RoboDream: Compositional World Models for Scalable Robot Data Synthesis
Pith reviewed 2026-06-28 14:05 UTC · model grok-4.3
The pith
Anchoring video generation to rendered robot motion and explicit scene priors produces feasible demonstrations with novel objects and scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
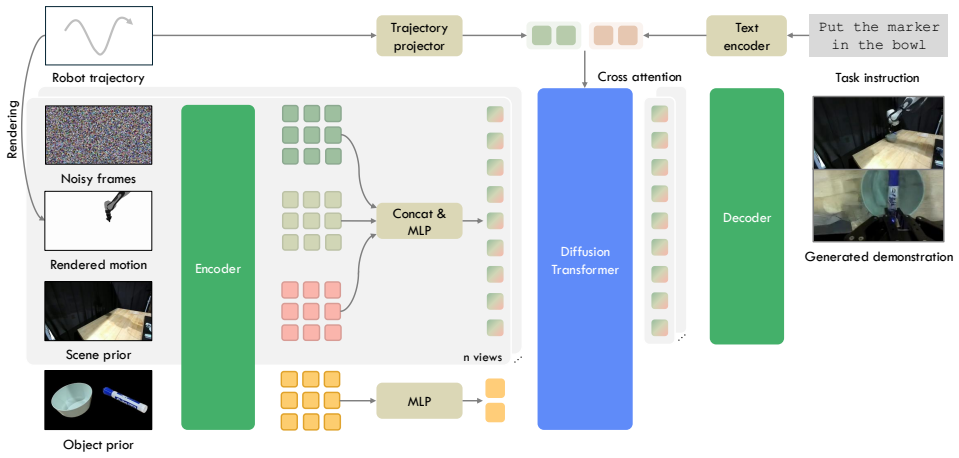
The central claim is that an embodiment-centric world model anchored to rendered robot motion trajectories, while conditioned on explicit scene and object priors, can synthesize photorealistic demonstrations involving novel objects, novel scenes, and novel viewpoints without embodiment hallucinations, thereby decoupling trajectory execution from environment synthesis and unlocking retrieval-rebirth of trajectories plus prop-free teleoperation.
What carries the argument
The compositional world model that anchors generation to rendered robot motion while conditioning on explicit scene and object priors to decouple trajectory from environment.
If this is right
- Existing motion trajectories can be repurposed into entirely new scenes and with new objects without collecting additional motion data.
- Teleoperation can be performed by manipulating empty space, with the model synthesizing the target objects and scene afterward.
- Downstream manipulation policies trained with the generated data achieve higher success rates on real-world tasks.
- The total amount of real-world teleoperated data needed to reach a given policy performance level is substantially reduced.
Where Pith is reading between the lines
- If the anchoring mechanism generalizes, the same separation of motion and scene could be applied to generate variations for multi-step or long-horizon tasks without new demonstrations.
- The method may reduce dependence on full physics simulators by letting the model handle visual and interaction realism once the robot motion is fixed.
- Successful decoupling could allow operators to record motion once and then rapidly populate many different object and scene combinations for dataset expansion.
Load-bearing premise
The generative model produces physically feasible motions and accurate interactions for novel objects and scenes without embodiment hallucinations when conditioned only on the anchored motion and explicit priors.
What would settle it
A controlled test in which policies trained on the generated data are deployed on real robots with the novel objects and scenes and exhibit frequent failures traceable to physically impossible motions or object interactions visible in the generated videos.
Figures





read the original abstract
Scaling robot learning requires large-scale, diverse demonstrations, yet real-world data collection via teleoperation remains prohibitively expensive and time-consuming. While video diffusion models offer a promising avenue for data scaling, existing generative approaches are often limited to superficial visual augmentation, or suffer from embodiment hallucinations that yield physically infeasible motions. We present a generalizable embodiment-centric world model that achieves scalable data generation by synthesizing photorealistic demonstrations with novel objects, in novel scenes, and from novel viewpoints. Our approach anchors generation to rendered robot motion while conditioning on explicit scene and object priors, effectively decoupling trajectory execution from environment synthesis. This formulation has the potential to unlock two powerful data scaling capabilities: (1) retrieval and rebirth, which repurposes existing trajectories into entirely new contexts without new motion data; and (2) prop-free teleoperation, where operators manipulate empty air and the model hallucinates the target objects and scene afterwards, eliminating reset time. We demonstrate with real-world experiments that our generated data consistently improves downstream policy performance and significantly reduces real-world data requirements across diverse manipulation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RoboDream, an embodiment-centric compositional world model for scalable robot data synthesis. It anchors video generation to rendered robot motion while conditioning on explicit scene and object priors, decoupling trajectory execution from environment synthesis. This enables two capabilities: retrieval/rebirth of existing trajectories into new contexts and prop-free teleoperation. The manuscript claims that real-world experiments demonstrate consistent improvements in downstream policy performance and significant reductions in required real-world data across diverse manipulation tasks.
Significance. If the empirical results hold with proper controls, the decoupling strategy could meaningfully advance scalable robot learning by addressing embodiment hallucinations in generative models and reducing teleoperation costs. The approach is internally consistent and directly targets a known failure mode of prior video diffusion methods without relying on self-referential fitting.
major comments (2)
- [Abstract] Abstract: The central claim that 'real-world experiments show consistent policy improvement and significantly reduces real-world data requirements' provides no details on baselines, metrics, number of tasks, statistical significance, embodiment controls, or quantitative effect sizes. This information is load-bearing for evaluating whether the generated data delivers the stated benefits.
- [§5] §5 (Experiments): Without reported comparison tables, ablation studies on the anchoring mechanism, or controls for novel objects/scenes, the assertion that the model avoids embodiment hallucinations while producing physically feasible interactions cannot be verified from the available description.
minor comments (1)
- [Abstract] Abstract: The phrase 'the model hallucinates the target objects' risks terminological confusion with the 'embodiment hallucinations' failure mode discussed earlier; a brief clarification would improve precision.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We address each major comment below and will incorporate revisions to strengthen the presentation of our experimental results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'real-world experiments show consistent policy improvement and significantly reduces real-world data requirements' provides no details on baselines, metrics, number of tasks, statistical significance, embodiment controls, or quantitative effect sizes. This information is load-bearing for evaluating whether the generated data delivers the stated benefits.
Authors: We agree that the abstract would benefit from a concise summary of the experimental validation to support the central claim. In the revised version, we will expand the abstract to briefly note the number of tasks, primary baselines, key metrics, and observed effect sizes while remaining within length limits. Full details remain in §5. revision: yes
-
Referee: [§5] §5 (Experiments): Without reported comparison tables, ablation studies on the anchoring mechanism, or controls for novel objects/scenes, the assertion that the model avoids embodiment hallucinations while producing physically feasible interactions cannot be verified from the available description.
Authors: We acknowledge that §5 would be strengthened by explicit tabular comparisons, ablations, and controls. We will add comparison tables against baselines, ablation studies isolating the anchoring mechanism, and controls for novel objects/scenes to directly support the claims on hallucination avoidance and physical feasibility. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript presents a methodological contribution for data synthesis via anchoring rendered robot motion to explicit scene/object priors, with claims supported by real-world empirical experiments on policy improvement. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The decoupling strategy is a design choice targeting embodiment hallucinations, not a result that reduces to its inputs by construction. The work is self-contained against external benchmarks via demonstrated downstream task performance.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xiaet al., “RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control,” inProceedings of the Conference on Robot Learning (CoRL), 2023
2023
-
[2]
Octo: An Open-Source Generalist Robot Policy
O. M. Team, D. Ghosh, H. R. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, J. Luo, Y . L. Tan, P. R. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine, “Octo: An Open-Source Generalist Robot Policy,”arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Data Scaling Laws in Imitation Learning for Robotic Manipulation,
F. Lin, Y . Hu, P. Sheng, C. Wen, J. You, and Y . Gao, “Data Scaling Laws in Imitation Learning for Robotic Manipulation,” inProceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[4]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset,
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasariet al., “DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset,” inProceedings of the Robotics: Science and Systems (RSS), 2024
2024
-
[5]
π0.5: a vision-language-action model with open-world generaliza- tion,
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, brian ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Wa...
2025
-
[6]
A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation,
TRI LBM Team, “A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation,”Science Robotics, vol. 11, no. 113, 2026
2026
-
[7]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,” inProceedings of the Robotics: Science and Systems (RSS), 2023
2023
-
[8]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,” inProceedings of the Robotics: Science and Systems (RSS), 2023
2023
-
[9]
Video generation models as world simulators,
T. Brooks, B. Peebles, C. Homes, W. DePue, Y . Guo, L. Jing, D. Schnurr, J. Taylor, T. Lugmayr, E. Troyet al., “Video generation models as world simulators,” OpenAI, Tech. Rep., 2024
2024
-
[10]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, “Wan: Open and Advanced Large-Scale Video Generative Models,”arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Scaling Robot Learning with Semantically Imagined Experience,
T. Yu, T. Xiao, A. Stone, J. Tompson, A. Brohan, S. Wang, J. Singh, C. Tan, M. Dee, J. Peralta, B. Ichter, K. Hausman, and F. Xia, “Scaling Robot Learning with Semantically Imagined Experience,” in Proceedings of the Robotics: Science and Systems (RSS), 2023
2023
-
[12]
Robo- Engine: Plug-and-Play Robot Data Augmentation with Semantic Robot Segmentation and Background Generation,
C. Yuan, S. Joshi, S. Zhu, H. Su, H. Zhao, and Y . Gao, “Robo- Engine: Plug-and-Play Robot Data Augmentation with Semantic Robot Segmentation and Background Generation,” inProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
2025
-
[13]
DreamGen: Unlocking Generalization in Robot Learning through Video World Models,
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Lin, L. Magne, A. Mandlekar, A. Narayan, Y . L. Tan, G. Wang, J. Wang, Q. Wang, Y . Xu, X. Zeng, K. Zheng, R. Zheng, M.-Y . Liu, L. Zettlemoyer, D. Fox, J. Kautz, S. Reed, Y . Zhu, and L. Fan, “DreamGen: Unlocking Generalization in Robot Learning through Video Worl...
2025
-
[14]
World Action Models are Zero-shot Policies
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, A. Malik, K. Lee, W. Liang, N. Ranawaka, J. Gu, Y . Xu, G. Wang, F. Hu, A. Narayan, J. Bjorck, J. Wang, G. Kim, D. Niu, R. Zheng, Y . Xie, J. Wu, Q. Wang, R. Julian, D. Xu, Y . Du, Y . Chebotar, S. Reed, J. Kautz, Y . Zhu, L. Fan, and J. Jang, “World Action Model...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
AnchorDream: Repurposing Video Diffusion for Embodiment-Aware Robot Data Synthesis,
J. Ye, R. Xue, B. Van Hoorick, P. Tokmakov, M. Z. Irshad, Y . Wang, and V . Guizilini, “AnchorDream: Repurposing Video Diffusion for Embodiment-Aware Robot Data Synthesis,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[16]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA, “Cosmos World Foundation Model Platform for Physical AI,”arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
S. Gao, W. Liang, K. Zheng, A. Malik, S. Yeet al., “DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos,” arXiv preprint arXiv:2602.06949, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Cosmos-Predict2: General-Purpose World Founda- tion Models for Physical AI,
N. Cosmos, “Cosmos-Predict2: General-Purpose World Founda- tion Models for Physical AI,” https://github.com/nvidia-cosmos/ cosmos-predict2, 2025, apache License 2.0, accessed June 2, 2026
2025
-
[19]
RoVi-Aug: Robot and Viewpoint Augmentation for Cross-Embodiment Robot Learning,
L. Y . Chen, C. Xu, K. Dharmarajan, M. Z. Irshad, R. Cheng, K. Keutzer, M. Tomizuka, Q. Vuong, and K. Goldberg, “RoVi-Aug: Robot and Viewpoint Augmentation for Cross-Embodiment Robot Learning,” inProceedings of the Conference on Robot Learning (CoRL), 2024
2024
-
[20]
OXE-AugE: A Large-Scale Robot Aug- mentation of OXE for Scaling Cross-Embodiment Policy Learning,
G. Ji, H. Polavaram, L. Y . Chen, S. Bajamahal, Z. Ma, S. Adebola, C. Xu, and K. Goldberg, “OXE-AugE: A Large-Scale Robot Aug- mentation of OXE for Scaling Cross-Embodiment Policy Learning,” inProceedings of the International Conference on Machine Learning (ICML), 2026
2026
-
[21]
RoboVIP: Multi-View Video Generation with Visual Identity Prompting Augments Robot Manipulation,
B. Wang, H. Zhang, S. Zhang, J. Hao, M. Jia, Q. Lv, Y . Mao, Z. Lyu, J. Zeng, X. Xu, and J. Pang, “RoboVIP: Multi-View Video Generation with Visual Identity Prompting Augments Robot Manipulation,”arXiv preprint arXiv:2601.05241, 2026
-
[22]
RoboTransfer: Controllable Geometry- Consistent Video Diffusion for Manipulation Policy Transfer,
L. Liu, X. Wang, G. Zhao, K. Li, W. Qin, J. Zhu, J. Qiu, Z. Zhu, G. Huang, and Z. Su, “RoboTransfer: Controllable Geometry- Consistent Video Diffusion for Manipulation Policy Transfer,”arXiv preprint arXiv:2505.23171, 2025
-
[23]
ReBot: Scaling Robot Learning with Real-to-Sim-to-Real Robotic Video Synthesis,
Y . Fang, Y . Yang, X. Zhu, K. Zheng, G. Bertasius, D. Szafir, and M. Ding, “ReBot: Scaling Robot Learning with Real-to-Sim-to-Real Robotic Video Synthesis,” inProceedings of the IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS), 2025
2025
-
[24]
World Simulation with Video Foundation Models for Physical AI
A. Ali, J. Bai, M. Bala, Y . Balajiet al., “World Simulation with Video Foundation Models for Physical AI,”arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Novel Demonstration Generation with Gaussian Splatting Enables Robust One-Shot Manipulation,
S. Yang, W. Yu, J. Zeng, J. Lv, K. Ren, C. Lu, D. Lin, and J. Pang, “Novel Demonstration Generation with Gaussian Splatting Enables Robust One-Shot Manipulation,” inProceedings of the Robotics: Science and Systems (RSS), 2025
2025
-
[26]
AnyView: Synthesizing Any Novel View in Dynamic Scenes,
B. V . Hoorick, D. Chen, S. Iwase, P. Tokmakov, M. Z. Irshad, I. Vasiljevic, S. Gupta, F. Cheng, S. Zakharov, and V . C. Guizilini, “AnyView: Synthesizing Any Novel View in Dynamic Scenes,”arXiv preprint arXiv:2601.16982, 2026
-
[27]
MimicGen: A Data Generation System for Scal- able Robot Learning using Human Demonstrations,
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox, “MimicGen: A Data Generation System for Scal- able Robot Learning using Human Demonstrations,” inProceedings of the Conference on Robot Learning (CoRL), 2023
2023
-
[28]
Real2Render2Real: Scaling Robot Data Without Dynamics Simulation or Robot Hardware,
J. Yu, L. Fu, H. Huang, K. El-Refai, R. A. Ambrus, R. Cheng, M. Z. Irshad, and K. Goldberg, “Real2Render2Real: Scaling Robot Data Without Dynamics Simulation or Robot Hardware,” inProceedings of the Conference on Robot Learning (CoRL), 2025
2025
-
[29]
Demogen: Synthetic demonstration generation for data-efficient visuomotor pol- icy learning,
Z. Xue, S. Deng, Z. Chen, Y . Wang, Z. Yuan, and H. Xu, “Demogen: Synthetic demonstration generation for data-efficient visuomotor pol- icy learning,” inProceedings of the Robotics: Science and Systems (RSS), 2025
2025
-
[30]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,”Journal of Ma- chine Learning Research, vol. 21, no. 140, pp. 1–67, 2020
2020
-
[31]
OpenAI, “OpenAI GPT-5 System Card,”arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
T. Ren, S. Liu, A. Zeng, J. Lin, K. Li, H. Cao, J. Chen, X. Huang, Y . Chen, F. Yan, Z. Zeng, H. Zhang, F. Li, J. Yang, H. Li, Q. Jiang, and L. Zhang, “Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks,”arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
OmniPaint: Mastering Object- Oriented Editing via Disentangled Insertion-Removal Inpainting,
Y . Yu, Z. Zeng, H. Zheng, and J. Luo, “OmniPaint: Mastering Object- Oriented Editing via Disentangled Insertion-Removal Inpainting,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.