SeeTraceAct: Visibility-Aware Latent Planning from Cross-Embodiment Demonstration Videos
Pith reviewed 2026-06-28 13:59 UTC · model grok-4.3
The pith
SeeTraceAct improves one-shot demo-conditioned VLAs by predicting visibility-aware future end-effector traces for precise spatial grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
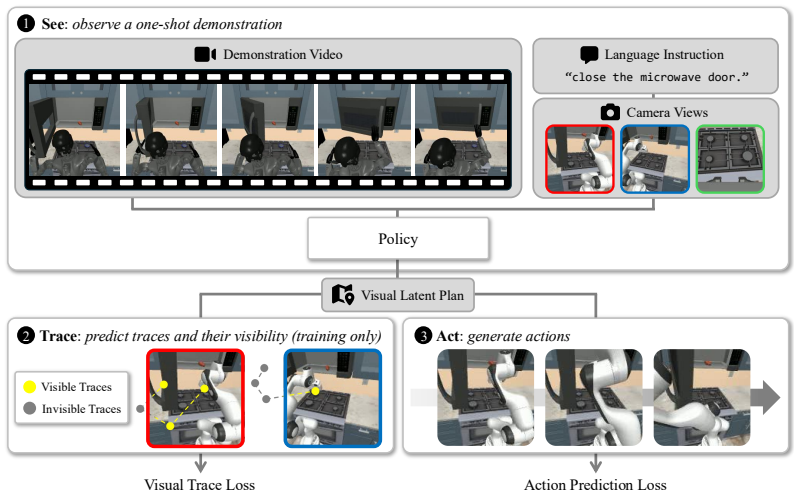
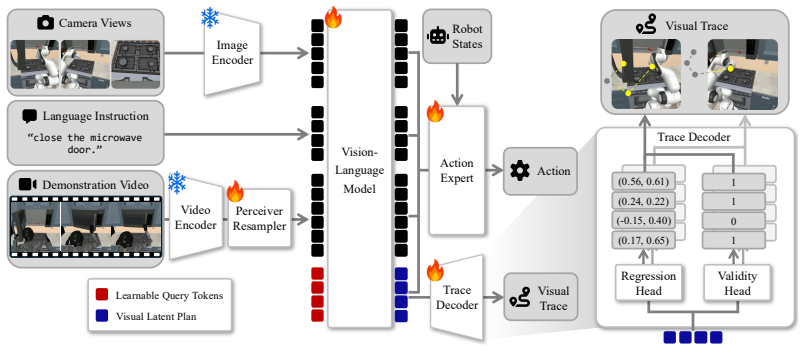
SeeTraceAct is a demo-conditioned VLA framework that encourages precise spatial grounding through visibility-aware prediction of future end-effector traces, outperforming prior end-to-end approaches on tasks that require localizing small targets when conditioned on a single cross-embodiment demonstration video.
What carries the argument
Visibility-aware prediction of future end-effector traces, which supplies an auxiliary supervision signal for spatial grounding inside the latent planning process of the VLA.
If this is right
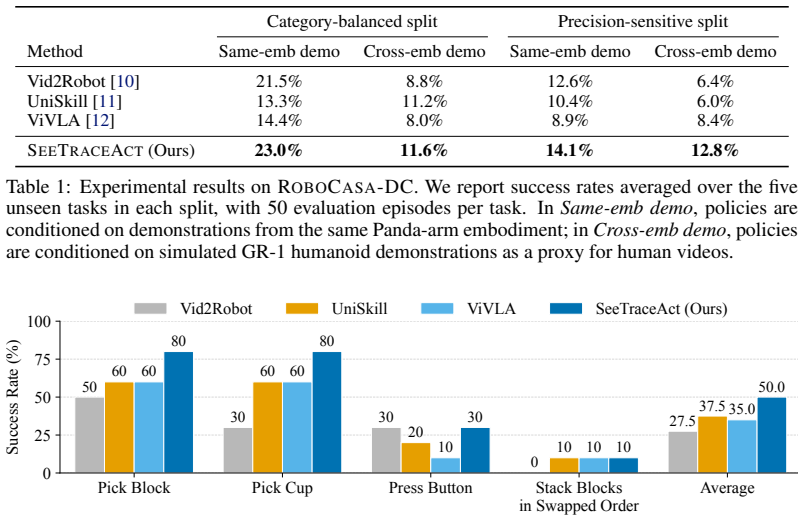
- SeeTraceAct records the highest success rate in every one of the four RoboCasa-DC evaluation settings.
- Conditioning a real Franka Panda arm on human demonstration videos raises average success by 12.5 percentage points.
- The method supports one-shot adaptation to new tasks without collecting task-specific teleoperation data.
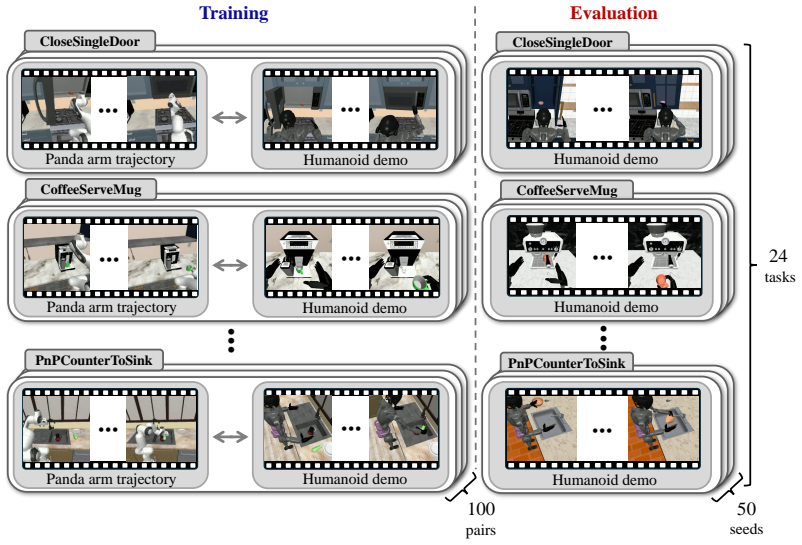
- RoboCasa-DC provides a reproducible testbed for cross-embodiment demo-conditioned policies.
Where Pith is reading between the lines
- Adding explicit trace prediction could generalize to multi-step manipulation sequences where cumulative localization errors compound.
- The visibility-aware auxiliary loss might reduce reliance on large volumes of embodiment-specific data by transferring spatial cues across robots and humans.
- Similar trace-based grounding signals could be tested in other latent planners that currently rely solely on image or language conditioning.
Load-bearing premise
The primary shortcoming of existing end-to-end demo-conditioned VLAs is insufficient precise spatial grounding that can be fixed by adding visibility-aware future end-effector trace prediction.
What would settle it
A controlled comparison on the RoboCasa-DC tasks where SeeTraceAct shows no improvement over a baseline VLA that lacks the trace-prediction head, or where another spatial-grounding technique without traces matches or exceeds its success rates.
Figures



read the original abstract
Vision-language-action models (VLAs) are promising general-purpose robot policies, but adapting them to new tasks typically requires costly task-specific teleoperation data. As an alternative, we study one-shot demo-conditioned VLAs, where a robot policy is conditioned on a single demonstration video of an unseen task. We find that existing end-to-end approaches often struggle when successful execution requires precisely localizing small target regions. To address this limitation, we propose SeeTraceAct, a demo-conditioned VLA framework that encourages precise spatial grounding through visibility-aware prediction of future end-effector traces. To enable reproducible evaluation with cross-embodiment demonstrations, we introduce and release RoboCasa-DC, a demo-conditioned extension of RoboCasa with episode-paired humanoid videos. Experiments on RoboCasa-DC and a real-world benchmark, where a Franka Panda arm is conditioned on human demonstrations, show that SeeTraceAct outperforms baselines, achieving the best success rate across all four RoboCasa-DC settings and improving real-world average success by 12.5 percentage points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SeeTraceAct, a demo-conditioned VLA framework that adds visibility-aware prediction of future end-effector traces to encourage precise spatial grounding when adapting to new tasks from a single cross-embodiment demonstration video. It introduces the RoboCasa-DC dataset (episode-paired humanoid videos) for reproducible evaluation and reports that SeeTraceAct achieves the highest success rate on all four RoboCasa-DC settings while improving real-world average success by 12.5 percentage points on a Franka Panda arm conditioned on human demos.
Significance. If the reported gains hold under full scrutiny of methods and ablations, the work would demonstrate a lightweight, additive mechanism for improving localization in one-shot VLA policies without requiring new task-specific teleoperation data, potentially easing deployment of generalist robot policies.
minor comments (1)
- The abstract states that existing end-to-end approaches 'often struggle' with small target regions but provides no quantitative breakdown or example failure cases to support this diagnosis.
Simulated Author's Rebuttal
We thank the referee for their summary of SeeTraceAct and for noting its potential significance as a lightweight addition to demo-conditioned VLAs. The report lists no specific major comments, so we provide no point-by-point responses below. We remain available to supply further details on the RoboCasa-DC dataset, trace-prediction ablations, or real-world Franka experiments if the editor or referee requests them.
Circularity Check
No significant circularity detected
full rationale
The paper introduces SeeTraceAct as an additive component to existing demo-conditioned VLAs, using visibility-aware future end-effector trace prediction to improve spatial grounding. No equations, parameter-fitting procedures, self-citations, or derivation chains are present in the abstract or summary that would reduce any claimed result to its own inputs by construction. The central claims are empirical performance gains on RoboCasa-DC and real-world benchmarks, which are not mathematical derivations and thus cannot exhibit the enumerated circularity patterns. The method is presented as an extension without load-bearing self-referential steps or uniqueness theorems.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
WatchAct: A Benchmark for Behavior-Grounded Robot Manipulation
WatchAct is a new benchmark of 3000 instances across 14 tasks in four cognitive domains for evaluating video-grounded robot manipulation, with current systems achieving at most 16.3% success.
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π0: A vision-language-action flow model for general robot control.ArXiv, abs/2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, G. Lam, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model. ArXiv, abs/2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z.-T. Xu, S. Ye, Z...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
H. R. Walke, K. Black, A. Lee, M. J. Kim, M. Du, C. Zheng, T. Zhao, P. Hansen-Estruch, Q. H. Vuong, A. W. He, V . Myers, K. Fang, C. Finn, and S. Levine. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning (CoRL), 2023
2023
-
[5]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . Ma, P. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Ra- dosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. Lu, J.-...
2024
-
[6]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Herzog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakrishna, A. Wahid, B. Burgess-Limerick, B. Kim, B. Sch ¨olkopf,...
2024
-
[7]
S. Park, H. Bharadhwaj, and S. Tulsiani. Demodiffusion: One-shot human imitation using pre-trained diffusion policy. InIEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[8]
J. Li, Y . Zhu, Y . Xie, Z. Jiang, M. Seo, G. Pavlakos, and Y . Zhu. Okami: Teaching humanoid robots manipulation skills through single video imitation. InConference on Robot Learning (CoRL), 2024
2024
-
[9]
Heppert, M
N. Heppert, M. Argus, T. Welschehold, T. Brox, and A. Valada. Ditto: Demonstration imitation by trajectory transformation. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
2024
-
[10]
V . Jain, M. Attarian, N. J. Joshi, A. Wahid, D. Driess, Q. Vuong, P. R. Sanketi, P. Sermanet, S. Welker, C. Chan, I. Gilitschenski, Y . Bisk, and D. Dwibedi. Vid2robot: End-to-end video- conditioned policy learning with cross-attention transformers. InRobotics: Science and Sys- tems (RSS), 2024
2024
-
[11]
H. Kim, J. Kang, H. Kang, M. Cho, S. J. Kim, and Y . Lee. Uniskill: Imitating human videos via cross-embodiment skill representations. InConference on Robot Learning (CoRL), 2025
2025
- [12]
-
[13]
Nasiriany, A
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots. InRobotics: Science and Systems (RSS), 2024
2024
-
[14]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. C. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Man- junath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Per...
2023
-
[15]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, K. Choromanski, T. Ding, D. Driess, K. A. Dubey, C. Finn, P. R. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. J. Joshi, R. C. Julian, D. Kalashnikov, Y . Kuang, I. Leal, S. Levine, H. Michalewski, I. Mordatch, K. Pertsch, K. Rao, K. Reymann, ...
2023
-
[16]
M. Xu, Z. Xu, C. Chi, M. Veloso, and S. Song. Xskill: Cross embodiment skill discovery. In Conference on Robot Learning (CoRL), 2023
2023
-
[17]
D. Niu, Y . Sharma, G. Biamby, J. Quenum, Y . Bai, B. Shi, T. Darrell, and R. Herzig. Llarva: Vision-action instruction tuning enhances robot learning. InConference on Robot Learning (CoRL), 2024
2024
-
[18]
J. Lee, J. Duan, H. Fang, Y . Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y . R. Wang, S. Lee, W. Han, W. Pumacay, A. Wu, R. Hendrix, K. Farley, E. VanderBilt, A. Farhadi, D. Fox, and R. Krishna. Molmoact: Action reasoning models that can reason in space.ArXiv, abs/2508.07917, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
J. Gu, S. Kirmani, P. Wohlhart, Y . Lu, M. Gonzalez Arenas, K. Rao, W. Yu, C. Fu, K. Gopalakr- ishnan, Z. Xu, P. Sundaresan, P. Xu, H. Su, K. Hausman, Q. Vuong, and T. Xiao. Rt-trajectory: Robotic task generalization via hindsight trajectory sketches. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[20]
Y . Li, Y . Deng, J. Zhang, J. Jang, M. Memmel, R. Yu, C. R. Garrett, F. Ramos, D. Fox, A. Li, A. Gupta, and A. Goyal. Hamster: Hierarchical action models for open-world robot manipulation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[21]
Zheng, Y
R. Zheng, Y . Liang, S. Huang, J. Gao, H. Daum’e, A. Kolobov, F. Huang, and J. Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[22]
Huang, Y .-H
C.-P. Huang, Y .-H. Wu, M.-H. Chen, Y .-C. F. Wang, and F.-E. Yang. Thinkact: Vision- language-action reasoning via reinforced visual latent planning. InNeural Information Pro- cessing Systems (NeurIPS), 2025
2025
-
[23]
Huang, Y
C.-P. Huang, Y . Man, Z. Yu, M.-H. Chen, J. Kautz, Y .-C. F. Wang, and F.-E. Yang. Fast- thinkact: Efficient vision-language-action reasoning via verbalizable latent planning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[24]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Komeili, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, S. Arnaud, A. Gejji, A. Martin, F. Robert Hogan, D. Dugas, P. Bojanowski, V . Khalidov, P. Labatut, F. Massa, M. Szafraniec, K. Krishnakumar, Y . Li, X. Ma, S. Chandar, F. Meier, Y . LeCun, M. Rabbat, and N. Ballas. V-jepa 2: Self-supervi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
something something
R. Goyal, S. E. Kahou, V . Michalski, J. Materzynska, S. Westphal, H. Kim, V . Haenel, I. Fr¨und, P. N. Yianilos, M. Mueller-Freitag, F. Hoppe, C. Thurau, I. Bax, and R. Memisevic. The “something something” video database for learning and evaluating visual common sense. In IEEE/CVF International Conference on Computer Vision (ICCV), 2017
2017
-
[26]
W. Kay, J. Carreira, K. Simonyan, B. H. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, A. Natsev, M. Suleyman, and A. Zisserman. The kinetics human action video dataset.ArXiv, abs/1705.06950, 2017. 12
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Alayrac, J
J. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds, R. Ring, E. Rutherford, S. Cabi, T. Han, Z. Gong, S. Samangooei, M. Monteiro, J. L. Menick, S. Borgeaud, A. Brock, A. Nematzadeh, S. Sharifzadeh, M. Binkowski, R. Bar- reira, O. Vinyals, A. Zisserman, and K. Simonyan. Flamingo: a visual language mo...
2022
-
[28]
Jaegle, F
A. Jaegle, F. Gimeno, A. Brock, O. Vinyals, A. Zisserman, and J. Carreira. Perceiver: General perception with iterative attention. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[29]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[30]
T. Yu, D. Quillen, Z. He, R. C. Julian, K. Hausman, C. Finn, and S. Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on Robot Learning (CoRL), 2019
2019
-
[31]
Goyal, V
A. Goyal, V . Blukis, J. Xu, Y . Guo, Y .-W. Chao, and D. Fox. Rvt2: Learning precise manipu- lation from few demonstrations. InRobotics: Science and Systems (RSS), 2024
2024
-
[32]
Y . Yin, Z. Han, S. Aarya, S. Xu, J. Wang, J. Peng, A. Wang, A. Yuille, and T. Shu. Partinstruct: Part-level instruction following for fine-grained robot manipulation. InRobotics: Science and Systems (RSS), 2025
2025
-
[33]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre- training. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[34]
Grab the coke can and lift it up
S. Ye, J. Jang, B. Jeon, S. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, et al. Latent action pretraining from videos. InInternational Conference on Learning Representations (ICLR), 2025. 13 A Benchmark Details A.1 RoboCasa-DC To collect GR-1 humanoid demonstrations, we restore the initial simulation state of each pre-defined Pand...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.