference on Machine Learning (ICML) , year=
-
[47]
arXiv preprint arXiv:2403.12544 , year=
Affinequant: Affine transformation quantization for large language models , author=. arXiv preprint arXiv:2403.12544 , year=
-
[48]
Quip\#: Even better llm quantization with hadamard incoherence and lattice codebooks , author=. arXiv preprint arXiv:2402.04396 , year=
-
[49]
Proceedings of the 32nd ACM International Conference on Multimedia , year=
Advancing Multimodal Large Language Models with Quantization-Aware Scale Learning for Efficient Adaptation , author=. Proceedings of the 32nd ACM International Conference on Multimedia , year=
-
[50]
Q-VLM: Post-training Quantization for Large Vision-Language Models , author=. arXiv preprint arXiv:2410.08119 , year=
-
[51]
MBQ: Modality-Balanced Quantization for Large Vision-Language Models , author=. arXiv preprint arXiv:2412.19509 , year=
-
[52]
Compressing pre-trained language models by matrix decomposition , author=. Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing , year=
-
[53]
Language model compression with weighted low-rank factorization , author=. arXiv preprint arXiv:2207.00112 , year=
-
[54]
ASVD: Activation-aware Singular Value Decomposition for Compressing Large Language Models
Asvd: Activation-aware singular value decomposition for compressing large language models , author=. arXiv preprint arXiv:2312.05821 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Basis shar- ing: Cross-layer parameter sharing for large language model compression
Svd-llm: Truncation-aware singular value decomposition for large language model compression , author=. arXiv preprint arXiv:2403.07378 , year=
-
[56]
Palu: Compressing kv-cache with low-rank projection.arXiv preprint arXiv:2407.21118, 2024
Palu: Compressing kv-cache with low-rank projection , author=. arXiv preprint arXiv:2407.21118 , year=
-
[57]
Philosophical transactions of the royal society A: Mathematical, Physical and Engineering Sciences , year=
Principal component analysis: a review and recent developments , author=. Philosophical transactions of the royal society A: Mathematical, Physical and Engineering Sciences , year=
-
[58]
Effectively compress kv heads for llm.arXiv preprint arXiv:2406.07056, 2024
Effectively compress kv heads for llm , author=. arXiv preprint arXiv:2406.07056 , year=
-
[59]
AdaSVD: Adaptive Singular Value Decomposition for Large Language Models , author=. arXiv preprint arXiv:2502.01403 , year=
-
[60]
A tutorial on Fisher information , author=
-
[61]
SVD-LLM V2: Optimizing Singular Value Truncation for Large Language Model Compression , author=. arXiv preprint arXiv:2503.12340 , year=
-
[62]
Group fisher pruning for practical network compression , author=
-
[63]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Importance estimation for neural network pruning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[64]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Pre-rmsnorm and pre-crmsnorm transformers: equivalent and efficient pre-ln transformers , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[65]
Proceedings of Machine Learning and Systems , year=
Awq: Activation-aware weight quantization for on-device llm compression and acceleration , author=. Proceedings of Machine Learning and Systems , year=
-
[66]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Gptq: Accurate post-training quantization for generative pre-trained transformers , author=. arXiv preprint arXiv:2210.17323 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Omniquant: Omnidirectionally calibrated quantization for large language models , author=. arXiv preprint arXiv:2308.13137 , year=
-
[68]
The 36th Conference on Neural Information Processing Systems (NeurIPS) , year=
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , author=. The 36th Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[69]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Seed-bench: Benchmarking multimodal large language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[70]
CVPR , year=
VizWiz Grand Challenge: Answering Visual Questions from Blind People , author=. CVPR , year=
-
[71]
Proceedings of the 32nd ACM International Conference on Multimedia , year=
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models , author=. Proceedings of the 32nd ACM International Conference on Multimedia , year=
-
[72]
Rotated Runtime Smooth: Training-Free Activation Smoother for accurate
Ke Yi and Zengke Liu and jianwei zhang and Chengyuan Li and Tong Zhang and Junyang Lin and Jingren Zhou , booktitle=. Rotated Runtime Smooth: Training-Free Activation Smoother for accurate
-
[73]
arXiv preprint arXiv:2306.07629 , year=
Squeezellm: Dense-and-sparse quantization , author=. arXiv preprint arXiv:2306.07629 , year=
-
[74]
2023 , eprint=
Training Transformers with 4-bit Integers , author=. 2023 , eprint=
2023
-
[75]
arXiv preprint arXiv:2406.16858 , year=
Eagle-2: Faster inference of language models with dynamic draft trees , author=. arXiv preprint arXiv:2406.16858 , year=
-
[76]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Eagle: Speculative sampling requires rethinking feature uncertainty , author=. arXiv preprint arXiv:2401.15077 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
arXiv preprint arXiv:2408.15766 , year=
Learning Harmonized Representations for Speculative Sampling , author=. arXiv preprint arXiv:2408.15766 , year=
-
[78]
arXiv preprint arXiv:2410.03804 , year=
Mixture of Attentions For Speculative Decoding , author=. arXiv preprint arXiv:2410.03804 , year=
-
[79]
arXiv preprint arXiv:2410.01296 , year=
Speculative Coreset Selection for Task-Specific Fine-tuning , author=. arXiv preprint arXiv:2410.01296 , year=
-
[80]
arXiv preprint arXiv:2411.11055 , year=
FastDraft: How to Train Your Draft , author=. arXiv preprint arXiv:2411.11055 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.