DetectZoo: A Unified Toolkit for AI-Generated Content Detection Across Text, Audio, and Image Modalities
Pith reviewed 2026-06-28 07:05 UTC · model grok-4.3
The pith
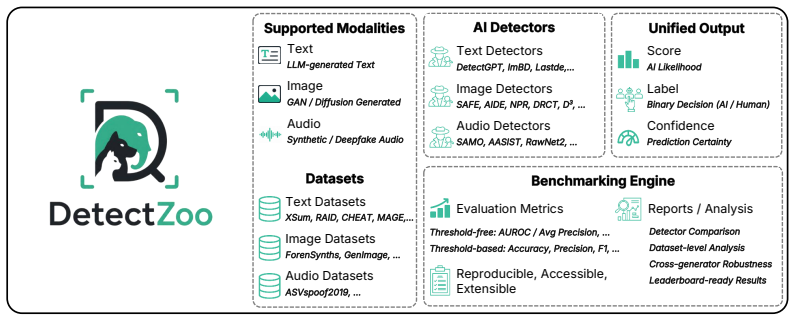
DetectZoo supplies one interface that runs 61 detectors on 22 datasets for spotting machine-generated text, audio, and images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DetectZoo provides reference implementations of 61 detectors, native loaders for 22 benchmark datasets, and a standardized evaluation pipeline that reports multiple metrics through a common interface; each detector remains self-contained, automatically caches pretrained weights, and reproduces the original published results.
What carries the argument
The unified API that standardizes the empirical pipeline from data ingestion and preprocessing to model assessment across text, audio, and image modalities.
If this is right
- Researchers can now compare detectors systematically without custom integration code for each one.
- Performance gaps between modalities become visible through the shared metrics.
- New detectors can be added while keeping the same evaluation protocol.
- Reproduction of results becomes automatic for the included baselines.
- Development of cross-modal detection methods gains a common testbed.
Where Pith is reading between the lines
- Widespread use could push the field toward shared evaluation standards rather than bespoke ones.
- The modular design makes it feasible to test whether a single detector family works across modalities without reimplementation.
- Community additions of newer detectors would keep the toolkit current without breaking existing comparisons.
Load-bearing premise
Wrapping the original detectors into a shared interface leaves their behavior and published performance unchanged.
What would settle it
Running the toolkit versions of published detectors on their original test sets and obtaining different performance numbers than the papers reported.
Figures
read the original abstract
The growing popularity and capacity of generative models have eroded the distinction between human and machine-generated content, motivating a growing body of work on detection across text, images, and audio. Most available detectors are either commercial software or, if open-source, come with incompatible codebases with bespoke preprocessing, evaluation protocols, and evaluation metrics, which make their adoption, fair comparison, and reproduction quite difficult. To address this critical gap, we introduce DetectZoo, a first-of-its-kind, extensible toolkit designed to provide a unified interface for AI-generated content detection across text, audio, and image modalities. DetectZoo standardizes the complete empirical pipeline, from data ingestion and preprocessing to model assessment, offering researchers a cohesive framework to benchmark state-of-the-art detectors systematically. By integrating diverse public datasets and baseline detection algorithms under a single, unified API, our toolkit facilitates rigorous and reproducible evaluation. DetectZoo provides reference implementations of 61 detectors, native loaders for 22 benchmark datasets, and a standardized evaluation pipeline that reports multiple metrics through a common interface. Each detector is self-contained yet accessible through the same interface, automatically caches pretrained weights, and reproduces the original published results. DetectZoo lowers the barrier to entry for multi-modal AI forensics, enabling researchers to identify performance gaps across domains and accelerating the development of robust, generalizable detection techniques. The open-source repository and comprehensive documentation are publicly available at https://github.com/sadjadeb/DetectZoo, and the package can be installed via pip install detectzoo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DetectZoo, a first-of-its-kind extensible toolkit providing a unified API and standardized empirical pipeline for AI-generated content detection across text, audio, and image modalities. It integrates 61 detectors and 22 benchmark datasets, with each detector claimed to be self-contained, cache pretrained weights automatically, and reproduce original published results. The contribution emphasizes lowering barriers to multi-modal AI forensics through open-source code available via pip and GitHub.
Significance. If the reproduction claims hold and the wrappers preserve original detector behavior without introducing biases, the toolkit would provide a valuable engineering contribution by enabling systematic, reproducible benchmarking across modalities and reducing fragmentation from incompatible codebases. The open-source release and pip installability are positive factors for adoption.
major comments (2)
- [Abstract] Abstract: The central claim that 'each detector ... reproduces the original published results' is load-bearing for the utility of the unification but is asserted without any quantitative validation, comparison tables, or error analysis in the manuscript; external verification via the repository is noted but does not substitute for evidence presented in the paper.
- [Abstract] Abstract: The assumption that wrapping 61 existing detectors under a common API 'preserves their original behavior and performance without introducing implementation-specific biases or incompatibilities' is not tested or discussed; this directly affects whether the standardized pipeline enables fair comparisons as claimed.
minor comments (1)
- [Abstract] The abstract mentions 'multiple metrics through a common interface' but does not specify which metrics are standardized, which would aid clarity for readers evaluating the pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, proposing revisions where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'each detector ... reproduces the original published results' is load-bearing for the utility of the unification but is asserted without any quantitative validation, comparison tables, or error analysis in the manuscript; external verification via the repository is noted but does not substitute for evidence presented in the paper.
Authors: We agree that the reproduction claim is central and that the manuscript would be strengthened by including quantitative validation directly in the paper rather than relying on the repository. In the revised version, we will add a new subsection (likely in Section 4 or an appendix) presenting reproduction results. This will include a table comparing key metrics (e.g., accuracy, AUC) from our implementations against the originally reported numbers for a representative subset of detectors across all three modalities, along with notes on any discrepancies and the evaluation protocol used. revision: yes
-
Referee: [Abstract] Abstract: The assumption that wrapping 61 existing detectors under a common API 'preserves their original behavior and performance without introducing implementation-specific biases or incompatibilities' is not tested or discussed; this directly affects whether the standardized pipeline enables fair comparisons as claimed.
Authors: The referee is correct that this assumption should be explicitly tested and discussed to support claims of fair comparisons. We will revise the manuscript to include a dedicated discussion of the wrapper design principles (e.g., preserving original preprocessing, model forward passes, and post-processing steps) and add empirical validation experiments. These will compare performance of the wrapped detectors versus their standalone original code on shared benchmark subsets, quantifying any differences and discussing mitigation strategies for potential biases. revision: yes
Circularity Check
No significant circularity; engineering integration claim with external verifiability
full rationale
The manuscript introduces a software toolkit that wraps 61 existing detectors and 22 datasets under a common API. No equations, fitted parameters, predictions, or derivations appear anywhere in the text. The central assertion—that each wrapper reproduces the original published detector behavior—is presented as an engineering requirement whose correctness is externally checkable via the linked open-source repository rather than derived internally. No self-citation chains, ansatzes, or uniqueness theorems are invoked to support the unification claim. The contribution is therefore self-contained against external benchmarks (the published detector papers and the released code).
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Defending against neural fake news.Advances in neural information processing systems, 32, 2019
Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, and Yejin Choi. Defending against neural fake news.Advances in neural information processing systems, 32, 2019
2019
-
[2]
Deepfake Media Generation and Detection in the Generative AI Era: A Survey and Outlook
Florinel-Alin Croitoru, Andrei Iulian Hiji, Vlad Hondru, Nicolae-C˘at˘alin Ristea, Paul Irofti, Marius Popescu, Cristian Rusu, Radu Tudor Ionescu, Fahad Shahbaz Khan, and Mubarak Shah. Deepfake media generation and detection in the generative ai era: A survey and outlook. ArXiv, abs/2411.19537, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
Deep fakes: A looming challenge for privacy, democracy, and national security.Calif
Bobby Chesney and Danielle Citron. Deep fakes: A looming challenge for privacy, democracy, and national security.Calif. L. Rev., 107:1753, 2019
2019
-
[4]
Audio deepfake detection: A survey.arXiv preprint arXiv:2308.14970, 2023
Jiangyan Yi, Chenglong Wang, Jianhua Tao, Xiaohui Zhang, Chu Yuan Zhang, and Yan Zhao. Audio deepfake detection: A survey.arXiv preprint arXiv:2308.14970, 2023
-
[5]
Human perception of audio deepfakes
Nicolas M Müller, Karla Pizzi, and Jennifer Williams. Human perception of audio deepfakes. InProceedings of the 1st international workshop on deepfake detection for audio multimedia, pages 85–91, 2022
2022
-
[6]
Beyond a reasonable doubt? audiovisual evidence, ai manipulation, deepfakes, and the law.IEEE Transactions on Technology and Society, 5(2):156–168, 2024
Yvonne Apolo and Katina Michael. Beyond a reasonable doubt? audiovisual evidence, ai manipulation, deepfakes, and the law.IEEE Transactions on Technology and Society, 5(2):156–168, 2024
2024
-
[7]
Judicial approaches to acknowledged and unacknowl- edged ai-generated evidence.Colum
Maura R Grossman and Paul W Grimm. Judicial approaches to acknowledged and unacknowl- edged ai-generated evidence.Colum. Sci. & Tech. L. Rev., 26:110, 2024
2024
-
[8]
Detectgpt: Zero-shot machine-generated text detection using probability curvature
Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D Manning, and Chelsea Finn. Detectgpt: Zero-shot machine-generated text detection using probability curvature. In International conference on machine learning, pages 24950–24962. PMLR, 2023
2023
-
[9]
Guangsheng Bao, Yanbin Zhao, Zhiyang Teng, Linyi Yang, and Yue Zhang. Fast-detectgpt: Efficient zero-shot detection of machine-generated text via conditional probability curvature. arXiv preprint arXiv:2310.05130, 2023
-
[10]
Abhimanyu Hans, Avi Schwarzschild, Valeriia Cherepanova, Hamid Kazemi, Aniruddha Saha, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Spotting llms with binoculars: Zero-shot detection of machine-generated text.arXiv preprint arXiv:2401.12070, 2024
-
[11]
Towards universal fake image detectors that generalize across generative models
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. Towards universal fake image detectors that generalize across generative models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24480–24489, 2023
2023
-
[12]
Drct: Diffusion reconstruction contrastive training towards universal detection of diffusion generated images
Baoying Chen, Jishen Zeng, Jianquan Yang, and Rui Yang. Drct: Diffusion reconstruction contrastive training towards universal detection of diffusion generated images. InForty-first International Conference on Machine Learning, 2024
2024
-
[13]
Co-spy: Combining semantic and pixel features to detect synthetic images by ai
Siyuan Cheng, Lingjuan Lyu, Zhenting Wang, Xiangyu Zhang, and Vikash Sehwag. Co-spy: Combining semantic and pixel features to detect synthetic images by ai. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13455–13465, 2025
2025
-
[14]
End-to-end anti-spoofing with rawnet2
Hemlata Tak, Jose Patino, Massimiliano Todisco, Andreas Nautsch, Nicholas Evans, and Anthony Larcher. End-to-end anti-spoofing with rawnet2. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6369–
2021
-
[15]
Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks
Jee-weon Jung, Hee-Soo Heo, Hemlata Tak, Hye-jin Shim, Joon Son Chung, Bong-Jin Lee, Ha-Jin Yu, and Nicholas Evans. Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks. InICASSP 2022-2022 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 6367–6371. IEEE, 2022. 10
2022
-
[16]
Climb: Class-imbalanced learning benchmark on tabular data
Zhining Liu, Zihao Li, Ze Yang, Tianxin Wei, Jian Kang, Yada Zhu, Hendrik Hamann, Jingrui He, and Hanghang Tong. Climb: Class-imbalanced learning benchmark on tabular data. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[17]
Robustbench: a standardized adversarial robustness benchmark
Francesco Croce, Maksym Andriushchenko, Vikash Sehwag, Edoardo Debenedetti, Nicolas Flammarion, Mung Chiang, Prateek Mittal, and Matthias Hein. Robustbench: a standardized adversarial robustness benchmark. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[18]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Huggingface’s trans- formers: State-of-the-art natural language processing.arXiv preprint arXiv:1910.03771, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[19]
Pyod: A python toolbox for scalable outlier detection
Yue Zhao, Zain Nasrullah, and Zheng Li. Pyod: A python toolbox for scalable outlier detection. Journal of Machine Learning Research, 20(96):1–7, 2019
2019
-
[20]
Release Strategies and the Social Impacts of Language Models
Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-V oss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, et al. Release strategies and the social impacts of language models.arXiv preprint arXiv:1908.09203, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[21]
Gltr: Statistical detection and visualization of generated text
Sebastian Gehrmann, Hendrik Strobelt, and Alexander M Rush. Gltr: Statistical detection and visualization of generated text. InProceedings of the 57th annual meeting of the association for computational linguistics: system demonstrations, pages 111–116, 2019
2019
-
[22]
Detecting fake content with relative entropy scoring.Pan, 8(27-31):4, 2008
Thomas Lavergne, Tanguy Urvoy, and François Yvon. Detecting fake content with relative entropy scoring.Pan, 8(27-31):4, 2008
2008
-
[23]
Detectllm: Leveraging log rank information for zero-shot detection of machine-generated text
Jinyan Su, Terry Zhuo, Di Wang, and Preslav Nakov. Detectllm: Leveraging log rank information for zero-shot detection of machine-generated text. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 12395–12412, 2023
2023
-
[24]
Xianjun Yang, Wei Cheng, Yue Wu, Linda Petzold, William Yang Wang, and Haifeng Chen. Dna-gpt: Divergent n-gram analysis for training-free detection of gpt-generated text.arXiv preprint arXiv:2305.17359, 2023
-
[25]
Intrinsic dimen- sion estimation for robust detection of ai-generated texts.Advances in Neural Information Processing Systems, 36:39257–39276, 2023
Eduard Tulchinskii, Kristian Kuznetsov, Laida Kushnareva, Daniil Cherniavskii, Sergey Nikolenko, Evgeny Burnaev, Serguei Barannikov, and Irina Piontkovskaya. Intrinsic dimen- sion estimation for robust detection of ai-generated texts.Advances in Neural Information Processing Systems, 36:39257–39276, 2023
2023
-
[26]
Radar: Robust ai-text detection via adversarial learning.Advances in neural information processing systems, 36:15077–15095, 2023
Xiaomeng Hu, Pin-Yu Chen, and Tsung-Yi Ho. Radar: Robust ai-text detection via adversarial learning.Advances in neural information processing systems, 36:15077–15095, 2023
2023
-
[27]
Remodetect: Reward models recognize aligned llm’s generations.Advances in Neural Information Processing Systems, 37:2886–2913, 2024
Hyunseok Lee, Jihoon Tack, and Jinwoo Shin. Remodetect: Reward models recognize aligned llm’s generations.Advances in Neural Information Processing Systems, 37:2886–2913, 2024
2024
-
[28]
Cnn- generated images are surprisingly easy to spot
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A Efros. Cnn- generated images are surprisingly easy to spot... for now. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8695–8704, 2020
2020
-
[29]
Rethinking the up-sampling operations in cnn-based generative network for generalizable deepfake detection
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. Rethinking the up-sampling operations in cnn-based generative network for generalizable deepfake detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 28130–28139, 2024
2024
-
[30]
Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 5052–5060, 2024. 11
2024
-
[31]
Improving synthetic image detection towards generalization: An image transformation perspective
Ouxiang Li, Jiayin Cai, Yanbin Hao, Xiaolong Jiang, Yao Hu, and Fuli Feng. Improving synthetic image detection towards generalization: An image transformation perspective. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 2405–2414, 2025
2025
-
[32]
Learning on gradients: Generalized artifacts representation for gan-generated images detection
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, and Yunchao Wei. Learning on gradients: Generalized artifacts representation for gan-generated images detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12105–12114, 2023
2023
-
[33]
Aeroblade: Training-free detection of latent diffusion images using autoencoder reconstruction error
Jonas Ricker, Denis Lukovnikov, and Asja Fischer. Aeroblade: Training-free detection of latent diffusion images using autoencoder reconstruction error. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9130–9140, 2024
2024
-
[34]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[35]
Forgery-aware adaptive transformer for generalizable synthetic image detection
Huan Liu, Zichang Tan, Chuangchuang Tan, Yunchao Wei, Jingdong Wang, and Yao Zhao. Forgery-aware adaptive transformer for generalizable synthetic image detection. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10770–10780, 2024
2024
-
[36]
C2p-clip: Injecting category common prompt in clip to enhance generalization in deepfake detection
Chuangchuang Tan, Renshuai Tao, Huan Liu, Guanghua Gu, Baoyuan Wu, Yao Zhao, and Yunchao Wei. C2p-clip: Injecting category common prompt in clip to enhance generalization in deepfake detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7184–7192, 2025
2025
-
[37]
A sanity check for ai-generated image detection
Shilin Yan, Ouxiang Li, Jiayin Cai, Yanbin Hao, Xiaolong Jiang, Yao Hu, and Weidi Xie. A sanity check for ai-generated image detection. InThe Thirteenth International Conference on Learning Representations
-
[38]
Improved DeepFake Detection Using Whisper Features
Piotr Kawa, Marcin Plata, Michał Czuba, Piotr Szyma´nski, and Piotr Syga. Improved DeepFake Detection Using Whisper Features. InProc. INTERSPEECH 2023, pages 4009–4013, 2023
2023
-
[39]
RAID: A shared benchmark for robust evaluation of machine-generated text detectors
Liam Dugan, Alyssa Hwang, Filip Trhlík, Andrew Zhu, Josh Magnus Ludan, Hainiu Xu, Daphne Ippolito, and Chris Callison-Burch. RAID: A shared benchmark for robust evaluation of machine-generated text detectors. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12463–12492, Bangkok, Thail...
2024
-
[40]
Turingbench: A bench- mark environment for turing test in the age of neural text generation
Adaku Uchendu, Zeyu Ma, Thai Le, Rui Zhang, and Dongwon Lee. Turingbench: A bench- mark environment for turing test in the age of neural text generation. InFindings of the association for computational linguistics: EMNLP 2021, pages 2001–2016, 2021
2021
-
[41]
M4: Multi-generator, multi- domain, and multi-lingual black-box machine-generated text detection
Yuxia Wang, Jonibek Mansurov, Petar Ivanov, Jinyan Su, Artem Shelmanov, Akim Tsvigun, Chenxi Whitehouse, Osama Mohammed Afzal, Tarek Mahmoud, Toru Sasaki, Thomas Arnold, Alham Aji, Nizar Habash, Iryna Gurevych, and Preslav Nakov. M4: Multi-generator, multi- domain, and multi-lingual black-box machine-generated text detection. InProceedings of the 18th Con...
2024
-
[42]
MGTBench: Benchmarking Machine-Generated Text Detection
Xinlei He, Xinyue Shen, Zeyuan Chen, Michael Backes, and Yang Zhang. MGTBench: Benchmarking Machine-Generated Text Detection. InACM SIGSAC Conference on Computer and Communications Security (CCS). ACM, 2024
2024
-
[43]
Deepfakebench: A comprehensive benchmark of deepfake detection.Advances in Neural Information Processing Systems, 36:4534–4565, 2023
Zhiyuan Yan, Yong Zhang, Xinhang Yuan, Siwei Lyu, and Baoyuan Wu. Deepfakebench: A comprehensive benchmark of deepfake detection.Advances in Neural Information Processing Systems, 36:4534–4565, 2023. 12
2023
-
[44]
Genimage: A million-scale benchmark for detecting ai-generated image.Advances in neural information processing systems, 36:77771–77782, 2023
Mingjian Zhu, Hanting Chen, Qiangyu Yan, Xudong Huang, Guanyu Lin, Wei Li, Zhijun Tu, Hailin Hu, Jie Hu, and Yunhe Wang. Genimage: A million-scale benchmark for detecting ai-generated image.Advances in neural information processing systems, 36:77771–77782, 2023
2023
-
[45]
Junhao Zhuang, Yanhong Zeng, Wenran Liu, Chun Yuan, and Kai Chen
Nan Zhong, Yiran Xu, Sheng Li, Zhenxing Qian, and Xinpeng Zhang. Patchcraft: Exploring texture patch for efficient ai-generated image detection.arXiv preprint arXiv:2311.12397, 2023
-
[46]
ASVspoof 2019: Future Horizons in Spoofed and Fake Audio Detection
Massimiliano Todisco, Xin Wang, Ville Vestman, Md Sahidullah, Héctor Delgado, Andreas Nautsch, Junichi Yamagishi, Nicholas Evans, Tomi Kinnunen, and Kong Aik Lee. Asvspoof 2019: Future horizons in spoofed and fake audio detection.arXiv preprint arXiv:1904.05441, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[47]
ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection
Junichi Yamagishi, Xin Wang, Massimiliano Todisco, Md Sahidullah, Jose Patino, Andreas Nautsch, Xuechen Liu, Kong Aik Lee, Tomi Kinnunen, Nicholas Evans, and Héctor Delgado. ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection. InProc. ASVspoof Challenge workshop, pages 47–54, 2021
2021
-
[48]
Mage: Machine-generated text detection in the wild
Yafu Li, Qintong Li, Leyang Cui, Wei Bi, Zhilin Wang, Longyue Wang, Linyi Yang, Shuming Shi, and Yue Zhang. Mage: Machine-generated text detection in the wild. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 36–53, 2024
2024
-
[49]
Junchao Wu, Runzhe Zhan, Derek F Wong, Shu Yang, Xinyi Yang, Yulin Yuan, and Lidia S Chao. Detectrl: Benchmarking llm-generated text detection in real-world scenarios.arXiv preprint arXiv:2410.23746, 2024
-
[50]
Is artificial intelligence generated image detection a solved problem? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
Ziqiang Li, Jiazhen Yan, Ziwen He, Kai Zeng, Weiwei Jiang, Lizhi Xiong, and Zhangjie Fu. Is artificial intelligence generated image detection a solved problem? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
-
[51]
Yihuai Xu, Yongwei Wang, Yifei Bi, Huangsen Cao, Zhouhan Lin, Yu Zhao, and Fei Wu. Training-free llm-generated text detection by mining token probability sequences.arXiv preprint arXiv:2410.06072, 2024
-
[52]
Who wrote this? the key to zero-shot llm-generated text detection is gecscore
Junchao Wu, Runzhe Zhan, Derek F Wong, Shu Yang, Xuebo Liu, Lidia S Chao, and Min Zhang. Who wrote this? the key to zero-shot llm-generated text detection is gecscore. In Proceedings of the 31st International Conference on Computational Linguistics, pages 10275– 10292, 2025
2025
-
[53]
Biscope: Ai-generated text detection by checking memorization of preceding tokens.Advances in Neural Information Processing Systems, 37:104065–104090, 2024
Hanxi Guo, Siyuan Cheng, Xiaolong Jin, Zhuo Zhang, Kaiyuan Zhang, Guanhong Tao, Guangyu Shen, and Xiangyu Zhang. Biscope: Ai-generated text detection by checking memorization of preceding tokens.Advances in Neural Information Processing Systems, 37:104065–104090, 2024
2024
-
[54]
Adadetectgpt: Adaptive detection of llm-generated text with statistical guarantees
Hongyi Zhou, Jin Zhu, Pingfan Su, Kai Ye, Ying Yang, Shakeel A O B Gavioli-Akilagun, and Chengchun Shi. Adadetectgpt: Adaptive detection of llm-generated text with statistical guarantees. InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[55]
Glimpse: Enabling white-box methods to use proprietary models for zero-shot llm-generated text detection
Guangsheng Bao, Yanbin Zhao, Juncai He, and Yue Zhang. Glimpse: Enabling white-box methods to use proprietary models for zero-shot llm-generated text detection. 2025
2025
-
[56]
Dna- detectllm: Unveiling ai-generated text via a dna-inspired mutation-repair paradigm
Xiaowei Zhu, Yubing Ren, Fang Fang, Qingfeng Tan, Shi Wang, and Yanan Cao. Dna- detectllm: Unveiling ai-generated text via a dna-inspired mutation-repair paradigm. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[57]
Beat LLMs at their own game: Zero-shot LLM- generated text detection via querying ChatGPT
Biru Zhu, Lifan Yuan, Ganqu Cui, Yangyi Chen, Chong Fu, Bingxiang He, Yangdong Deng, Zhiyuan Liu, Maosong Sun, and Ming Gu. Beat LLMs at their own game: Zero-shot LLM- generated text detection via querying ChatGPT. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7470–7483, Singapore, December
2023
-
[58]
Association for Computational Linguistics. 13
-
[59]
Raidar: generative AI detection via rewriting
Chengzhi Mao, Carl V ondrick, Hao Wang, and Junfeng Yang. Raidar: generative AI detection via rewriting. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[60]
Ghostbuster: Detecting text ghostwritten by large language models
Vivek Verma, Eve Fleisig, Nicholas Tomlin, and Dan Klein. Ghostbuster: Detecting text ghostwritten by large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies (Volume 1: Long Papers), pages 1702–1717, 2024
2024
-
[61]
Zero-shot detection of LLM-generated text using token cohe- siveness
Shixuan Ma and Quan Wang. Zero-shot detection of LLM-generated text using token cohe- siveness. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17538–17553, Miami, Florida, USA, November 2024. Association for Computational Linguistics
2024
-
[62]
Zheng Chen, Yushi Feng, Jisheng Dang, Yue Deng, Changyang He, Hongxi Pu, Haoxuan Li, and Bo Li. Ipad: Inverse prompt for ai detection-a robust and interpretable llm-generated text detector.arXiv preprint arXiv:2502.15902, 2025
-
[63]
Text fluoroscopy: Detecting llm-generated text through intrinsic features
Xiao Yu, Kejiang Chen, Qi Yang, Weiming Zhang, and Nenghai Yu. Text fluoroscopy: Detecting llm-generated text through intrinsic features. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15838–15846, 2024
2024
-
[64]
Coco: Coherence-enhanced machine-generated text detection under low resource with contrastive learning
Xiaoming Liu, Zhaohan Zhang, Yichen Wang, Hang Pu, Yu Lan, and Chao Shen. Coco: Coherence-enhanced machine-generated text detection under low resource with contrastive learning. Inproceedings of the 2023 conference on empirical methods in natural language processing, pages 16167–16188, 2023
2023
-
[65]
Imitate before detect: Aligning machine stylistic preference for machine-revised text detection
Jiaqi Chen, Xiaoye Zhu, Tianyang Liu, Ying Chen, Chen Xinhui, Yiwen Yuan, Chak Tou Leong, Zuchao Li, Long Tang, Lei Zhang, et al. Imitate before detect: Aligning machine stylistic preference for machine-revised text detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23559–23567, 2025
2025
-
[66]
Detective: Detecting ai-generated text via multi-level contrastive learn- ing.Advances in Neural Information Processing Systems, 37:88320–88347, 2024
Xun Guo, Shan Zhang, Yongxin He, Ting Zhang, Wanquan Feng, Haibin Huang, and Chongyang Ma. Detective: Detecting ai-generated text via multi-level contrastive learn- ing.Advances in Neural Information Processing Systems, 37:88320–88347, 2024
2024
-
[67]
Zero-Shot Detection of LLM-Generated Text via Implicit Reward Model
Runheng Liu, Heyan Huang, Xingchen Xiao, and Zhijing Wu. Zero-shot detection of llm- generated text via implicit reward model.arXiv preprint arXiv:2604.21223, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[68]
Cong Zeng, Shengkun Tang, Yuanzhou Chen, Zhiqiang Shen, Wenchao Yu, Xujiang Zhao, Haifeng Chen, Wei Cheng, and Zhiqiang Xu. Human texts are outliers: Detecting llm-generated texts via out-of-distribution detection.arXiv preprint arXiv:2510.08602, 2025
-
[69]
Progressive growing of gans for improved quality, stability, and variation
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation. InInternational Conference on Learning Represen- tations, 2018
2018
-
[70]
Dˆ 3: scaling up deepfake detection by learning from discrepancy
Yongqi Yang, Zhihao Qian, Ye Zhu, Olga Russakovsky, and Yu Wu. Dˆ 3: scaling up deepfake detection by learning from discrepancy. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23850–23859, 2025
2025
-
[71]
Manifold induced biases for zero-shot and few-shot detection of generated images
Jonathan Brokman, Amit Giloni, Omer Hofman, Roman Vainshtein, Hisashi Kojima, and Guy Gilboa. Manifold induced biases for zero-shot and few-shot detection of generated images. In 13th International Conference on Learning Representations, ICLR 2025, pages 12803–12828. International Conference on Learning Representations, ICLR, 2025
2025
-
[72]
End- to-end spectro-temporal graph attention networks for speaker verification anti-spoofing and speech deepfake detection
Hemlata Tak, Jee-weon Jung, Jose Patino, Massimiliano Todisco, and Nicholas Evans. End- to-end spectro-temporal graph attention networks for speaker verification anti-spoofing and speech deepfake detection. InProc. ASVspoof Challenge workshop, pages 1–8, 2021
2021
-
[73]
Towards end-to-end synthetic speech detection.IEEE Signal Processing Letters, 28:1265–1269, 2021
Guang Hua, Andrew Beng Jin Teoh, and Haijian Zhang. Towards end-to-end synthetic speech detection.IEEE Signal Processing Letters, 28:1265–1269, 2021. 14
2021
-
[74]
SAMO: Speaker attractor multi-center one-class learning for voice anti-spoofing
Siying Ding, You Zhang, and Zhiyao Duan. SAMO: Speaker attractor multi-center one-class learning for voice anti-spoofing. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
2023
-
[75]
AST: Audio spectrogram transformer
Yuan Gong, Yu-An Chung, and James Glass. AST: Audio spectrogram transformer. InProc. Interspeech 2021, pages 571–575, 2021
2021
-
[76]
Post-training for deepfake speech detection.arXiv preprint arXiv:2506.21090, 2025
Wanying Ge, Xin Wang, Junichi Yamagishi, and Nicholas Evans. Post-training for deepfake speech detection.arXiv preprint arXiv:2506.21090, 2025
-
[77]
Audio deepfake detection with self-supervised XLS-R and sensitive layer selection
Qishan Zhang, Jian Ye, Yue Lu, and Huan Liu. Audio deepfake detection with self-supervised XLS-R and sensitive layer selection. InProceedings of the 32nd ACM International Conference on Multimedia, pages 1–10. ACM, 2024
2024
-
[78]
Biyang Guo, Xin Zhang, Ziyuan Wang, Minqi Jiang, Jinran Nie, Yuxuan Ding, Jianwei Yue, and Yupeng Wu. How close is chatgpt to human experts? comparison corpus, evaluation, and detection.arXiv preprint arxiv:2301.07597, 2023
-
[79]
Zhenpeng Su, Xing Wu, Wei Zhou, Guangyuan Ma, and Songlin Hu. Hc3 plus: A semantic- invariant human chatgpt comparison corpus.arXiv preprint arXiv:2309.02731, 2023
-
[80]
Cheat: A large-scale dataset for detecting chatgpt-written abstracts.IEEE Transactions on Big Data, 11(3):898–906, 2025
Peipeng Yu, Jiahan Chen, Xuan Feng, and Zhihua Xia. Cheat: A large-scale dataset for detecting chatgpt-written abstracts.IEEE Transactions on Big Data, 11(3):898–906, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.