Wavelet as Tokenizer: Preliminary Results on a Shared Wavelet Token Schema for Natural Signals
Pith reviewed 2026-06-28 18:03 UTC · model grok-4.3
The pith
A single wavelet token schema can represent audio, images, and video with competitive reconstruction quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
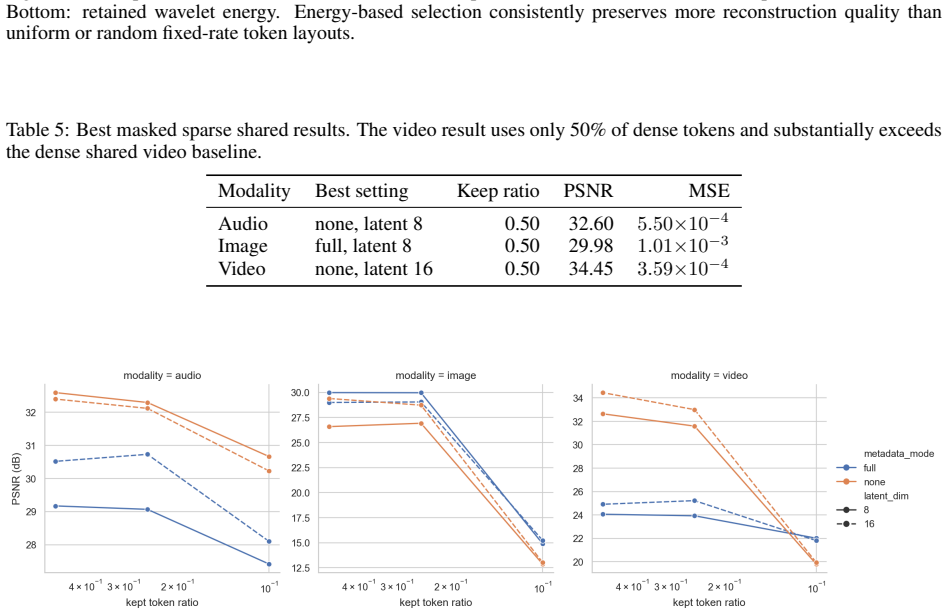
A continuous-token model built on a shared one-level Haar DWT/IDWT frontend and token-wise trunk reaches 39.92 dB PSNR on audio, 29.37 dB on images, and 23.93 dB on video, with masked sparse training maintaining 34.45 dB video PSNR at 50 percent of dense tokens.
What carries the argument
The shared coefficient-token layout with one-level Haar DWT frontend, optional metadata embeddings, modality value adapters, and shared trunk that processes tokens from any of the three modalities interchangeably.
If this is right
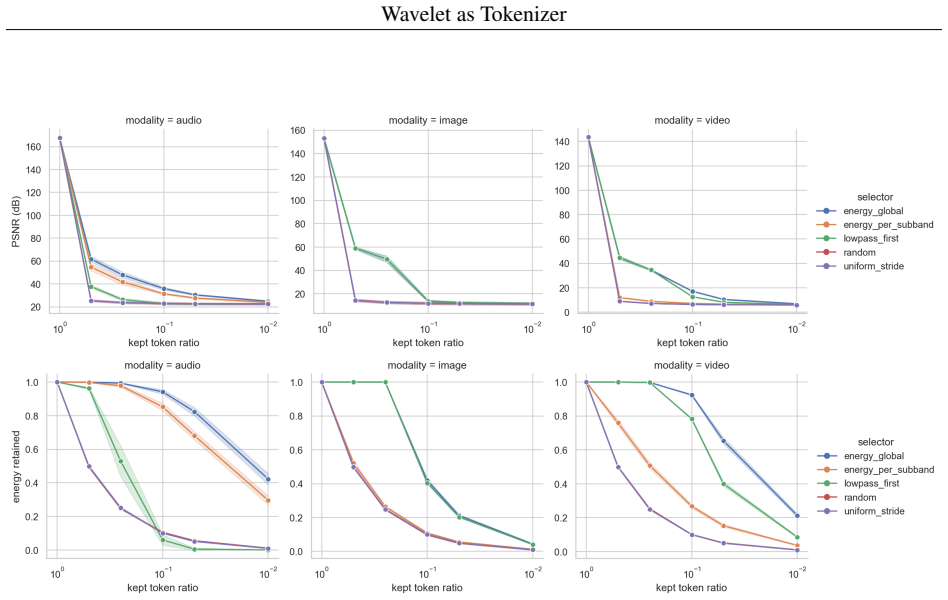
- Energy_global selection improves average PSNR by 16.73 dB for audio, 16.90 dB for images, and 15.86 dB for video over uniform selection under compressed keep ratios.
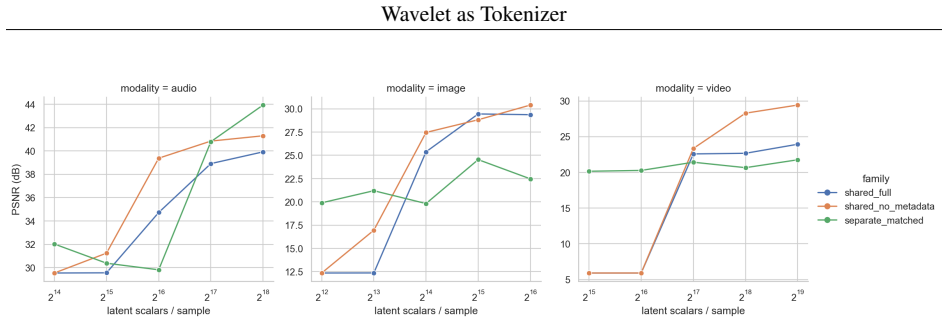
- Visual gains persist after controlling for latent capacity in matched-rate sweeps.
- Masked sparse training preserves 34.45 dB video PSNR while using only 50 percent of dense tokens.
Where Pith is reading between the lines
- The schema could support cross-modal pretraining where tokens from one signal type initialize processing for another.
- Extending the frontend to multiple wavelet levels might increase compression efficiency without losing the shared-trunk property.
- Replacing the continuous scalars with a learned discrete codebook on top of the same layout would test whether a universal vocabulary emerges naturally.
Load-bearing premise
The specific datasets and continuous-token PSNR metric are sufficient to indicate that a shared wavelet schema will be useful for natural signals in general.
What would settle it
An experiment on the same datasets showing that modality-specific wavelet frontends or trunks achieve substantially higher PSNR than the shared version at matched rates would falsify the unification benefit.
Figures
read the original abstract
This paper studies whether audio, images, and video can share a common wavelet token schema rather than relying on separate modality-specific latent grids. It introduces a preliminary continuous-token model built around a one-level Haar DWT/IDWT frontend, a shared coefficient-token layout, optional structural metadata, lightweight modality value adapters, and a shared token-wise encoder-decoder trunk. On Speech Commands, EuroSAT RGB, and DAVIS 2017 data, a dense shared model reaches 39.92 dB audio, 29.37 dB image, and 23.93 dB video PSNR. A matched-rate sweep under continuous latent scalar budgets indicates that the visual gains are not explained solely by latent capacity, while also showing that additive metadata embeddings are not a universal source of improvement. Finally, fixed-rate energy selection provides a strong non-parametric baseline: energy_global improves average PSNR over uniform selection by 16.73 dB for audio, 16.90 dB for images, and 15.86 dB for video under compressed keep ratios. Masked sparse training reaches 34.45 dB video PSNR with 50% of dense tokens. The results support a unified wavelet token schema and sparse token interface, while stopping short of establishing a universal discrete vocabulary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a preliminary continuous-token model for a shared wavelet token schema across audio, images, and video, using a one-level Haar DWT/IDWT frontend, shared coefficient-token layout, optional structural metadata, lightweight modality value adapters, and a shared token-wise encoder-decoder trunk. On Speech Commands, EuroSAT RGB, and DAVIS 2017, it reports PSNR of 39.92 dB (audio), 29.37 dB (image), and 23.93 dB (video) for a dense shared model; a matched-rate sweep under continuous latent scalar budgets; fixed-rate energy selection as a non-parametric baseline (improving average PSNR by ~16 dB across modalities at compressed keep ratios); and masked sparse training reaching 34.45 dB video PSNR at 50% token density. The results are presented as supporting a unified wavelet token schema and sparse token interface, while explicitly stopping short of a universal discrete vocabulary.
Significance. If the advantage of cross-modality weight sharing can be isolated and quantified, the approach could provide a practical unified frontend for tokenizing natural signals, enabling shared sparse interfaces and potentially simplifying multimodal architectures. The energy baseline and matched-rate controls are useful empirical anchors, and the explicit acknowledgment of the gap to discrete vocabularies is appropriately cautious. At present the work demonstrates architectural feasibility more than comparative superiority of sharing.
major comments (2)
- [Abstract / Experiments] The central claim that the results support a 'unified wavelet token schema' (shared trunk) is undercut by the absence of modality-specific non-shared baselines. All reported models employ the shared trunk plus adapters; no equivalent-capacity per-modality models (identical wavelet frontend and trunk architecture but with separate, non-shared weights) are provided. The matched-rate sweep controls latent dimension but does not isolate the effect of weight sharing, leaving the benefit of unification unquantified (see abstract and experimental results).
- [Abstract] The reported PSNR values and sweep conclusions lack error bars, standard deviations, or details on the number of runs, making it difficult to assess whether the visual gains independent of latent capacity are statistically reliable or sensitive to initialization (abstract).
minor comments (2)
- [Abstract] Implementation details for the energy_global baseline (e.g., exact coefficient selection rule, handling of structural metadata) are referenced but not fully specified, hindering reproducibility.
- [Abstract] The manuscript would benefit from explicit discussion of why the chosen datasets (Speech Commands, EuroSAT RGB, DAVIS 2017) and the continuous-token PSNR metric are expected to generalize to other natural signals.
Simulated Author's Rebuttal
We thank the referee for the constructive review of our preliminary work. We address each major comment below and describe the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract / Experiments] The central claim that the results support a 'unified wavelet token schema' (shared trunk) is undercut by the absence of modality-specific non-shared baselines. All reported models employ the shared trunk plus adapters; no equivalent-capacity per-modality models (identical wavelet frontend and trunk architecture but with separate, non-shared weights) are provided. The matched-rate sweep controls latent dimension but does not isolate the effect of weight sharing, leaving the benefit of unification unquantified (see abstract and experimental results).
Authors: We agree that the current experiments do not isolate the effect of weight sharing. No modality-specific non-shared baselines with matched capacity are reported, and the matched-rate sweep addresses latent dimension rather than parameter sharing. In the revised manuscript we will update the abstract and the discussion of results to state that the work demonstrates architectural feasibility of the shared schema rather than a quantified advantage of unification. This limitation will also be noted as future work. revision: yes
-
Referee: [Abstract] The reported PSNR values and sweep conclusions lack error bars, standard deviations, or details on the number of runs, making it difficult to assess whether the visual gains independent of latent capacity are statistically reliable or sensitive to initialization (abstract).
Authors: We acknowledge that the reported PSNR values are from single training runs and lack error bars or run counts. In the revision we will update the abstract to indicate that the values are single-run results and add a corresponding note in the experimental section describing the preliminary nature of the study. Multiple runs with standard deviations will be included in future extensions of the work. revision: yes
Circularity Check
No circularity; empirical results are self-contained
full rationale
The paper defines a wavelet-based tokenizer architecture (one-level Haar DWT/IDWT frontend, shared coefficient layout, modality adapters, shared trunk) and reports PSNR on held-out data from Speech Commands, EuroSAT RGB, and DAVIS 2017. No derivation, equation, or claim reduces a reported result to a fitted parameter by construction, nor invokes self-citation for a uniqueness theorem or ansatz. Energy selection and masked sparse training are presented as non-parametric baselines and empirical variants, respectively. The central claims rest on direct comparisons against external benchmarks rather than tautological redefinitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- modality value adapters
Reference graph
Works this paper leans on
-
[1]
Junke Wang, Yi Jiang, Zehuan Yuan, Binyue Peng, Zuxuan Wu, and Yu-Gang Jiang. Omnitokenizer: A joint image-video tokenizer for visual generation.arXiv preprint arXiv:2406.09399, 2024
-
[2]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Neural discrete representation learning
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. InAd- vances in Neural Information Processing Systems, volume 30, 2017
2017
-
[4]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bj ¨orn Ommer. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12873–12883, 2021
2021
-
[5]
Hauptmann, Ming-Hsuan Yang, Yuan Hao, Irfan Essa, and Lu Jiang
Lijun Yu, Yong Cheng, Kihyuk Sohn, Jos ´e Lezama, Han Zhang, Huiwen Chang, Alexander G. Hauptmann, Ming-Hsuan Yang, Yuan Hao, Irfan Essa, and Lu Jiang. Magvit: Masked generative video transformer.arXiv preprint arXiv:2212.05199, 2022
-
[6]
Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Vigh- nesh Birodkar, Agrim Gupta, Xiuye Gu, Alexander G
Lijun Yu, Jos ´e Lezama, Nitesh B. Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Vigh- nesh Birodkar, Agrim Gupta, Xiuye Gu, Alexander G. Hauptmann, Boqing Gong, Ming-Hsuan Yang, Irfan Essa, David A. Ross, and Lu Jiang. Language model beats diffusion—tokenizer is key to visual generation. In International Conference on Learning Represe...
2024
-
[7]
Wavelet-based image tokenizer for vision transformers.arXiv preprint arXiv:2405.18616, 2024
Zhenhai Zhu and Radu Soricut. Wavelet-based image tokenizer for vision transformers.arXiv preprint arXiv:2405.18616, 2024
-
[8]
Stephane G. Mallat. A theory for multiresolution signal decomposition: The wavelet representation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 11(7):674–693, 1989
1989
-
[9]
Taubman and Michael W
David S. Taubman and Michael W. Marcellin. JPEG2000: Standard for interactive imaging.Proceedings of the IEEE, 90(8):1336–1357, 2002
2002
-
[10]
Soundstream: An end-to-end neural audio codec.arXiv preprint arXiv:2107.03312, 2021
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. Soundstream: An end-to-end neural audio codec.arXiv preprint arXiv:2107.03312, 2021
-
[11]
High Fidelity Neural Audio Compression
Alexandre D ´efossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression. arXiv preprint arXiv:2210.13438, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Wavtokenizer: An efficient acoustic discrete codec tokenizer for audio language modeling
Shengpeng Ji, Ziyue Jiang, Wen Wang, Yifu Chen, Minghui Fang, Jialong Zuo, Qian Yang, Xize Cheng, Zehan Wang, Ruiqi Li, et al. Wavtokenizer: An efficient acoustic discrete codec tokenizer for audio language modeling. arXiv preprint arXiv:2408.16532, 2024
-
[13]
Finite scalar quantization: Vq-vae made simple
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: Vq-vae made simple. InInternational Conference on Learning Representations, 2024
2024
-
[14]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 586–595, 2018
2018
-
[15]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[16]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Syl- vain Gelly. Towards accurate generative models of video: A new metric and challenges.arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
3d gaussian splatting for real- time radiance field rendering.ACM Transactions on Graphics, 42(4):139:1–139:14, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real- time radiance field rendering.ACM Transactions on Graphics, 42(4):139:1–139:14, 2023
2023
-
[18]
Joo Chan Lee, Daniel Rho, Xiangyu Sun, Jong Hwan Ko, and Eunbyung Park. Compact 3d gaussian splatting for static and dynamic radiance fields.arXiv preprint arXiv:2408.03822, 2024
-
[19]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
Pete Warden. Speech commands: A dataset for limited-vocabulary speech recognition.arXiv preprint arXiv:1804.03209, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019
2019
-
[21]
The 2017 DAVIS Challenge on Video Object Segmentation
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbel ´aez, Alexander Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017. 11 Wavelet as Tokenizer A Experimental Details A.1 Data Preprocessing The experiments use Speech Commands v0.02, EuroSAT RGB, and DA VIS 2017 train/va...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.