SCOPE: Real-Time Natural Language Camera Agent at the Edge
Pith reviewed 2026-06-28 13:50 UTC · model grok-4.3
The pith
Stronger small language models reduce hallucinations in edge PTZ camera agents once perception becomes the main limit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SCOPE demonstrates that sufficiently capable small language models paired with mixture-of-experts vision models deliver reliable closed-loop natural language PTZ camera control at the edge, where perception becomes the dominant performance bottleneck after language planning quality is adequate.
What carries the argument
The SCOPE agent architecture that routes natural language instructions through an SLM planner to callable perception and control tools, evaluated locally on edge compute in Blender simulation and on physical PTZ hardware.
If this is right
- Stronger SLMs substantially reduce hallucinations and improve tool routing for more reliable closed-loop behavior.
- Perception becomes the dominant performance bottleneck once a sufficiently capable SLM is in use.
- Mixture-of-experts models on planning and perception sides match or exceed dense alternatives at similar latencies and memory footprints.
- Quantization provides additional efficiency gains with minimal accuracy degradation.
Where Pith is reading between the lines
- Further gains in similar language-driven edge robotics may come from targeted improvements to perception models rather than planner size.
- The modular tool-calling design could transfer to other edge devices that combine natural language with camera-based control.
- The 536-task benchmark offers a reusable testbed for comparing future SLM-VLM combinations under realistic latency and error constraints.
Load-bearing premise
The Blender simulation and 536-task benchmark accurately capture the error modes, latency constraints, and task distributions of real-world PTZ camera deployments on edge hardware.
What would settle it
Running the full set of 536 tasks on physical PTZ hardware and measuring substantially higher hallucination rates, different dominant error modes, or latency profiles that diverge from the simulation results.
Figures
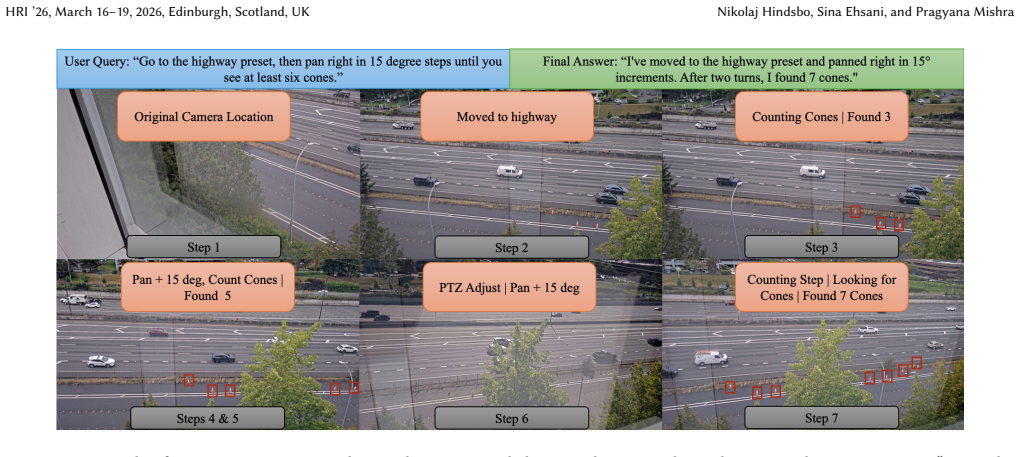
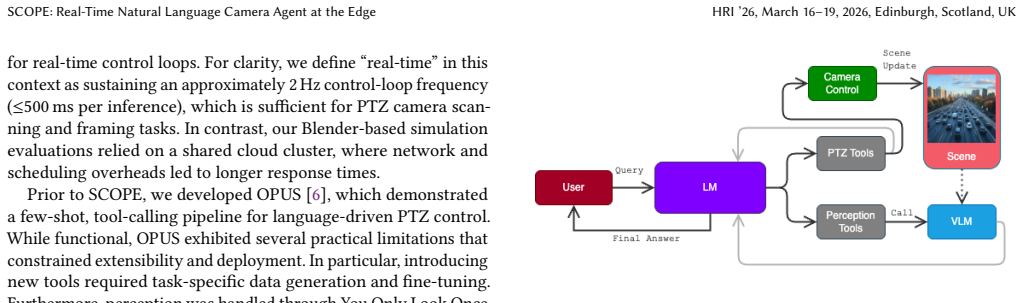

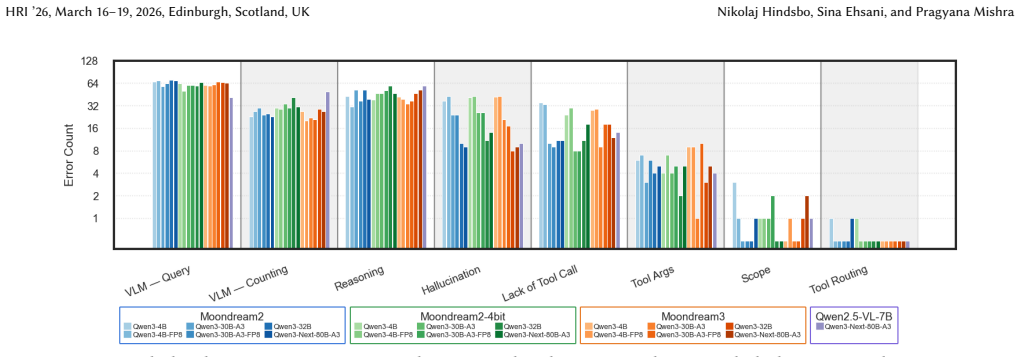
read the original abstract
Deploying language-driven agents in robotics requires evaluations that reflect real-world task demands: natural-language instructions with reproducible outcomes. Such agents must connect language models to callable perception and control tools, and be assessed using deployment-critical metrics including latency, accuracy, and error modes. We present SCOPE (Simulation and Camera Operations for Perception and Evaluation), a modular agent for natural-language, open-vocabulary pan-tilt-zoom (PTZ) camera control and visual scene understanding, designed explicitly for edge deployment. SCOPE operates both in a Blender-based simulation environment and on a physical PTZ camera, executing all perception, planning, and control locally at the deployment site using edge-accessible compute. We release a 536-task benchmark spanning QA, single- and multi-step commands, counting, spatial reasoning, descriptions, and optical character recognition in a Blender-based simulation environment that exposes realistic PTZ control affordances. Execution traces are combined with an LM-as-Judge to evaluate latency, accuracy, and error modes. We evaluate 19 planner-perception model combinations pairing Qwen3 small language models (SLMs) with Moondream and Qwen vision-language models (VLMs). Stronger SLMs substantially reduce hallucinations and improve tool routing, leading to more reliable closed-loop behavior. Once a sufficiently capable SLM is used, perception becomes the dominant performance bottleneck. Mixture-of-Experts models on both the planning and perception side consistently match or exceed dense alternatives at latencies and memory footprints comparable to much smaller networks. Quantization provides additional efficiency gains with minimal accuracy degradation, identifying a practical, sim-to-real validated design point for real-time, edge-feasible language-driven PTZ control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SCOPE, a modular natural-language agent for real-time PTZ camera control and scene understanding that executes perception, planning, and control locally on edge hardware. It releases a 536-task benchmark spanning QA, spatial reasoning, and OCR in a Blender simulation exposing PTZ affordances, evaluates 19 planner-perception combinations of Qwen3 SLMs with Moondream/Qwen VLMs using LM-as-Judge metrics, and claims that stronger SLMs reduce hallucinations and improve tool routing, that perception becomes the dominant bottleneck once a capable SLM is used, that MoE models on planning and perception sides match or exceed dense alternatives at comparable latency and memory, and that quantization yields further gains with a sim-to-real validated design point for physical PTZ operation.
Significance. If the empirical results and bottleneck diagnosis hold, the work supplies a concrete, reproducible benchmark and design guidance for deploying language-driven agents on resource-constrained robotic camera platforms, with practical efficiency findings on MoE versus dense models and quantization that could inform edge robotics deployments.
major comments (2)
- [Abstract] Abstract: the claim of a 'sim-to-real validated design point' and the diagnosis that 'perception becomes the dominant performance bottleneck' rest on Blender simulation results without any reported quantitative comparison (error rates, latency distributions, or accuracy under realistic lighting/motion) between simulation and physical PTZ hardware; if camera artifacts increase perception errors while leaving planner routing unchanged, both the bottleneck shift and the reported MoE efficiency advantage would no longer hold at the claimed operating point.
- [Evaluations] Evaluations (19 model combinations on 536-task benchmark): the support for claims that 'stronger SLMs substantially reduce hallucinations and improve tool routing' and that 'Mixture-of-Experts models ... consistently match or exceed dense alternatives' is undermined by the absence of error bars, full per-task data, or detailed methods for the LM-as-Judge protocol and latency measurements, preventing verification of the cross-model comparisons.
minor comments (2)
- [Abstract] The abstract is information-dense; breaking the list of benchmark task categories and the exact 19 model pairings into a table would improve readability.
- Notation for model variants (e.g., specific Qwen3 sizes and MoE configurations) should be defined consistently when first introduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important points regarding the strength of our sim-to-real claims and the verifiability of our evaluation results. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 'sim-to-real validated design point' and the diagnosis that 'perception becomes the dominant performance bottleneck' rest on Blender simulation results without any reported quantitative comparison (error rates, latency distributions, or accuracy under realistic lighting/motion) between simulation and physical PTZ hardware; if camera artifacts increase perception errors while leaving planner routing unchanged, both the bottleneck shift and the reported MoE efficiency advantage would no longer hold at the claimed operating point.
Authors: We agree that the manuscript lacks quantitative metrics directly comparing simulation and physical hardware (e.g., error rates or latency distributions under matched conditions). The 'sim-to-real validated design point' refers to the fact that the final quantized MoE configuration was successfully deployed and operated in closed-loop on physical PTZ hardware without modification, confirming basic feasibility and real-time performance. However, we did not collect or report paired quantitative sim/real error distributions. The perception-bottleneck diagnosis and MoE comparisons are derived entirely from the 536-task simulation benchmark. We will revise the abstract and add a limitations paragraph to clarify that the sim-to-real aspect is a qualitative feasibility demonstration rather than a quantitative transfer study, and we will not claim that the bottleneck diagnosis has been verified on hardware. revision: partial
-
Referee: [Evaluations] Evaluations (19 model combinations on 536-task benchmark): the support for claims that 'stronger SLMs substantially reduce hallucinations and improve tool routing' and that 'Mixture-of-Experts models ... consistently match or exceed dense alternatives' is undermined by the absence of error bars, full per-task data, or detailed methods for the LM-as-Judge protocol and latency measurements, preventing verification of the cross-model comparisons.
Authors: We acknowledge that the current manuscript does not include error bars on the aggregate metrics, does not release the full per-task breakdown, and provides only high-level descriptions of the LM-as-Judge protocol and latency measurement procedure. These omissions limit independent verification of the reported trends. We will expand the evaluation section to include: (1) the exact LM-as-Judge prompt template and scoring rubric, (2) standard deviations or confidence intervals for the key accuracy and hallucination metrics across the 19 combinations, (3) a summary table of per-category results, and (4) a link to a supplementary repository containing the full per-task traces and raw latency logs. These additions will be made without altering the experimental setup or conclusions. revision: yes
Circularity Check
No circularity: purely empirical model evaluation on released benchmark
full rationale
The manuscript contains no equations, derivations, fitted parameters, or predictions that reduce to inputs by construction. All claims rest on direct experimental measurements of 19 planner-perception combinations across 536 tasks in Blender simulation plus physical PTZ hardware, using latency, accuracy, and LM-as-Judge error modes. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core results; the work is a comparative benchmark study whose validity hinges on external reproducibility rather than internal definitional closure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. 2025. gpt-oss- 120b & gpt-oss-20b Model Card. arXiv:2508.10925 [cs.CL] doi:10.48550/arXiv. 2508.10925
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
-
[2]
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Haus- man, et al. 2022. Do as I can, not as I say: Grounding language in robotic affor- dances.arXiv preprint arXiv:2204.01691(2022). doi:10.48550/arXiv.2204.01691
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.01691 2022
-
[3]
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünder- hauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. 2018. Vision-and- Language Navigation: Interpreting Visually-Grounded Navigation Instructions in Real Environments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 3674–3683....
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. 2025. Qwen2.5-VL Technical Report.arXiv preprint arXiv:2502.13923(2025). doi:10.48550/arXiv.2502.13923
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[5]
2024.Prompt Engineering
Lee Boonstra. 2024.Prompt Engineering. Whitepaper. Google Cloud. https: //www.kaggle.com/whitepaper-prompt-engineering
2024
-
[6]
Alexiy Buynitsky, Sina Ehsani, Bhanu Pallakonda, and Pragyana Mishra. 2025. Camera Control at the Edge with Language Models for Scene Understanding. arXiv preprint arXiv:2505.06402(2025). doi:10.1109/ICCAR64901.2025.11073044
-
[7]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. 2024. Chatbot arena: An open platform for evaluating llms by human preference. InForty-first International Conference on Machine Learning. doi:10.5555/3692070.3692401
-
[8]
Abhishek Das, Samyak Datta, Georgia Gkioxari, Stefan Lee, Devi Parikh, and Dhruv Batra. 2018. Embodied question answering. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, Salt Lake City, UT, USA, 1–10. doi:10.1109/CVPR.2018.00008
-
[9]
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al
-
[10]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Molmo and Pixmo: Open Weights and Open Data for State-of-the-Art Vision–Language Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 91–104. doi:10.48550/arXiv.2409. 17146
-
[11]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300(2020). doi:10.48550/arXiv.2009.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2009.03300 2020
-
[12]
Brad Hilton, Kyle Corbitt, David Corbitt, Saumya Gandhi, Angky William, Bohdan Kovalenskyi, and Andie Jones. 2025. ART: Agent Reinforcement Trainer. https: //github.com/openpipe/art
2025
-
[13]
Vikhyat Karamcheti. 2025. Moondream: Lightweight Vision–Language Models (Moondream2, Moondream2-4bit, Moondream3-preview). https://huggingface. co/moondream. Includes Moondream2 (2025-06-21), Moondream2-4bit (2025-04- 14), Moondream3-preview (2025-09-18)
2025
-
[14]
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. 2022. Code as policies: Language model programs for embodied control.arXiv preprint arXiv:2209.07753(2022). doi:10.1109/ICRA48891. 2023.10160591
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/icra48891 2022
-
[15]
Roni Paiss, Ariel Ephrat, Omer Tov, Shiran Zada, Inbar Mosseri, Michal Irani, and Tali Dekel. 2023. Teaching CLIP to Count to Ten. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 3170–3180. doi:10.1109/ICCV51070.2023.00294
-
[16]
Gonzalez
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. 2025. The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models. In Proceedings of the 42nd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 267)...
2025
-
[17]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] doi:10. 48550/arXiv.2505.09388
Pith/arXiv arXiv 2025
-
[18]
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. 2016. You Only Look Once: Unified, Real-Time Object Detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 779–788. doi:10.1109/CVPR.2016.91
-
[19]
Nidhish Shah, Zulkuf Genc, and Dogu Araci. 2024. StackEval: Benchmarking LLMs in Coding Assistance. InAdvances in Neural Information Processing Systems, Vol. 37. doi:10.52202/079017-1166
-
[20]
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. 2020. ALFRED: A bench- mark for interpreting grounded instructions for everyday tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE/CVF, 10740–10749. doi:10.1109/CVPR42600.2020.01075
-
[21]
Sai H Vemprala, Rogerio Bonatti, Arthur Bucker, and Ashish Kapoor. 2024. Chat- GPT for robotics: Design principles and model abilities.IEEE Access12 (2024), 55682–55696. doi:10.1109/ACCESS.2024.3387941
-
[22]
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. 2024. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception.arXiv preprint arXiv:2401.16158(2024). doi:10.48550/arXiv.2401.16158
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.16158 2024
-
[23]
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, and Graham Neubig. 2024. MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark.arXiv preprint arXiv:2409.02813(2024). doi:10.48550/ arXiv.2409.02813 Received 2025-09-30; accepted 2025-12-01
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.