Global-Local Attention Decomposition for Terrain Encoding in Humanoid Perceptive Locomotion
Pith reviewed 2026-06-28 18:45 UTC · model grok-4.3
The pith
Global-local attention split lets humanoid policies handle gaps and stairs without entangling terrain cues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
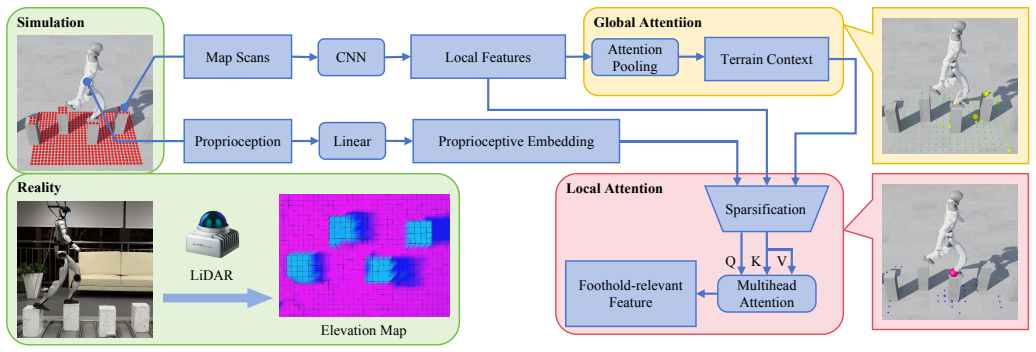
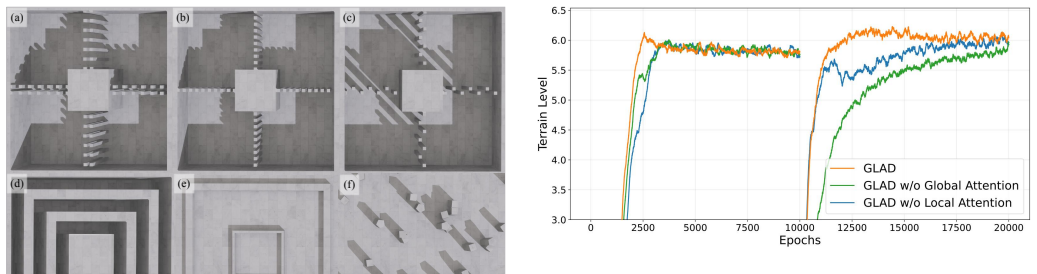
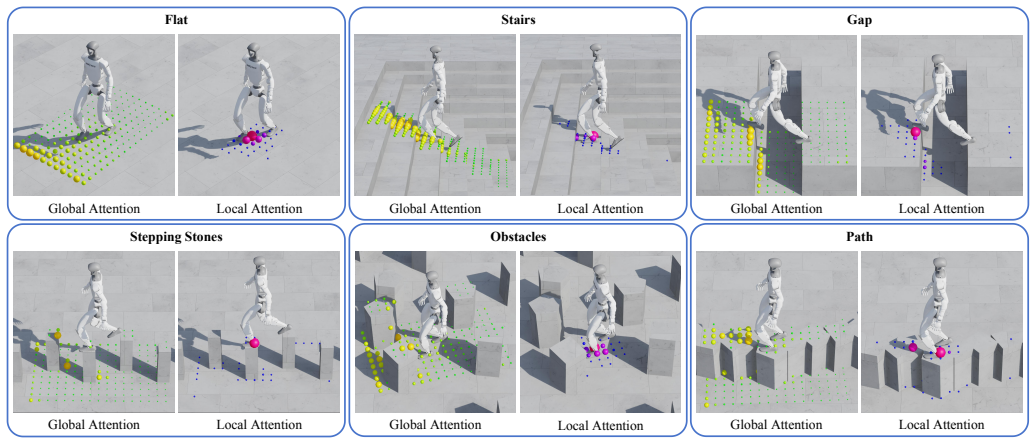
GLAD realizes a coarse-to-fine encoder that explicitly decomposes terrain perception: a global attention branch summarizes surrounding context via attention pooling, while a state-conditioned local attention branch sparsifies and encodes precise foothold geometry. The decomposition is claimed to prevent dilution of fine-grained spatial cues and to reduce training overhead, enabling reliable locomotion over gaps, stepping stones, and stairs plus emergent behaviors such as autonomous path following under simple velocity commands.
What carries the argument
Global-Local Attention Decomposition (GLAD): a coarse-to-fine encoder on a robot-centric elevation map that separates global attention pooling from state-conditioned local attention sparsification.
If this is right
- Policies can cross sparse-foothold terrain and constrained spaces without separate navigation modules.
- Simple velocity commands suffice for emergent obstacle avoidance and narrow-path following.
- Zero-shot sim-to-real transfer works on a physical Unitree G1 using only onboard LiDAR in diverse domains.
Where Pith is reading between the lines
- The same split might reduce sample complexity in other perception-heavy control tasks such as manipulation on cluttered tables.
- If the local branch can be conditioned on different state features, the approach could generalize to quadrupeds or wheeled platforms with similar elevation maps.
- Emergent path-following suggests the global branch already encodes enough topology for basic navigation, which could be tested by removing explicit planners in more environments.
Load-bearing premise
Conventional encoders necessarily entangle broad awareness with precise foothold selection, and splitting them via attention on an elevation map will preserve the fine cues without extra cost.
What would settle it
A policy using a single undifferentiated encoder that matches or exceeds GLAD's success rate on the same gap, stepping-stone, and stair test sets while using comparable training compute.
Figures


read the original abstract
Although reinforcement learning has significantly advanced humanoid locomotion, perceptive policies still struggle on sparse-foothold terrain and constrained environments. Success in these scenarios requires both broad terrain awareness and precise foothold selection, two perceptual roles that conventional encoders often entangle. To address this challenge, we propose Global-Local Attention Decomposition (GLAD) for terrain encoding in humanoid locomotion. Realized by a coarse-to-fine encoder over a robot-centric elevation map, GLAD explicitly separates these objectives: a global attention branch utilizes attention pooling to summarize the surrounding terrain context, while a state-conditioned local attention branch sparsifies and encodes precise foothold-relevant geometry. This explicit attention decomposition prevents the dilution of fine-grained spatial cues while reducing training overhead. Experiments demonstrate that GLAD enables reliable locomotion over challenging gaps, stepping stones, and stairs. Furthermore, the learned policy exhibits emergent terrain-responsive behaviors, autonomously following narrow paths and avoiding obstacles under simple velocity commands without explicit navigation planners. In real-world deployment on a Unitree G1 humanoid robot using onboard LiDAR, the proposed method achieves robust zero-shot sim-to-real transfer across diverse sparse-foothold and obstacle-rich domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Global-Local Attention Decomposition (GLAD) as a terrain encoder for reinforcement-learning humanoid locomotion policies. GLAD is realized as a coarse-to-fine architecture operating on a robot-centric elevation map: a global attention branch applies attention pooling to produce a summary of surrounding terrain context, while a state-conditioned local attention branch performs sparsification to encode precise foothold geometry. The central claim is that this explicit decomposition avoids dilution of fine-grained spatial cues, lowers training cost, and yields policies that achieve reliable locomotion over gaps, stepping stones and stairs, exhibit emergent terrain-responsive behaviors (narrow-path following and obstacle avoidance under velocity commands), and transfer zero-shot from simulation to a physical Unitree G1 robot equipped with onboard LiDAR across sparse-foothold and obstacle-rich domains.
Significance. If the reported locomotion performance and sim-to-real results hold, the contribution is significant because it supplies a concrete architectural mechanism for separating global context from local geometry in elevation-map encoders, a separation that conventional monolithic encoders are argued to entangle. The explicit real-world deployment on a Unitree G1 with zero-shot transfer constitutes a concrete strength that moves the work beyond simulation-only claims and provides a falsifiable benchmark for future perceptive locomotion research.
minor comments (2)
- [Method] The method section would benefit from explicit equations defining the attention pooling operation in the global branch and the state-conditioned sparsification mask in the local branch; without them the precise computational flow remains underspecified.
- [Figures] Figure captions and axis labels for any elevation-map visualizations or attention-weight heatmaps should be expanded to indicate the robot-centric coordinate frame and the numerical range of the height values.
Simulated Author's Rebuttal
We thank the referee for their thorough review and positive recommendation for minor revision. The summary accurately captures the core contribution of GLAD as an explicit decomposition of global context and local geometry in elevation-map encoding for perceptive humanoid locomotion. We appreciate the recognition of the zero-shot sim-to-real transfer on the Unitree G1 as a concrete strength.
Circularity Check
No significant circularity detected
full rationale
The paper presents GLAD as an architectural proposal for terrain encoding via explicit global-local attention decomposition on a robot-centric elevation map, with no equations, derivations, parameter fittings, or mathematical reductions appearing in the provided text. The central claim rests on a design rationale (attention pooling for global context, state-conditioned sparsification for local cues) that is introduced directly as a new choice rather than derived from or reduced to prior fitted quantities or self-citations. No load-bearing steps match any of the enumerated circularity patterns, as the work is self-contained as an empirical architectural innovation without internal reductions to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey on legged robots: Advances, technologies and applications,
Z. Wu, K. Zheng, Z. Ding, and H. Gao, “A survey on legged robots: Advances, technologies and applications,”Engineering Applications of Artificial Intelligence, vol. 138, p. 109418, 2024
2024
-
[2]
Advancements in humanoid robots: A comprehensive review and future prospects,
Y . Tong, H. Liu, and Z. Zhang, “Advancements in humanoid robots: A comprehensive review and future prospects,”IEEE/CAA Journal of Automatica Sinica, vol. 11, no. 2, pp. 301–328, 2024
2024
-
[3]
Real-world humanoid locomotion with reinforcement learning,
I. Radosavovic, T. Xiao, B. Zhang, T. Darrell, J. Malik, and K. Sreenath, “Real-world humanoid locomotion with reinforcement learning,”Sci- ence Robotics, vol. 9, no. 89, p. eadi9579, 2024
2024
-
[4]
I. Radosavovic, S. Kamat, T. Darrell, and J. Malik, “Learning humanoid locomotion over challenging terrain,”arXiv preprint arXiv:2410.03654, 2024
-
[5]
Learning vision-based bipedal locomotion for challeng- ing terrain,
H. Duan, B. Pandit, M. S. Gadde, B. Van Marum, J. Dao, C. Kim, and A. Fern, “Learning vision-based bipedal locomotion for challeng- ing terrain,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 56–62
2024
-
[6]
No more blind spots: Learning vision-based omnidirectional bipedal locomotion for challenging terrain,
M. S. Gadde, P. Dugar, A. Malik, and A. Fern, “No more blind spots: Learning vision-based omnidirectional bipedal locomotion for challenging terrain,” in2025 IEEE-RAS 24th International Conference on Humanoid Robots (Humanoids). IEEE, 2025, pp. 601–608
2025
-
[7]
Learning agile locomo- tion on risky terrains,
C. Zhang, N. Rudin, D. Hoeller, and M. Hutter, “Learning agile locomo- tion on risky terrains,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 11 864–11 871
2024
-
[8]
Learn- ing humanoid locomotion with perceptive internal model,
J. Long, J. Ren, M. Shi, Z. Wang, T. Huang, P. Luo, and J. Pang, “Learn- ing humanoid locomotion with perceptive internal model,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 9997–10 003
2025
-
[9]
Attention-based map encoding for learning generalized legged locomo- tion,
J. He, C. Zhang, F. Jenelten, R. Grandia, M. B ¨acher, and M. Hutter, “Attention-based map encoding for learning generalized legged locomo- tion,”Science Robotics, vol. 10, no. 105, p. eadv3604, 2025
2025
-
[10]
Beamdojo: Learning agile humanoid locomotion on sparse footholds
H. Wang, Z. Wang, J. Ren, Q. Ben, T. Huang, W. Zhang, and J. Pang, “Beamdojo: Learning agile humanoid locomotion on sparse footholds,” arXiv preprint arXiv:2502.10363, 2025
-
[11]
Hiking in the wild: A scalable perceptive parkour framework for humanoids,
S. Zhu, Z. Zhuang, M. Zhao, K.-Y . Lee, and H. Zhao, “Hiking in the wild: A scalable perceptive parkour framework for humanoids,”arXiv preprint arXiv:2601.07718, 2026
- [12]
-
[13]
Learning vision-guided quadrupedal locomotion end-to-end with cross-modal transformers,
R. Yang, M. Zhang, N. Hansen, H. Xu, and X. Wang, “Learning vision- guided quadrupedal locomotion end-to-end with cross-modal transform- ers,”arXiv preprint arXiv:2107.03996, 2021
-
[14]
Ame-2: Agile and gen- eralized legged locomotion via attention-based neural map encoding,
C. Zhang, V . Klemm, F. Yang, and M. Hutter, “Ame-2: Agile and gen- eralized legged locomotion via attention-based neural map encoding,” arXiv preprint arXiv:2601.08485, 2026
-
[15]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Conference on Robot Learning. PMLR, 2022, pp. 91–100
2022
-
[16]
Per- ception for humanoid robots,
A. Roychoudhury, S. Khorshidi, S. Agrawal, and M. Bennewitz, “Per- ception for humanoid robots,”Current Robotics Reports, vol. 4, no. 4, pp. 127–140, 2023
2023
-
[17]
Humanoid robot motion planning approaches: a survey,
C. R. de Lima, S. G. Khan, M. Tufail, S. H. Shah, and M. R. Maximo, “Humanoid robot motion planning approaches: a survey,”Journal of Intelligent & Robotic Systems, vol. 110, no. 2, p. 86, 2024
2024
-
[18]
Pie: Parkour with implicit-explicit learning framework for legged robots,
S. Luo, S. Li, R. Yu, Z. Wang, J. Wu, and Q. Zhu, “Pie: Parkour with implicit-explicit learning framework for legged robots,”IEEE Robotics and Automation Letters, 2024
2024
-
[19]
J. Sun, G. Han, P. Sun, W. Zhao, J. Cao, J. Wang, Y . Guo, and Q. Zhang, “Dpl: Depth-only perceptive humanoid locomotion via realistic depth synthesis and cross-attention terrain reconstruction,”arXiv preprint arXiv:2510.07152, 2025
-
[20]
Learning perceptive humanoid locomotion over challenging terrain,
W. Sun, B. Cao, L. Chen, Y . Su, Y . Liu, Z. Xie, and H. Liu, “Learn- ing perceptive humanoid locomotion over challenging terrain,”arXiv preprint arXiv:2503.00692, 2025
-
[21]
Gait-adaptive perceptive humanoid locomotion with real-time under- base terrain reconstruction,
H. Song, H. Zhu, T. Yu, Y . Liu, M. Yuan, W. Zhou, H. Chen, and H. Li, “Gait-adaptive perceptive humanoid locomotion with real-time under- base terrain reconstruction,”arXiv preprint arXiv:2512.07464, 2025
-
[22]
R. Yu, Q. Wang, Y . Wang, Z. Wang, J. Wu, and Q. Zhu, “Walking with terrain reconstruction: Learning to traverse risky sparse footholds,” arXiv preprint arXiv:2409.15692, 2024
-
[23]
Tamols: Terrain- aware motion optimization for legged systems,
F. Jenelten, R. Grandia, F. Farshidian, and M. Hutter, “Tamols: Terrain- aware motion optimization for legged systems,”IEEE Transactions on Robotics, vol. 38, no. 6, pp. 3395–3413, 2022
2022
-
[24]
Per- ceptive locomotion through nonlinear model-predictive control,
R. Grandia, F. Jenelten, S. Yang, F. Farshidian, and M. Hutter, “Per- ceptive locomotion through nonlinear model-predictive control,”IEEE Transactions on Robotics, vol. 39, no. 5, pp. 3402–3421, 2023
2023
-
[25]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Fast-lio: A fast, robust lidar-inertial odometry package by tightly-coupled iterated kalman filter,
W. Xu and F. Zhang, “Fast-lio: A fast, robust lidar-inertial odometry package by tightly-coupled iterated kalman filter,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 3317–3324, 2021
2021
-
[27]
Elevation mapping for locomotion and navigation using gpu,
T. Miki, L. Wellhausen, R. Grandia, F. Jenelten, T. Homberger, and M. Hutter, “Elevation mapping for locomotion and navigation using gpu,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 2273–2280
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.